当全行业还在争论30B模型能否挑战万亿参数时,一个更激进的答案出现了:4B。没有万亿参数的算力堆砌,没有百万级数据的暴力灌入。
清华大学自然语言处理实验室、中国人民大学、面壁智能与 OpenBMB 开源社区联合研发的 AgentCPM-Explore 智能体模型,基于仅4B参数的底座,在深度探索类任务上取得了同尺寸模型的SOTA(State-of-the-Art)成绩。它不仅越级赶上甚至超越了部分8B级SOTA模型,更比肩了部分30B级以上模型和闭源大模型的效果,真正让大模型的长程任务处理能力有望部署于端侧设备。
AgentCPM-Explore 核心亮点一览
- 打破参数壁垒:首个具备在GAIA、Xbench、Browsecomp等8个主流长难智能体任务上处理能力的4B端侧模型,重新定义了小模型的性能天花板。
- 长程深度探索:最高可实现超过100轮不重复且稳定的环境交互,能够持续深度探索直至任务准确完成。
- 全流程开源:在开源模型的基础上,进一步开源了配套的工具沙盒统一管理调度平台 AgentDock、全异步强化学习训练框架 AgentRL、智能体能力一键式测评平台 AgentToLeaP,支持社区进行全流程复现与自定义扩展。
更高能力密度:端侧智能体模型 SOTA 表现
AgentCPM-Explore 在 GAIA、HLE、Browsecomp、Browsecomp(ZH)、WebWalker、FRAMES、Xbench-DeepResearch、Seal-0 这八大主流智能体评测基准上,均展现出了极致的参数效能比。
它不仅取得了同尺寸模型的SOTA,而且越级赶上甚至超越了两倍参数量(8B级)的SOTA模型,表现比肩部分30B级以上和闭源大模型。
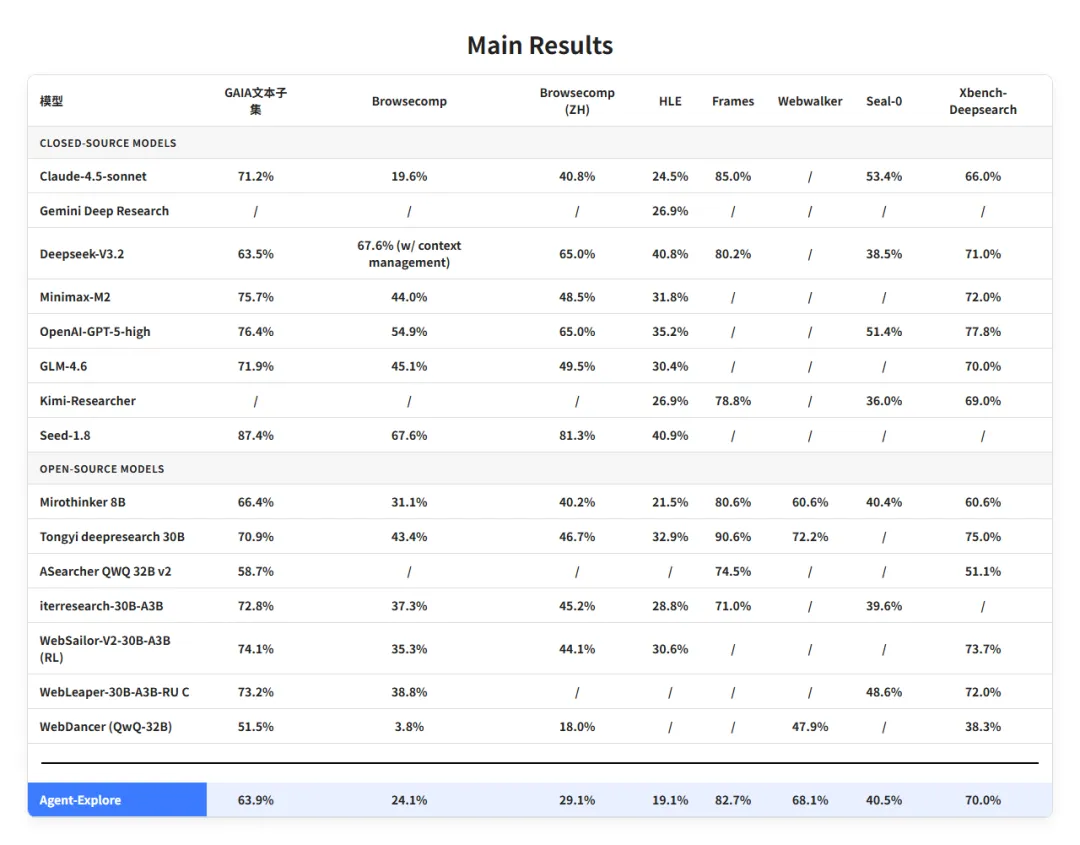
表1:AgentCPM-Explore在8个主流智能体评测任务上的表现榜单
特别是在 Xbench-DeepResearch 上,AgentCPM-Explore 的表现超越了 Claude-4.5-Sonnet 等闭源大模型,并显著超出了不同参数量级SOTA模型的表现趋势线,展现出了更高的能力密度。
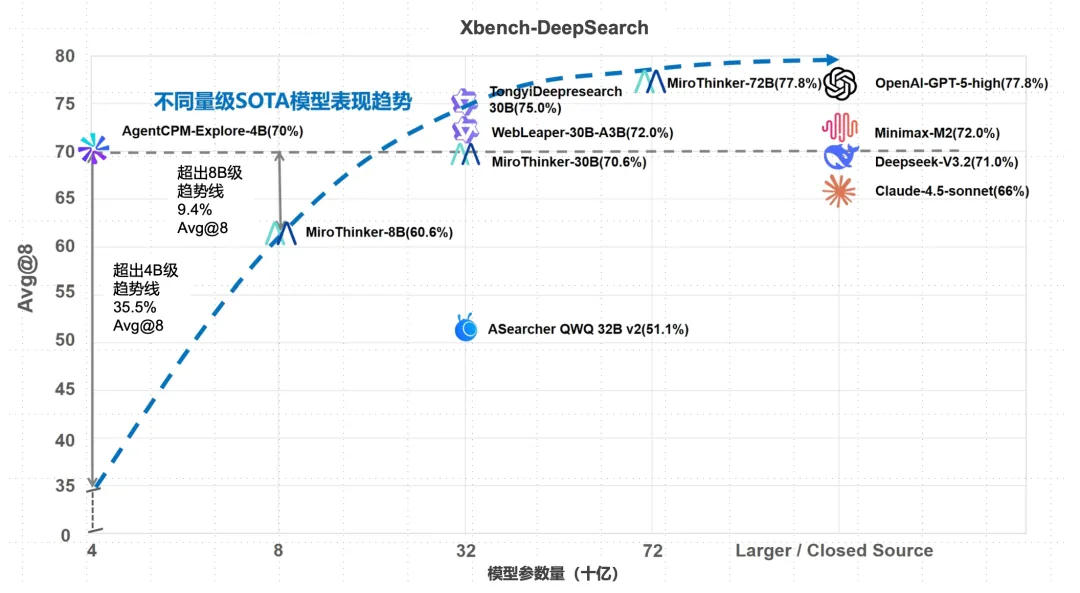
图1:Xbench-DeepSearch数据集模型表现效果分析(注:深度搜索任务通常存在较大的采样波动。AgentCPM-Explore及部分对比模型采用了高标准的Avg@8评估方式,相比业界的单次/3次设定,可将波动误差控制在2%以内,提供更真实、可复现的性能对比)
更宽能力边界:深挖端侧智能体模型极致潜能
4B端侧模型在GAIA上有希望做对几乎全部的题目! 如图所示,基于 AgentDock 和 AgentRL 基础设施下的稳定后训练,AgentCPM-Explore 实现了相较于基础模型 Qwen3-4B-thinking-2507 的成倍效果跃升。
在允许多次尝试(Pass@k)的情况下,AgentCPM-Explore 能够解决 GAIA 文本任务中 95% 以上的题目。这证明,小模型并非“能力受限”,而是“潜力被低估”。在正确的训练框架下,端侧模型完全具备解决绝大多数复杂难题的潜质。
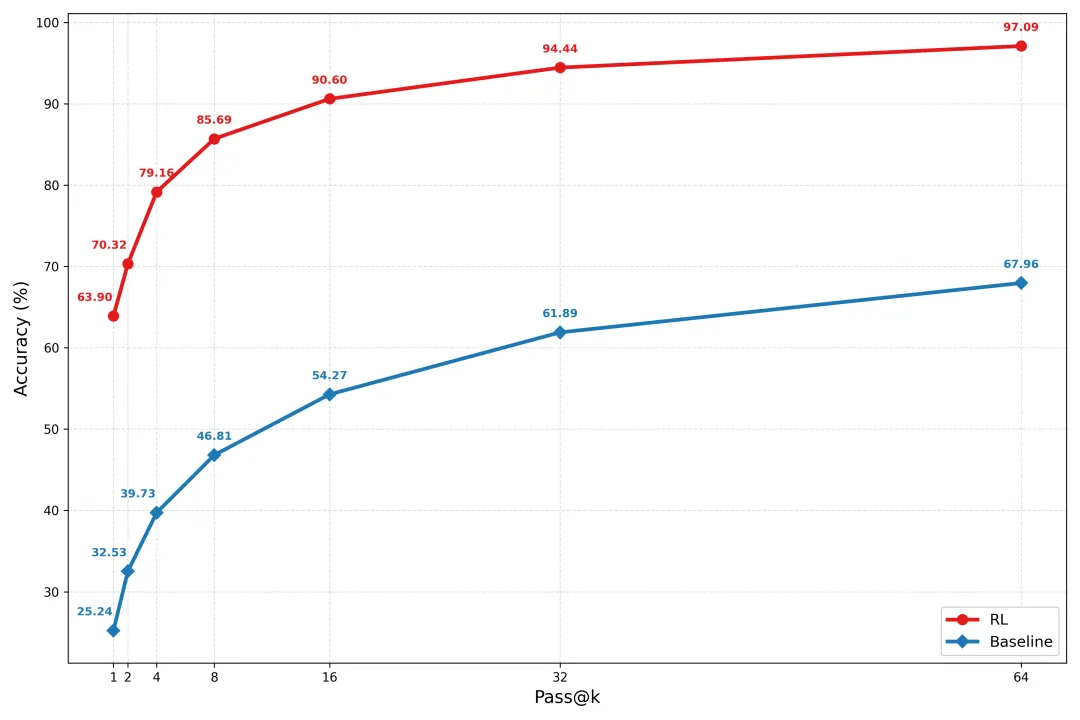
图2:基础模型 Qwen3-4B-thinking-2507 与经过后训练的 AgentCPM-Explore 在GAIA任务上的能力边界对比
更多智能行为:端侧智能体模型展现“类人”思考逻辑
在深度探索任务中,AgentCPM-Explore 打破了小模型“只会死记硬背”的刻板印象。面对“美国历届总统的出生地中,哪两个城市之间东西相距最远?”这一复杂地理历史交叉难题,它展现出了接近人类研究员的思考模式:
- 它会“质疑”:拒绝盲信工具。当发现初步搜索结果“Brookline, MA”被列为最东端时,它判断摘要可能遗漏了关键信息(如阿拉斯加州的总统出生地),果断要求重新核查全量数据。
- 它能“求真”:不满足于被压缩的二手信息,主动寻找完整版原始数据(如维基百科完整列表),确保决策基于事实全貌。
- 它懂“变通”:搜索不通就尝试爬取表格,路径不对就转向数据库搜索。它能从通用搜索引擎灵活切换到 GitHub 等平台进行精准定位,根据实时反馈调整问题解决策略。
- 它很“执着”:面对连续的搜索无果不会气馁,而是不断寻找替代信源,直到挖掘出最可靠的数据源为止。
全流程开源基建:支持自定义扩展
该项目不仅开源了模型,更开源了从 Base 模型(在GAIA上仅25.24%准确率)进化至 SOTA 模型(GAIA 63.90%)的全流程代码与工具链。
通过以下三大核心基础设施,开发者可以轻松复现性能翻倍的训练过程,并快速实现私有化部署与自定义功能扩展。
(1)AgentDock:工具沙盒统一管理调度平台
- 高并发工具集成:原生支持16个 MCP(Model Context Protocol)服务及百余种工具。通过多版本轮询与负载均衡机制,支持核心高频使用工具实现100+ QPS的高并发调用。
- 健全容错机制:实现输出标准化、自动重试、服务自愈及备用工具自动切换,确保长程任务持续运行的稳定性。
- 统一沙盒管理:实现任务分发、容器编排与动态路由的统一管控。智能体所在的客户端仅需关注“能力接口”,无需处理复杂的网络与并发细节,支持工具的热插拔与弹性扩缩容。
(2)AgentRL:极简高效的异步强化学习框架
- 零门槛接入:只需标准的 ChatCompletions 接口即可无缝接入训练流程。
- 极简代码架构:核心实现仅7个文件、1000余行代码,极大降低了学习与二次开发门槛,方便快速验证新想法。
- 全异步训推同卡:支持采样(推理)与训练在同一张GPU上以全异步流水线方式运行,极致压榨硬件性能。
- 解耦与并行:训练与采样完全解耦,采样进程可独立扩缩容。兼容 PyTorch 原生并行及 FSDP2、Tensor Parallel、Context Parallel 等高级并行策略,轻松支持 128K+ 长文本训练。
(3)AgentToLeaP:智能体能力一键式评测平台
- 一键全自动化:支持 GAIA、HLE 等8个主流评测榜单的一键自动化测评,一行命令即可启动从环境准备到结果输出的全流程。
- 模块化扩展:评测集独立管理,结果统一输出。开发者可参考文档,轻松接入自定义测试集。
端侧模型性能“以小博大”的关键点
4B模型有限的参数容量,在面对长周期、多交互的智能体任务时,容错空间极低。技术团队在实战中发现并探索出了应对三大核心挑战的有效方法。
以“模型融合”破解 SFT 过拟合。 小模型在监督微调(SFT)阶段极易陷入“死记硬背”。实验发现,仅调整Prompt中无关的工具描述,模型性能就会大幅下滑,这是典型的过拟合。为此,团队采用参数融合技术,将训练后的“专用模型”与训练前的“通用模型”进行加权融合。其机制在于:通专模型一致的泛化参数得以保留,互补的专业能力得以强化,而过拟合产生的随机噪音参数则在融合中相互抵消。实测显示,融合后的模型在智能体任务上性能提升约7%,有效实现了通专能力的平衡。
以“信号去噪”修正 RL 奖励偏差。 智能体任务的轨迹动辄数十步,小模型对长链路中的负面信号极其敏感。传统强化学习中,一旦长序列在最后一步出错,惩罚会回传至整条链路,导致中间正确的推理步骤也被“误伤”,可能致使模型训练崩塌。技术团队实施了严格的奖励信号去噪,筛选真正具备策略更新价值的轨迹。对于步骤很长但最终失败的样本,避免进行全轨迹惩罚,从而保护小模型已学到的正确推理逻辑,维护训练稳定性。
以“信息精炼”对抗推理长文干扰。 在模型推理时,网页返回的冗长噪音信息对小模型判断影响极大。对比实验表明,使用不同能力的模型对上下文进行摘要,最终在GAIA任务上的性能差异可达10%。技术团队引入了上下文信息精炼机制,利用上下文管理工具或多模型协作的方式,专门负责网页内容的过滤与摘要,在信息进入4B模型前完成关键信息提取。通过构建高质量的“学习环境”,让小模型能聚焦于关键决策,避免在海量噪声中迷失方向。
更多技术细节在项目的技术报告中有详细描述。
相关链接与资源
对于想要深入了解、复现或应用此模型的开发者,可以参考以下资源。在 云栈社区 的开源实战板块,你也能找到更多类似的优质项目与深度讨论。
 发表于 2026-1-15 11:24:57
|
查看: 287|
回复: 0
发表于 2026-1-15 11:24:57
|
查看: 287|
回复: 0
