假设面试官问你:“如果美团需要每天处理100亿条消息,系统架构该怎么设计?”这可不是一个空想的理论题,它对应着美团真实的业务场景:海量的外卖订单、用户请求、骑手轨迹、支付流水等等,每秒的请求峰值可能高达数万条。
面对这样的“不可能的任务”,传统架构很容易在瞬间被压垮。那么,问题的核心挑战究竟在哪里?
- 高并发写入:每秒数万条消息的写入,对数据库是极大的考验。
- 低延迟处理:用户点击下单后,系统必须在毫秒级别给出响应。
- 数据一致性:在分布式环境下,如何确保消息不丢、不重?
- 弹性扩展:当业务量爆发式增长时,系统能否像搭积木一样快速扩容?
1. 美团的“分层解耦”方案:像搭积木一样设计系统
1.1 消息接收层:流量“泄洪闸”设计
核心思路很清晰:“把汹涌的流量先导入蓄水池,再分批处理。” 这能有效避免后端服务被瞬间冲垮。

来看具体实现:
- 分布式网关集群:
- 采用 Nginx 结合自研网关,假设每秒需处理3.8万条消息。如果配置100个网关节点,那么平均到每个节点只需处理380条/秒,压力瞬间降低了99%。
- 负载均衡算法可采用加权轮询,动态地将流量分配到不同节点。
- 消息队列削峰:
- 将接收到的消息迅速写入 Kafka。按100亿条消息、每条1KB估算,总量约为1TB。可以配置一个3节点的Kafka集群,通过数据副本机制来保障可靠性。
- 分区策略至关重要。可以按消息类型(如订单、支付、物流)进行分区。假设每个分区每秒能处理1000条消息,那么大约38个分区就能支撑起3.8万条/秒的吞吐量。
协议优化:在网络传输和数据序列化层面,选择高效的协议能极大节省带宽和提升处理速度。

从上表可以看到,对于“订单ID+时间戳”这样的典型字段,Protobuf 相比 JSON 能带来高达85%的压缩率,这在百亿级别的数据传输中节省的资源是巨大的。
1.2 消息存储层:冷热数据“分家”策略
核心思路:“热数据住‘豪宅’,冷数据住‘地下室’。” 根据数据的访问频率采用不同的存储方案,是兼顾性能与成本的关键。
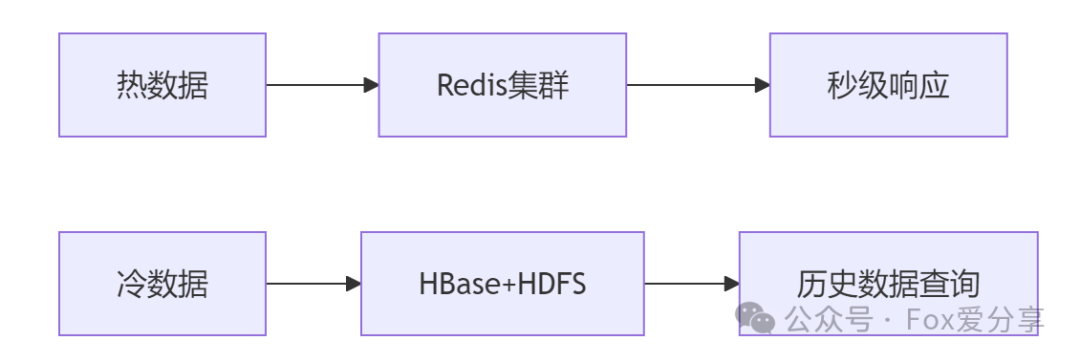
具体策略如下:
- 热数据(最近7天):
- 使用 Redis集群 存储。例如,部署一个10节点的Redis集群,每个节点存储约100万条活跃订单状态,集群总容量可达10亿条,查询响应时间能控制在1毫秒以内。
- 美团的红包系统就是典型案例,通过Redis集群每秒处理超过10万次查询,支撑了“领券-核销”的实时校验。
- 冷数据(历史数据):
- 使用 HBase 进行存储。设计时需要注意:
- RowKey设计:采用“TraceID(唯一标识)+ 时间戳”的组合,可以有效避免数据热点问题。
- 分桶策略:按月或按周划分数据,将不同时间段的数据物理隔离,查询时能快速定位到目标数据桶,提升效率。
1.3 消息处理层:并行计算“流水线”
核心思路:“把复杂任务拆解成多个小任务,流水线式处理。” 通过微服务化和流式计算,实现高效、稳定的处理能力。

看看如何落地:
- 微服务拆分:
- 将一个庞大的智能调度系统,拆分为路径规划、骑手匹配、异常处理等12个独立的微服务,服务间通过高效的 gRPC 进行通信。
- 这样做的好处是故障隔离。当某个服务(如“风控服务”)出现问题时,不会影响“订单服务”、“物流调度”等其他服务的正常运行,系统的整体可用性得到显著提升。
- Flink流处理:
- 对于需要实时计算的场景,如订单与骑手位置的实时同步,可以使用 Flink 这样的流处理框架。
# 订单与骑手位置实时同步示例
def process_order(order):
rider_location = flink.get_rider_position(order.region)
path = flink.calculate_shortest_path(order.address, rider_location)
return path
- 吞吐量:配置一个拥有100个TaskManager的Flink集群,可以实现每秒处理超过10万条消息,且处理延迟控制在100毫秒以内。
2. 技术选型背后的“数学题”
2.1 Kafka的“分区魔法”
分区的数量直接决定了消息队列的吞吐能力。其计算公式非常简单:
总吞吐量 = 单分区吞吐量 × 分区数
假设单个分区每秒能稳定处理1000条消息,那么要支撑每秒3.8万条的总吞吐量,大约需要 38000 / 1000 = 38 个分区。这就是通过水平扩展来提升 Kafka 处理能力的核心逻辑。
2.2 分库分表的“哈希分桶”
当数据量巨大,单一数据库无法承载时,分库分表是必然选择。
- 分片键策略:例如对订单表,采用
order_id % 100 作为分片规则,将数据均匀分散到100个分片(库/表)中,每个分片大约存储1亿条订单。
- 读写分离:
- 写操作:由主库集群(例如5个节点)专门负责处理订单创建等高并发写入。
- 读操作:通过从库集群(例如10个节点)并结合 Redis 缓存,可以分担掉80%以上的读请求压力,有效保护主库。
2.3 智能分片策略
更高级的策略是根据业务特征进行动态资源分配。
- 北京片区:如果其订单量占全国总业务的30%,那么就应该为其分配30%的存储和计算资源。
- 哈尔滨片区:如果订单量仅占5%,则分配5%的基础资源,但同时预留10%的冗余资源,以应对节假日或突发事件带来的流量高峰。
3. 容灾设计:像“防洪堤”一样兜底
再健壮的系统也可能出现故障,因此必须设计完善的容灾机制。
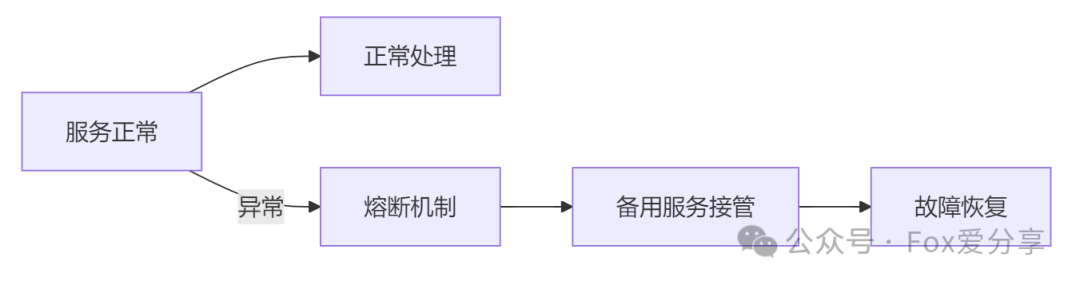
看几个关键设计:
- 熔断机制:
- 配置规则:例如,为服务间调用设置超时阈值为500毫秒;当连续10次请求的错误率达到20%时,立即触发熔断,阻断对故障服务的调用。
- 案例:当主支付服务因网络问题超时后,熔断器会快速介入,自动将请求切换到备用支付网关,用户完全感知不到支付过程的异常。
- 全链路监控与追踪:
- 使用如 MTrace 这样的工具为每个请求分配一个全局唯一的
TraceID,串联起该请求经过的所有服务节点。
TraceID: 1234567890
节点1: 网关(200ms) → 节点2: Kafka(50ms) → 节点3: 订单服务(150ms)
- 瓶颈定位:通过分析
TraceID 串联的链路数据,可以快速发现哪个环节响应变慢(例如订单服务耗时从平均150ms突增到800ms),从而有针对性地进行扩容或问题修复,这是保障 高并发 系统稳定性的眼睛。
4. 总结:高并发系统的“黄金法则”
构建一个能应对百亿级消息的 系统设计,就像跑一场马拉松,不能只靠蛮力冲刺,而要靠清晰的策略和稳健的架构。
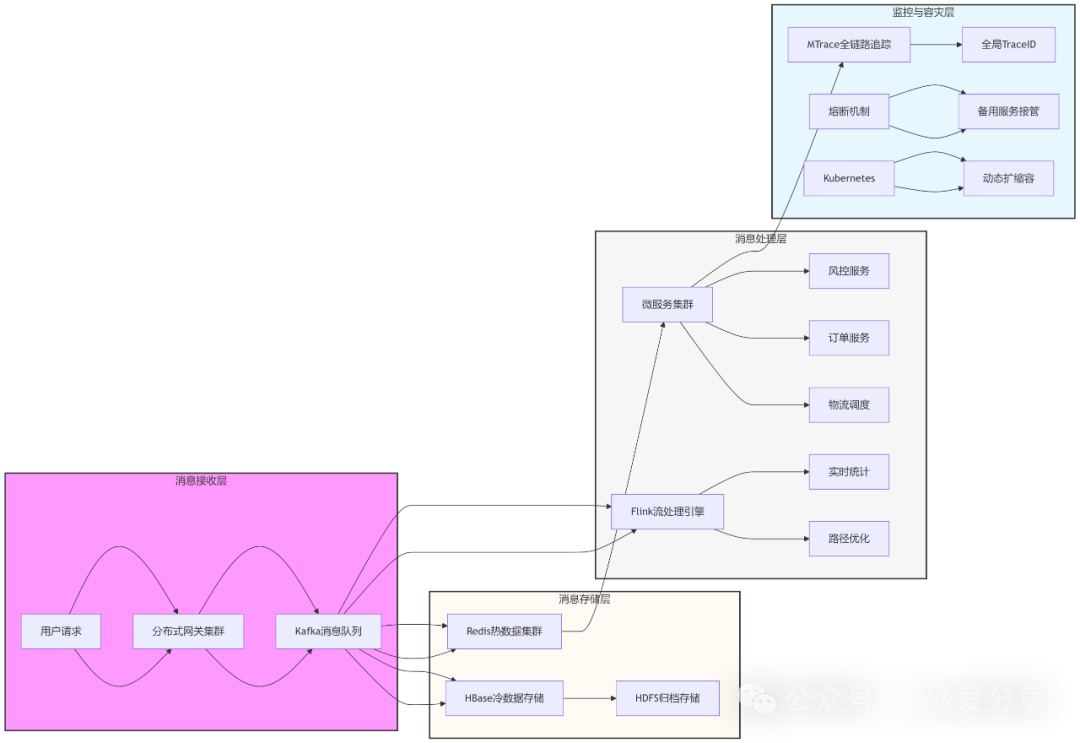
核心原则可以归纳为以下几点:
- 分层解耦:将系统像乐高积木一样拆分为清晰的层次(接入层、队列层、处理层、存储层),实现故障隔离,必要时可以“断臂求生”。
- 异步化:善用消息队列作为缓冲池,将同步的脉冲流量转化为异步的平稳流,避免系统内部“堵车”。
- 冷热分离:根据数据的访问模式,采用不同的存储方案(内存、SSD、HDD),用最低的成本满足性能需求。
- 监控兜底:建立完善的全链路追踪和熔断降级机制,它们就像系统的“安全带”和“安全气囊”,能在出现问题时最大限度地兜住风险,保障核心业务流程。
希望这份针对超大规模消息处理的架构解析,能为你应对下一次的 系统设计 面试或实际挑战提供清晰的思路。如果你在实践过程中遇到过其他棘手的“不可能任务”,或者有更巧妙的解决方案,欢迎在云栈社区与其他开发者交流探讨。 |  发表于 2026-3-3 12:07:33
|
查看: 125|
回复: 0
发表于 2026-3-3 12:07:33
|
查看: 125|
回复: 0
