提高大模型的长期记忆能力,各路研究机构都在积极出招。作为开源领域的重量级玩家,英伟达近期联合Astera研究所、斯坦福大学、UC伯克利等知名机构,推出了一项名为 TTT-E2E 的新方法。
该方法在128K超长文本上的处理速度比传统的全注意力模型快了2.7倍。在处理长达2M的上下文时,速度提升更是达到了惊人的35倍,且模型性能几乎没有损失。
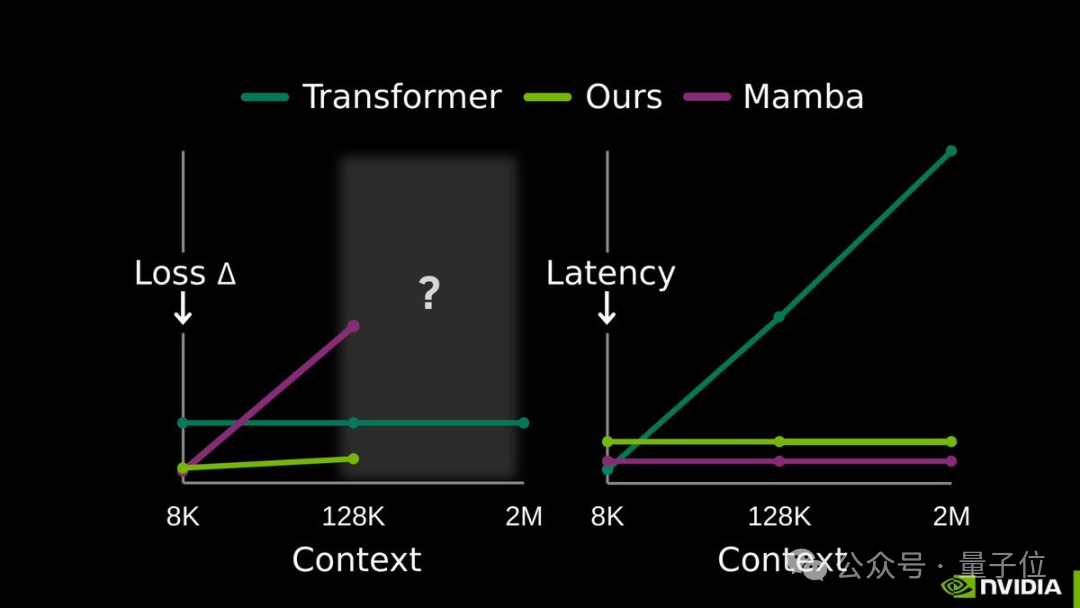
这项技术与之前引发关注的DeepSeek条件记忆模块思路不同。DeepSeek的Engram模块更偏向于“按需查表”的静态学习路径,而英伟达团队则选择了一条动态学习的路线,其核心秘诀在于上下文压缩。
简单来说,TTT-E2E让模型在测试(推理)阶段也能持续学习,通过实时训练将关键信息动态压缩到自身的网络权重中。这样做的好处显而易见:既避免了引入额外缓存带来的存储与计算负担,又能更精准地捕捉长文本中的核心逻辑关系。
给模型装上动态记忆压缩包
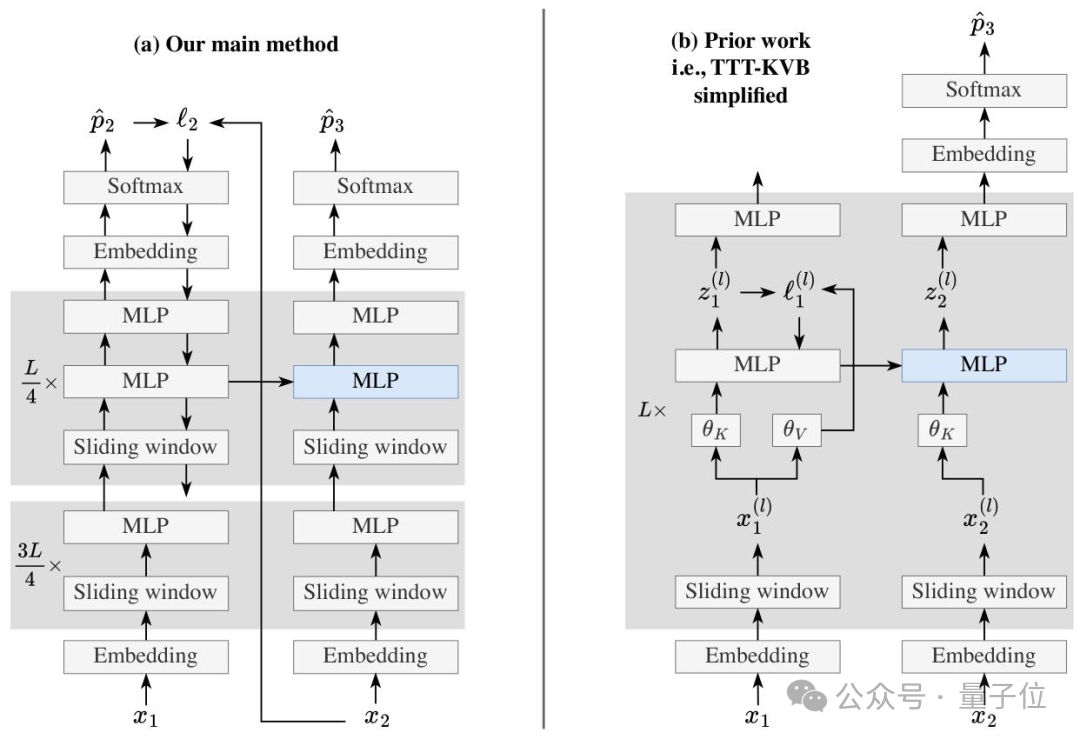
TTT-E2E并未依赖复杂或特殊的模型架构,其基础是配备了滑动窗口注意力的标准Transformer结构,这使得它更容易被部署和应用。
该方法的核心创新在于,它将处理长文本的挑战从一个架构设计问题,转化为了一个「持续学习」任务。
在测试阶段,模型像往常一样基于当前读取的上下文进行下一个词的预测。但关键区别在于,每读取一段文本,它就会通过梯度下降算法“偷偷地”更新自己的部分参数。通过这种持续的自我训练,模型将读到的文本信息动态地压缩到自身的权重里,从而无需存储海量的中间状态或冗余数据。
为了让模型在测试时能快速适应并高效学习,研究团队在训练阶段引入了元学习进行初始化。具体而言,他们将每个训练序列都模拟成测试序列:先在内循环中对模型进行测试时训练,然后在外循环中优化模型的初始参数。这种端到端的对齐优化确保了模型从一开始就具备了快速适配测试时学习需求的能力。
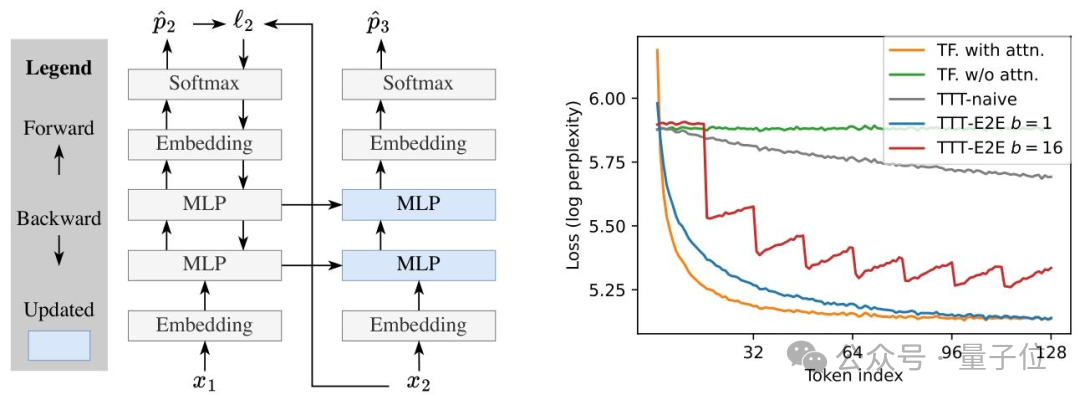
为了在效率与稳定性之间取得平衡,TTT-E2E还设计了三个关键优化策略:
- 迷你批处理+滑动窗口:将测试时的训练数据划分为多个迷你批次,并结合8K大小的滑动窗口注意力机制。这既缓解了单token梯度更新易导致数值不稳定的问题,又确保了模型能记住批次内的上下文,同时提升了计算的并行度。
- 精准更新策略:仅更新模型中的MLP层(冻结嵌入层、归一化层和注意力层),并且只更新网络最后1/4的块。这大幅减少了计算开销,同时避免了大规模参数更新带来的知识混乱。
- 双MLP设计:在需要更新的网络块中,设置两个MLP层。一个静态MLP专门用于保存预训练阶段学到的通用知识,另一个动态MLP则负责吸收和理解新的上下文信息。这种设计有效缓解了模型在学习新知识时“遗忘”旧知识的问题。
性能表现与局限
从实验结果来看,TTT-E2E的表现相当亮眼。
在参数量为3B的模型测试中,TTT-E2E在128K上下文长度下的测试损失与全注意力Transformer模型持平甚至更优。相比之下,Mamba 2、Gated DeltaNet等同样致力于高效长文本处理的模型,在长上下文场景下的性能均出现了明显下降。
在延迟方面,TTT-E2E的推理延迟几乎不随上下文长度的增加而增长,这一点与RNN模型类似。在H100显卡上处理128K文本时,其速度比全注意力模型快2.7倍。
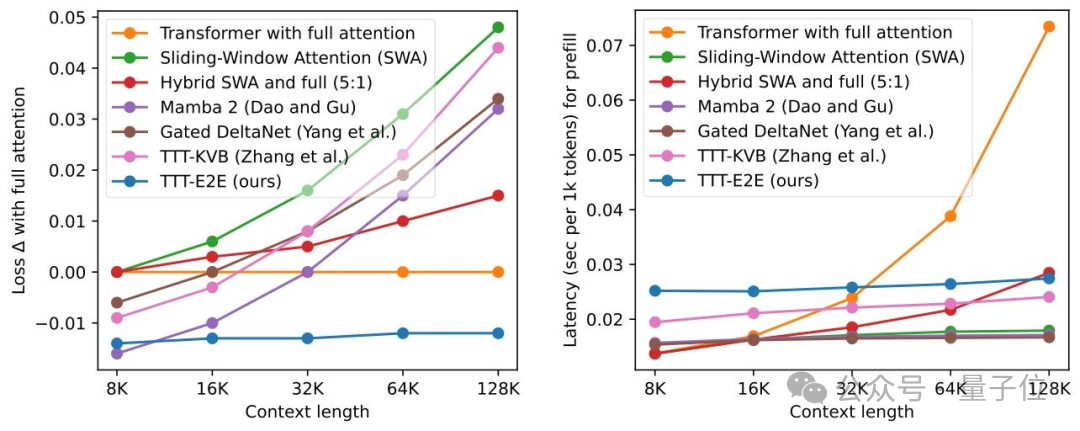
在生成长序列的解码任务中,基于Qwen-8B模型的评估显示,TTT-E2E生成的文本质量稳定,其损失值持续低于使用全注意力的传统模型。

实验结果也印证了,该方法的推理延迟与上下文长度无关,基本保持恒定。这意味着无论是处理8K还是128K的文本,用户都能获得近乎一致的快速响应体验。
当然,TTT-E2E也存在其局限性。
在“大海捞针”这类需要精确回忆文本中特定细节的任务中,它的表现远不如全注意力模型。这是因为它的核心是“压缩记忆”,会本能地过滤掉那些看似无关紧要的细节,而全注意力模型则能近乎无损地保留和召回所有信息。
另一方面,训练阶段的元学习需要计算梯度的梯度(二阶优化),目前的实现效率相比标准的预训练要低,计算成本更高。

目前,TTT-E2E的代码和相关论文已完全开源。这项研究的项目总负责人是斯坦福大学的博士后研究员Yu Sun,他也是该研究的核心贡献者。他的长期研究目标是让人工智能系统能够像人类一样持续学习。自2019年起,他就在持续开发“测试时训练”这一概念框架,TTT-E2E项目的早期构想便由他提出。
这一研究为大模型的长上下文处理提供了新的思路,其动态压缩和测试时学习的理念,值得广大开发者和研究者在云栈社区进一步探讨与实践。
论文地址:https://arxiv.org/abs/2512.23675
代码地址:https://github.com/test-time-training/e2e
参考链接:https://x.com/karansdalal/status/2010774529120092481
 发表于 2026-1-15 06:24:00
|
查看: 245|
回复: 0
发表于 2026-1-15 06:24:00
|
查看: 245|
回复: 0
