据外媒报道,芯片巨头英伟达正迎来一次关键的架构调整。在即将开幕的3月圣何塞GTC大会上,黄仁勋预计将发布一套全新的AI推理系统,其核心是一颗专为推理优化的新芯片。
引人注目的是,这款芯片的首位大客户已经敲定,正是刚刚完成巨额融资的OpenAI。而更关键的变化在于芯片的底层架构——它并非完全自研,而是基于收购获得的原Groq团队打造的LPU(语言处理单元)架构。
这意味着,英伟达第一次在核心AI算力产品线上,大规模引入外部架构设计。
这次“不自造”的背后,是去年那笔震动行业的交易:英伟达斥资约200亿美元,完成了对Groq核心技术与团队的“acqui-hire”(收购式招聘)。如今,这枚推理芯片正是那笔投资的首次落地。这依然是典型的黄仁勋式策略:购买成熟方案,快速部署,直接上战场。
是LPU,不是GPU
据《华尔街日报》披露,英伟达正在开发一个新的推理计算系统,该系统将结合Groq设计的芯片,并在GTC大会上正式发布。

与此同时,在OpenAI最新的融资文件中,这一计划已现端倪:
将扩大与英伟达的长期合作,包括使用3GW的dedicated inference capacity(专用推理算力),以及在Vera Rubin系统上提供2GW的训练算力。
如果计划顺利,这一“专用推理算力”极可能就是基于这颗新芯片。选择直接引入外部LPU架构,而非完全自研,与紧迫的时间窗口密切相关。近几个月来,OpenAI等头部客户已在积极寻找更高效率的推理替代方案。在推理需求迅速增长的背景下,英伟达需要更快给出针对性的解决方案。
那么,为什么这次用LPU,而非传统的GPU?核心原因在于推理场景的特殊性。GPU通常将大量模型参数存放在外部HBM(高带宽内存)中,计算核心与内存之间需要频繁进行数据搬运。在训练阶段,通过大规模并行可以摊薄这种搬运成本。
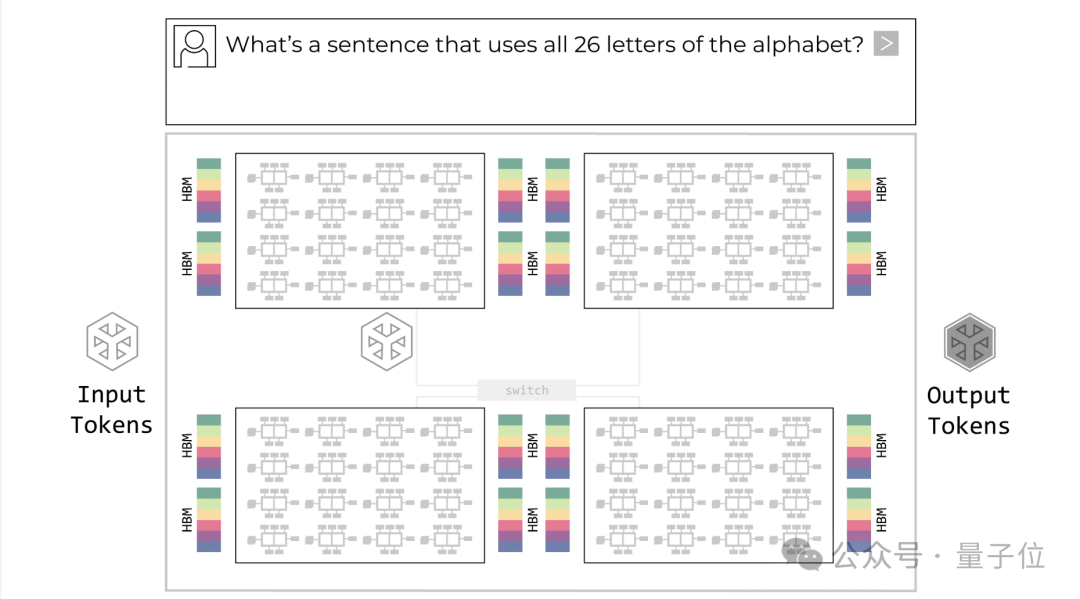
但在推理,尤其是生成(decode)阶段,请求批量变小、对延迟极为敏感,系统瓶颈更多来自数据移动而非算力本身。

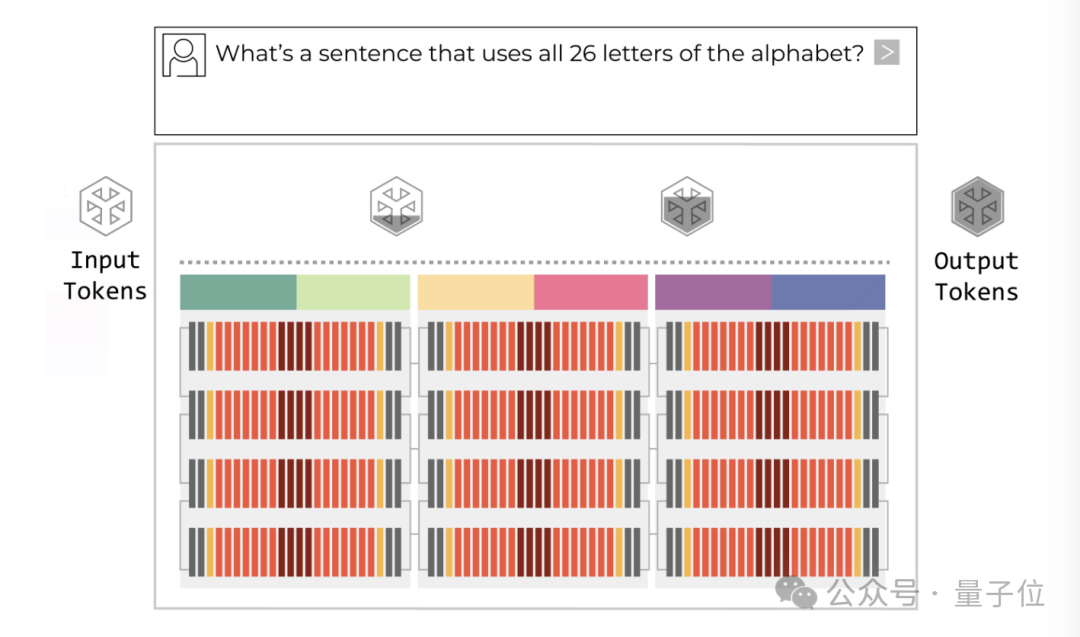
Groq的LPU架构改变了这一逻辑。它采用高密度片上SRAM,将数据“紧贴算力单元存放”,极大缩短了数据路径,从架构层面降低了延迟与能耗,更适配低延迟推理场景,理论速度可比GPU快10倍甚至更多。这标志着AI推理正在进入一个追求极致效率的新阶段。
随着AI Agent应用逐渐普及,整个智能算力的结构正在从“训练优先”向“推理优先”转移。推理不再只是训练后的补充环节,而成为规模更大、频率更高的长期负载。如果英伟达正式将LPU纳入核心产品线,这不仅是一款新芯片的发布,更是对算力市场重心转移的明确回应。
这也解释了为何英伟达不惜重金收购Groq,并引入其创始人Jonathan Ross(谷歌TPU之父)等核心成员。

可以说,推理市场正在重塑算力格局,而英伟达必须拿下这个新战场。
英伟达在推理芯片市场面临挑战
过去一年,随着Agent应用爆发,市场对算力的需求结构发生了明显变化:重心从训练转向推理。训练固然重要,但推理的调用频率更高、规模更大,成本开始成为核心考量。
一些领先的AI服务商已经开始将训练与推理分开部署——训练继续使用英伟达GPU,推理则转向更具性价比的专用芯片。例如,上个月,OpenAI与Cerebras签署了价值数十亿美元的计算合作协议。Cerebras主打推理优化芯片,其首席执行官公开表示,其芯片在特定场景下快于英伟达GPU。
Anthropic则更多依赖Amazon Web Services与Google Cloud的自研芯片来支持模型运行。Meta也与AMD达成了大规模芯片订单合作,双方正在联合优化用于推理任务的GPU架构,以减少对单一供应商的依赖。

在国内市场,模型公司同样开始探索本土算力方案。有消息称,DeepSeek甚至直接将DeepSeek V4的早期访问权限授予华为,并已在昇腾平台完成模型迁移。根据Bernstein Research的预测,到2026年,华为在中国AI芯片市场的份额可能达到50%,而英伟达的份额或降至个位数。
与此同时,英伟达的其他竞争对手也在强化推理专用架构的布局。早已布局TPU的谷歌,以及在OpenAI融资计划中拿下计算生态合作权的亚马逊,都在推动自研芯片在高频推理场景中的落地。国内如字节、阿里、百度等大厂也开始亲自下场造芯。
趋势已经非常清晰:推理成为主战场,而客户正在积极分散供应链风险。那么,为什么传统GPU不那么适合推理呢?因为训练追求的是“大规模并行”和总吞吐量,而推理,尤其是生成阶段,追求的是“单token速度”和稳定低延迟。
具体来说,推理分为两个阶段:pre-fill(处理用户输入)和decode(逐token生成输出)。真正决定用户体验的是第二步——低延迟生成。此时的系统瓶颈往往不在计算能力,而在频繁的数据存取与搬运。GPU架构虽强,但为并行计算设计;LPU则针对性地调整了存储与计算的路径,更贴合推理负载。
正因如此,有评论认为,这是AI浪潮以来,英伟达第一次在核心硬件层面面临实质性的架构挑战。虽然英伟达仍占据全球GPU市场的绝大部分份额,Hopper、Blackwell以及即将登场的Rubin系列依旧是训练主力,但面对爆发式增长的推理需求,英伟达也必须给出正面回应。而这枚基于LPU的芯片,就是他们交出的答案。
One More Thing
除了这枚备受关注的LPU推理芯片,黄仁勋之前还曾透露,在今年GTC大会上将发布“世界前所未见”的新系列产品。外界普遍猜测可能包括:Rubin系列新一代GPU,或代号为“Feynman”的全新架构芯片。
无论最终发布什么,AI算力市场的竞争无疑正在进入一个更加多元化、专业化的新阶段。对于这场即将到来的架构之争,你有什么看法?欢迎到云栈社区的开发者广场板块,与大家一起交流讨论。
参考链接:
[1]https://www.wsj.com/tech/ai/nvidia-plans-new-chip-to-speed-ai-processing-shake-up-computing-market-51c9b86e?st=SdUxv4&reflink=desktopwebshare_permalink
[2]https://nvidianews.nvidia.com/news/rubin-platform-ai-supercomputer?ncid=no-ncid
[3]https://berttempleton.substack.com/p/nvidias-blackwell-ultra-and-vera
 发表于 2026-3-3 13:41:21
|
查看: 132|
回复: 0
发表于 2026-3-3 13:41:21
|
查看: 132|
回复: 0
