文章概览
- 引言
- 名词解释
- 现状与痛点:旧系统存在的瓶颈
- 技术选型:从 Push 到 Pull 模式
- 新系统的目标
- 全面采集系统:分组和分级采集
- 智能告警策略:减少误报和漏报
- 新系统成效:部分结果展示
- 总结与展望
一、引言
线上的告警系统运行多年总体稳定,但实际使用中仍遇到过几类典型问题:明明数据库告警指标已经很高,却没有告警;有些指标触发了告警,但排查时找不到对应原因,甚至监控图上也没有明显波动。
如果仅通过修改告警间隔和告警次数来“调参”,往往会在误报与漏报之间反复摇摆。要从根上解决,就必须系统性梳理现有告警系统的风险点,并针对性改造。
另一方面,线上数据库、服务器等多类指标的采集分散在不同位置,缺乏统一管理。指标体系如果不先厘清、收拢并标准化,后续无论是做聚合分析、容量规划还是自动化治理,都会被数据质量和一致性拖住。
本文主要聚焦数据库(MySQL、Redis)监控,同时也会略微涉及服务器与网络指标。不同类型监控的原理大体一致,只是采集细节与告警策略会有所差异,方案设计可供同类告警系统参考。
二、名词解释
- collectd:一个定期收集系统和应用程序性能指标的守护进程,并提供以多种方式存储这些值的机制。
- nagios:一个开源监控系统,可以监控整个 IT 基础设施,确保系统、应用程序、服务和业务流程正常运行。
- nrpe:nagios 插件,nrpe 允许 nagios 远程执行各种命令或插件。
- prometheus:一个基于云原生的开源系统监控,以时间序列数据的形式收集和存储指标。
- exporter:prometheus 的数据采集端,需要运行在被采集的服务器上,将采集到的监控数据转化为 prometheus 能识别的格式,prometheus 会定时从 exporter 上拉取数据。
三、现状与痛点:旧系统存在的瓶颈
3.1 现状
监控告警对线上数据库是必不可少的能力。通过采集线上服务的关键指标,并为关键指标设定阈值,可以在数据库异常时通知到相关人员,尽快介入处理,避免异常进一步影响业务。
当前去哪儿大部分数据库并没有上云,依然采用实体机部署方式,且大量场景是一机多实例。现有数据库监控系统基于开源的 collectd 采集与 nagios 告警进行定制。
当前数据库指标采集系统架构:
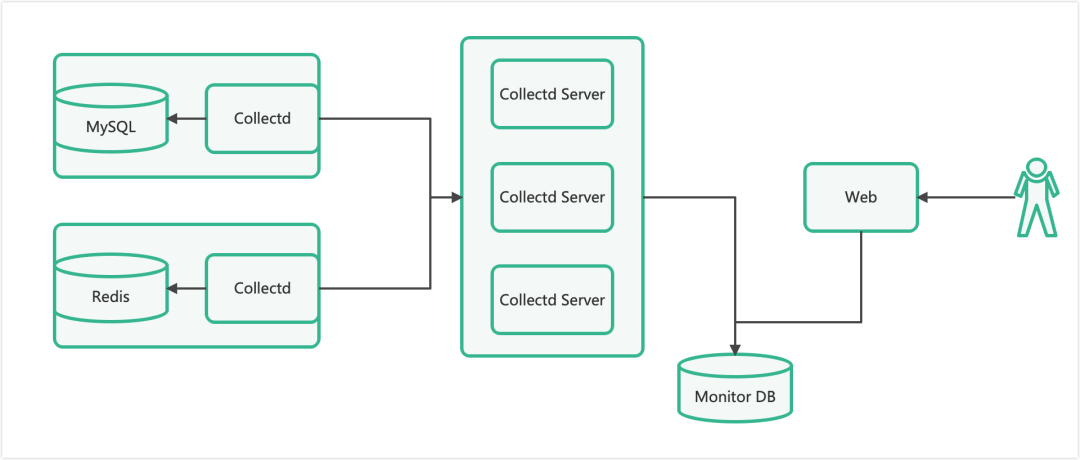
每个数据库服务器上部署一套 collectd 服务。collectd 定时采集数据库状态信息,将数据发送给 collectd server。collectd server 再将数据分类存储到监控数据库中,并提供 Web 页面用于查询监控指标详情。
当前数据库监控告警系统架构:
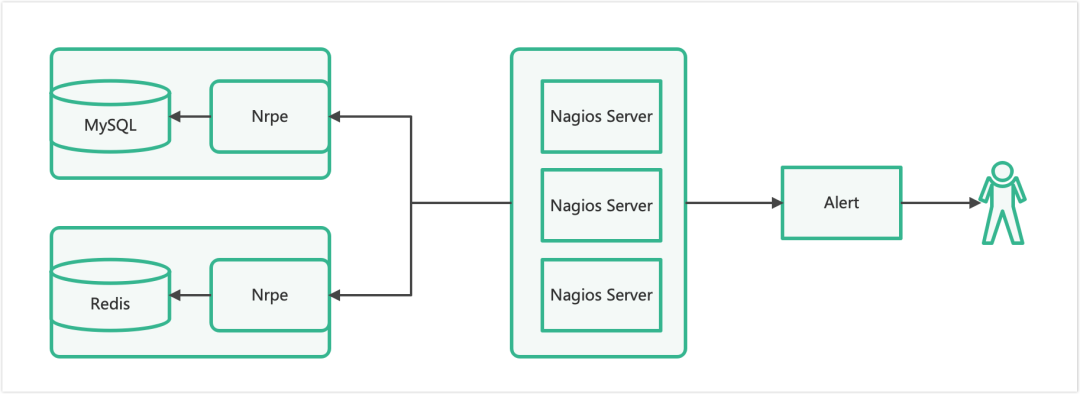
每个数据库服务器上部署一套 nrpe 服务,nagios server 定时向 nrpe 发起检测请求;nrpe 执行检查脚本并返回结果。nagios server 判断后将需要告警的信息发送给 alert 服务,alert 再做二次判断并补充元数据,最终把告警发送给对应负责人。
这两套系统在多数情况下能满足需求,但随着需求持续变化,一些诉求无法继续覆盖,同时一些结构性问题逐步暴露。
3.2 痛点
目前数据库指标采集系统主要存在以下问题:
-
collectd 的 push 模式可能出现数据断点,且难以排查根因
collectd 端采集数据后,经网络层发送到 collectd server,再进入存储层。collectd 采用 UDP 协议,UDP 不保证数据可靠到达。链路节点多,断点往往是偶发问题,难以定位到底是哪一段链路、哪个节点在什么条件下丢了数据。
-
采集指标偏少
目前更多是基础数据库指标与服务器指标,缺少更高阶、更贴近排障与优化的数据库监控指标。
-
存储层缺乏关键元数据
collectd server 收到推送数据后直接写入存储层,没有补充必要的元数据信息(例如用于聚合与分组的标签)。缺少这些元数据会直接限制高层次维度的聚合能力,很多分析类需求因此无法落地。
数据库告警系统在当前场景下也存在明显问题:
- 监控粒度较粗:仅支持分钟级监控,难以满足更细粒度探测。
- 采集间隔为“瞬时值”,在部分场景可能探测不到告警信息
nagios server 向 nrpe 发起探测请求时,nrpe 执行脚本采集数据。即时状态一般这样处理:
stat = collect()
if stat > threshold:
alert()
对于非即时状态,需要计算差值,通常会这样采集:
stat1 = collect()
sleep X
stat2 = collect()
if (stat2 - stat1)/X > threshold:
alert()
一般情况下 [X] 会远小于采集间隔。这会导致某些场景出现漏报:告警真实发生在“未被采到的区间”,采集区间刚好都没越线。

如图所示,0-10、60-70、120-130 为采集区间,采集区间内没有超阈值;但其他区间内已超阈值。采集区间与告警区间可能出现非重叠,从而造成应告警却未告警的漏报。
- 每次下发新的监控需要重启 agent
这属于系统架构层面的约束,并非完全不可解,但改造成本较高。
四、技术选型:从 Push 到 Pull 模式
针对两个系统的问题,需要分别分析指标采集系统与监控告警系统的模式差异。
4.1 指标采集系统:Push vs Pull
指标采集系统的数据模型大体分为两类:push 和 pull。
- push 模式:agent 定时采集数据,采集完成后推送到 server;server 聚合后写入存储层。
- pull 模式:server 定时向 agent 发起采集请求;agent 采集后返回给 server;server 聚合、补充标签后写入存储层。
push 模式优势:
- agent 部署后即可自动采集与推送,使用方便。
- server 接近无状态,易于按负载扩缩容。
- server 管理成本通常低于 pull。
push 模式劣势:
- agent 采集间隔通常统一,难以按服务级别精细化设置采集频率。
- 推送链路长、排查断点困难,尤其在 UDP 且链路节点多时。
- server 难以补充标签,限制高层次聚合需求。
pull 模式优势:
- 可细粒度控制拉取间隔,不同级别/维度可配置不同频率。
- server 可个性化添加标签,便于高层次聚合分析。
- server 直连 agent,链路更短,数据断点概率更低。
pull 模式劣势:
- server 更偏“有状态”,扩缩容与高可用设计更复杂,使用成本更高。
- 标签体系若过于复杂,可能带来 server 压力。
- agent 需占用端口,部分场景会成为限制。
综合对比后,选择 pull 模式:更利于添加标签与减少断点概率。
4.2 告警系统:采集频率与指标采集系统解耦
告警的数据来源既可以是指标采集系统,也可以是告警系统自行采集。关键在于:告警采集频率是否必须与指标采集一致?
通常告警采集的数据只用于与阈值对比,超过阈值的才会保留与通知,其余数据会丢弃。因此告警系统一般不会像指标采集系统那样承担“全量存储”的成本压力。反过来,指标采集系统需要保存每次采集的结果,采集间隔越小,存储成本呈倍数上涨(暂不考虑压缩)。
为了保障告警及时性,同时避免给指标采集系统额外施压,告警系统选择 自行采集。
Qunar 业务线对故障要求“1-5-10”:1 分钟发现问题、5 分钟定位问题、10 分钟解决问题。这要求告警采集频率高于指标采集频率。在数据库与告警系统可承受范围内,提高告警采集频率,才能更早确认问题并减少业务影响。
五、新系统的目标
结合“1-5-10”故障响应体系,并满足业务与 DBA 的告警诉求,新系统目标如下:
-
数据库指标采集系统
- 采集范围尽可能全面,避免遗漏关键指标。
- 按指定频率稳定采集,尽可能避免丢失。
- 为指标补充指定标签,支持更高层次聚合。
- 存储成本保持在合理范围内。
-
数据库监控告警系统
- 合理化监控采集频率,确保及时定位问题,满足业务需求。
- 尽可能减少误告警,提升告警真实性。
- 尽可能减少无效告警,确保告警“有用”。
按目标拆解,第一步优先完成数据库指标采集体系的重构与统一。
六、全面采集系统:分组和分级采集
指标采集系统最关键的两件事:采集范围 与 采集频率。范围要全,频率要匹配业务与成本,否则后续分析会被“缺数据/不准/不全”拖垮。
6.1 采集范围
针对一套服务,采集指标范围可大致拆分为如下需求:
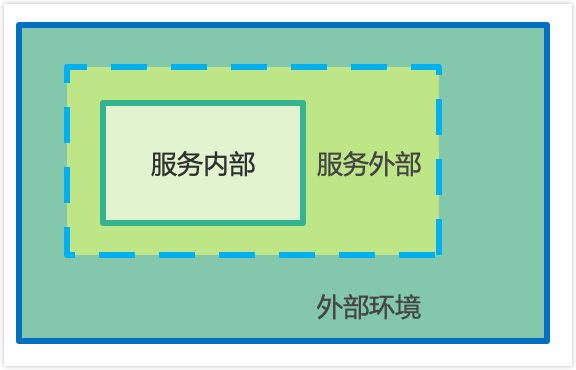
一个数据库服务通常以进程形式存在,并通过端口提供访问。
- 服务内部信息:进程内部状态指标,通常需要连接数据库进入进程内部获取。
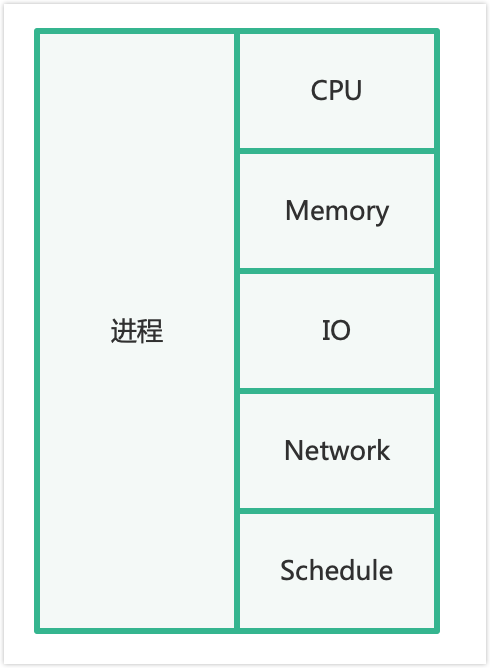
- 服务外部指标:进程占用的资源(CPU、内存、IO、网络、存储等),需要从进程外部采集。
以 MySQL 为例,需要采集的内部指标包括(示例):Thread 和 Client、Instance/DB/Table 状态、事务、SQL 请求与 SQL 指纹、InnoDB Buffer Pool 与 MyISAM Cache、InnoDB/MyISAM 引擎指标、Redo 与 Binlog、Galera(PXC)与 Replication(复制)等。

MySQL 外部指标包括:进程占用的 CPU、Memory、IO、Network、Schedule 等,以及 MySQL 自身占用的存储(Instance、DB、Table 级别文件信息)。
操作系统层面也需要覆盖:
- OS 内部指标:CPU、Memory、Disk、Network、System 等。
- OS 外部指标:Hardware、交换机、网卡链路等。
因此采集范围至少应覆盖:数据库(MySQL/Redis)、操作系统。
6.2 采集频率
确认范围后,再确认频率。指标按变化特征可大致分为三类:
- stat 类型:即时状态。不同时间点值不同,当前值有明确含义,需要即时存储。对应 Prometheus 的 Gauge,例如线程数、内存使用量、复制延迟秒数。
- util 类型:非即时状态。通常需要计算差值/区间才能表示明确含义。对应 Prometheus 的 Counter / Histogram / Summary,例如 CPU 利用率、网卡流量等。
- info 类型:信息类型。通常不变化,只需保存最新一份,例如数据库版本、配置信息、服务器对应交换机接口。
还需要注意:部分指标即使属于 stat/util,但如果使用频率低、变化不大,也不一定需要实时存储,可按小时/天/周级别采集与存储,以节省空间。
基于不同频率需求,设计如下数据库监控采集系统架构:
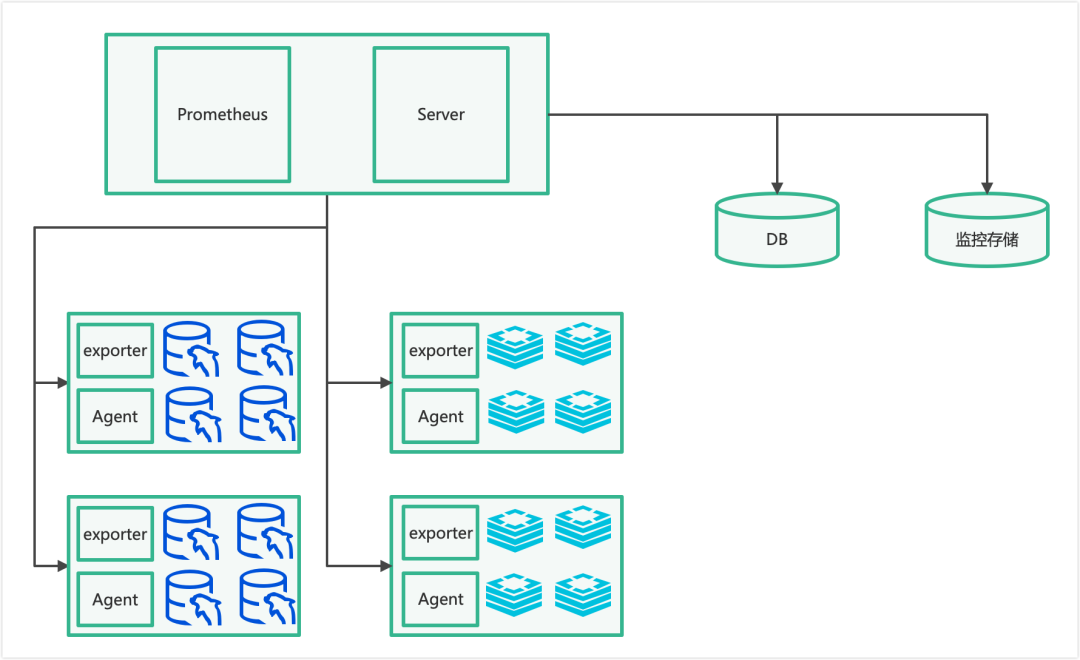
高频指标采集采用业内成熟的监控采集架构,这里使用 Prometheus 监控存储方案,并对 Prometheus 进行改造,定制 exporter 以支持个性化采集。在每台服务器部署 exporter,Prometheus 按服务级别配置不同拉取间隔,拉取后聚合并添加标签,最终写入监控存储。
低频指标采集采用自定义方案:Server 定时向 agent 发起采集请求,汇总数据后添加标签并写入数据库。
采集系统的目标是在可控成本内,尽可能多地采到“可用的数据”。尤其是为指标关联标签,为后续的聚合、分析、预测、规划等提供依据支撑。(相关数据库与中间件话题也可在 数据库/中间件/技术栈 进一步交流。)
七、智能告警策略:减少误报和漏报
告警系统真正需要关注的不是“告警数量”,而是告警的 真实性、有效性、及时性。漏报与误报是两个极端:漏报会让问题被延迟发现,误报会让人疲劳并忽略真实风险。新告警系统需要尽可能同时满足两端约束。
告警本质可以理解为 告警阈值 × 触发次数 的组合。阈值是最关键的:阈值高,可能发现不及时导致漏报;阈值低,又可能频繁误报,造成干扰。
7.1 计算阈值
即时状态计算阈值的逻辑如下:
stat = collect()
if stat > threshold:
alert()
针对非即时状态的计算,关键点是:计算时间间隔必须等于采集间隔。也就是说,用第二次采集的时间减第一次采集的时间作为区间,避免因 [X] 过小导致漏报。逻辑如下:
last_time = now()
last = collect()
...
current_time= now()
current = collect()
if (current - last)/(current_time - last_time) > threshold:
alert()
其中 [current_time - last_time] 为采集间隔。
7.2 告警阈值:从固定阈值到分时阈值
业务请求存在波峰波谷,还会受定时任务、促销、不定时操作影响。用一个固定阈值覆盖全天,其实并不合理。以 MySQL 进程占用 CPU 核数为例:
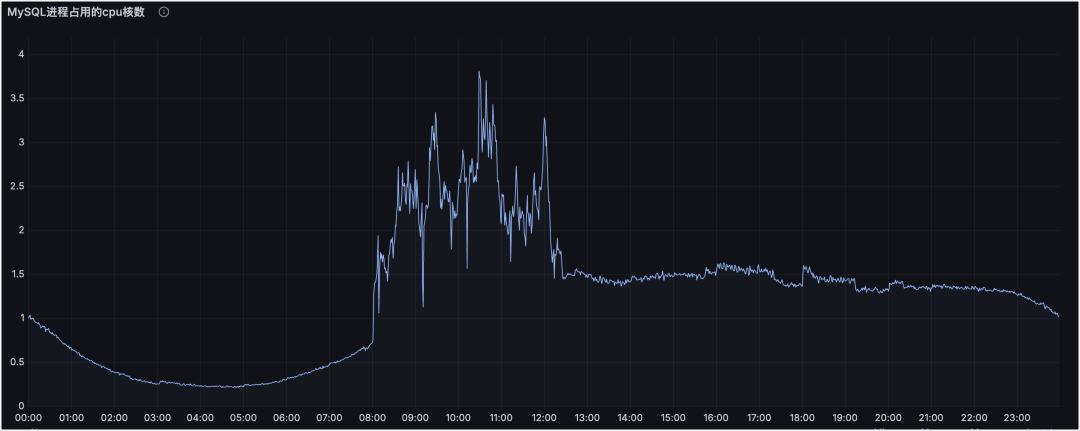
每天 0 点后逐渐进入低峰,凌晨 4 点左右最低;8 点开始有定时任务直至 12 点左右;下午进入高峰,晚间持续,23 点后回落。其中 8:00-12:00 的压力主要来自定时任务,且任务不可取消,业务期望尽快跑完。
如果用固定阈值覆盖全天,往往会被定时任务“抬高阈值”,从而在非任务时段放大漏报风险。更合理的方式是引入分时阈值,例如:
| 时间段 |
阈值 |
说明 |
| 8:00-12:30 |
5 |
业务定时任务导致 CPU 使用核数较多,需要适当调高阈值 |
| 其他时间 |
2 |
业务通常情况下的告警阈值 |
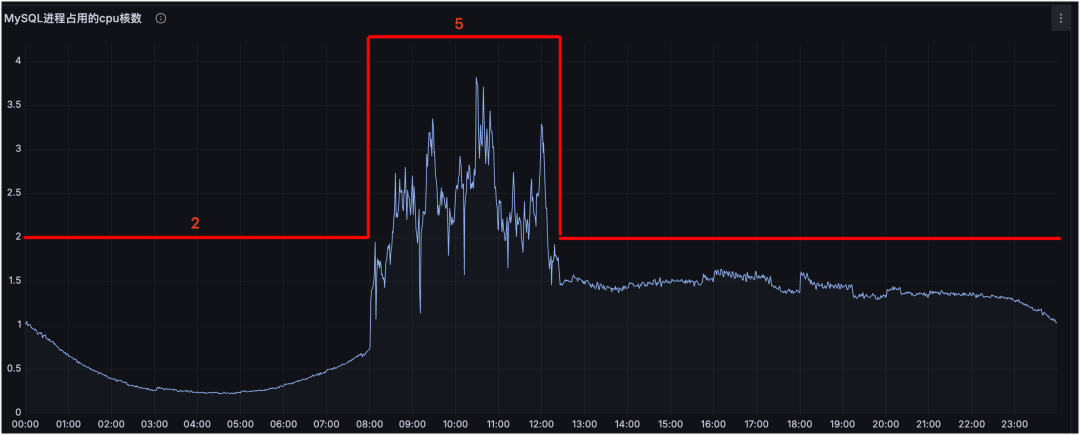
通过不同时段设置不同阈值,既能避免因统一高阈值导致漏报,也能避免特殊时段阈值过低导致误报频繁。
7.3 触发策略:动态检测频率与探测结果聚合
分时阈值能显著减少误报,但仍会遇到“瞬时尖峰”的场景:指标偶发超阈值,若直接告警会误报;若拉高阈值又会漏掉真实问题。传统做法是增加触发次数,但会拉长告警确认时间:
告警检测时长 = 检测间隔 × 触发次数。这会牺牲及时性。
为满足“1-5-10”,可以引入 动态检测频率:第一次检测到超阈值后,自动缩短下一次检测间隔;若下一次仍超阈值,则更确定为真实问题,否则视为偶发波动记录即可。
示例:检测间隔 10s,触发次数 3 次。

固定检测频率下,告警检测时长为 10s × 3 = 30s。

若第一次告警后将检测间隔缩短为 5s,则可能在第 30s 时发送告警,总检测时长为 20s,相比固定频率缩短三分之一。
但动态检测也可能遇到“阈值附近上下波动”的情况:

这类情况可能是阈值不合理,也可能是状态确有问题。为了避免被“单次波动”误导,可以引入 探测结果聚合:对连续 [M] 次检测结果,若其中 [N] 次超过阈值,且最近一次超过阈值,则告警。
例如 [M=3]、[N=2]:检测区间 10-20 超阈值、20-25 正常、25-35 超阈值,则最近三次中两次超阈值,且最近一次超阈值,于是第 35s 应告警。
此外还存在“预期内的负载增加”场景:备份任务导致 IO 增加、促销导致 Redis 内存临时增长、发布加载数据等。指标可能超阈值,但仍在可承受范围内。这类告警不一定必须打扰人。更好的方式是让多系统联动:告警系统识别到指定操作窗口时,临时调整告警指标并设定有效期,尽量降低误报。(这类联动与值班体系、告警路由、变更管控等也常属于 运维/DevOps/SRE 讨论范畴。)
7.4 告警自愈:告警不是终点
没有告警当然最好,但现实中告警不可避免。真正的目标不是“发出告警”,而是“减少告警对人的消耗”,甚至让系统能自动处理,达到自愈。
告警触发后,负责人需要检查服务状态,常见两类问题:
- 告警持续时间短,负责人查看时指标已恢复。
- 部分告警重复出现,短期无法彻底消除,又不能直接屏蔽。
因此,仅有“阈值超了”并不足以排障,系统需要自动采集与该告警相关的上下文与下钻信息,帮助快速定位。

下面列举部分指标的下钻操作与后续动作示例:
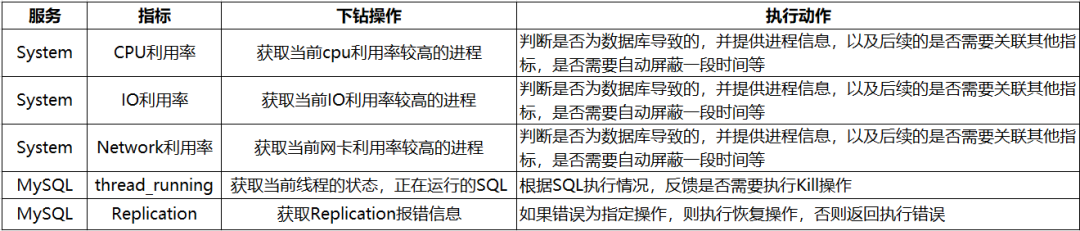
目前自愈模块收到告警后,会按不同指标执行下钻,采集相关详情,并根据下钻结果生成动作。现阶段除少量可明确自动执行的操作外,其余动作仍需要人工确认后执行。
基于上述思路,数据库告警系统架构如下:
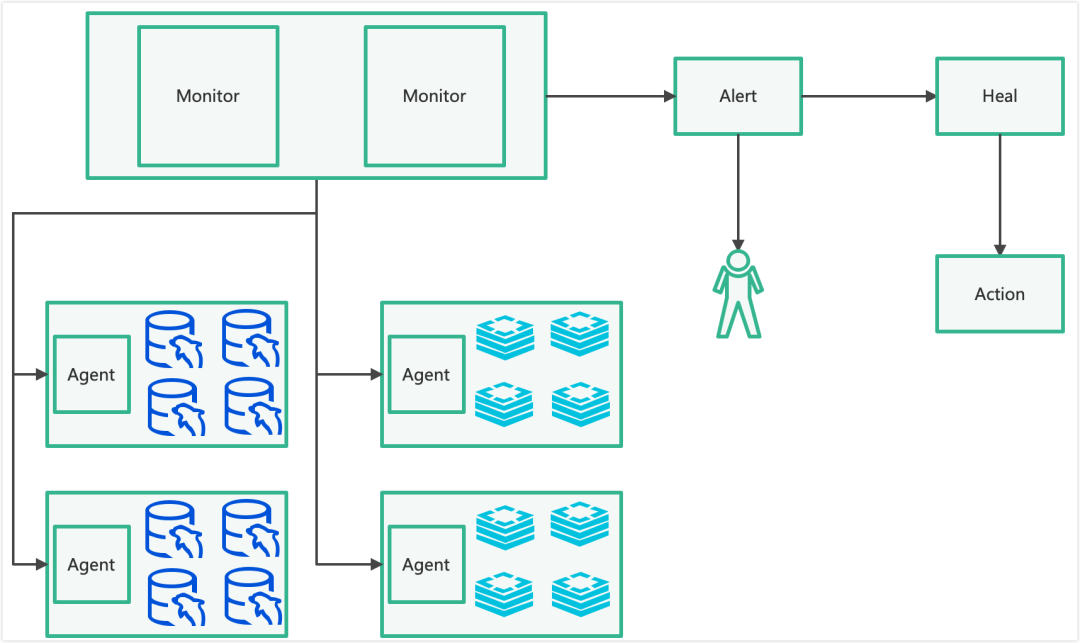
Monitor 根据级别设定采集不同服务指标,并结合不同时段阈值与触发策略。触发后 Alert 通知负责人;Heal 收到告警后自动下钻并执行既定操作;页面查询告警时可关联分析结果,缩短定位链路。(监控体系与告警治理相关话题也可在 运维 & 测试 进一步探讨。)
7.5 其他
7.5.1 告警收敛
为避免告警风暴,当前告警收敛基于实例维度聚合:同实例相同类型告警自动收敛到同一条告警下,只做简单提示,不做强提醒。告警页面也支持设置收敛时间,在收敛时间内仅统计不提示。
后续计划在分析阶段自动判定收敛范围:当某告警触发时,自愈阶段自动分析后续告警应收敛到指标、实例、集群、服务器、交换机还是机房级别。按级别收敛对应范围,可显著降低告警风暴对人的干扰,让负责人更专注于处理核心问题。
7.5.2 AI 监控
当前告警层面并未深入引入 AI,更多是规则与算法层面的优化。告警流程强调秒级响应,现阶段 AI 并不擅长在秒级内给出稳定、可控的判断。
但在自愈分析阶段,当现有规则无法覆盖时,可以考虑使用 AI 生成处理建议,再由人工判断并执行。AI 更适合“辅助决策”,而非直接接管告警触发。
7.5.3 其他类型
告警原理通用。新告警系统具备插件化能力,通过自定义探测方式可扩展到更多监控类型,例如 Web 请求探测、端口存活、进程存在性、主机存活探测,以及更多数据库类型的监控等。
八、新系统成效:部分结果展示
示例一:深入细节定位问题 SQL
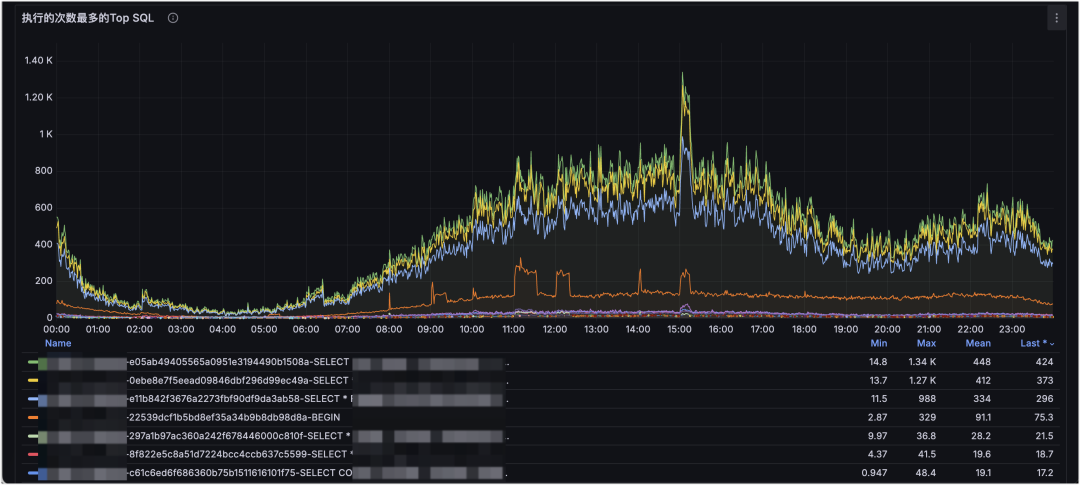
MySQL 执行 SQL 的 QPS 监控:
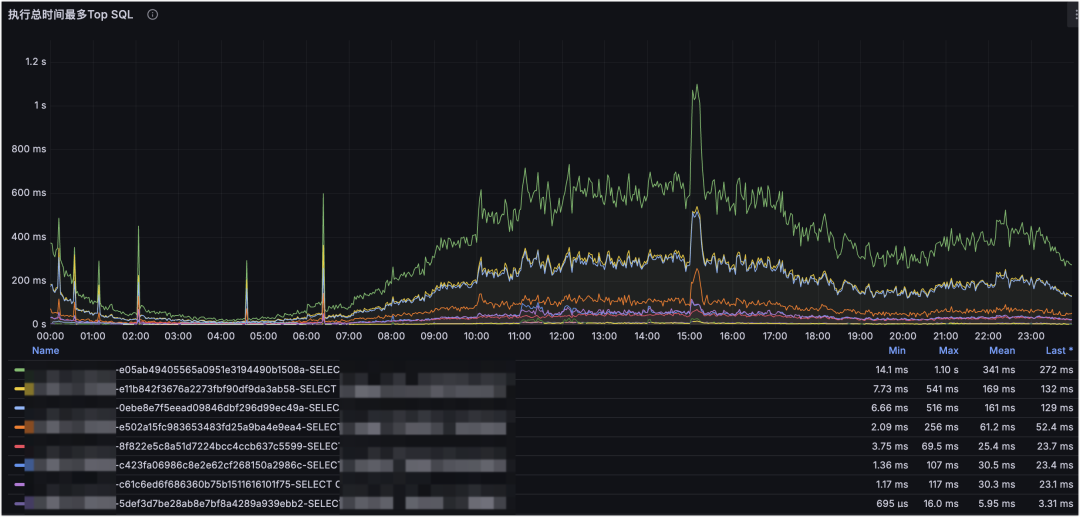
MySQL 执行 SQL 的耗时监控。
这是 MySQL SQL 维度的监控。下钻到 SQL 维度后,可以清楚看到某个时间点对数据库造成压力最大的 SQL 是哪条:是请求量上涨造成的,还是索引错误导致的耗时放大?这能更快定位原因,并为 SQL 优化提供明确依据。
示例二:定位进程负载原因和请求量预估
MySQL 集群 QPS 监控:
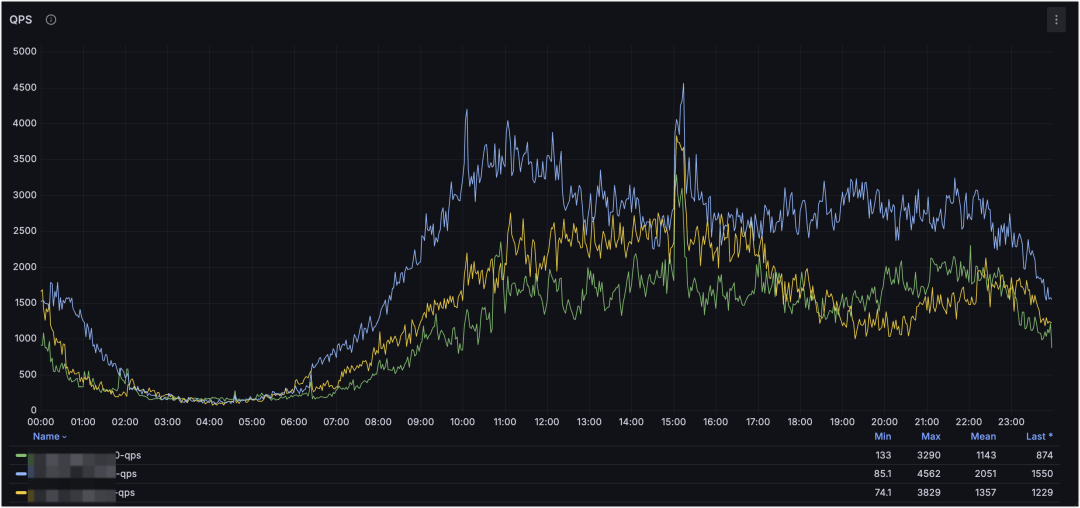
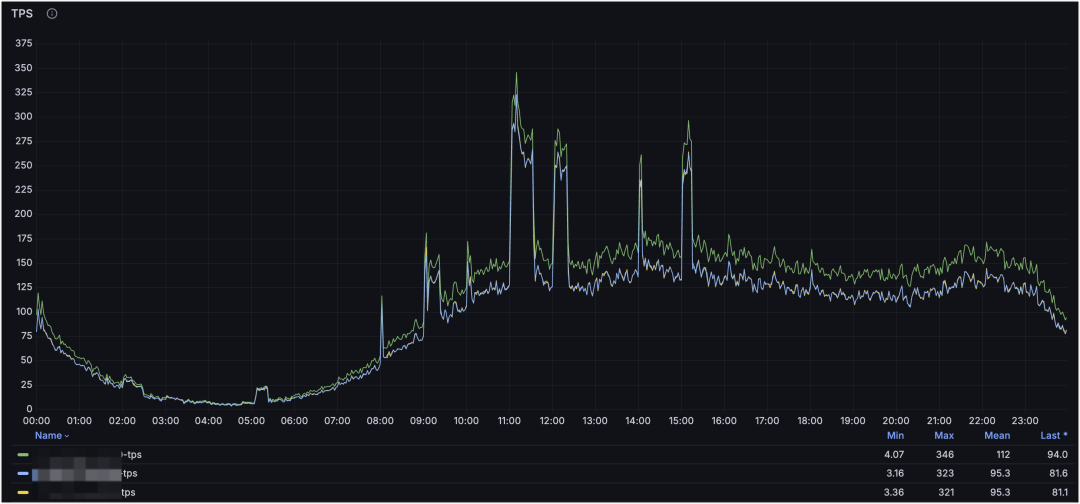
MySQL 集群 TPS 监控:
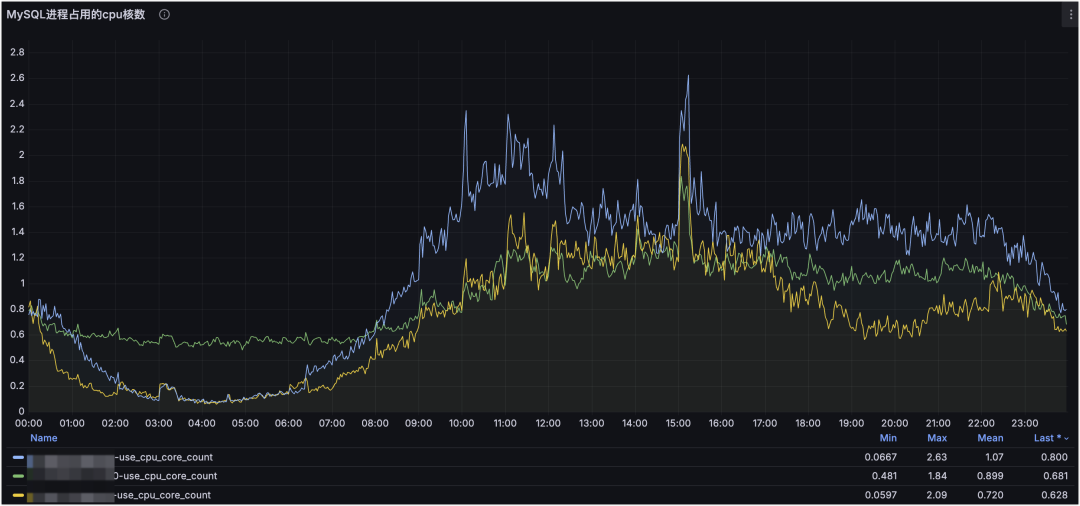
MySQL 进程占用的 CPU:
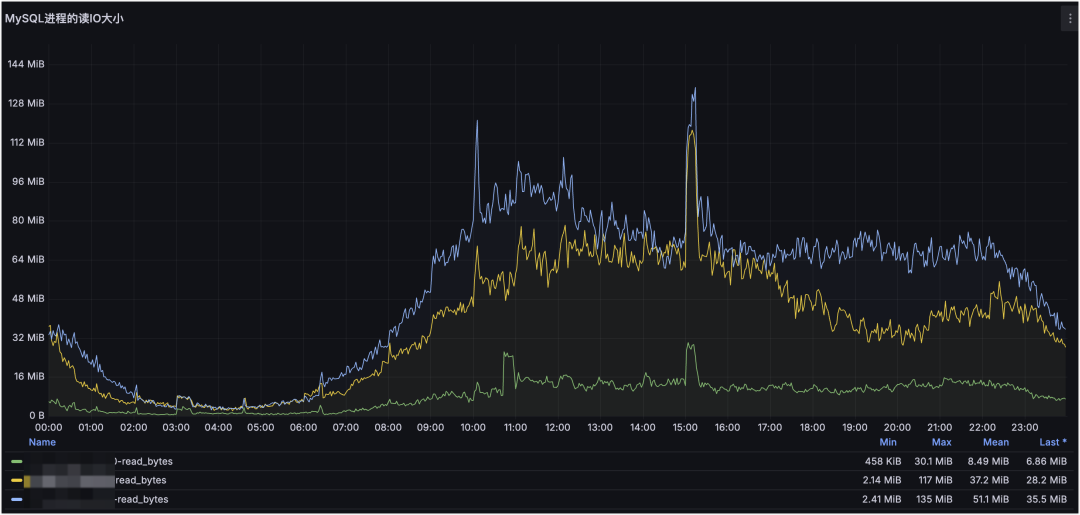
MySQL 进程占用的读 IO 大小:
MySQL 进程占用的写 IO 大小:
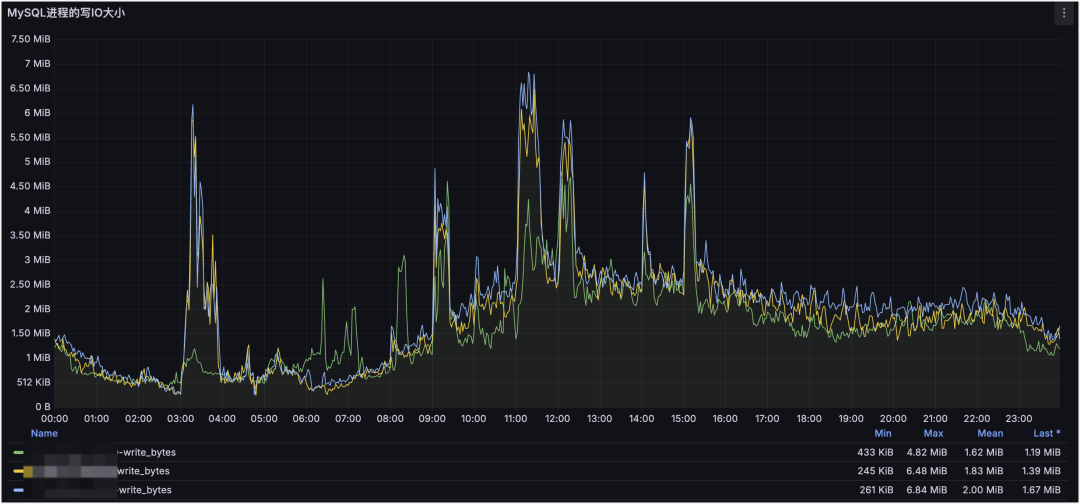
这是 MySQL 集群与进程维度的监控。通过集群维度可以看到整体请求走势,通过进程维度可以定位对服务器压力最大的 MySQL 进程(或其他进程),并结合请求类型判断是读还是写造成的。
进一步地,利用请求量与资源占用,还可以粗略评估服务器承载上限:
例如当前集群单节点请求量 QPS 峰值约为 4.5k,CPU 负载为 2.8 核;服务器 32 核,预留 2 核给系统与其他服务,CPU 最大使用率为 80%。在理想情况下(只考虑读以及 CPU 使用率),单节点可承载峰值 QPS 约为:
3080%/2.82.5k≈21w QPS。
示例三:资源容量评估,提前规划服务器
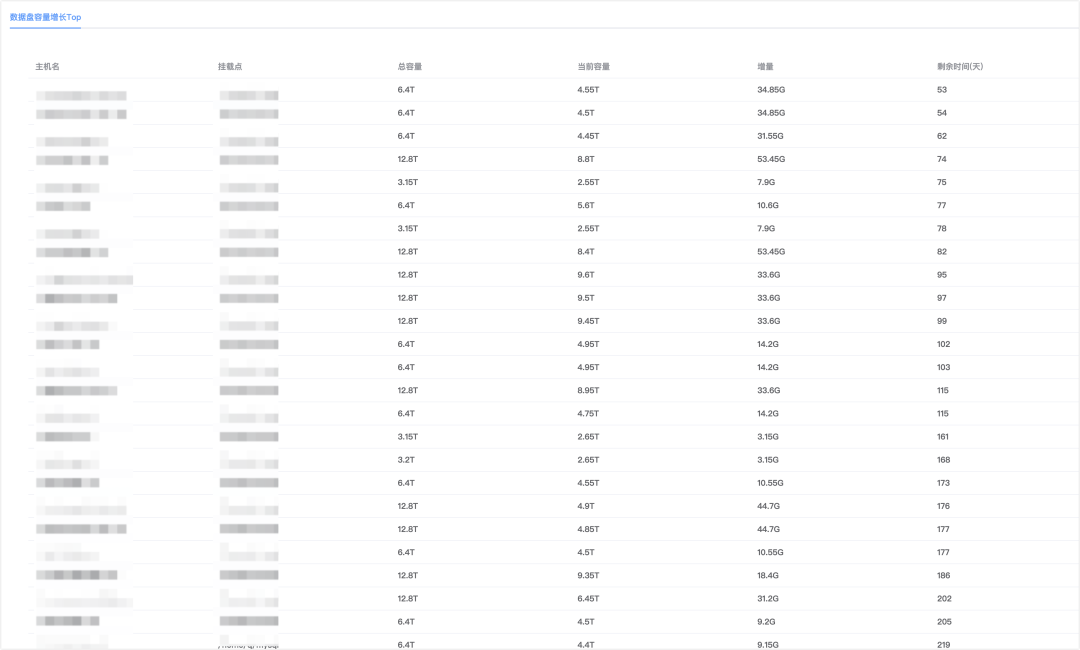
服务器数据盘容量评估报告:
MySQL 集群实例、库、表的数据采集:
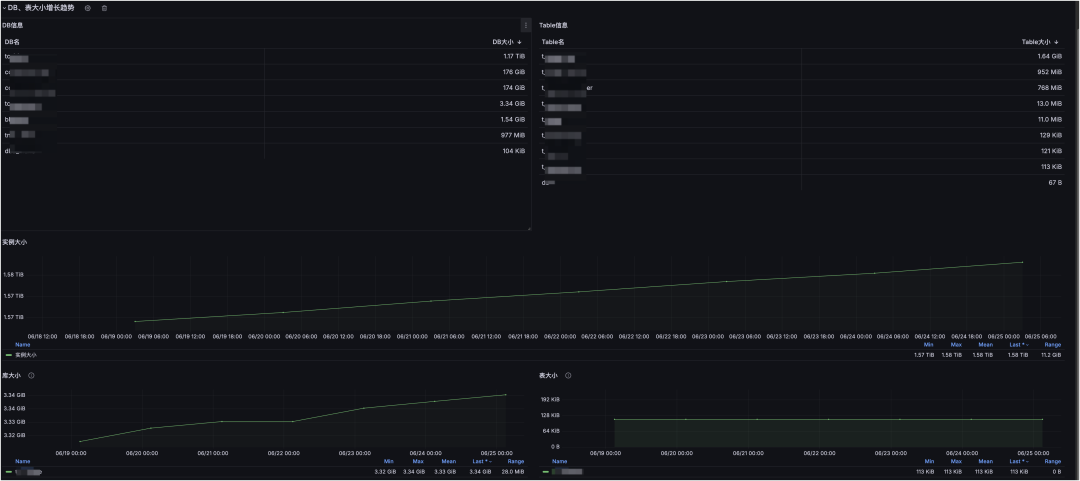
从容量评估报告可以看出服务器数据盘还能支撑多久;从实例/库/表采集可以定位最需要关注的库表,增量主要来自哪里。两者结合,可以更早做资源规划,避免“快满了才扩容”的被动局面。
示例四:主机和网络监控,排查抖动原因
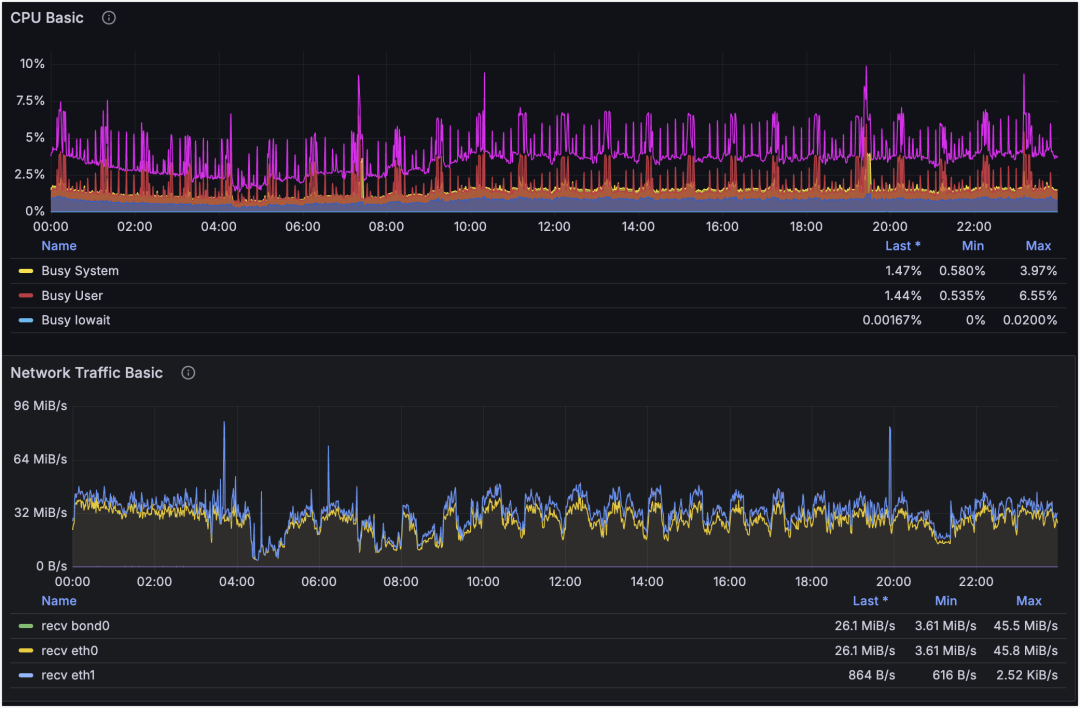
主机 CPU 和网卡流量维度监控:
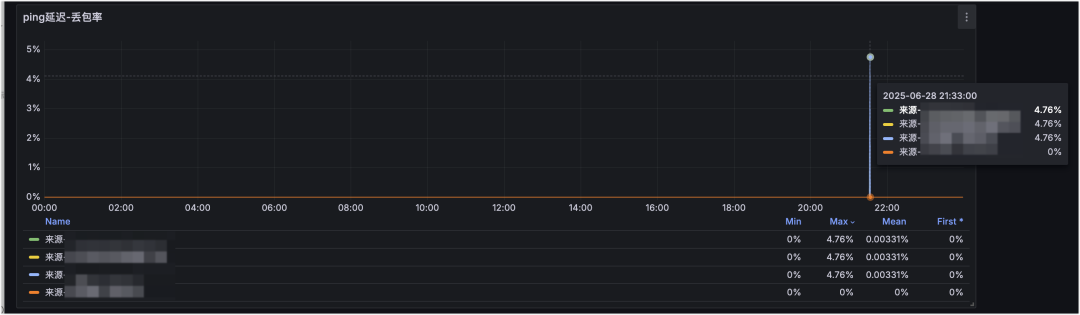
主机 ping 丢包率监控:
Redis 集群 QPS 和连接数监控:
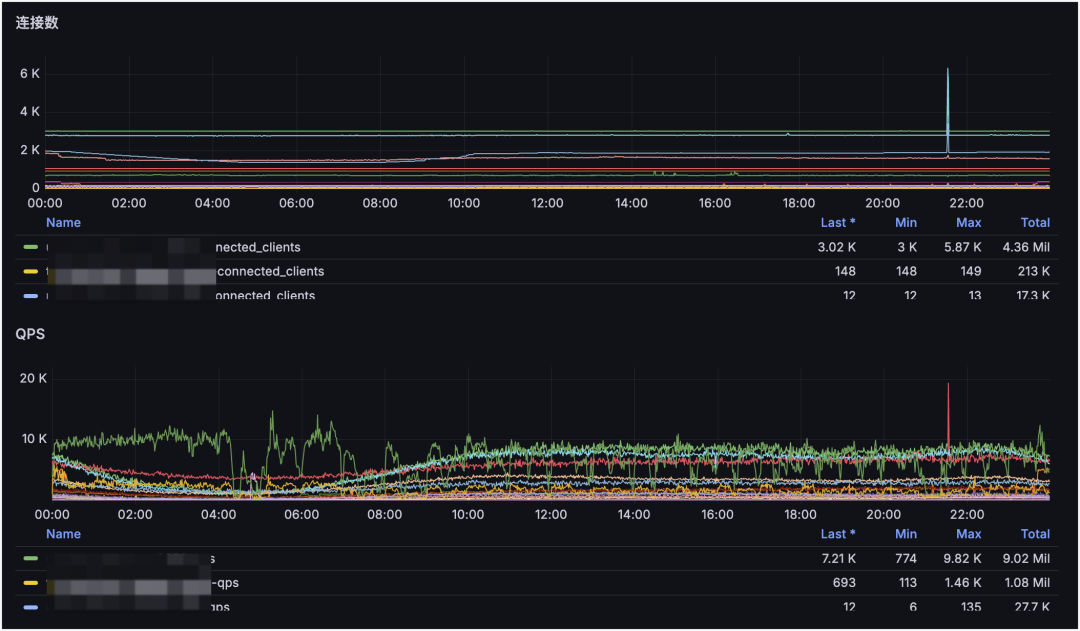
从主机监控看,21:33 时刻 CPU 和网卡波动不明显,但某业务的 Redis QPS 与连接数波动很大。再结合从不同 IDC 采集的丢包率监控,可以看到四条线路里有三条发生丢包。因此可判断:21:33 的业务抖动主要由网络抖动引起。
示例五:个性化定制标签,高维度汇总趋势图
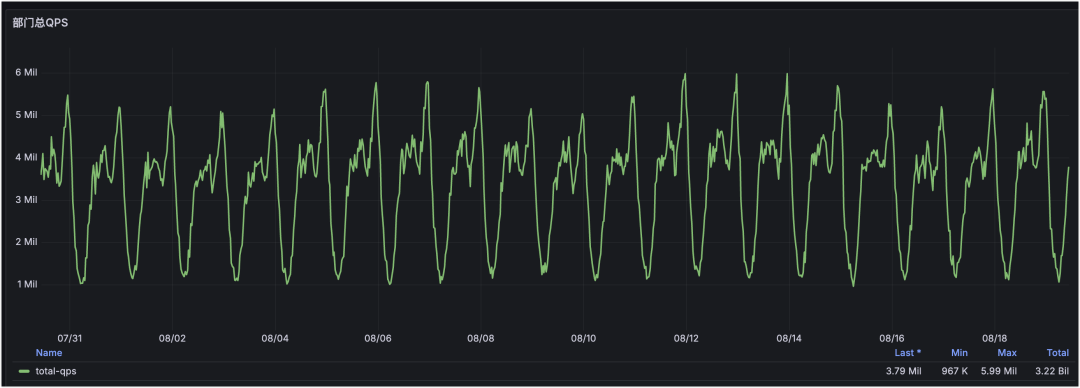
部门 Redis 请求 QPS 汇总:
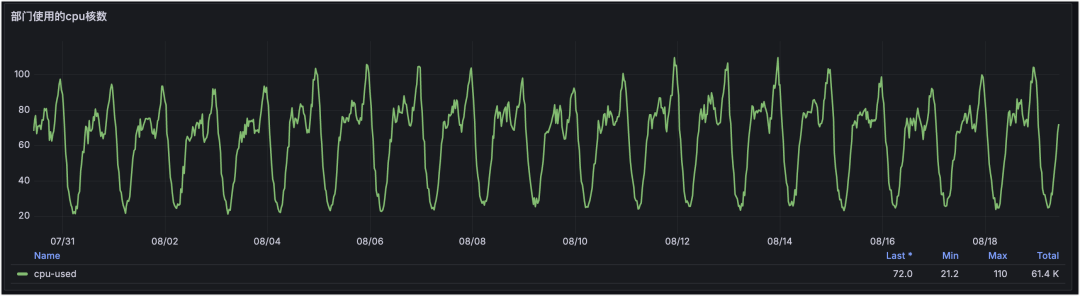
部门 Redis 使用 CPU 核数汇总:
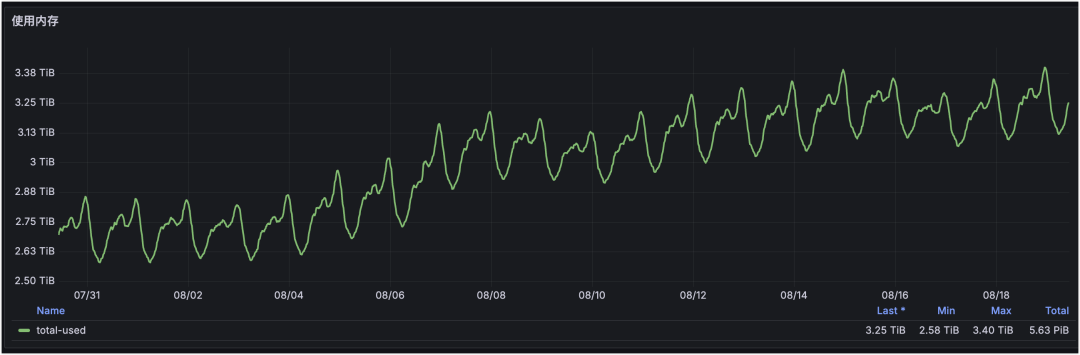
部门 Redis 使用内存汇总:
部门下 Redis 使用内存 Top:
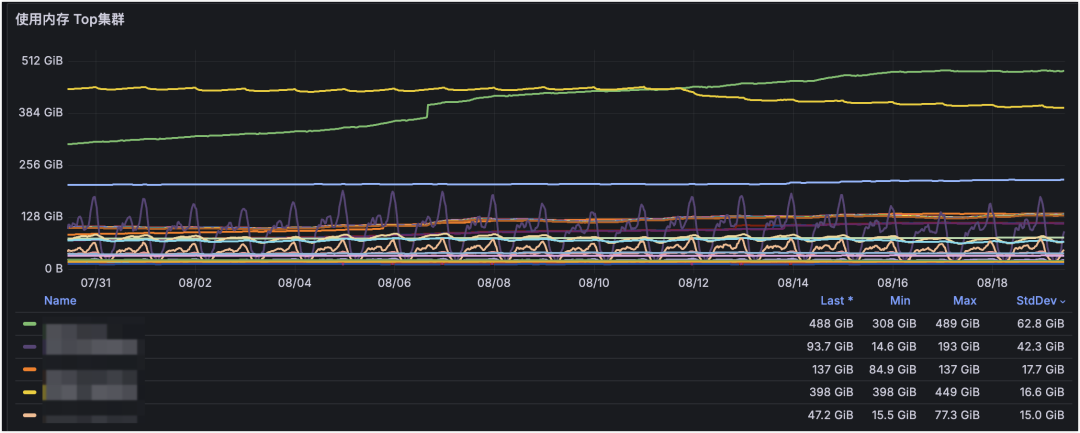
通过个性化标签可以实现高维度汇总,这是部门维度的 Redis 监控。通过定制化展示部门下 Redis/MySQL/服务器等资源使用量与增长趋势,可以基于趋势提前规划资源。
从图中可见:部门下 Redis 请求量与 CPU 使用率整体稳定,但内存使用量在逐步增长。再结合“内存 Top 集群”即可定位到是哪个集群容量在增长,并据此制定治理方案。
九、总结与展望
新的采集系统覆盖更完整的指标体系,并为指标补齐了更高层次的标签。基于标签聚合,可以得到更高维度的数据视角,为后续巡检、分析与报告提供稳定支撑。
告警系统通过优化探测流程与策略(分时阈值、动态检测频率、探测结果聚合、自愈下钻等),能够更精准、更及时地发现服务问题并通知负责人介入处理,尽可能满足公司“1-5-10”故障响应体系的要求。更多同类实践与讨论可在 云栈社区( https://yunpan.plus )延伸阅读与交流。
 发表于 2026-1-15 19:18:38
|
查看: 148|
回复: 0
发表于 2026-1-15 19:18:38
|
查看: 148|
回复: 0
