在 Linux 内核网络子系统中,sk_buff(常称 SKB)是一个无处不在的核心数据结构。它如同网络数据包的“灵魂载体”,从网卡驱动接收数据的那一刻起,直至应用程序最终读取,全程承载着数据包及其元信息。理解 SKB 的设计与运作机制,是深入掌握 Linux 网络体系、进行高性能网络编程和内核开发的基石。
核心概念详解
Socket Buffer 是什么
SKB 全名 struct sk_buff,是 Linux 内核网络子系统中最核心的数据结构。它的职责非常关键:作为一个统一的“载体”,在网络协议栈的各个层级之间高效地传递数据包及其状态信息。
当网卡驱动程序接收到数据时,数据立刻被封装进 SKB;随后,这个 SKB 会依次经过 IP 层、传输层的处理并向上传递;最终抵达应用程序。在整个过程中,SKB 本身作为一个容器基本保持不变,而其内部指向数据的指针和描述包状态的元数据,则会被各个协议层动态地读取和更新。
为什么需要 SKB
你可能会问,为什么不用简单的内存缓冲区来传递数据包呢?这背后是网络包处理复杂性的需求。一个网络包从物理网卡进入内核,需要经历:网卡驱动层 → MAC 层 → IP 层 → 传输层(TCP/UDP) → socket 缓冲区 → 应用程序。在这个链条的每一环,都需要:
- 读取和修改协议头:例如,IP 头中的 TTL 需要递减,TCP 头中的 ACK 序号需要更新。
- 跟踪包的状态:这个包来自哪个网卡?属于哪个 Socket?是否需要分片?
- 管理相关资源:什么时候释放内存?数据应该被复制还是共享?
- 支持高级功能:如 TSO(TCP Segment Offload)、GSO(Generic Segmentation Offload)、VLAN 标签处理等。
一个简单的缓冲区无法应对这些多维度的需求。SKB 的诞生,正是为了以统一、高效的方式,同时承载数据和丰富的元数据,让各层协议栈能够以最少的开销协同工作。
SKB 与其他网络层的关系
可以将其想象成一条生产流水线。数据包是流水线上的“产品”,每个工作站(网络协议层)都需要对其进行加工。SKB 就是那个托着产品的“智能托盘”,托盘上不仅放着产品,还贴着一张动态更新的“工艺单”(元数据),指示下一个工作站该如何处理。
- 网卡驱动:负责初始化这个托盘,设置源地址、目标地址等初始信息。
- MAC 层:读取托盘上的信息,决定数据链路层的转发策略。
- IP 层:修改 TTL,检查校验和,并决策这个包是发给本机还是需要转发。
- TCP/UDP 层:查看源端口、目标端口,将其关联到相应的 Socket。
- 应用程序:最终消费托盘中的产品(数据)。
这种设计的精妙之处在于:数据包在物理内存中的位置基本保持不动,各层协议栈只需操作“工艺单”(即移动指针、更新索引),从而极大地减少了昂贵的内存拷贝操作,提升了整体处理效率。想深入理解网络协议栈各层如何协同,可以参考 网络/系统 相关的技术讨论。
实现机制深度剖析
数据结构定义
SKB 的核心定义位于 include/linux/skbuff.h。一个完整的 struct sk_buff 结构体包含数百个字段,我们可以按功能分类来理解其核心部分:
// 简化的 sk_buff 结构体框架(仅展示核心字段)
struct sk_buff {
// ========== 链表与控制信息 ==========
struct sk_buff *next; // 用于组织成链表(已逐步被 skb_queue 替代)
struct sk_buff_head *list; // 所属的 SKB 队列
struct sock *sk; // 关联的 socket 结构
struct net_device *dev; // 网络设备(收包时: 源设备;发包时: 目标设备)
struct net_device *input_dev; // 接收包的网络设备
// ========== 数据缓冲区指针 ==========
unsigned char *head; // 缓冲区的起始地址
unsigned char *data; // 当前协议层的数据起始位置
unsigned char *tail; // 数据的末尾位置
unsigned char *end; // 缓冲区的末尾位置
// ========== 长度信息 ==========
unsigned int len; // 整个数据包的长度
unsigned int data_len; // 分页数据的长度(用于 frags)
unsigned int truesize; // 整个 SKB 占用的总内存(包含元数据)
// ========== 协议栈标记 ==========
__u16 protocol; // 协议号(ETH_P_IP, ETH_P_IPV6 等)
__u16 transport_header; // 传输层头在 data 中的偏移
__u16 network_header; // IP 层头在 data 中的偏移
__u16 mac_header; // MAC 层头在 data 中的偏移
// ========== SKB 分页支持(零复制技术) ==========
struct skb_shared_info *shinfo; // 分页数据、分片信息等
// ========== 其他控制字段 ==========
__u8 pkt_type; // 包的类型(PACKET_HOST, PACKET_BROADCAST 等)
__u16 queue_mapping; // 多队列网卡的队列号
unsigned long _skb_refdst; // 路由缓存引用
// ========== 时间戳与状态 ==========
ktime_t tstamp; // 包的时间戳
unsigned int mark; // netfilter 标记, 用于数据包分类
};
这个结构体本身的大小通常在 200 字节以上(不包括实际数据),看起来有些“重量级”。但考虑到它承载的数据可能超过 1500 字节,并且精心组织的字段布局能有效利用 CPU 缓存,这个开销是完全值得的。
内存布局与数据组织
理解 SKB 的内存布局是理解其高效性的关键。一个 SKB 对象的内存不是单一连续块,而是由元数据区和数据缓冲区等多个部分组成。
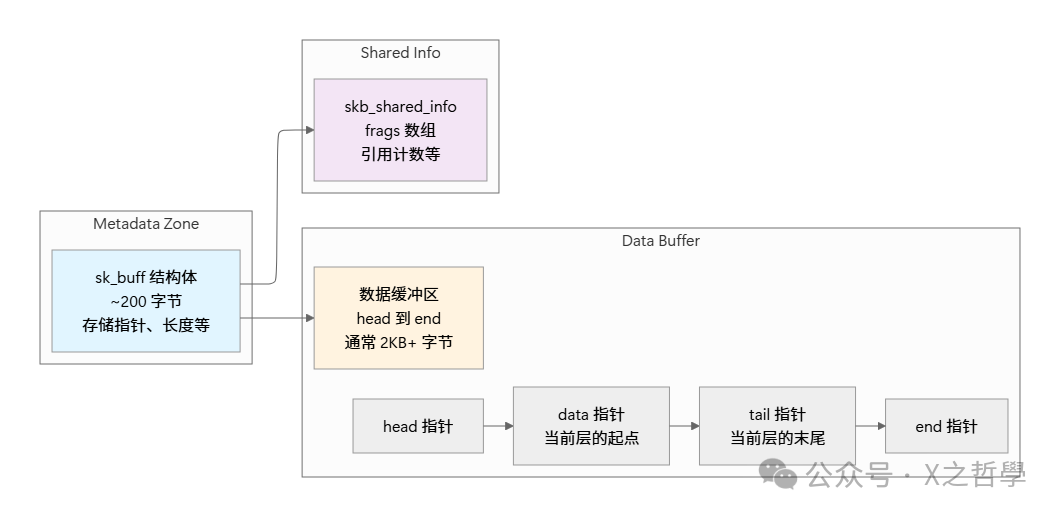
一个完整的网络包在内存中的典型布局如下所示:
┌─────────────────────────────────────────────────────┐
│ sk_buff 结构体 (200+ 字节) │
│ • head、data、tail、end 指针 │
│ • protocol、transport_header、network_header │
│ • sk、dev、tstamp 等元数据 │
└──────────────────┬──────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────┐
│ 数据缓冲区 │
├──────────────┬──────────────┬──────────┬───────────┤
│ 预留空间 │ MAC 头 │ IP 头 │ TCP/UDP │
│ (headroom) │ (14 字节) │ (20字节) │ 头+ 数据 │
│ │ │ │ │
│◄─ head ──────► data ────────► tail ───────► end │
└──────────────┴──────────────┴──────────┴───────────┘
│
┌──────────┴──────────┐
▼ ▼
MAC 层读取 IP 层移动
MAC 头的起点 data 指针越过
MAC 头
核心要点在于:数据包在物理内存中的位置基本固定不变,各层协议栈通过移动 data 和 tail 指针来“进入”或“离开”各自的协议头区域。 这种“指针漫步”的设计优雅地避免了大量的数据复制,是高性能的关键。这涉及到对 内存管理 和指针操作的深刻理解。
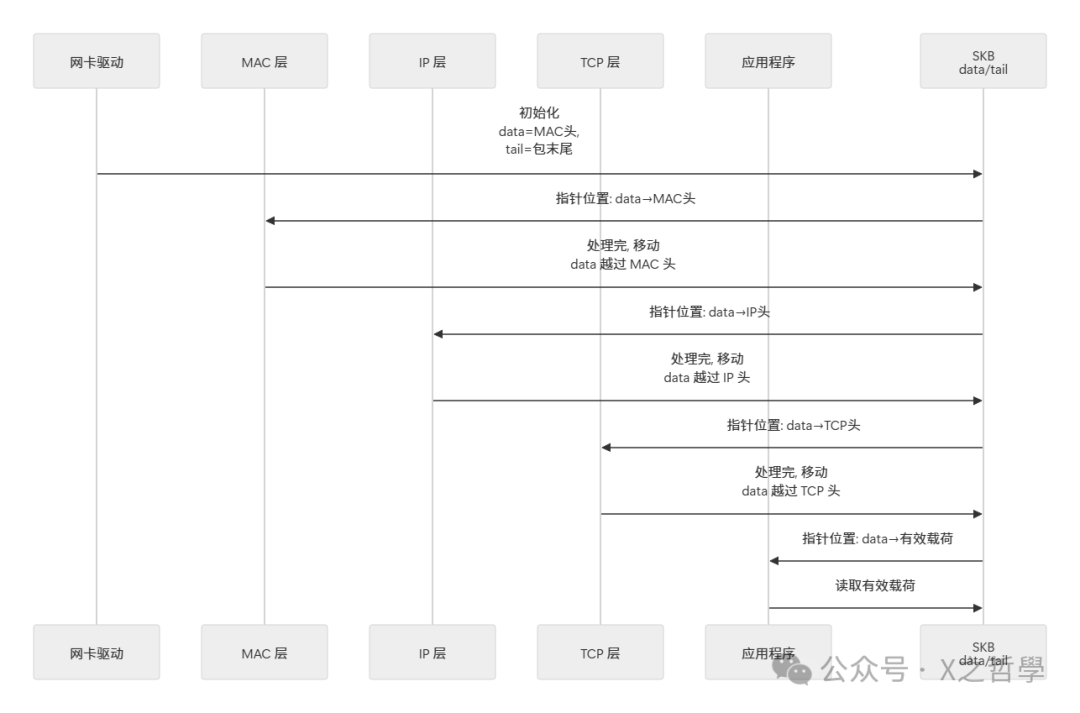
数据流动模型
那么,当一个网络包从网卡传送到应用程序时,SKB 内部的 data 和 tail 指针具体是如何变化的呢?下图清晰地展示了这一过程:
零复制与分页支持
现代高性能网络驱动面临一个关键挑战:如何在不复制数据的前提下,将网卡通过 DMA 接收到的数据高效地交给协议栈处理?SKB 的分页支持(frags 数组)正是这个问题的答案。
// skb_shared_info 结构(SKB 的扩展部分)
struct skb_shared_info {
__u8 __unused;
__u8 meta_len;
__u8 nr_frags; // 分页片段的个数
__u8 tx_flags;
unsigned short gso_segs; // GSO 分片段数(用于 TSO/GSO)
unsigned short gso_size; // GSO 分片大小
struct skb_frag_struct frags[MAX_SKB_FRAGS]; // 分页数组
struct skb_shared_hwtstamps hwtstamps;
unsigned int gso_type;
u32 tskey;
atomic_t dataref; // 引用计数
};
// 分页片段描述
struct skb_frag_struct {
struct {
struct page *p; // 指向物理页面
} page;
__u32 page_offset; // 页内偏移
__u32 size; // 分片大小
};
通过分页支持,网卡驱动可以直接将 DMA 接收到的数据存放在某个物理内存页上,然后在 SKB 的 frags 数组中记录这个页面的地址和偏移量,而无需将数据复制到新的缓冲区。当数据包流经协议栈时,各层可以直接访问这些原始页面中的数据。
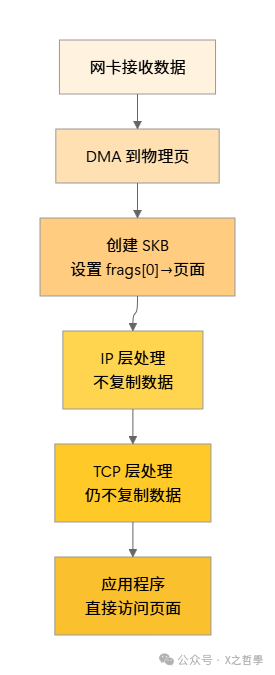
这就是“零复制”技术的精髓:数据在内存中保持不动,只有指向数据的指针和元数据在协议栈中飞速流转。
SKB 的生命周期与引用计数
SKB 作为内核中的一个动态对象,需要有明确的生命周期管理。虽然内核没有垃圾回收机制,但通过引用计数实现了类似的安全共享与释放。
// SKB 的引用计数管理
static inline struct sk_buff *skb_get(struct sk_buff *skb) {
refcount_inc(&skb->users); // 增加引用计数
return skb;
}
static inline void __kfree_skb(struct sk_buff *skb) {
// SKB 的实际销毁逻辑
skb_release_all(skb); // 释放所有关联资源
kfree(skb); // 释放 SKB 结构体本身
}
// 减少引用,如果为 0 则销毁
static inline void kfree_skb(struct sk_buff *skb) {
if (unlikely(!skb))
return;
if (likely(refcount_dec_and_test(&skb->users)))
__kfree_skb(skb);
}
SKB 的典型生命周期如下:
- 分配阶段:通过
alloc_skb() 或 dev_alloc_skb() 分配 SKB 对象及其数据缓冲区。
- 填充阶段:驱动程序或各个协议层向 SKB 中填充数据和元数据。
- 传递阶段:SKB 在协议栈各层、乃至多个消费者(如应用程序和 tcpdump)之间流转,各处可能同时持有其引用。
- 释放阶段:当所有引用都被释放,引用计数降为 0 时,SKB 及其关联资源被安全地回收或销毁。
这种基于引用计数的设计有效避免了频繁的内存分配与释放,提升了性能,也是 C/C++ 中资源管理思想的体现。
协议头指针的管理
为了在协议栈中快速定位,SKB 维护了几个关键的偏移量字段,用于记录各层协议头的位置。
// 在 sk_buff 中
__u16 transport_header; // 传输层头相对于 skb->head 的偏移
__u16 network_header; // 网络层头相对于 skb->head 的偏移
__u16 mac_header; // MAC 层头相对于 skb->head 的偏移
// 访问宏
#define skb_transport_header(skb) ((void *)(skb)->head + (skb)->transport_header)
#define skb_network_header(skb) ((void *)(skb)->head + (skb)->network_header)
#define skb_mac_header(skb) ((void *)(skb)->head + (skb)->mac_header)
// 类型转换获取结构体指针
#define ip_hdr(skb) ((struct iphdr *)skb_network_header(skb))
#define tcp_hdr(skb) ((struct tcphdr *)skb_transport_header(skb))
#define udp_hdr(skb) ((struct udphdr *)skb_transport_header(skb))
通过这种方式,任何一层协议栈都能以 O(1) 的时间复杂度直接定位到属于自己的协议头结构,无需从数据包起始处进行逐字节扫描。
设计思想与架构权衡
核心设计思想
SKB 的设计深刻体现了内核开发者对极致性能和良好模块化的追求。
- 对零复制的追求:在高吞吐量网络场景下,数据复制是主要的性能瓶颈之一。SKB 通过移动指针而非数据本身的设计,让各层协议栈都能“原地”处理数据,显著降低了 CPU 开销。
- 灵活的缓冲区设计:
head, data, tail, end 四个指针的组合提供了极大的灵活性。无论是发包时在前端插入协议头,还是收包时逐层剥离协议头,亦或是支持 TSO 等高级功能,SKB 都能优雅应对。
- 统一的元数据容器:将网络包在全局范围内需要的状态信息(来源设备、所属连接、处理标记等)集中存储在 SKB 中,避免了各层协议栈维护独立元数据结构的开销和复杂性。
- 支持多消费者:引用计数机制使得一个 SKB 可以安全地被多个上下文共享(例如,应用程序接收和网络抓包工具同时处理),实现了高效的数据共享。
设计权衡
当然,SKB 的设计也包含了一些权衡:
| 权衡方面 |
优点 |
缺点 |
| 指针操作 |
避免数据复制,极致高效 |
需要精心管理指针,编程模型复杂,易出错 |
| 元数据集中 |
统一访问,便于维护全局状态 |
SKB 结构体本身较大(200+字节),有一定内存开销 |
| 四指针缓冲设计 |
极其灵活,支持各种操作 |
概念复杂,容易混淆各指针的准确含义 |
| 引用计数 |
安全支持多消费者共享数据 |
需要正确维护引用,否则会导致内存泄漏或非法访问 |
与其他设计的对比
- BSD mbuf:BSD 系统使用
mbuf(memory buffer)结构。mbuf 更倾向于“链式”设计,支持多个 mbuf 链接成一个链表来表示一个数据包,灵活性高但复杂性也高。Linux 的 SKB 则更“扁平”,用分页(frags)代替链表,在现代硬件(尤其是有 DMA 支持的网卡)上通常表现更优。
- 用户态网络栈:在 DPDK、io_uring 等用户态网络方案中,数据包常保存在预分配的内存池中,应用直接操作,避免了系统调用和上下文切换开销。SKB 可以看作是内核态下的类似设计,但它需要处理内核与用户态边界带来的额外成本。
实践示例
场景一:编写网络过滤模块
假设我们要实现一个简单的内核模块,用于统计经过系统的 IP 数据包数量并打印源地址。这就需要直接操作 SKB。
// filter_module.c - 一个简单的网络过滤内核模块
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/netfilter.h>
#include <linux/netfilter_ipv4.h>
#include <linux/skbuff.h>
#include <linux/ip.h>
#include <linux/inet.h>
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Network Developer");
MODULE_DESCRIPTION("Simple packet statistics module");
static unsigned long packet_count = 0;
static unsigned long dropped_count = 0;
// Netfilter hook 处理函数
static unsigned int packet_filter_hook(void *priv,
struct sk_buff *skb,
const struct nf_hook_state *state) {
struct iphdr *iph;
__be32 saddr, daddr;
// 检查 SKB 是否有效
if (!skb) {
return NF_ACCEPT;
}
// 确保 IP 头在线性缓冲区中
// skb_linearize() 会在必要时复制分页数据到线性缓冲区
if (skb_is_nonlinear(skb)) {
if (skb_linearize(skb) != 0) {
dropped_count++;
return NF_DROP;
}
}
// 获取 IP 头指针
iph = ip_hdr(skb);
// 检查 IP 头长度是否合法
if (!pskb_may_pull(skb, sizeof(struct iphdr))) {
dropped_count++;
return NF_DROP;
}
saddr = iph->saddr;
daddr = iph->daddr;
packet_count++;
// 打印源 IP 和目标 IP(每 100 个包打印一次,避免日志过多)
if (packet_count % 100 == 0) {
printk(KERN_INFO "Packet %lu: SRC=%pI4 DST=%pI4 Protocol=%u\n",
packet_count,
&saddr,
&daddr,
iph->protocol);
}
return NF_ACCEPT;
}
// Netfilter hook 结构体
static struct nf_hook_ops packet_filter_ops = {
.hook = packet_filter_hook,
.pf = PF_INET,
.hooknum = NF_INET_PRE_ROUTING, // 在路由之前处理
.priority = NF_IP_PRI_FILTER,
};
// 模块初始化
static int __init packet_filter_init(void) {
int ret;
ret = nf_register_hook(&packet_filter_ops);
if (ret < 0) {
printk(KERN_ERR "Failed to register netfilter hook\n");
return ret;
}
printk(KERN_INFO "Packet filter module loaded\n");
return 0;
}
// 模块卸载
static void __exit packet_filter_exit(void) {
nf_unregister_hook(&packet_filter_ops);
printk(KERN_INFO "Packet filter module unloaded\n");
printk(KERN_INFO "Total packets: %lu, Dropped: %lu\n",
packet_count, dropped_count);
}
module_init(packet_filter_init);
module_exit(packet_filter_exit);
编译运行命令:
# 编译模块(路径需根据实际环境调整)
gcc -c -Wall -DMODULE -D__KERNEL__ \
-I/lib/modules/$(uname -r)/build/include \
filter_module.c -o filter_module.o
# 加载模块
sudo insmod filter_module.ko
# 查看内核日志
dmesg | tail -20
# 卸载模块
sudo rmmod filter_module
代码解析:
ip_hdr(skb) 宏通过 SKB 的 network_header 偏移快速获取 IP 头指针。skb_is_nonlinear() 检查 SKB 是否包含分页数据;skb_linearize() 在必要时将分页数据复制到线性缓冲区以简化处理。pskb_may_pull() 确保 SKB 的线性部分包含完整的 IP 头。- 通过
ip_hdr() 获取的 iphdr 指针,可以直接访问所有 IP 头字段。
场景二:手动构造发送用的 SKB
以下示例展示如何手动构造一个 ICMP Echo Request(ping)包。
// 构造一个 ICMP Echo Request(ping)包
struct sk_buff *create_ping_skb(unsigned int saddr, unsigned int daddr) {
struct sk_buff *skb;
struct iphdr *iph;
struct icmphdr *icmph;
unsigned char *data;
int ip_header_len = sizeof(struct iphdr);
int icmp_header_len = sizeof(struct icmphdr);
int payload_len = 32;
int total_len = ip_header_len + icmp_header_len + payload_len;
// 分配 SKB: 预留 LL_RESERVED_SPACE 字节的 headroom(给驱动使用)
skb = alloc_skb(LL_RESERVED_SPACE(dev) + total_len + dev->needed_tailroom,
GFP_ATOMIC);
if (!skb) {
return NULL;
}
// 设置网络设备
skb->dev = dev;
// 预留 headroom(给 MAC 层和驱动使用)
skb_reserve(skb, LL_RESERVED_SPACE(dev));
// 推进 tail,为 IP 头腾出空间并获取指针
iph = (struct iphdr *)skb_put(skb, ip_header_len);
// 填充 IP 头
iph->version = 4;
iph->ihl = 5; // IP 头长度(以 32-bit 字为单位)
iph->tos = 0;
iph->tot_len = htons(total_len);
iph->id = htons(0x1234);
iph->frag_off = 0;
iph->ttl = 64;
iph->protocol = IPPROTO_ICMP;
iph->check = 0; // 校验和先设为 0
iph->saddr = saddr;
iph->daddr = daddr;
// 计算 IP 头校验和
iph->check = ip_fast_csum((unsigned char *)iph, iph->ihl);
// 推进 tail,为 ICMP 头腾出空间并获取指针
icmph = (struct icmphdr *)skb_put(skb, icmp_header_len);
// 填充 ICMP 头
icmph->type = ICMP_ECHO;
icmph->code = 0;
icmph->checksum = 0;
icmph->un.echo.id = htons(1234);
icmph->un.echo.sequence = htons(1);
// 推进 tail,为有效载荷腾出空间并获取指针
data = skb_put(skb, payload_len);
memset(data, 'A', payload_len);
// 计算 ICMP 校验和(包含头部和载荷)
icmph->checksum = ip_compute_csum((unsigned char *)icmph,
icmp_header_len + payload_len);
// 设置协议和协议头偏移
skb->protocol = htons(ETH_P_IP);
skb_set_network_header(skb, 0); // IP 头在 data 的起点
skb_set_transport_header(skb, ip_header_len); // ICMP 头在 IP 头之后
return skb;
}
这个例子展示了:
alloc_skb() 分配 SKB 及数据缓冲区。skb_reserve() 在数据区前端预留空间(headroom)。skb_put() 推进 tail 指针以扩展数据区,并返回新空间的指针用于填充。skb_set_network_header() 和 skb_set_transport_header() 记录各层协议头的位置。- 手动计算 IP 和 ICMP 校验和是构造合法网络包的必要步骤。
调试工具与技巧
调试 SKB 相关的问题通常需要多种工具协同:
| 工具/命令 |
主要用途 |
示例 |
gdb |
内核调试,查看 SKB 结构体字段 |
gdb vmlinux 后 p *(struct sk_buff *)0xaddr |
crash |
分析内核转储(dump),检查 SKB |
crash vmlinux vmcore 后 skb <addr> |
kprobes/tracepoints |
动态追踪 SKB 生命周期事件 |
echo 'p:skb_alloc alloc_skb size=%di' > .../kprobe_events |
perf |
性能分析,定位 SKB 处理热点 |
perf record -g -e skb:skb_copy_datagram_iovec |
tcpdump/wireshark |
抓包验证内容 |
tcpdump -i eth0 -vv |
ethtool -S |
查看网卡统计信息(包括丢包) |
ethtool -S eth0 |
ss/netstat |
查看 Socket 和连接状态 |
ss -tuapn |
使用 kprobes 追踪 SKB 分配:
# 创建一个 kprobe,在 alloc_skb() 入口处插入追踪点
echo 'p:skb_alloc alloc_skb size=%di' > /sys/kernel/debug/tracing/kprobe_events
# 启用追踪
echo 1 > /sys/kernel/debug/tracing/events/kprobes/skb_alloc/enable
# 查看实时输出
cat /sys/kernel/debug/tracing/trace_pipe
# 清理
echo > /sys/kernel/debug/tracing/kprobe_events
使用 crash 分析内核转储:
crash vmlinux vmcore
crash> skb <address> # 查看指定地址的 SKB 结构体
crash> kmem -s sk_buff # 查看 sk_buff 类型的内存使用统计
crash> net -s # 查看网络子系统的统计信息
架构总览
在 Linux 网络栈中,SKB 是数据流的核心承载者。整个网络处理流程可以视为 SKB 在不同模块间的流转与状态转换。
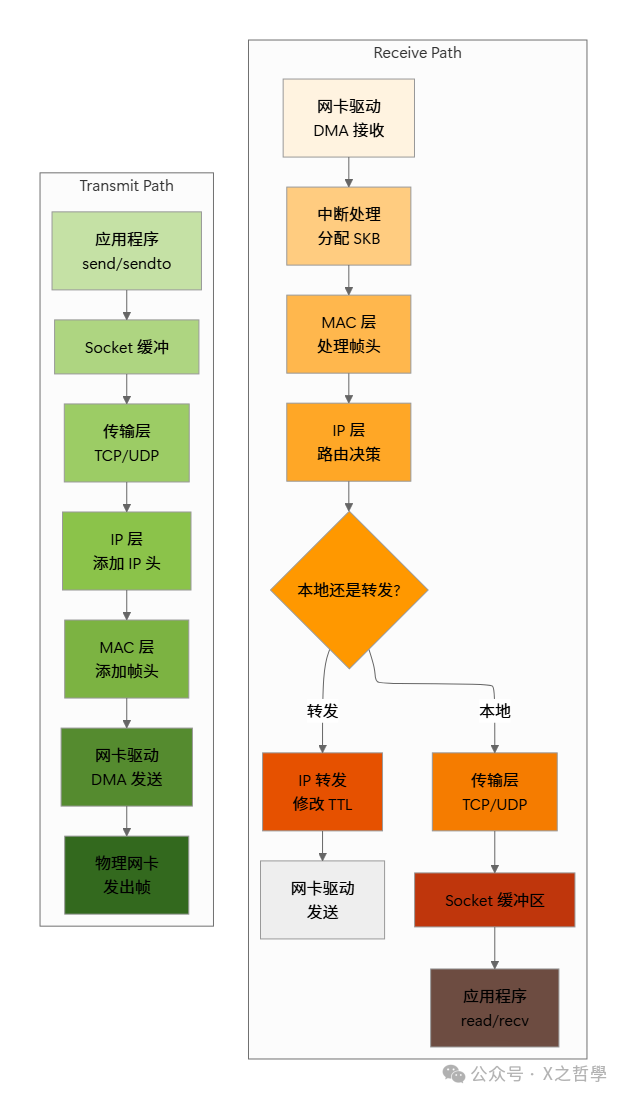
在这个全景图中:
- 接收路径:网卡驱动创建 SKB,填充初始数据;各层协议栈依次处理,最终递送给应用程序。
- 转发路径:IP 层判断目的地址非本机,修改 TTL 和校验和后,直接转发给输出网卡。
- 发送路径:应用程序数据经各层封装协议头,最终由驱动通过 DMA 发送。
SKB 作为一致性的载体,确保了每一层都能准确地定位并处理属于自己的那部分数据。
SKB 与其他内核子系统的交互
SKB 并非孤立存在,它与内核的多个子系统紧密耦合,共同构成完整的网络处理引擎。
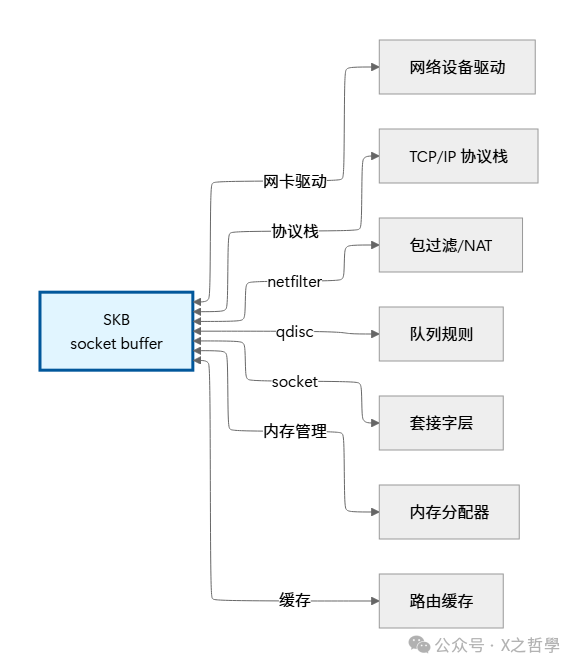
总结
Linux 内核中的 sk_buff (SKB) 是网络栈高效运转的“活力之源”,其精妙设计系统性地解决了网络包处理中的一系列核心问题:
| 技术挑战 |
SKB 的解决方案 |
带来的收益 |
| 数据与元数据的统一管理 |
在单一结构体中集成数据指针和全栈状态 |
协议栈各层能快速定位所需信息和数据 |
| 高效的包处理(零复制) |
通过指针操作和分页支持替代数据复制 |
大幅降低 CPU 开销,提升吞吐量 |
| 灵活的缓冲区操作 |
head, data, tail, end 四指针设计 |
完美支持从 MAC 层到应用层的各种操作需求 |
| 驱动多消费者场景 |
引用计数 + 内存池机制 |
安全支持如 tcpdump 和应用程序同时处理数据包 |
| 高级功能支持(TSO/GSO) |
分页结构 (frags) + GSO 相关字段 |
高效处理大报文,卸载 CPU 负担 |
| 性能观测与调优 |
丰富的统计字段和内建追踪点 |
便于定位性能瓶颈,进行深度优化 |
深入理解 SKB,不仅能帮助开发者编写更高效、更底层的网络程序,更能带来以下深层次收益:
- 透彻理解网络包的生命周期:从硬件中断到用户态读取,数据与状态如何流转。
- 掌握内核网络性能优化的钥匙:明晰零拷贝、分页、缓存等高级优化手段的实现原理。
- 获得调试复杂网络问题的利器:当出现丢包、延迟、错序等问题时,能通过分析 SKB 的状态快速定位根因。
- 学习系统设计的权衡智慧:SKB 在面对复杂性、性能和资源开销时的设计取舍,是值得借鉴的宝贵经验。
希望这篇对 Linux SKB 的深度解析能帮助你在 云栈社区 的技术探索之路上更进一步。无论是进行内核开发、高性能网络编程,还是单纯为了深入理解操作系统,掌握 SKB 都是至关重要的一步。
 发表于 2026-1-15 08:16:43
|
查看: 283|
回复: 0
发表于 2026-1-15 08:16:43
|
查看: 283|
回复: 0
