金融市场长期依赖于时间序列建模进行研究,然而纯粹基于数值的预测因市场噪声、非平稳性和制度转变而充满挑战,这也促使研究者们积极引入替代信息源。资产价格的变动常常由离散且可解释的事件引发,不同的事件类别会导致异质化的市场反应。遗憾的是,现有的交易系统并未充分利用事件级信息,大多仅将文本新闻作为辅助手段。
本文提出的 Janus-Q 是一个端到端的事件驱动交易框架,其核心分为两阶段:第一阶段构建了一个包含 62400 篇文章的大规模金融新闻事件数据集;第二阶段则结合了监督学习与强化学习进行决策导向的微调。
实验结果表明,Janus-Q 的表现显著优于市场指数和各类大语言模型基线,其夏普比率最高提升了 102.0%,方向准确率比最强的竞争策略提高了超过 17.5%。

摘要
金融市场走势常常由新闻传达的离散金融事件所驱动。然而,现有基于文本信息的交易信号学习系统面临两大核心挑战:一是缺乏大规模、以事件为中心的数据集;二是语言模型的语义推理与金融市场中真正有效的交易行为之间存在不匹配。
为了解决这些问题,本文提出了 Janus-Q 这一端到端的事件驱动交易框架。该框架同样分为两个阶段:第一阶段致力于构建一个大规模、带有市场验证标签的金融新闻事件数据集;第二阶段采用决策导向的训练范式,结合监督微调(SFT)和基于分层门控奖励模型(HGRM)的强化学习进行微调。
实验验证了 Janus-Q 的卓越性能。它在多个评估指标上均超越了市场指数和众多大语言模型基线,夏普比率最高提升 102.0%,方向准确率比最强竞争对手提高了 17.5% 以上。
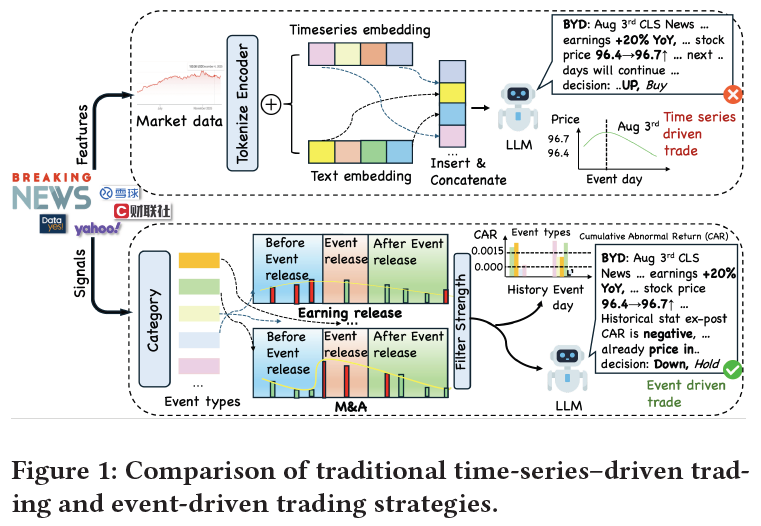
简介
金融市场建模长期以时间序列分析为主流,但纯数值预测固有的缺陷——如市场噪声、非平稳性和制度转变——使得研究者不断寻求新的信息源。一个关键洞察是,资产价格的变动往往由具体的、可解释的离散事件(如财报发布、并购消息)触发,且不同事件类型引发的市场反应各不相同。然而,当前的交易系统并未充分挖掘这种事件级别的信息潜力,大多仍将文本新闻视为辅助性输入。
当前的方法主要面临两大挑战:
- 缺乏事件-市场粒度数据:现有的金融数据集难以有效区分有信息含量的新闻与市场噪声,同时面向通用领域、具备精细标注的事件数据集非常稀缺。
- 语义推理与市场现实脱节:即使大语言模型能够对新闻进行看似合理的语义判断,但这种判断可能与实际的市场结果(如价格变动方向、幅度)并不一致,导致其推理难以直接转化为盈利的交易决策。
针对上述挑战,本文提出了 Janus-Q,一个两阶段的事件驱动交易框架。我们首先构建了一个包含 62400 篇由专家标注新闻文章的大规模金融事件数据集。基于此数据集,我们开发了一套决策导向的训练范式。该范式采用多步优化:先通过监督微调建立从事件描述到预期市场反应(以累计异常收益率CAR衡量)的映射;再引入创新的分层门控奖励模型(HGRM) 进行强化微调,以弥合语义推理与市场结果之间的鸿沟。
实验结果表明,Janus-Q 的表现全面优于市场指数、时间序列模型及其他各类基线模型,平均方向准确率提高了 17.5%,事件类型准确率提高了 18.2%。消融研究也证实了 HGRM 在框架中的关键作用。
本文的主要贡献包括:
- 构建了一个包含 62400 篇金融新闻、集成了事件类型、情感、市场影响量化(CAR)的大规模高质量数据集。
- 提出了首个端到端的事件驱动交易框架 Janus-Q,并设计了分层门控奖励模型(HGRM)来对齐事件理解与交易决策。
- 综合评估显示 Janus-Q 的交易表现强劲且稳定,夏普比率提升 102.0%,方向准确率提升 5.4%,有效证明了该框架在事件理解与交易决策对齐上的成功。
相关工作
事件驱动建模
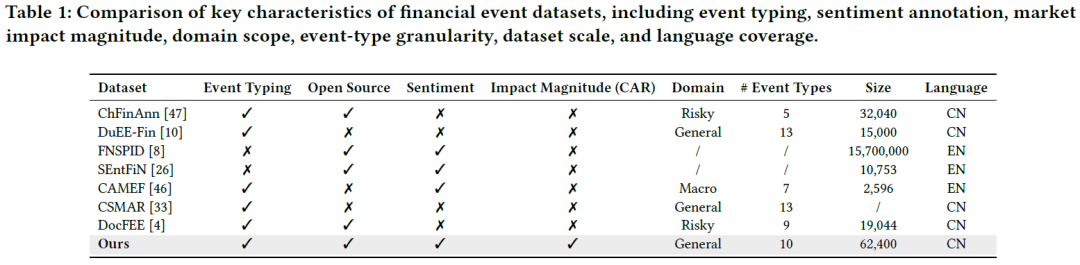
早期的事件驱动市场分析源于计量和统计金融,经典的事件研究法通过因子模型估计预期回报来衡量市场对事件的反应。后续研究开始纳入文本信息,机器学习和深度学习方法尝试将文本与市场数据相结合。然而,现有方法多侧重于预测,未能明确建模事件属性,且缺乏标准的、适用于交易的事件数据集。为此,我们提出了一个集成了事件分类、情感标注和事件影响量化评估的、以事件为中心的数据集。
大模型用于交易
近期研究开始探索使用大语言模型(LLMs) 处理交易相关任务。LLMs 能够处理非结构化金融文本并提供推理过程,相比传统模型,在解释复杂市场事件和适应市场冲击方面更具潜力。然而,当前基于 LLM 的交易系统存在局限:一是交易决策仍多依赖价格或成交量等传统信号,文本信息融合较弱;二是强化学习方法中的奖励设计往往较为简单,难以模拟经济决策中复杂的权衡。为此,我们提出了分层门控奖励模型(HGRM),旨在将事件级的语义推理与基于真实市场结果的交易回报相结合。
方法
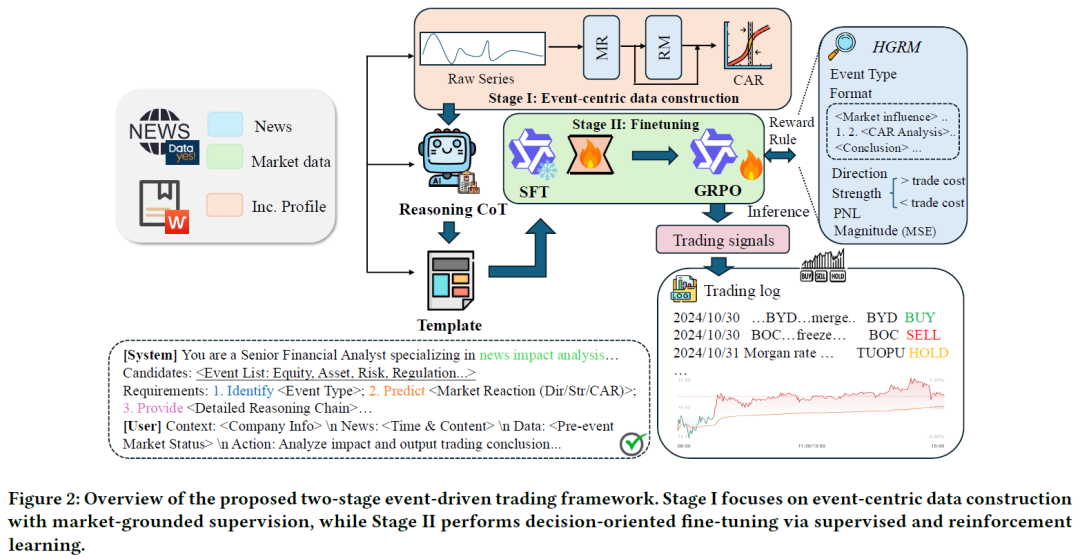
以事件为中心的数据构建
本文旨在探究特定事件对其关联资产在价格变动方向和幅度上的影响,并比较不同事件类型影响的差异。我们通过构建事件中心数据集,将市场影响与金融新闻事件的语义解读紧密结合。
事件-CAR 建模
我们以事件发生时的股票相关新闻为基础,使用事件窗口内的累计异常收益率(CAR)来量化市场影响。定义了估计窗口(用于估计无事件发生时的“正常”收益)和事件窗口(用于捕捉事件引发的异常价格反应)。
市场模型(MR):通过估计窗口的市场模型去除市场整体波动的影响,得到异常收益率(AR)。
$$r_{i,t} = \alpha_i + \beta_i r_{m(i),t} + \varepsilon_{i,t}, t \in T_{est}. (1)$$
$$AR_{i,t}^{MR} = r_{i,t} - (\hat{\alpha}_i + \hat{\beta}_i \cdot r_{m(i),t}), t \in T_{evt}. (2)$$
风险模型(RM):对 MR 模型得到的 AR 进一步用多因子风险模型进行中性化处理,得到因子中性的 AR。
$$AR_{i,t}^{MR} = \gamma_i + x_{i,t}^{\top} \lambda_l + u_{i,t}, t \in T_{cvt}. (3)$$
$$AR_{i,t} = AR_{i,t}^{MR} - x_{i,t}^{\top} \hat{\lambda}_{l}, t \in T_{evt}. (4)$$
累积异常收益(CAR):计算事件窗口内 AR 的总和,以概括事件导致的异常价格变动。
$$CAR_i = \sum_{t \in T_{evt}} AR_{i,t}. (5)$$
事件分类和情感标注
我们使用 CAR 来量化事件对资产价格的经济影响,同时为每个事件关联结构化的语义标签。每个事件用一个真实标签 $y = \\{ c, d, s, e \\}$ 表示,其中 $c$ 是已实现的 CAR,$e$ 是标注的事件类型。方向 $d$ 由 $d = \text{sign}(c)$ 确定,交易强度 $s$ 由预定义的阈值 $\tau$ 决定。$d$ 和 $s$ 共同表征市场对事件的反应,是对定量影响幅度 $c$ 的补充。
面向决策的微调
纯监督微调无法保证模型的推理能转化为符合市场规律的决策。而现有的强化学习方法多依赖启发式、简单加和的奖励设计,相互竞争的奖励目标可能彼此抵消,难以模拟经济决策中有意义的权衡。
本文基于构建的事件中心数据集,进行面向决策的微调,采用多步训练范式:先进行监督微调(SFT)以稳定模型的结构化事件推理能力;再使用 Group Relative Policy Optimization(GRPO)进行强化微调,直接优化交易决策。
我们设计了一套结构化的奖励机制:
分层门控奖励模型(HGRM):模型生成一个包含预测累计异常回报 ($\hat{c}$)、方向 ($\hat{d}$)、交易强度 ($\hat{s}$)、事件类型 ($\hat{e}$) 的复合预测。若预测方向或交易强度缺失,则从预测的累计异常回报 $\hat{c}$ 中推断。
-
硬方向门:方向正确性
设硬方向门 $g_{dir}$,用于防止在错误判断市场极性时获得虚假奖励。当方向预测错误导致 $s_{dir} < 0$ 时,$g_{dir} = 0$ 将阻断后续所有奖励。
$$s_{dir}(\hat{d}, d) = \begin{cases} 1, & \hat{d} = d, \\\\ -\lambda_{dir}, & \hat{d} = -d, \\\\ 0, & \text{otherwise}, \end{cases} (6)$$
-
软事件类型门:事件类型一致性
引入事件类型软门,当预测的事件类别错误时对奖励进行折扣,鼓励模型的事件理解与交易结果保持一致。
$$s_{evt}(\hat{e}, e) = \begin{cases} 1, & \hat{e} = e, \\\\ -\lambda_{evt}, & \hat{e} \neq e, \\\\ -\lambda_{miss}, & \hat{e} = \varnothing, \end{cases} \quad m_{evt} = \begin{cases} 1, & \hat{e} = e, \\\\ \alpha, & \text{otherwise}, \end{cases} (7)$$
-
交易奖励:具有强度正则化的成本感知 PnL
定义了一个考虑交易成本的单事件交易回报函数,仅当预测的交易强度为“强”时才被激活。结果奖励被裁剪到一个对称的范围内,并对误判的交易强度采用非对称成本惩罚,以防止模型产生过于极端或频繁的交易行为。
$$\text{PnL}(d, c) = \begin{cases} c - \kappa, & d = \text{positive}, \\\\ -c - \kappa, & d = \text{negative}, \\\\ 0, & d = \text{neutral}, \end{cases} (8)$$
-
量级塑形和过程奖励
当方向预测未被阻断时,添加幅度塑形项 $r_{mag}$ 以提供更精细的监督。此外,还设置了一个轻量级的过程奖励 $r_{proc}$ 用于评估推理链的质量,例如惩罚过长的回复或过度的自我提问。
$$r_{mag} = \exp(-|\hat{c} - c| / \sigma), (9)$$
-
整体奖励
最终的 HGRM 奖励由上述各部分分层构成,高层门控控制低层奖励的激活,其中 $g_{dir}$ 可以完全阻断低层奖励。
$$R = w_{dir} s_{dir} + g_{dir} (w_{evt} s_{evt} + w_{pnl} r_{pnl} + w_{mag} r_{mag} + w_{proc} r_{proc}). (10)$$
实验
实验设置
对于股票集合 $S$ 中的股票 $s$,我们在交易日 $t$ 执行由 Janus-Q 驱动的多空交易策略:
- 信号生成:分析 $t$ 日 9:30 至 $t+1$ 日 9:30 期间的所有相关新闻,为每只股票 $s$ 生成方向信号 $\gamma_{s,t}$(做多、做空、持有)。
- 事件加权信号聚合:在 $t$ 日,按照不同事件类型的预设权重 $w_k$ 聚合新闻信号,并利用 $t+1$ 日开盘前的信息分配每日交易预算。
- 入场规则:若聚合信号 $\gamma_{s,t}$ 为做多(做空),则在 $t+1$ 日以开盘价 $o_{s,t+1}$ 开仓。
- 出场规则:持仓至后续两个交易日中的最后一个交易日 $\tau(t)$,并以收盘价 $c_{s,\tau(t)}$ 平仓。
评价目标
我们对 Janus-Q 在事件驱动交易中的有效性进行了综合评估,重点关注整体交易表现及各关键设计组件的贡献,主要围绕以下四个研究问题展开实验:
- RQ1:Janus-Q 在交易表现和决策准确性上是否持续优于市场指数和各类竞争模型基线?
- RQ2:框架中各核心组件对其整体交易表现的贡献如何?
- RQ3:多样化的奖励目标对于提升学习稳定性和决策导向的交易表现效果如何?
- RQ4:Janus-Q 在解读金融事件时,其判断与人类专家的契合程度如何?
数据集和评估指标
模型在一个整合了文本与金融信息的多源数据集上进行评估。新闻文章于 2023.1.1 - 2025.1.25 期间从 Datayes 收集,股价数据于 2023.1.1 - 2025.2.6 期间从 Tushare 获取,数据按 4:4:1:1 的比例划分为训练、验证、测试和样本外测试集。此外还引入了 Wind 平台的企业资料以丰富语义信息。我们采用了 MAE、RMSE、方向准确率(DA)、事件类型准确率(ETA)、夏普比率(SR)、最大回撤(MDD)六个指标来全面评估模型的预测质量和投资表现。
基线模型
我们将 Janus-Q 与以下四类基线进行对比评估:
- 市场指数:以沪深300、中证500、中证1000等代表中国股市大、中、小盘风格的指数作为被动投资基准。
- 时间序列导向大语言模型:如 Time-MQA、ChatTS-14B、TimeMaster 等专用于时间序列预测的模型。
- 金融领域特定大语言模型:如 FinMA、DISC-FinLLM、Stock-Chain 等经过金融语料预训练或针对金融任务微调的模型。
- 通用大语言模型:包括 QwQ-32B、Claude-3-Haiku、GPT-4o-mini、DeepSeek-V3.1-nex-n1 等未专门针对金融任务进行调优的模型。
结果
我们将 Janus-Q 与 16 种基线方法在六项通用评估指标上进行了全面对比。在测试期间,市场处于修正、回调和盘整阶段,各基准指数的风险调整后收益均为负值。多数时间感知模型和金融大语言模型表现不佳。在通用大语言模型中,仅 QwQ-32B 和 DeepSeek-v3.1-nex-n1 取得了正夏普比率,但净值波动较大。相比之下,Janus-Q 成功地抓住了 12 月下旬的市场上涨行情,并在后续保持了稳定增长,最终实现了最高的累计回报。
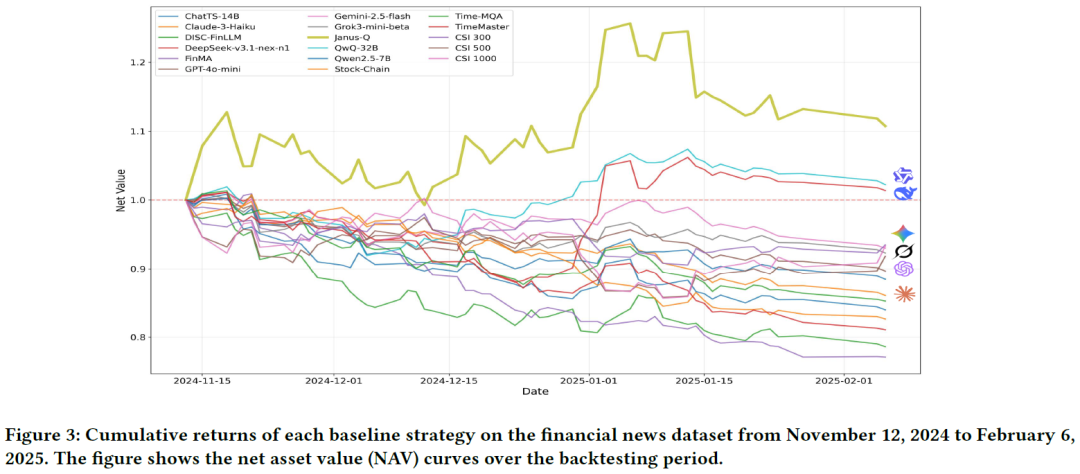
表 2 显示,Janus-Q 在决策层面和交易层面的指标上均优于所有基线。它的 CAR 预测误差(MAE、RMSE)最低,较最佳的时间感知模型、最强的金融大语言模型基线和最佳的通用大语言模型分别降低了 18.3%、50.6% 和 5.4%;其方向准确率(DA)分别超过了这三者 17.5%、29.0% 和 22.4%。
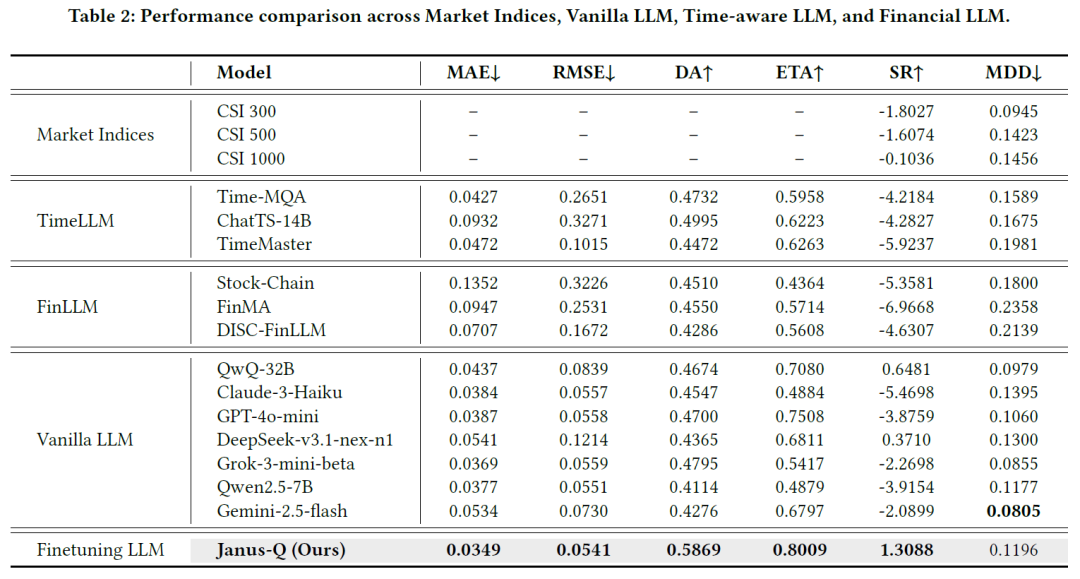
一个有趣的发现是,领域特定的金融大语言模型(FinLLM)的表现反而逊于多数通用大语言模型,这可能是因为它们在微调时的任务与当前交易领域不匹配,或者受限于模型架构及上下文长度。时间感知模型在回测中表现不佳,说明仅仅向模型中注入文本线索并不足以支撑稳健的交易决策,直接优化从事件到决策的映射更有价值。Janus-Q 的夏普比率达到了 1.3088,超过亚军 QwQ-32B 一倍多,相对提升超过 102.0%。而时间感知和金融大语言模型基线在测试期的夏普比率均为负值。部分基线虽然最大回撤略低,但其回报也大幅降低。Janus-Q 在盈利性与稳定性之间取得了更好的平衡,风险调整后的表现更优。
消融分析
表 3 展示了 Janus-Q 各核心组件的消融研究结果。移除任何一个组件都会导致模型性能下降,这表明框架的有效性源于核心模块的协同作用。移除监督微调(SFT)导致的性能恶化最为明显,方向准确率下降了超过 14%,夏普比率由正转负,凸显了 SFT 为后续决策奠定基础的关键作用。移除强化学习优化(GRPO)使夏普比率下降了约 13%,说明强化学习主要起到对已有策略进行微调的作用。移除 CAR 监督或公司级信息,也会导致预测准确性和盈利能力下降,这显示了市场影响线索和公司特定信息对于事件驱动交易的重要贡献。
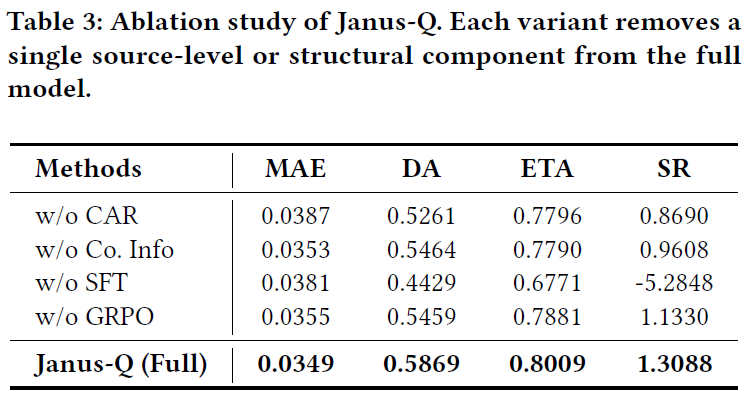
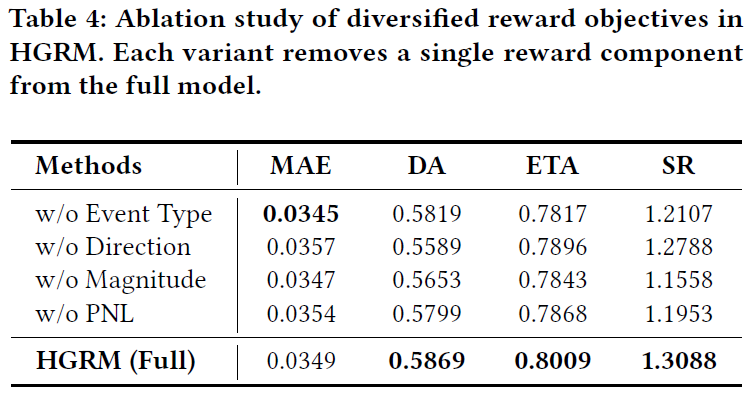
表 4 研究了从完整的 HGRM 中移除单个奖励目标的影响。结果显示,所有消融变体的表现均不如完整模型,说明多样化的奖励目标在学习稳定有效的交易策略中起到了互补作用。移除方向相关目标使决策质量下降最明显(方向准确率下降超 4.8%),但对最终交易表现的影响相对温和。移除事件类型监督会轻微降低预测误差,并使交易表现小幅下降。消除幅度或损益目标则导致表现显著变差,夏普比率分别下降约 11.7% 和 8.7%。完整的 HGRM 取得了最高的决策准确率和最强的交易表现,这表明联合优化多样化的奖励目标对于稳定学习和实现决策导向的事件驱动交易至关重要。
案例分析
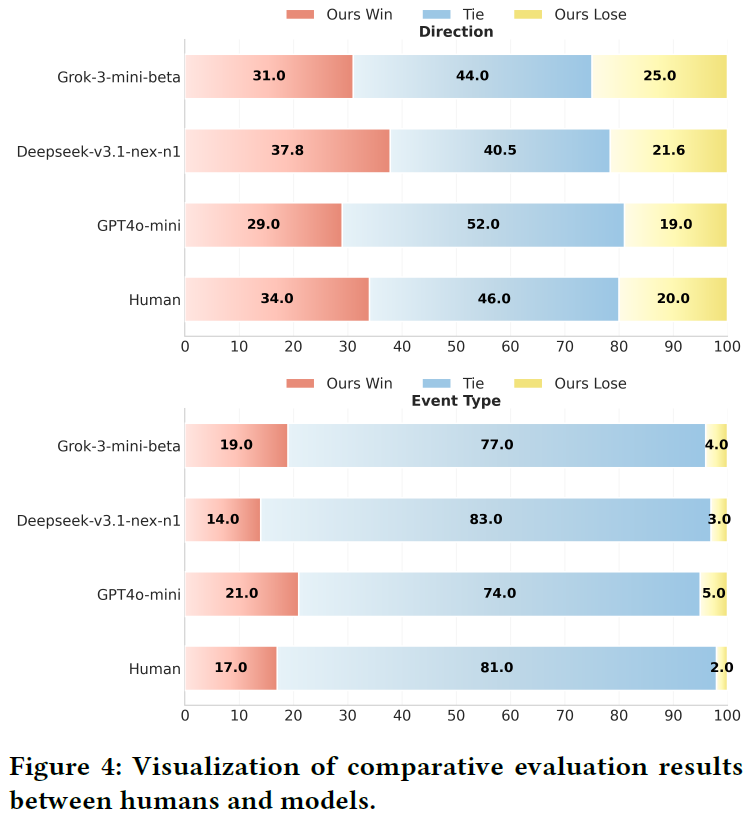
我们对 200 个测试样本进行了事件解释评估,并招募了三位不同金融专业背景的人员,通过多数投票形成人类共识基准。在方向预测方面,Janus-Q 与人类及其他模型具有较高的一致性,平局率在 40.5% 到 52.0% 之间,最高胜率达 37.8%,输率不超过 25.0%。在事件类型理解方面,平局占比高达 74.0% 到 83.0%,输率低于 5.0%,且有 14.0% 到 21.0% 的胜率。这表明 Janus-Q 在事件解释上不仅与人类评估者高度契合,甚至在某些方面表现得更准确,同时保持了决策和上下文敏感交易所需的灵活性。
总结
本文聚焦于事件驱动交易,提出了 Janus-Q 这一两阶段的事件驱动交易框架。该框架首先构建了一个以事件为中心、带有市场影响(CAR)分析的数据集,随后采用了一种多步训练范式进行决策导向的微调。实验表明,Janus-Q 在决策准确性和交易表现上均显著超越了市场指数和各类大语言模型基线。
这项研究展示了将 Transformer 架构的大语言模型与严谨的金融市场分析方法相结合的巨大潜力。通过精心设计的分层奖励机制,我们成功地将模型的语义理解能力引导至更具经济意义的交易决策上,这在深度学习和强化学习应用于复杂金融场景的探索中是一个有价值的实践。
未来,我们计划扩展该框架以支持更细粒度的事件结构解析、融入多模态输入(如财报PDF、电话会议音频),并进行跨市场的回测验证,进一步推动数据挖掘和AI在量化交易领域的应用。对这类结合前沿AI与量化交易的研究感兴趣的朋友,欢迎关注云栈社区的智能 & 数据 & 云和人工智能板块,获取更多深度讨论与技术资源。
 发表于 2026-3-3 06:28:25
|
查看: 140|
回复: 0
发表于 2026-3-3 06:28:25
|
查看: 140|
回复: 0
