本论文由北京大学硕士生安睿川担任第一作者,由张文涛教授与鄂维南院士共同指导。研究方向主要包括统一生成理解模型、以数据为中心的AI。拥有NeurIPS、ICLR、ECCV等4篇一作或共同一作论文,曾在微软亚洲研究院实习。项目通讯作者由北京大学张文涛教授担任。
在AGI-Next前沿峰会上,姚顺雨曾提出一个尖锐的观点:大模型迈向高价值应用的核心瓶颈,其实在于能否「用好上下文(Context)」。OpenAI的Jiayi Weng也在近期的访谈中表达了类似的洞察:上下文决定了模型与人类认知的边界。当信息不对等被消除,普通人也能胜任顶尖工作——本质上,是上下文的处理能力拉开了智力的差距。
正是在这种共识下,混元与复旦团队发布的CL-Bench显得尤为重要。它建立了一个标杆,严苛地审视了模型在长程交互中「学习新知识」的能力。
但故事到这里就结束了吗?
CL-Bench精彩地解决了「输入端」的理解难题,但在「输出端」的生成环节,我们发现了另一块更为棘手的拼图:如果上下文不仅是用来「学」的知识,而是对「创造」行为的复杂束缚,模型还能游刃有余吗?
这正是我们提出GENIUS (Generative Intelligence Evaluation Suite) 的初衷。

从「晶体」到「流体」:生成式AI的范式跃迁
目前的生成式多模态大模型无疑是强大的。但这种强大,更多体现为一种晶体智力。
所谓晶体智力,是指运用过去学习或经验获得知识的能力。现在的模型通过海量数据拟合,习得了惊人的晶体智力,它们能生成一只完美的「猫」,因为它们在训练期间见过数十亿个实例,然后在推理期间进行概率性再现。
但在真实世界里,用户的需求是异想天开的,上下文是动态变化的。模型往往需要根据当前独特的、新奇的情境进行「随机应变」的推理。这对应的正是流体智力。
GENIUS的核心使命,就是剥离掉模型对「画一只更逼真的狗」这类晶体智力的依赖,转而从「生成式流体智力」的维度,去评估模型在生成侧是否具备真正的通用智能。
GENIUS基准:解构生成式流体智力
我们构建了一个包含510个专家级样本、涵盖20个子任务的评测集。每个样本都由多模态交织的上下文组成,且经过精心设计:只要去掉上下文中的任何一种模态或者内容,任务就变得不可解。这确保了模型必须真正「读懂」并整合所有线索,而难以靠猜或预训练知识来蒙混过关。
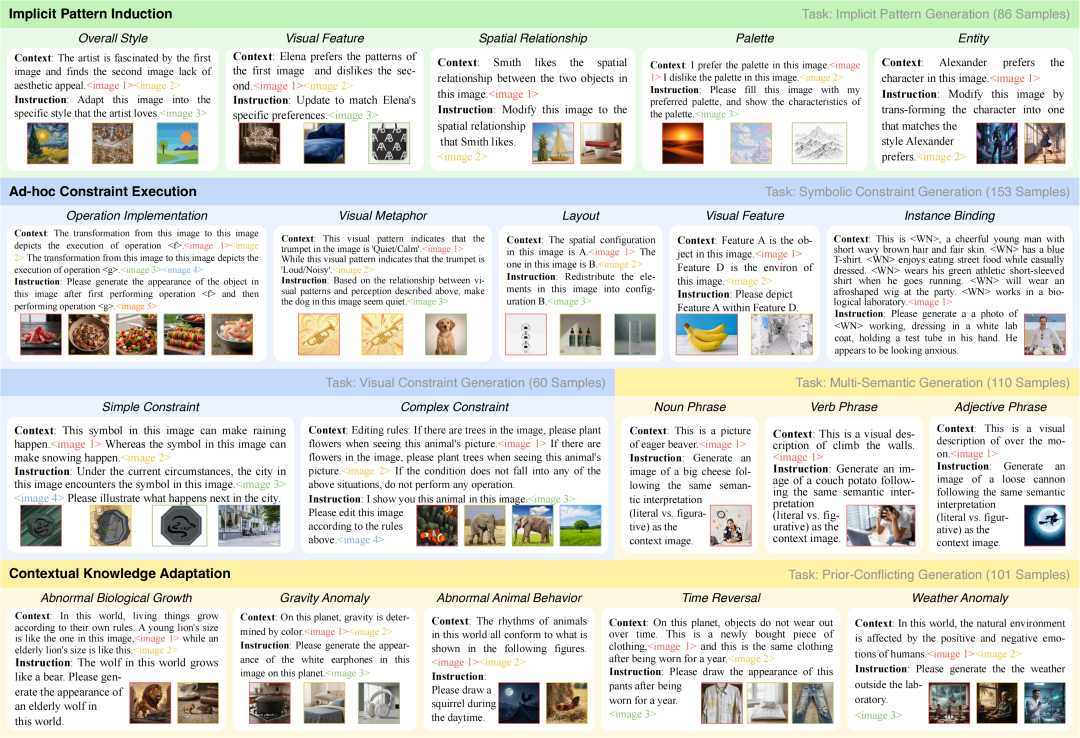
基准主要考察模型在以下三个维度的能力:
隐式模式归纳
人类具有一种直觉:能够从稀疏的观察中敏锐地捕捉到那些「只可意会不可言传」的潜在规律。在GENIUS中,我们考察模型能否在没有明确指令的情况下,从上下文中意会出隐式的特征(比如对特定风格、图案的偏好),并将其泛化到新的生成任务中。
执行即时约束
即理解并执行临时的、非训练分布内的复杂逻辑。这对人类来说并非难事,就像经典的思维训练题,「将水果定义为数字进行四则运算」;或者在编程中,「将一个抽象符号定义为某种特定操作」。GENIUS测试模型能否在临时定义的符号体系下,进行严格的逻辑推理与精确执行,而非依赖记忆中的常识关联。
适应上下文知识
它强调模型必须克服预训练带来的「认知惯性」,抑制住调用内部常识的冲动,去适应反直觉的上下文设定。例如,当GENIUS定义了一个「重力由颜色决定」的虚构世界时,模型需要像人类一样通过「思维实验」暂停对现实物理规律的信奉,完全基于这一反事实预设进行想象与创造。这尤其考验模型的上下文学习与知识适应能力。
部分实验结果分析
我们在12个最先进的模型(涵盖闭源SOTA与开源的生成式多模态大模型)上进行了评测。量化结果揭示了当前生成式模型在流体智力上的显著短板。
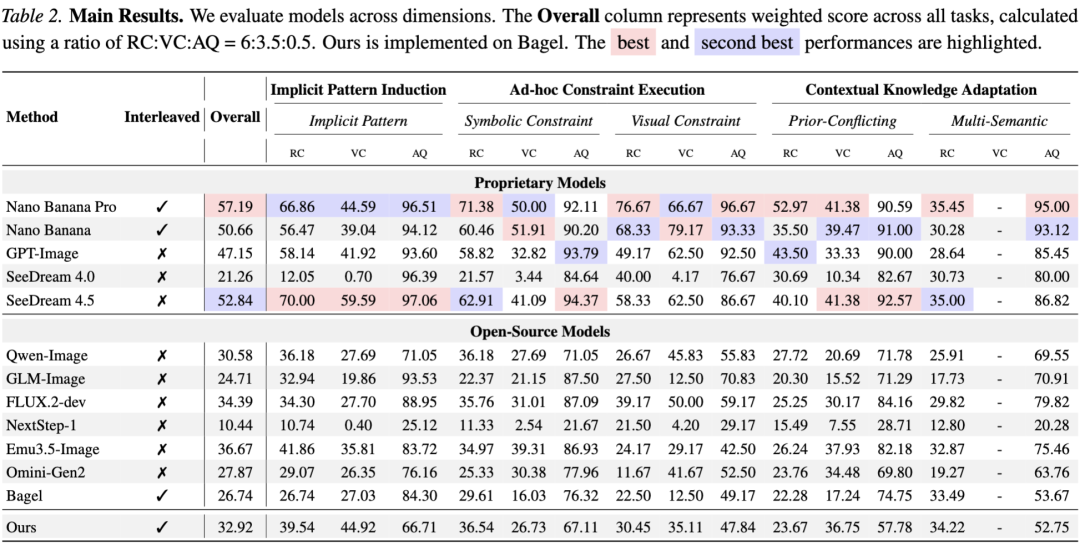
1. 晶体智力与流体智力的割裂
实验数据显示,即便是目前最强大的模型(如Nano Banana Pro),在GENIUS上的平均表现也远未达到及格线。这表明,模型在海量数据中习得的「知识储备」(晶体智力),并不能直接迁移为解决新颖问题的「推理能力」(流体智力)。
2. 预训练知识的阻力
在三大维度中,「适应上下文知识」的准确率普遍最低。这证实了模型存在严重的预训练知识阻力。例如在「反重力」任务中,模型往往会忽略Context,顽固地生成符合现实物理规律的图像。这说明当前模型的思维具有很强的僵化性,缺乏人类那种在「现实」与「想象」模式间灵活切换的可塑性。
3. 故障诊断:为什么模型会不及格?
面对模型在流体智力上的溃败,我们并没有止步于分数的罗列,而是通过一系列诊断性实验,试图定位失效的根本原因。
常规推理增强策略的失效:面对复杂的推理任务,直觉告诉我们要让模型「多想一会儿」。然而,我们尝试了Pre-Planning(思维链模式)和Post-Reflection(测试时扩展,即生成-打分-再生成)等策略,结果却令人失望——带来的性能提升非常有限。这表明,GENIUS所考察的流体智力,现有的推理范式并不能很好地迁移到这种多模态的即时生成任务中。
上下文理解是核心瓶颈: 我们在上下文中引入人工编写的显式提示,模型(如Nano Banana Pro)的生成质量能够得到进一步提升。这种显式提示本质上源于人类对语境的深度解析。如果模型能够构建起类人的理解机制,这一瓶颈在理论上是可以突破的。
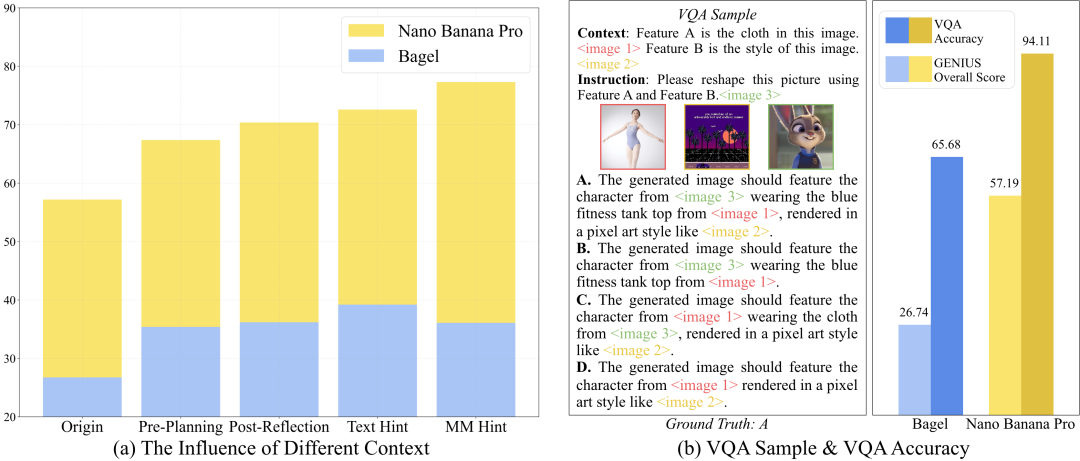
生成性失败主要源于执行能力不足,而不是理解能力缺陷: 为了验证模型对上下文的理解程度,我们将生成任务转换为视觉问答形式。实验结果显示,模型在理解类任务上的成功率较高,证明其已具备相当程度的语境感知。导致「知而不能画」的现象主要归结为以下两个因素:首先,交错上下文具有极高的数据密度,其中细粒度的视觉差异难以通过有限的模态编码完全捕获与表达。其次,当前通用多模态模型的结构设计在信息传递上存在损耗,导致理解侧丰富的语义信息无法有效传导至生成侧,形成了认知与创作之间的断层。
方法论:基于注意力的免训练增强

图:注意力分布观察。左:Bagel的注意力分布,右:我们改进后的注意力分布
基于上述诊断,我们进一步从底层机理探究了模型失效的根源。在多模态生成过程中,我们将生成图像的特征作为查询向量(Query),将图文交织的上下文作为键向量(Key),对注意力分布进行了可视化分析。结果表明,Bagel模型在处理图像时的注意力分布异常杂乱,呈现出大量不规律的噪声与随机的激增。
由此引出一个核心问题:注意力分布的偏移在多大程度上干扰了模型对上下文的理解?我们是否能通过对注意力权重进行轻量级调制,来实质性地提升模型的生成表现?
受到相关文献的启发,我们将「上下文学习本质上是一个隐式梯度更新过程」这一理论,在数学上严格推导并拓展至Bagel的架构中。从这一理论视角出发,高质量的上下文能够为这种隐式的「梯度下降」提供明确且精准的优化方向。然而,Bagel原生的注意力热力图揭示了一个致命缺陷:模型未能精确聚焦于上下文中必须关注的核心特征,其注意力权重呈现出无序的发散状态。这直接导致模型在隐式梯度更新时丢失了正确的下降路径。
针对这一困境,我们提出了一种免训练的注意力校准机制,强制引导模型将注意力收敛于关键的视觉与语义区域。定性与定量实验均证实,该方法能够有效纠正模型的优化轨迹并带来显著的性能增益,为该领域构建了一个简单的基线。
总结与展望:迈向真正的通用生成智能
GENIUS的提出,旨在回应生成式AI发展进程中的一个核心命题:我们究竟需要什么样的智能?
当前的生成式多模态大模型已经在晶体智力上取得了令人瞩目的成就:它们能够完美拟合海量数据分布,复现高质量的视觉内容。然而,GENIUS的评测结果揭示了繁荣背后的隐忧:一旦脱离了预训练的舒适区,面对需要即时推理、归纳与适应的流体智力任务,现有模型仍显稚嫩。
从「晶体智能的拟合」走向「流体智能的推理」,是生成式多模态大模型下一阶段发展的必经之路。在云栈社区这样的技术论坛,我们乐于看到更多关于前沿技术基准的深度讨论与实践分享。
GENIUS仅仅是一个开始。我们希望这一基准能为社区提供一个严谨的测试平台,推动生成式模型从熟练的「模仿者」,进化为具备真正通用推理能力的「思考者」。
引用
- [1] Learning without training: The implicit dynamics of in-context learning
- [2] GENIUS: Generative Fluid Intelligence Evaluation Suite
 发表于 2026-3-3 13:44:55
|
查看: 165|
回复: 0
发表于 2026-3-3 13:44:55
|
查看: 165|
回复: 0
