Linux 高性能网络编程中,epoll 凭借其优异的性能和稳定性,长期以来被视为高并发应用场景的首选。然而,随着 io_uring 这一异步 I/O 模型的出现,传统的认知正在被打破。
那么,epoll 与 io_uring 究竟有何异同?各自的技术原理是怎样的?谁又能提供更高的性能?本文将通过图解和测试,为您深入解析。
1. epoll 机制图解
epoll 的核心工作机制可以通过图 1 清晰地展示。
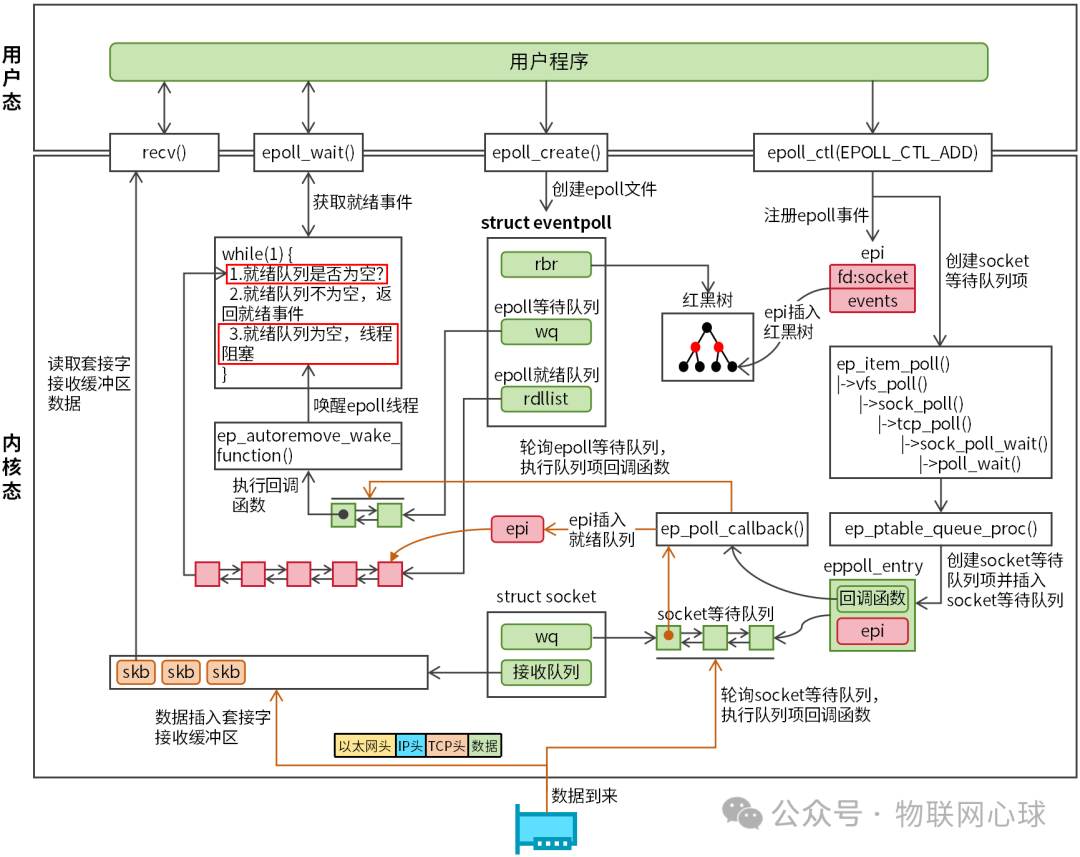
图 1: epoll 机制工作流程图
epoll 总共包含三个核心系统调用:epoll_create、epoll_ctl、epoll_wait。
epoll_create
epoll_create 用于在内核创建一个 eventpoll 对象(即 epoll 实例)并返回一个文件描述符(epfd),通过这个 epfd 可以快速访问该对象。eventpoll 对象的内核定义如下:
struct eventpoll {
wait_queue_head_t wq; // 等待队列
struct list_head rdllist; // 就绪队列
struct rb_root rbr; // 红黑树
......
};
该对象包含三个重要成员:
- wq(等待队列):内核通过此队列来唤醒被阻塞的 epoll 线程。
- rdllist(就绪队列):用于存储已就绪的 I/O 事件。
- rbr(红黑树):用于高效管理所有通过
epoll_ctl 注册的 I/O 事件。
epoll_ctl
epoll_ctl 用于向 epoll 实例中添加、修改或删除需要监控的文件描述符及其关联的事件。内核为每个注册的事件创建一个 struct epitem 结构体进行管理。
struct epitem {
union {
struct rb_node rbn; /* 红黑树节点*/
};
struct list_head rdllink; /* 就绪队列节点*/
struct epoll_filefd ffd; /* 文件描述符信息,包含fd和对应的file指针 */
int nwait;
struct eventpoll *ep; /* 指向所属的eventpoll实例 */
struct epoll_event event; /* 通过epoll_ctl设置的epoll_event事件 */
......
};
epitem 对象(图 1 中简称为 epi)是内核管理 epoll 事件的基本单元。当用户程序调用 epoll_ctl(操作类型为 EPOLL_CTL_ADD)时,内核会:
- 创建
epitem 对象,复制用户设置的事件信息。
- 将
epitem 对象插入红黑树。
- 创建一个 socket 等待队列项(
struct eppoll_entry),其中注册了回调函数 ep_poll_callback,并将该队列项插入目标 socket 的等待队列。这个回调函数用于在事件就绪时通知 epoll。
epoll_wait 与事件触发
完成事件注册后,用户程序调用 epoll_wait 获取就绪事件。该函数的核心工作是将就绪事件从内核空间拷贝到用户空间。其内部逻辑是一个循环:
- 检查就绪队列
rdllist 是否为空。
- 如果不为空,则将所有就绪事件拷贝到用户提供的
epoll_event 数组中。
- 如果为空,则创建一个 epoll 等待队列项,注册回调函数
ep_autoremove_wake_function(用于唤醒线程),并将线程阻塞。
当网络数据到达时,数据流经网卡、网络协议栈,最终存入套接字的接收缓冲区。此时,该 socket 的读事件就绪。内核会轮询其等待队列,执行 ep_poll_callback 回调函数,该函数负责:
- 将对应的
epitem 对象插入 epoll 的就绪队列 rdllist。
- 轮询 epoll 的等待队列
wq,执行 ep_autoremove_wake_function 回调函数,唤醒被阻塞的 epoll 线程。
线程被唤醒后,epoll_wait 将就绪队列中的事件拷贝给用户程序,用户程序随后便可以进行数据的读写操作。
epoll 的优缺点
优点:
- 无文件描述符数量限制,非常适合高并发场景。
- 采用事件驱动模型,无需主动轮询所有文件描述符。
缺点:
- 处理每个 I/O 事件通常都伴随着一次系统调用(如
read/write)。
- 本质上仍是同步 I/O(尽管在通知机制上是异步的),难以批量处理 I/O 操作,系统调用开销在高压力下成为瓶颈。
2. io_uring 机制图解
io_uring 是一种真正的异步 I/O 模型,其设计与同步 I/O 模型有显著区别。其工作原理如图 2 所示。
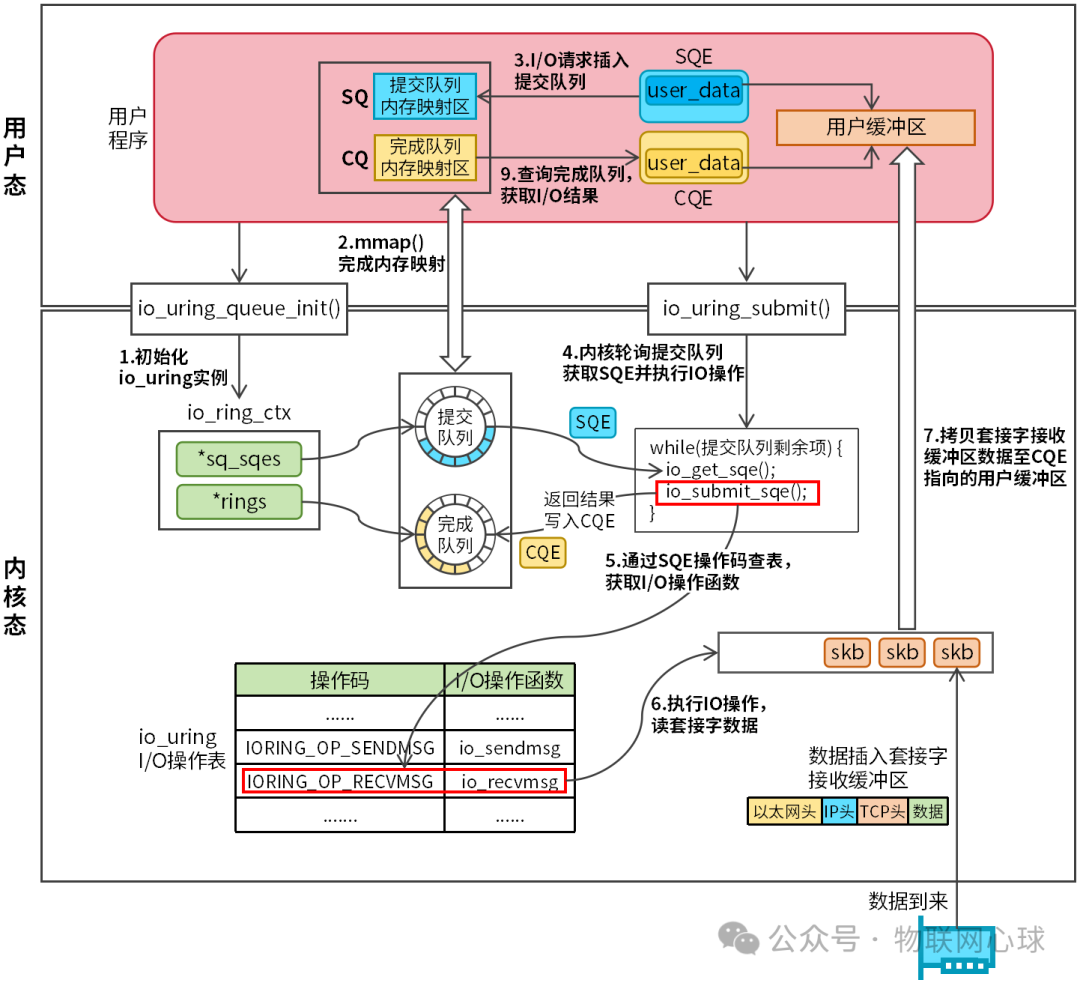
图 2: io_uring 异步 I/O 工作流程图
io_uring 本身也包含三个系统调用:io_uring_setup、io_uring_enter、io_uring_register。在实际开发中,我们更常使用 liburing 库,它对上述系统调用进行了友好封装,提供了更简洁的编程接口。
用户程序首先调用 io_uring_queue_init 函数(内部调用 io_uring_setup)创建并初始化一个 io_uring 实例(内核中为 struct io_ring_ctx)。
struct io_ring_ctx {
struct io_rings *rings; /* 指向完成队列CQ */
struct io_uring_sqe *sq_sqes; /* 指向提交队列SQ */
......
};
io_ring_ctx 结构复杂,其中最关键的两个成员是:
- rings:指向完成队列(CQ - Completion Queue)。
- sq_sqes:指向提交队列(SQ - Submission Queue)。
CQ 和 SQ 都是无锁环形队列。内核在初始化时,会从特殊的内存区域分配它们,并映射到用户空间。这使得用户程序和内核能够直接访问同一块内存区域,实现了零拷贝的数据交换通道,同时避免了锁竞争带来的开销。
内核维护了一张 io_uring I/O 操作表,定义了所有支持的操作(如读、写、接受连接等)。
/* 内核io_uring I/O操作表 */
const struct io_issue_def io_issue_defs[] = {
......
[IORING_OP_SENDMSG] = {
.needs_file = 1,
.unbound_nonreg_file = 1,
.pollout = 1,
.ioprio = 1,
.async_size = sizeof(struct io_async_msghdr),
.prep = io_sendmsg_prep,
.issue = io_sendmsg,
},
[IORING_OP_RECVMSG] = {
.needs_file = 1,
.unbound_nonreg_file = 1,
.pollin = 1,
.buffer_select = 1,
.ioprio = 1,
.async_size = sizeof(struct io_async_msghdr),
.prep = io_recvmsg_prep,
.issue = io_recvmsg,
},
......
}
每个 I/O 请求都有一个操作码,内核根据此操作码查表,找到对应的函数并执行。
io_uring 执行一个异步 I/O 操作的典型流程为:
- 提交请求:用户程序从 SQ 中获取一个空闲的提交队列项(SQE),设置操作码(如读、写)和用户数据,然后调用
io_uring_submit(内部可能调用 io_uring_enter)批量提交一个或多个 SQE。
- 内核执行:内核线程从 SQ 中取出 SQE,根据操作码查表找到对应的 I/O 函数并执行。操作完成后,内核在 CQ 中生成一个完成队列项(CQE),存放操作结果。
- 收割结果:用户程序轮询 CQ,从中取出 CQE,并根据其中存储的
user_data 关联到原始请求,处理 I/O 结果。
io_uring 的优缺点
优点:
- 共享内存与零拷贝:SQ/CQ 通过内存映射共享,避免了用户态与内核态之间的多次数据拷贝。
- 批处理:支持一次提交和收割多个 I/O 请求,极大减少了系统调用次数。
- SQPOLL 模式:可以启动一个内核线程主动轮询 SQ,用户程序在提交请求时甚至可能完全无需系统调用。
缺点:
- 作为一种较新的机制,其在某些极端场景下可能还存在稳定性问题或 Bug,需要持续的迭代和优化。
3. epoll 与 io_uring 性能对比测试
两者在理论模型上的对比如下表所示。
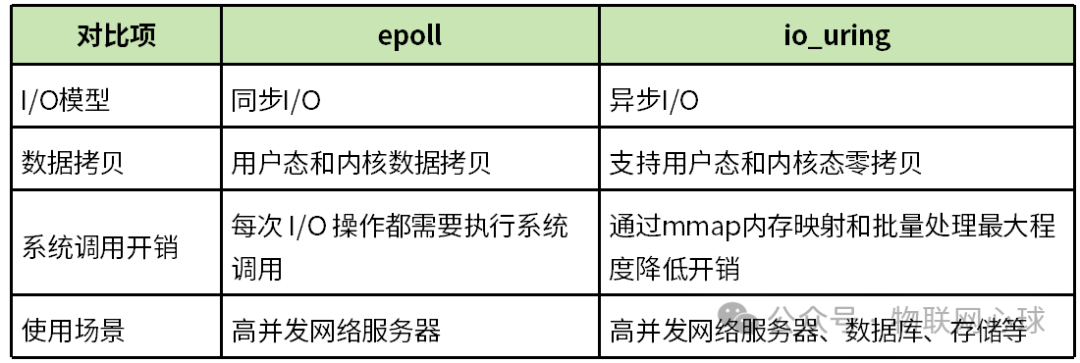
表 1: epoll 与 io_uring 特性对比
从表 1 可知,io_uring 在数据拷贝和系统调用开销方面理论上优于 epoll。下面通过一个实际的性能测试来验证。
3.1 测试环境
- 客户端:AMD Ryzen 7 8845HS,8核16线程,24G内存。
- 服务端:12th Gen Intel Core i5-12500H,8核16线程,16G内存。
- 网络:1Gbps 局域网。
3.2 测试用例
TCP 客户端创建 50 个线程,每个线程与服务器建立 20,000 个 TCP 连接,总计 100 万个并发连接。每个连接发送并接收 100 个数据包(每个包 100 字节)。
服务端分为两个版本:epoll 服务端和 io_uring 服务端。使用 strace -c 命令分别统计两者在处理百万连接过程中的系统调用情况。strace -c 命令的输出示例如下:
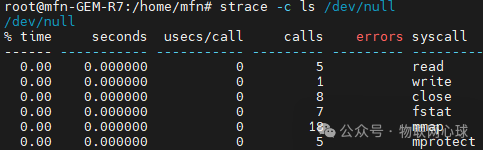
输出各列含义:
% time:该系统调用耗时占总时间的百分比。seconds:该系统调用总耗时(秒)。usecs/call:每次调用平均耗时(微秒)。calls:总调用次数。errors:调用失败次数。syscall:系统调用名称。
3.3 测试结果
(1)epoll 服务端测试结果
执行 strace -c ./tcp_epoll 192.168.2.2 9999 后,关键统计结果如下:
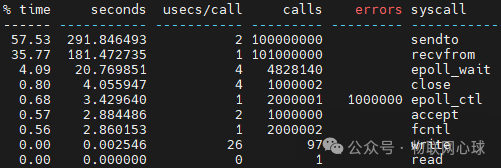
可以看到,epoll 服务端的总系统调用次数高达 2.11 亿次。除了 sendto 和 recvfrom 超亿次,epoll_wait、epoll_ctl 等调用也达数百万次。完成百万连接测试用时 632,008 毫秒。
(2)io_uring 服务端测试结果
执行 strace -c ./io_uring_server 192.168.2.2 9999(开启批处理和 SQPOLL 模式),关键统计结果如下:
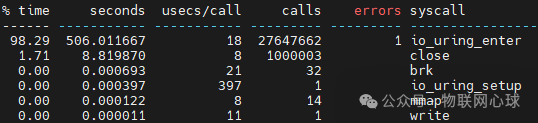
在优化模式下,io_uring 服务端的总系统调用次数降至 2864 万次,其中 io_uring_enter 调用占比 98%。完成百万连接测试用时 626,473 毫秒。
3.4 结果分析
对比可知,epoll 服务端的系统调用次数远高于 io_uring 服务端。如果每次系统调用的开销约为 1 微秒,那么数千万次的差异将直接转化为数十秒的性能差距。测试结果也印证了这一点,io_uring 在处理海量并发连接时,凭借其异步、批处理和零拷贝的特性,有效降低了系统调用和上下文切换的开销,从而获得了更优的性能表现。
总结
epoll 作为久经考验的成熟模型,在稳定性和兼容性上仍有不可替代的优势。而 io_uring 代表了 Linux I/O 的未来方向,尤其在对极限性能有要求的场景下(如高性能网络编程、数据库、存储系统),展现出巨大潜力。开发者可以根据具体应用场景和性能需求,在二者之间做出选择。对于希望深入理解这些底层机制并动手实践的开发者,可以参考相关的系统编程与C语言资料进行学习。更多关于 Linux 高性能网络开发的深入讨论,欢迎访问云栈社区与广大开发者交流。
 发表于 2026-1-16 04:55:48
|
查看: 151|
回复: 0
发表于 2026-1-16 04:55:48
|
查看: 151|
回复: 0
