引言
随着技术演进,从SQL查询到AI推理,数据处理方式正经历革新。本文将探讨如何在保持系统稳定性的前提下,通过SQL与AI接口实现高效可靠的数据处理流程。
背景:在复杂中追求简洁
长期的项目实践表明,复杂的运维流程与多系统环境往往导致协作障碍与效率损耗。这种经验积累催生了"极简主义"技术理念——用最精简且可靠的工具应对多样化场景。
SQL、Bash与Python成为跨环境开发的核心支柱,体现了高稳定性、高效率与强可移植性的技术哲学。
接口演进:从SQL到AI
在软件开发与数据分析中,接口是实现人机交互的核心桥梁。
SQL:稳定的数据接口
SQL自1970年代以来一直是数据操作中最稳定的核心工具,通过标准化方式将人类需求转化为数据库执行计划。
SQL的接口特性:
- 描述"想要什么",而非"如何实现"
- 数据表提供直观可视化表示
- 标准化操作(尽力而为)
- 从查询到报表完整流程
- 隐藏底层复杂性
- EXPLAIN PLAN提供有限洞察
AI:自然语言与推理的新接口
AI接口是SQL理念的延伸与升级,能够理解自然语言,进一步降低操作门槛。
AI的接口特性:
- 理解自然语言描述:可生成查询或执行计划
- 执行与智能推理:处理复杂数据和逻辑推理
- 延续SQL接口哲学:只需描述需求,系统负责实现
核心转变:从执行计划到推理计划
在高级AI应用中,执行计划与推理计划呈现对应关系。用户通过提示词获得结果,再对结果进行组合优化,这本质上是推理逻辑的编排,而不仅仅是操作执行。
现状分析:LLM框架的挑战
复杂的生态与过度抽象
当前大模型生态技术迭代速度过快,主要表现为:
- 行业缺乏统一标准与稳定范式
- 经验方法更新频率高,难以长期复用
- HOW-TO类资料因工具更新而快速过时
- 不同模型性能依赖具体场景
- 各LLM框架引入额外复杂度和学习成本
历史对比:LLM框架与ORM的相似性
LLM框架类似于80年代的ORM:
- ORM提供SQL抽象封装,但底层原理仍需掌握
- LLM框架提供抽象接口,但早期依赖掩盖底层逻辑
- 当前框架过度封装,增加不必要的复杂性
LLM框架存在的问题:
- 过度自信与复杂化
- 死板抽象使问题难以理解
- 强制框架化增加学习成本
- 简单任务需要冗长步骤
- 限制操作灵活性
- 阻碍底层原理理解
SQL的持久价值
面对快速变化的AI生态,SQL依然是数据访问和处理的核心接口。数十年来,SQL的声明式语法和标准化特性使其在复杂系统中保持可靠。
SQL不仅是查询语言,更是系统编排者。在AI应用中,模型的推理流程与SQL执行计划存在对应关系,通过SQL结构化操作可有效管理AI推理过程。
技术本质:AI即相似度搜索
当前大模型及AI应用的核心机制可归结为"相似度搜索",基本流程:
- 输入文本切分成tokens
- 通过向量化模型生成向量表达
- 存储数据向量进行相似度比对
- 根据得分返回结果
核心概念
- tokens:文本最小单元
- vectors:语义向量表示
- documents:文档或数据片段
PostgreSQL的预先能力
向量检索思想对数据库从业者并非全新概念。PostgreSQL在十余年前就通过全文检索实现了类似能力:
SELECT 'a fat cat sat on a mat'::tsvector @@ 'cat & rat'::tsquery;
全文检索流程同样依赖文本分词、构建词典、生成向量化表示。区别在于:
- 过去依赖本地语料构建的词典与向量
- 现在依托更大规模的语言模型语料与向量空间
实战应用:上下文构建策略
多层封装架构
现代AI应用普遍构建在大模型框架之上,外层工具不断叠加新的包装接口,形成"套娃式"技术结构。
上下文的关键作用
上下文长度直接影响推理结果的完整性与连续性。随着上下文窗口不断扩大,数据组织方式与调用策略相应调整。
提示词构建:数据连接艺术
上下文构建决定模型效果的核心环节,本质上是数据Join的组合工程。在客户服务、电商等场景中,约80%工作是从数据库中筛选关键字段,剔除无关内容。
基于字符串的模板化构建
上下文构建主要依赖字符串拼接与模板化处理。SQL格式化函数、标准字符串模板引擎即可满足大部分生产需求。
复杂度分配策略
在设计业务流时,不必在应用层堆叠大量逻辑判断。大模型具备强大推理能力,适合承担复杂推断工作,应用层应聚焦准备精简准确的输入数据。
PostgreSQL集成:简化数据链路
通过PostgreSQL扩展生态,可将多种数据处理集成到数据库内部,减少跨系统数据搬运。
PDF解析:非结构化数据提取
借助pgPDF扩展,PostgreSQL可直接读取并解析PDF文件:
CREATE EXTENSION pgpdf;
SELECT '/path/to/my.pdf'::pdf;
HTTP请求:外部数据获取
利用http扩展,在数据库内直接发起API请求:
CREATE EXTENSION http;
SELECT http_post('http://myprovider');
这种集成方式减少:
- 系统间数据传输延迟
- 应用层额外逻辑与依赖
- 链路增长导致的失败点
Unix哲学在现代数据处理中的应用
核心原则
Unix哲学强调以最小单元构建工具,通过清晰接口协同完成复杂任务,在数据密集型场景中依然适用。
工具组合实践
以下工具链覆盖大量数据处理场景:
- curl:获取本地或远程API数据
- jq:处理JSON结构
- xargs:批量或并行处理
- psql:与PostgreSQL交互
实际项目示例
通过Makefile驱动数据处理流程:
- 生成时间区间
- 拉取与分组数据
- 构建JSON数据
- 向量化处理
- 结果写回PostgreSQL
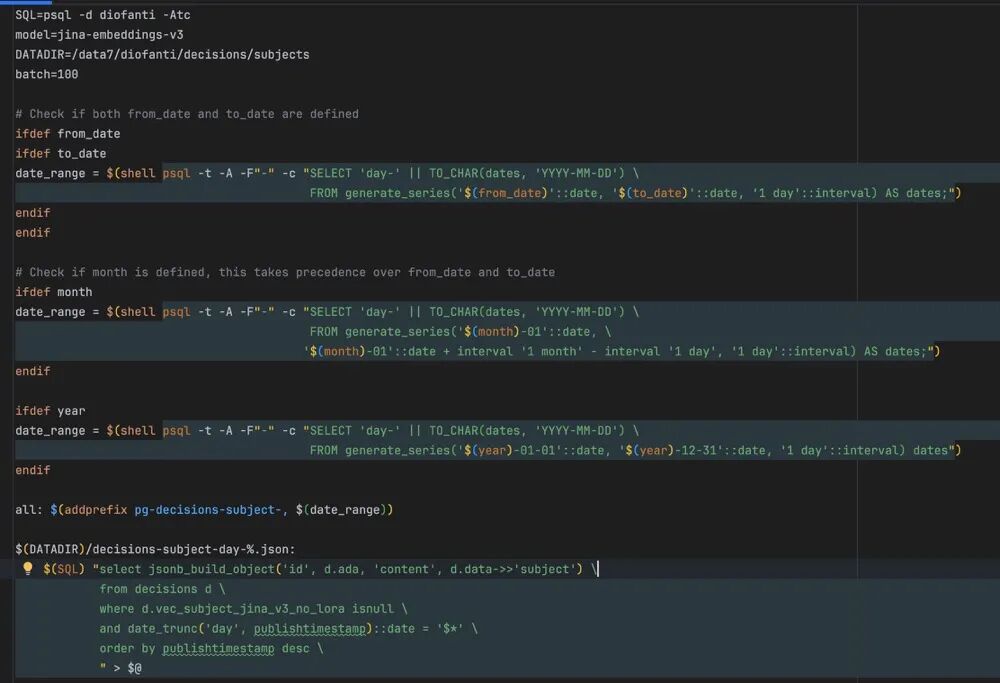
流程以JSON为中间格式,PostgreSQL作为统一存储,避免额外数据搬移。
命令行数据流水线
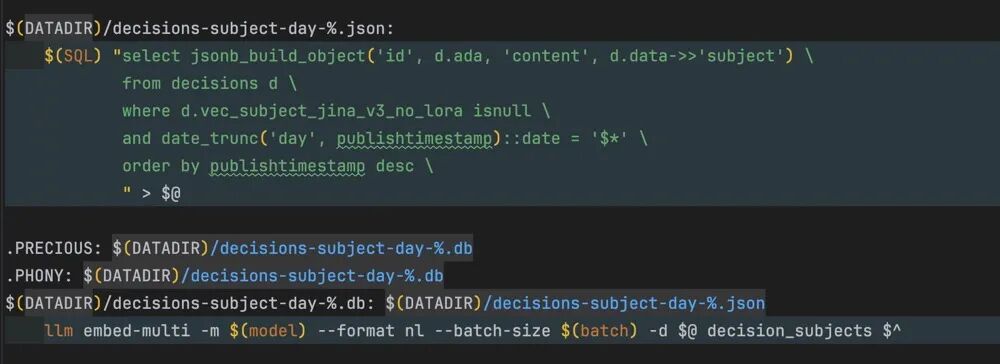
通过命令行工具操作PostgreSQL实现自动化:
- 使用通配符灵活查询数据
- 本地LLM处理数据并生成聚合结果
- 为每天创建独立数据库
- 命令行管道实现数据流闭环
LLM集成处理
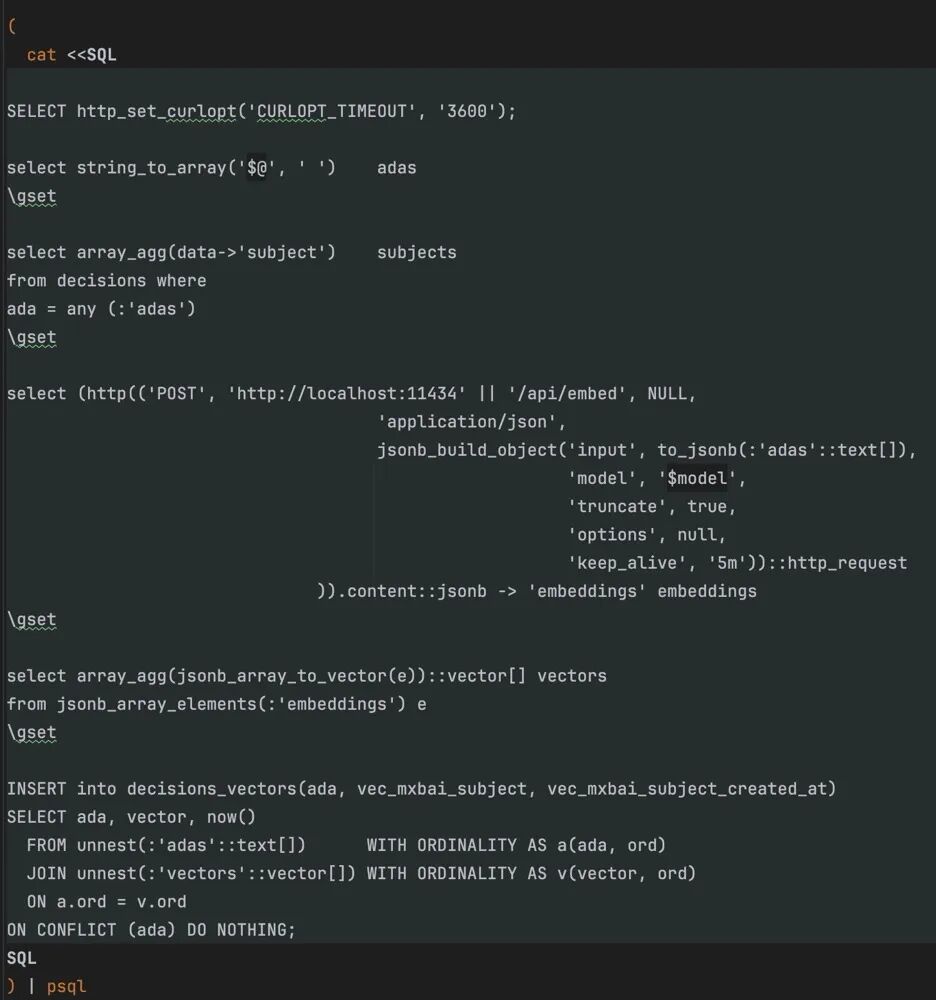
本地LLM对文本、集合或结构化数据进行处理聚合,生成信息并向量化,结果直接写入PostgreSQL,利用数据库索引和聚合能力完成优化。
总结
SQL与AI的结合展示了简化复杂、提升效率的显著价值。深入理解底层原理并合理运用工具组合,才能在快速演进的技术生态中保持掌控力与高效性。
 发表于 2025-11-29 02:26:18
|
查看: 206|
回复: 0
发表于 2025-11-29 02:26:18
|
查看: 206|
回复: 0
