虽说 LLM 发展很快,但在根因分析(RCA)这个领域,核心还是要看底层的数据建设以及经验沉淀。如何把资深工程师脑子里的独门秘籍沉淀为代码、产品,是自动化 RCA 成功的关键因素之一。Meta 的 DrP 平台,或许能给我们带来一些启发。
原文:DrP: Meta's Root Cause Analysis Platform at Scale
作者:Shubham Somani, Vanish Talwar, Madhura Parikh, Chinmay Gandhi
发布时间:2025 年 12 月 19 日
在当今的数字化环境中,大型系统往往由众多相互关联的组件和依赖项构成,一旦出现故障,排查起来往往令人头疼不已。
DrP 是 Meta 自主研发的根因分析(RCA)平台,旨在将故障排查流程程序化、自动化,从而大幅缩短平均修复时间(MTTR),同时减轻 on-call 工程师的工作负担。目前,DrP 已在 Meta 内部被超过 300 个团队广泛使用,每天执行 5 万次分析任务,成功将 MTTR 降低了 20% 到 80%。
深入了解 DrP 及其能力,有助于我们探索更高效的故障处理方式,进一步提升系统可靠性。
什么是 DrP
DrP 是一个端到端的平台,专为大规模系统的故障排查自动化而设计。它解决了传统人工排查方式的诸多痛点——过时的运维手册、临时拼凑的脚本,这些做法不仅导致故障恢复时间拉长,还让 on-call 工程师在问题定位和调试上耗费大量精力。
DrP 提供了一套完整的解决方案:通过表达力强且灵活的 SDK,工程师可以编写结构化的排查剧本(称为 analyzer)。这些 analyzer 由可扩展的后端系统执行,并与告警系统、事件管理工具等主流工作流无缝集成。此外,DrP 还配备了后处理系统,可根据分析结果自动执行修复操作。
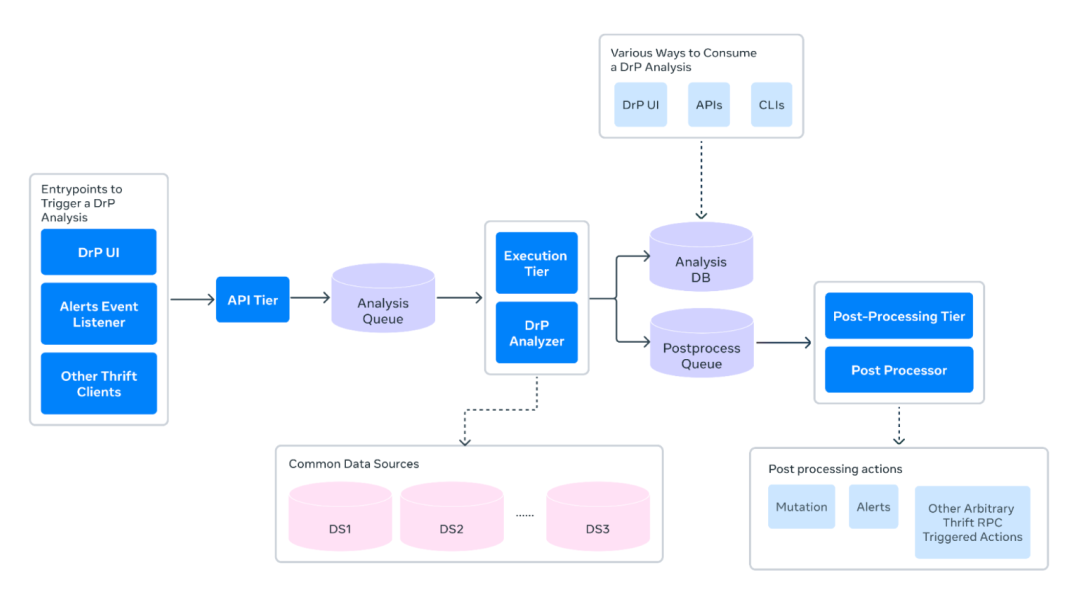
DrP 的核心组件包括:
- 表达力强的 SDK:DrP SDK 让工程师能够将排查流程编码为 analyzer。它提供了丰富的辅助库和机器学习算法,用于数据访问和问题定位分析,如异常检测、事件隔离、时序相关性分析和维度分析等。
- 可扩展的后端系统:后端系统负责执行 analyzer,支持多租户和隔离执行环境,确保每天能够处理数千次自动化分析任务。这套系统的设计理念与构建稳定、高效的 运维与DevOps架构 一脉相承。
- 与工作流深度集成:DrP 与告警和事件管理工具紧密集成,支持在事件发生时自动触发 analyzer,让 on-call 工程师第一时间获得分析结果。
- 后处理系统:分析完成后,后处理系统可根据分析结果自动执行相应操作,例如创建任务或提交 PR 来修复发现的问题。
工作原理
编写流程

创建自动化排查剧本(analyzer)的过程从 DrP SDK 开始。工程师需要梳理排查步骤,列出输入参数和可能的问题定位路径。SDK 提供了相应的 API 和库,帮助工程师将这些流程编码,并以类型安全的方式捕获所有必要的输入参数和上下文信息。
- 梳理排查步骤:工程师首先列出排查事件所需的步骤,包括输入参数和定位问题的可能路径。
- 生成模板代码:DrP SDK 提供脚手架工具,可创建预填充样板代码的 analyzer 模板。工程师在此基础上扩展,补充所有必要的输入参数和上下文。
- 数据访问与分析:SDK 内置了数据访问和分析库,如维度分析和时序相关性分析。工程师利用这些库,将主要的排查决策树编码到 analyzer 中。这些分析往往需要查询各种 数据库和中间件 来获取关键指标。
- Analyzer 链式调用:针对依赖服务的分析,SDK 的 API 支持 analyzer 之间的无缝串联,传递上下文并获取输出结果。
- 输出与后处理:输出方法用于捕获分析结论,采用特殊数据结构支持文本和机器可读两种格式。后处理方法则根据分析结论自动执行相应操作。
analyzer 编写完成后,需要经过测试并提交代码审查。DrP 提供了与代码审查工具集成的自动化回测功能,确保 analyzer 在部署前达到质量标准。
使用流程
在生产环境中,analyzer 与 UI、命令行工具、告警系统和事件管理系统等工具深度集成。当告警触发时,analyzer 可自动执行,立即向 on-call 工程师提供分析结果,显著提升响应速度。DrP 后端通过请求队列和工作池来管理执行过程,结果以异步方式返回。
- 与告警集成:DrP 与告警系统集成,告警触发时可自动执行 analyzer,为 on-call 工程师即时提供分析结果。
- 执行与监控:后端系统通过请求队列和工作池管理 analyzer 的执行,确保运行安全高效,并提供执行监控。
- 后处理与洞察:独立的后处理系统负责处理分析结果,并将结论标注到告警上。DrP Insights 系统会定期分析输出数据,识别并排序最常见的告警根因,帮助团队确定可靠性改进的优先级。
价值与意义
缩短 MTTR
DrP 已在多个团队和场景中展现出显著的 MTTR 优化效果。通过将人工排查自动化,DrP 加速了问题定位和修复,系统恢复更快,可用性更高。
- 提升效率:自动化排查减少了工程师在人工定位上花费的时间,让他们能专注于更复杂的任务。效率的提升直接转化为更快的故障解决速度和更短的停机时间。
- 保证一致性:将排查流程编码为 analyzer,确保了排查过程的一致性和可重复性,降低了人为失误的概率,提高了故障解决的可靠性。
- 良好的扩展性:DrP 每天可处理数千次自动化分析,完全能够支撑具有复杂依赖关系的大规模系统,随着组织规模的增长持续发挥作用。
提升 On-Call 效率
DrP 的自动化能力大幅减少了排查过程中的 on-call 工作量,节省了工程师的时间,缓解了 on-call 疲劳。通过自动化那些重复且耗时的步骤,工程师可以将精力集中在更具挑战性的任务上,整体生产力得以提升。
规模化落地
DrP 已在 Meta 大规模部署,覆盖超过 300 个团队,拥有 2000 多个 analyzer,每天执行 5 万次自动化分析。它与告警系统等主流工作流的深度集成,推动了广泛的采用,并在实际场景中充分证明了其价值。这种将复杂排查逻辑产品化的实践,对于构建高可用的 后端与分布式系统 具有重要参考意义。
- 广泛采用:DrP 已被数百个不同领域的团队采用,展现了其在满足多样化排查需求方面的通用性和有效性。
- 效果验证:DrP 已在生产环境运行超过五年,在缩短 MTTR 和提升 on-call 效率方面成效显著,用户反馈积极,故障解决时间大幅缩短。
- 持续演进:DrP 不断迭代升级,持续优化机器学习算法、SDK、后端系统和集成能力。这种持续改进的投入确保了 DrP 始终是故障排查领域的前沿方案。同时,随着越来越多团队的加入,现有的工作流和 analyzer 可以被其他团队复用,共享知识库不断壮大,平台价值也随之倍增。
未来展望
展望未来,DrP 将向 AI 原生平台演进,在推进 Meta 更广泛的 AI4Ops 愿景中扮演核心角色,实现更强大的自动化排查能力。这一转型将通过更精准、更深入的分析结果提升排查质量,同时通过简化机器学习算法、SDK、UI 和集成方式来优化用户体验,让 analyzer 的编写和执行更加轻松便捷。
延伸阅读
- DrP: Meta's Efficient Investigations Platform at Scale(论文)
提问 AI
普通公司的体量一般都没有 meta 的体量大,你觉得普通公司能从这篇文章中学到什么?
这是个很实际的问题。Meta 的规模(每天 5 万次分析、2000+ analyzer)确实遥不可及,但这篇文章背后的核心理念对任何规模的公司都有借鉴价值:
可以借鉴的核心思路
1. 把排查经验从“脑子里”搬到“代码里”
这是最重要的一点。很多团队的排查知识存在于:
一旦人员变动,这些知识就流失了。即使没有专门的平台,用脚本把常见问题的排查步骤固化下来,也是巨大的进步。
2. 从高频告警入手
不需要一开始就搞大平台。统计一下哪些告警最频繁、最耗时,先把这几个的排查流程脚本化。比如:
- 磁盘满了 → 自动检查哪个目录占用最多、是否有大日志文件
- 服务响应慢 → 自动抓取当时的 CPU、内存、连接数、慢查询
3. 告警触发时自动执行诊断
很多告警系统(如 Prometheus Alertmanager、Nightingale 等)都支持 webhook。告警触发时调一个脚本,把诊断结果直接附在告警通知里,on-call 拿到的就不只是“CPU 高了”,而是“CPU 高了,top 3 进程是 xxx”。
4. 结构化输出,便于复盘
排查结果不要只是一坨文本,最好有结构化格式。这样事后可以统计:哪类问题最常见、根因分布是什么、哪些服务最不稳定。
5. 鼓励复用,形成知识飞轮
A 团队写的数据库排查脚本,B 团队大概率也能用。建立共享机制,让排查能力成为组织资产而非个人资产。
落地建议
| Meta 的做法 |
普通公司的简化版 |
| DrP SDK |
用 Python/Shell 脚本 |
| 可扩展后端 |
Cron + 脚本,或 Jenkins pipeline |
| 与告警集成 |
Webhook + 脚本 |
| 机器学习算法 |
简单阈值判断,或用开源异常检测库 |
| 2000+ analyzer |
先搞 10 个高频场景 |
总结:这篇文章的价值不在于 DrP 这个平台本身,而在于“将排查流程程序化”这个思路。哪怕只用最简单的脚本,只要能把经验沉淀下来、让机器代替人做重复劳动,就已经抓住了精髓。在 云栈社区 ,你也可以找到更多关于自动化运维和故障排查的实战讨论与资源。
 发表于 2026-1-16 07:20:14
|
查看: 239|
回复: 0
发表于 2026-1-16 07:20:14
|
查看: 239|
回复: 0
