概述
伴随着大模型性能的提升与成本的下降,其应用场景已不再局限于网页端的在线对话。越来越多的传统业务系统开始寻求集成大模型能力,以创造新的价值。
在大模型的 API 交互模式与业务集成模式经历“百家争鸣”并逐渐趋于稳定之后,作为 Java 生态系统中的开源巨头,Spring 框架也正式入场,为大型语言模型(LLM)提供了官方的生态支持,并于近期发布了 spring-ai 的正式版本。
需要明确的是,Spring-AI 所提供的能力本身并不神秘,从业务实现的角度看,也并非非用不可。然而,正如 Spring 过去对各种新型数据库和中间件提供的支持一样,Spring-AI 的核心价值在于:它为 Java 开发者提供了一套与 Spring 全家桶深度兼容、设计良好、语义统一且易于扩展的大模型交互 API。这套 API 能够显著降低在 Java 应用中集成和开发 LLM 功能的成本。
从工程化与实用化的角度来看,当你理清了 Spring-AI 这套 API 设施的设计逻辑后,事情的本质最终会回归到业务开发者最熟悉的领域。就如同使用 MyBatis 操作 MySQL 数据库一样,未来我们很可能会习惯使用 spring-ai 来“操作”大模型。
那么,让我们开始今天的探讨。
什么是大模型
大模型的舞台上从来不缺少新面孔。自 ChatGPT 拉开 AI 新时代的帷幕以来,各类大模型如雨后春笋般涌现。
但我们暂时不去深究大模型背后复杂的训练原理、推理架构或参数调优等数学层面的内容。这就像我们日常使用数据库时,很少去关心 MySQL 的源码是如何实现的一样。
在此,我们尝试用熟悉的知识进行类比,旨在对大模型建立一个基础、直观且能自洽的认知。
- 从某种意义上说,模型训练就是通过分析海量文本数据(如维基百科、书籍、网页等)来寻找人类语言的规律,并将这个规律固化成一个包含数十亿甚至更多“参数”的超级“数学公式”。就像简单公式
y = 5x + 8 中的 5 和 8,这两个“参数”决定了如何将输入 X 转化为输出 Y。
- 训练好的这个“数学公式”就像一段复杂的代码,需要部署在强大的算力平台上,并借助显卡(GPU)的并行计算能力来实现高效推理。
- 用户的输入作为这个“数学公式”的入参,经过公式运算后,得到相应的“输出”。

我们可以假设大模型就是上述的数学公式,那么不同的模型(如 ChatGPT、DeepSeek)就对应着不同的架构和公式。而模型训练的过程,就是通过分析海量文本来为公式寻找最合适的参数值。
大模型的特点
接下来,我们重点关注在工程应用场景下,开发者需要了解的大模型核心特点。这就像我们选用 MySQL 时,需要关注不同存储引擎(如 InnoDB 与 MyISAM)的特性一样。
无状态
大模型本身是没有记忆、没有状态的,它本质上是一个“纯函数”。
它并不知道之前与你进行过什么对话。因此,每次向大模型提交输入时,我们需要根据业务场景,将之前的【对话历史】(包括用户的输入和模型的反馈)一并提供给它们,以避免因“模型失忆”导致的对话不连贯。
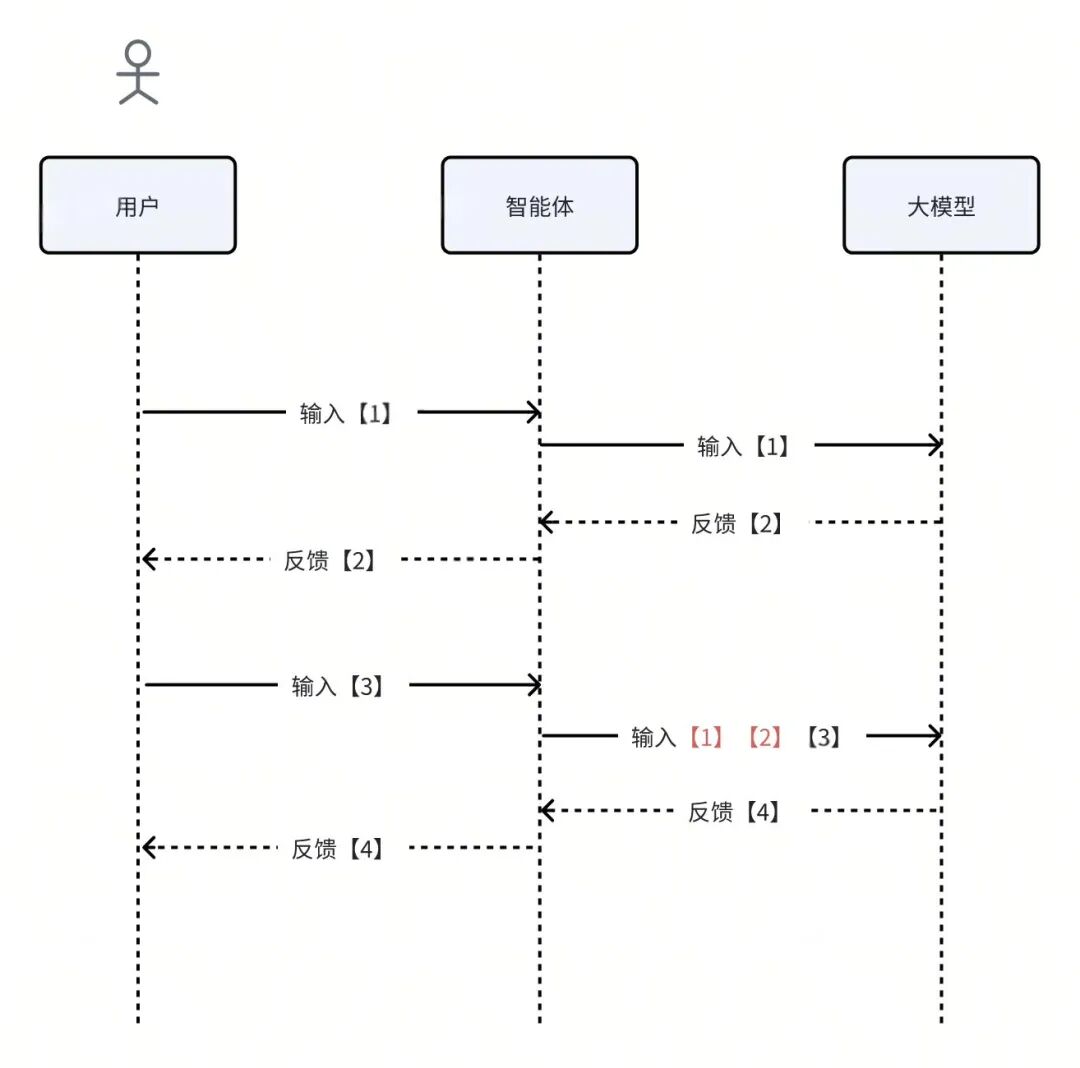
// 纯函数,无状态,无副作用,每次调用不会在系统里留下痕迹
// 某种意义上来说大模型就是一个类似输入/输出的函数
// 只不过这个函数非常复杂,由亿级的参数构成
public String statelessGenerate(String input) {
byte[] result = new byte[512];
ThreadLocalRandom.current().nextBytes(result);
return new String(result);
}
StringBuilder builder = new StringBuilder();
// 有状态,前一次调用会对下一次调用产生影响
public synchronized String statefulGenerate(String input) {
byte[] result = new byte[512];
ThreadLocalRandom.current().nextBytes(result);
return builder.append(new String(result)).toString();
}
结构化输出
大模型具备结构化输出的能力。虽然不同模型对此的支持程度可能有所差异,但重要的是,它们基本都支持!
所谓的结构化输出,是指大模型除了能返回自由格式的自然语言文本外,还可以按照开发者的要求,返回特定结构的数据格式,例如:JSON。

看,这是不是有点像在调用一个 RESTful 接口?甚至可以说是一个“万能”接口,毕竟大模型“声称”自己什么都会。

函数调用
实际上,理解到这一步,我们已经可以构想一个大模型驱动的 RPC 调用引擎了!

大模型会帮你进行推理和规划,得出需要执行的函数名以及对应的参数。至于这个【函数名】背后对应的是一个进程内的方法、一个 HTTP 接口、一个 Dubbo 服务还是一个 MCP 协议接口,这些都属于智能体实现的技术细节,对大模型而言并不重要。
我们可以用自然语言描述需求,同时告诉大模型有哪些外部的【工具/函数】可供它调用。大模型会自行推理,并编排这些工具来完成既定目标。
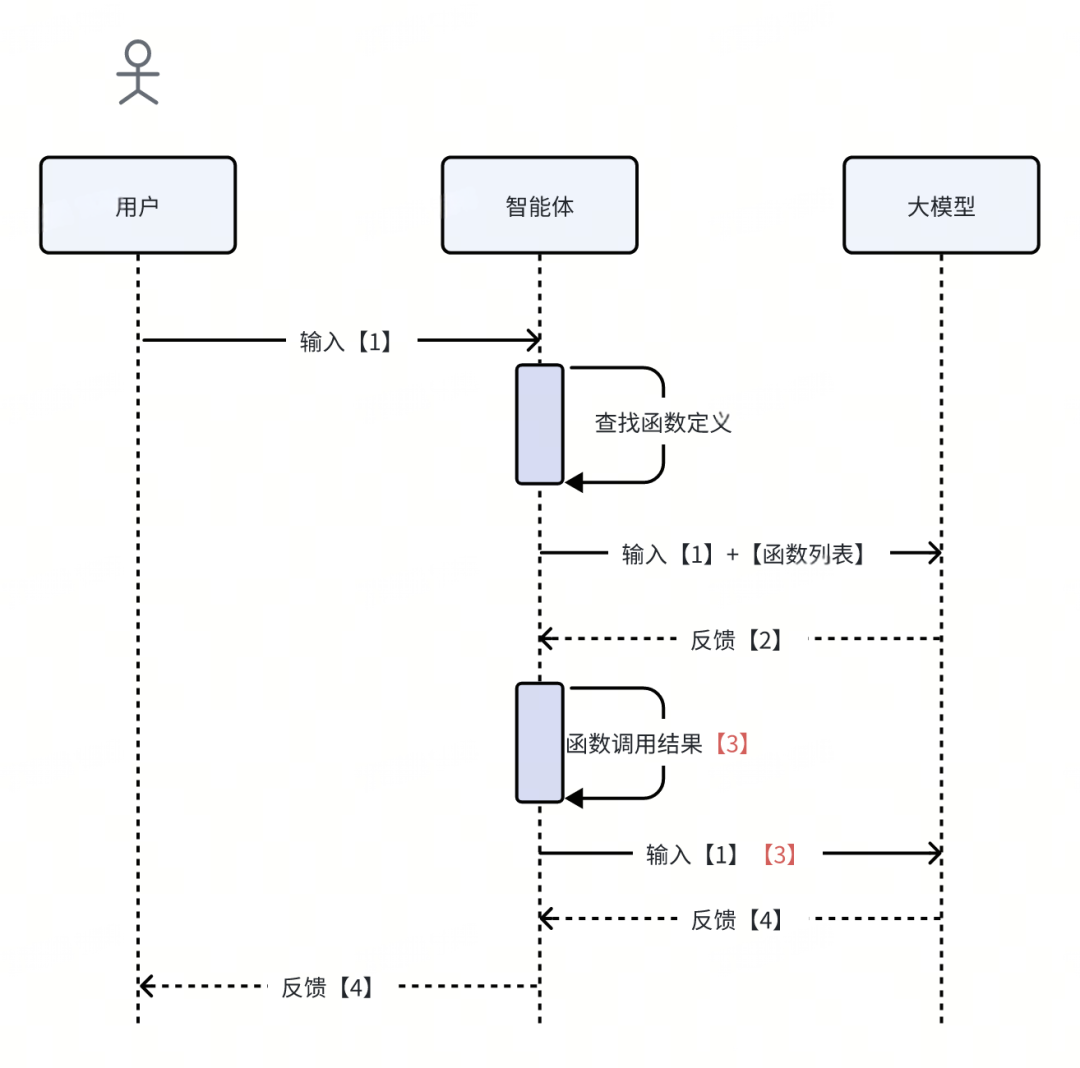
- 将用户的输入和可用函数列表输入给大模型。大模型经过推理,认为需要调用外部函数,于是返回【函数名】和【调用参数】。
- 智能体捕获这个输出,对指定的函数发起实际调用,然后将用户原始的输入和函数的调用结果一起再次输入给大模型。大模型基于这些完整的上下文,推理并输出最终结果。
考虑到函数调用是大模型的普遍需求,主流的大模型供应商通常都在其 API 层面直接提供了【function call】能力,用以在输出中明确区分普通文本回复和函数调用指令。明白了背后的原理,我们就知道这只是 API 抽象层次的不同。
大模型接口
由于大模型对硬件资源(如高端显卡)有特殊需求,它们通常被独立部署,并以 SaaS(软件即服务)的形式对外提供能力。这类似于 MySQL 因对大内存有需求而常被独立部署。
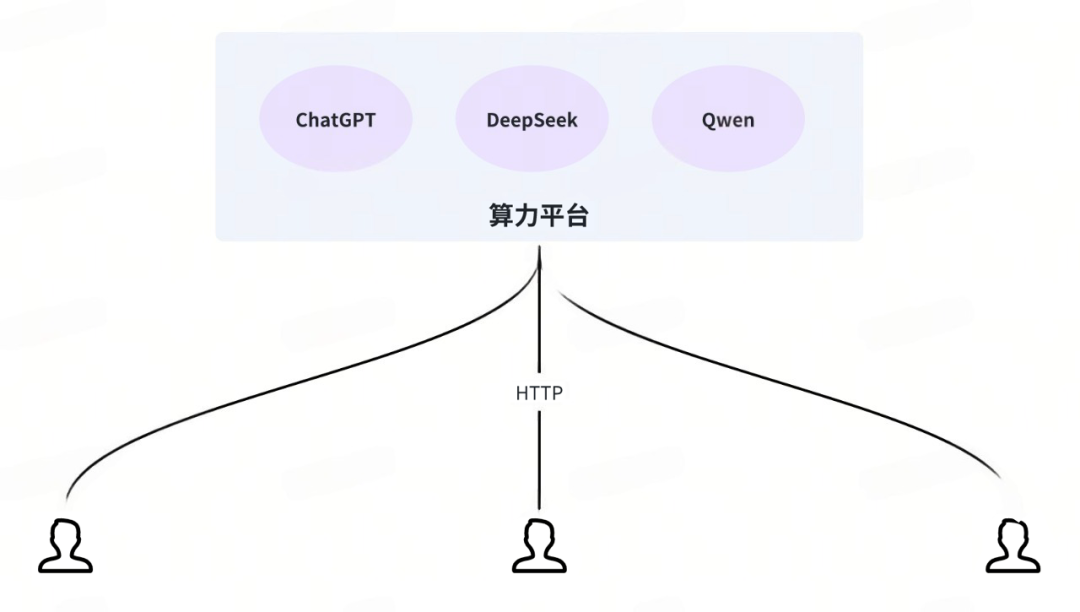
训练好的大模型本质上是一套庞大的二进制参数数据集。要将其服务化、产品化,就需要进行外围的封装。同一套模型可以在不同的算力平台上部署,并提供可能截然不同的服务化 API。
模型封装
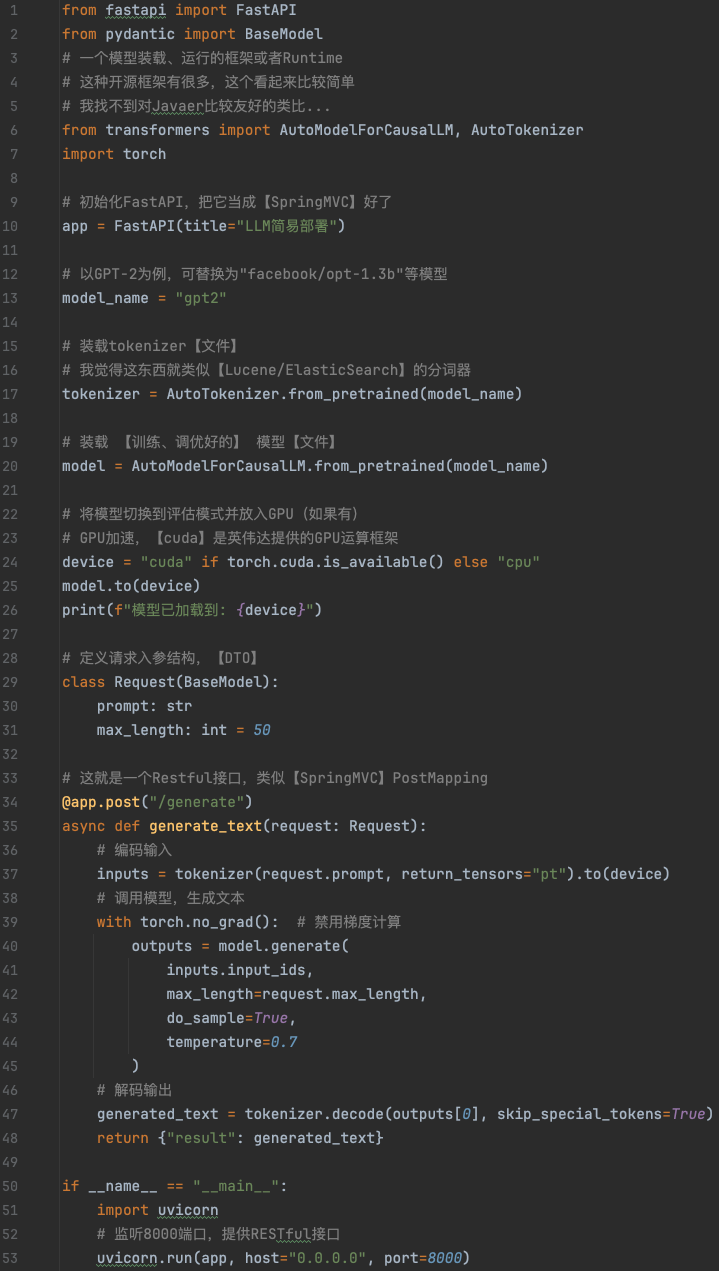
以下是一个简化的伪代码示例,展示了如何加载并封装一个开源模型以提供 API 服务:
我们可以快速浏览一下当前几个热门供应商的核心 API 文档:
- OpenAI - 会话补全: https://platform.openai.com/docs/api-reference/chat
- DeepSeek - 会话补全: https://api-docs.deepseek.com/zh-cn/api/create-chat-completion
- 硅基流动 - 会话补全: https://docs.siliconflow.cn/cn/api-reference/chat-completions/chat-completions
- Ollama - 会话补全: https://github.com/ollama/ollama/blob/main/docs/api.md
其中,硅基流动和 Ollama 属于大模型算力/治理平台。它们自身不研发大模型,而是作为“大模型的搬运工”。你可以将大模型理解为微服务,而将这些平台理解为微服务的构建与发布平台。
稍作浏览便会发现,这些核心 API 的设计大同小异。毕竟 OpenAI 制定了早期的标准,许多系统已经接入了其 API。后来者为了降低开发者的接入成本、实现兼容,其 API 设计也基本与 OpenAI 保持近似。
这就像数据库领域,尽管产品百花齐放,但大家都兼容标准的 SQL 语法。
我们聚焦于【会话补全】这个核心接口,会发现其输入和输出结构大致如下:
接口输入
{
"stream": false, // 是否是流式输出(是否启用SSE)
"model": "deepseek-chat", // 选用哪个具体模型
"messages": [ // 历史对话消息列表。由于大模型无状态,需按场景提供一定轮次的历史消息
{
"content": "You are a helpful assistant", // 系统提示词,设定AI角色
"role": "system"
},
{
"content": "Hi", // 用户消息内容
"role": "user" // 消息发送者角色
}
],
"tools": null, // 外部函数列表,这是【函数调用】能力在API层面的直接支持
"frequency_penalty": 0, // 模型行为控制参数(理解原理后可调整)
"presence_penalty": 0, // 模型行为控制参数
"temperature": 1, // 模型行为控制参数(影响输出的随机性)
"top_p": 1, // 模型行为控制参数
"logprobs": false, // 模型行为控制参数
"top_logprobs": null // 模型行为控制参数
}
我们以达成目标为优先,文中部分暂时不理解的参数可以先忽略。
接口输出
{
"id": "<string>", // 本次调用的唯一ID
"choices": [
{
"message": {
"role": "assistant",
"content": "<string>", // 大模型生成的主要文本内容
"reasoning_content": "<string>", // 部分模型的“思考过程”
"tool_calls": [ // 需要发起的【函数调用】列表
{
"id": "<string>", // 工具调用ID
"type": "function",
"function": {
"name": "<string>", // 函数名
"arguments": "<string>" // 函数参数(JSON字符串格式)
}
}
]
},
"finish_reason": "stop" // 结束原因,如“stop”、“length”、“tool_calls”等
}
],
"usage": { // Token使用量统计,用于计费
"prompt_tokens": 123,
"completion_tokens": 123,
"total_tokens": 123
},
"created": 123, // 时间戳
"model": "<string>", // 使用的模型名称
"object": "chat.completion" // 对象类型
}
看到这里,你是否已经开始跃跃欲试?是否感觉打造一个垂直领域的智能体,并没有想象中那么困难?
RAG 架构
除非是使用特定业务场景的私有数据专门训练的大模型,否则当涉及到企业内部或某个垂直领域的私有信息时,通用大模型往往也只能“不懂装懂”地凭空生成(Hallucination)。
例如,当你询问大模型“DJob 系统如何接入与使用时”,除非它的训练数据中包含了相关文档,否则它很可能给你编造一套看似合理实则错误的步骤。
考虑到专用大模型的训练成本极高,工程上解决这个问题的通用方法是通过外挂知识库来实现,即 RAG(检索增强生成):
- 结合具体业务场景,将相关的文档、手册、FAQ等资料提前处理和录入到【知识库】中。
- 用户提交一个问题(输入)后,先用这个问题作为检索条件,去【知识库】中搜索最相关的【资料片段】。
- 将用户的原始【输入】和检索到的【资料片段】一起组合成新的上下文,提供给大模型进行生成。
这个【知识库】组件的具体选型属于实现细节。简单的方案可以使用传统的 MySQL 或 Elasticsearch 进行全文检索。如果想进一步提升检索结果与问题之间的语义匹配度,也可以使用近来讨论度很高的【向量数据库】。
添加了 RAG 组件后,完整的流程如下:
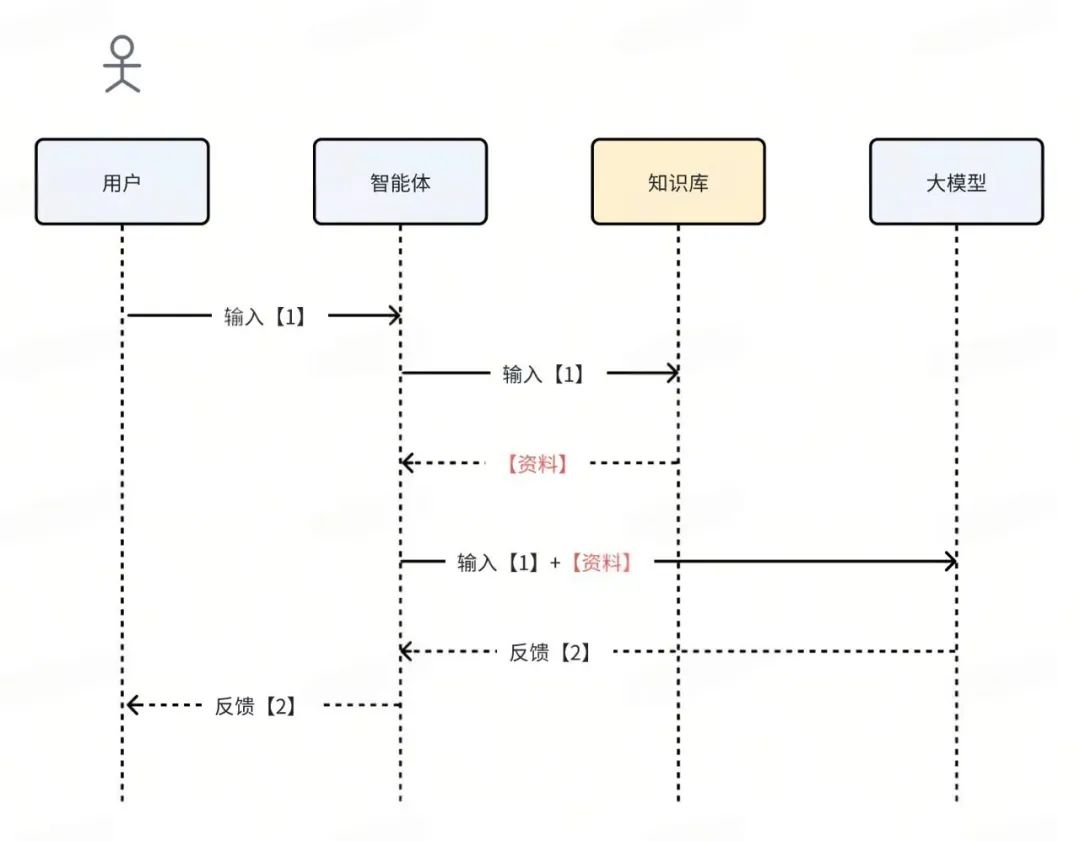
关于 RAG 的更多细节,可参考相关技术文章。
MCP 协议
可以看到,将大模型作为一个【函数调用】的规划与推理引擎,借助其强大的上下文理解和生成能力,我们可以实现非常复杂的业务流程。如果说大模型是智能体的“大脑”,那么提供给大模型调用的那些【函数】就是它的“手”和“脚”。一个有脑、有手、有脚的大模型,能迸发出巨大的业务潜力。
那么,如何高效地打通大模型与传统软件系统(例如存量的微服务集群)呢?
我们所关注的问题,正是开源社区积极推动的方向,这也催生了 MCP(Model Context Protocol)协议的诞生。
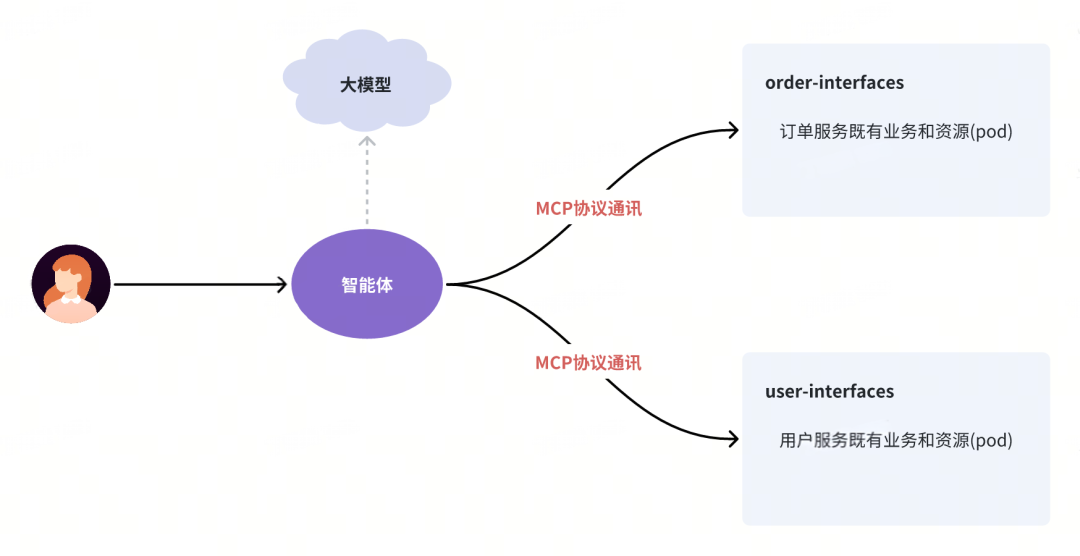
MCP 协议介绍: https://spec.modelcontextprotocol.io/specification/
在此我们不深入 MCP 协议的技术细节,仅分享一些关键思考,旨在打破其神秘感:
- MCP 协议本身并非高深莫测的黑科技。简单来说,它是一套由社区共同约定的、用于系统间(特别是 AI 智能体与工具之间)调用的流程和格式规范。如果不考虑通用性,任何团队都可以设计符合自身需求的、领域特定的交互协议。
- MCP 协议的优势在于,它出现得非常及时,并且基本满足了常见的工具集成需求,因此在开发者社区中快速形成了共识。
- 协议的具体名称是 MAP、MBP 还是 MCP 并不最重要,但“形成共识”这一点至关重要。只有当协议成为标准,开源社区才能围绕它合力构建繁荣的生态系统。
Spring-AI
铺垫了这么多,我们终于要进入 Java 代码的世界了。首先,我们需要熟悉一下 spring-ai 的整体代码架构。我们将按照从整体到细节的节奏进行探讨。
模型抽象
Spring-AI 最核心的 API 抽象是 Model 接口。它是一个泛型化的纯函数接口,提供了对大模型能力最顶层的抽象:
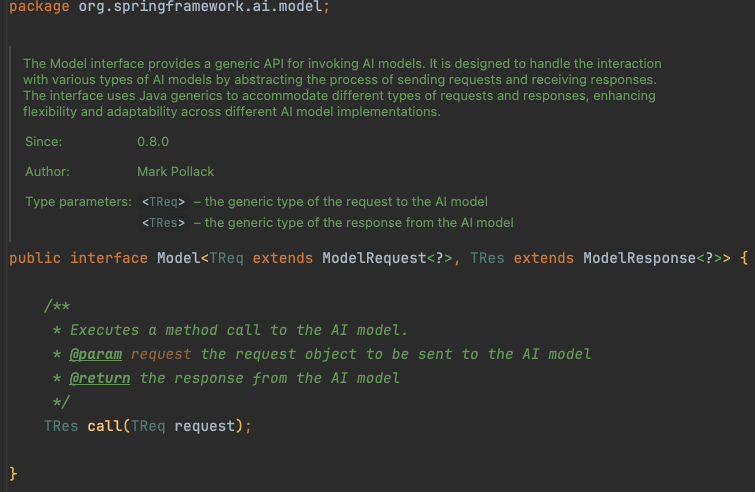
org.springframework.ai.model.Model
大模型能力的本质就是:输入一个请求(request),返回一个响应。至于输入/输出的具体类型,则由其各个子类接口来限定:
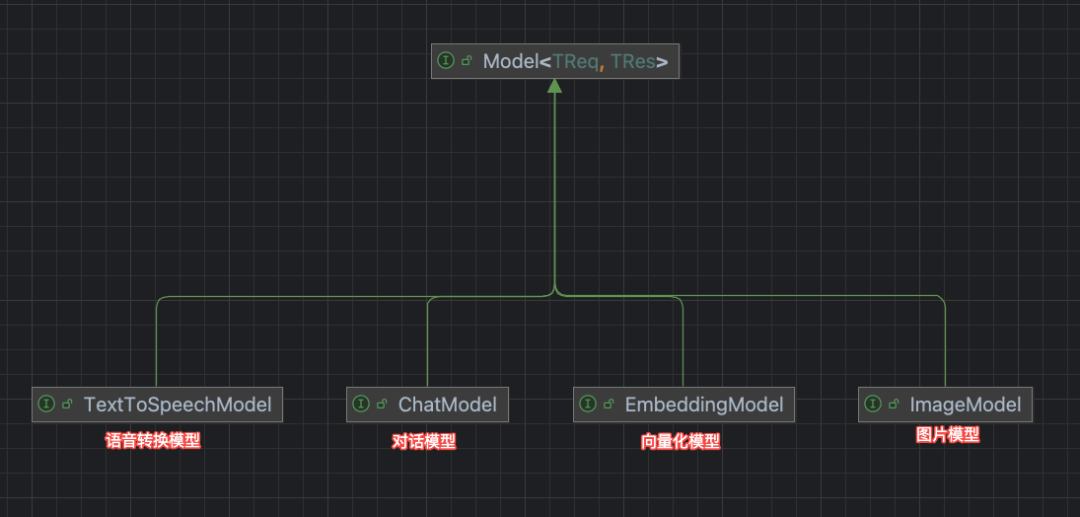
不同模态的大模型支持不同类型的输入/输出。在本文中,我们主要讨论 ChatModel(对话模型)。
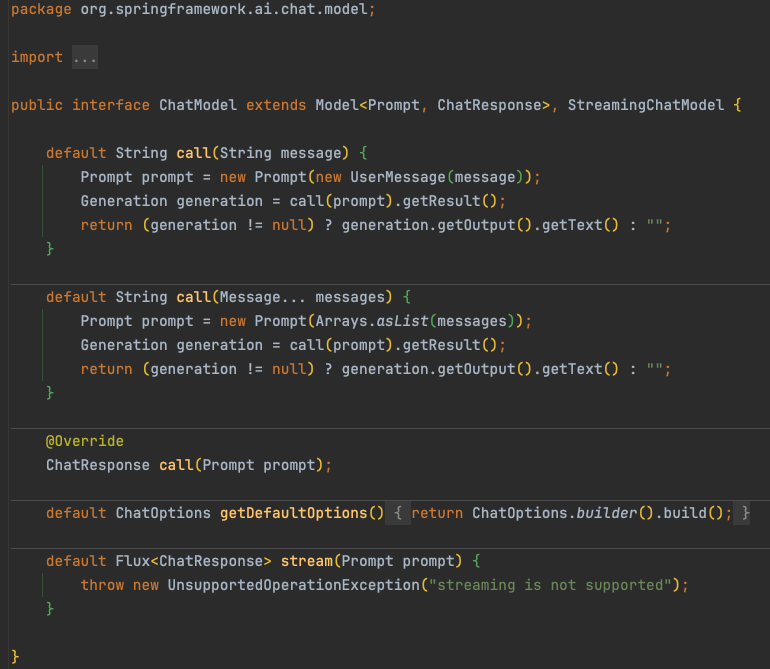
org.springframework.ai.chat.model.ChatModel
spring-ai 已经为我们集成了不同平台、不同模型的 API 客户端。开发者通常只需要在配置中提供 API 的基础地址(Base URL)和调用凭证(API Key),即可开箱使用。
聊天会话
考虑到大模型对话是最高频的应用场景,spring-ai 贴心地提供了更上层的会话客户端抽象 —— ChatClient。
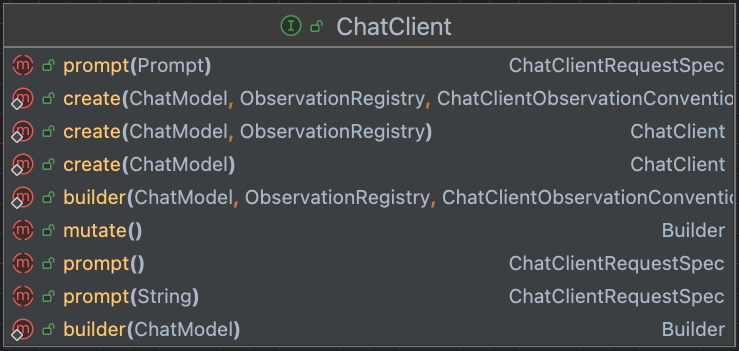
org.springframework.ai.chat.client.ChatClient
RAG 拓展
类似于 Spring AOP 的设计思想,spring-ai 基于“顾问”(Advisor)机制,在请求处理链路上进行横切,提供了开箱即用的 RAG 能力抽象。
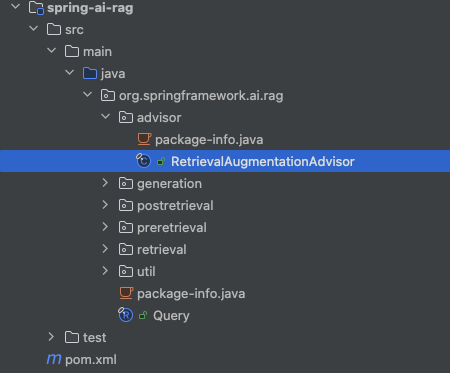
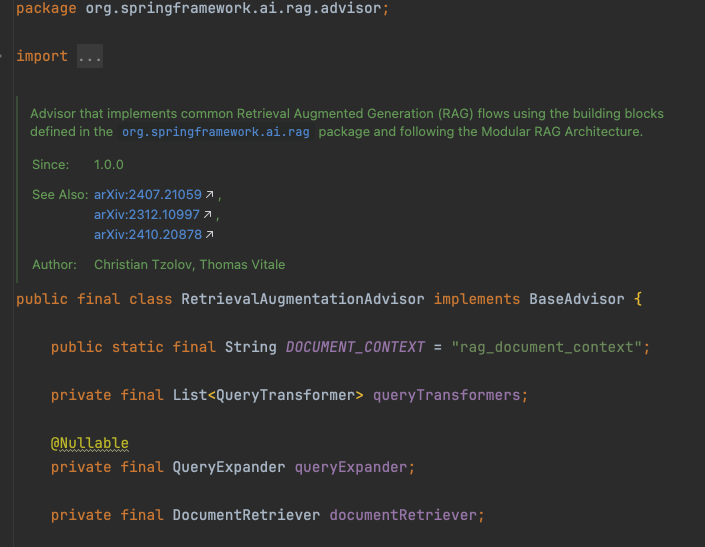
org.springframework.ai.rag.advisor.RetrievalAugmentationAdvisor
代码示例
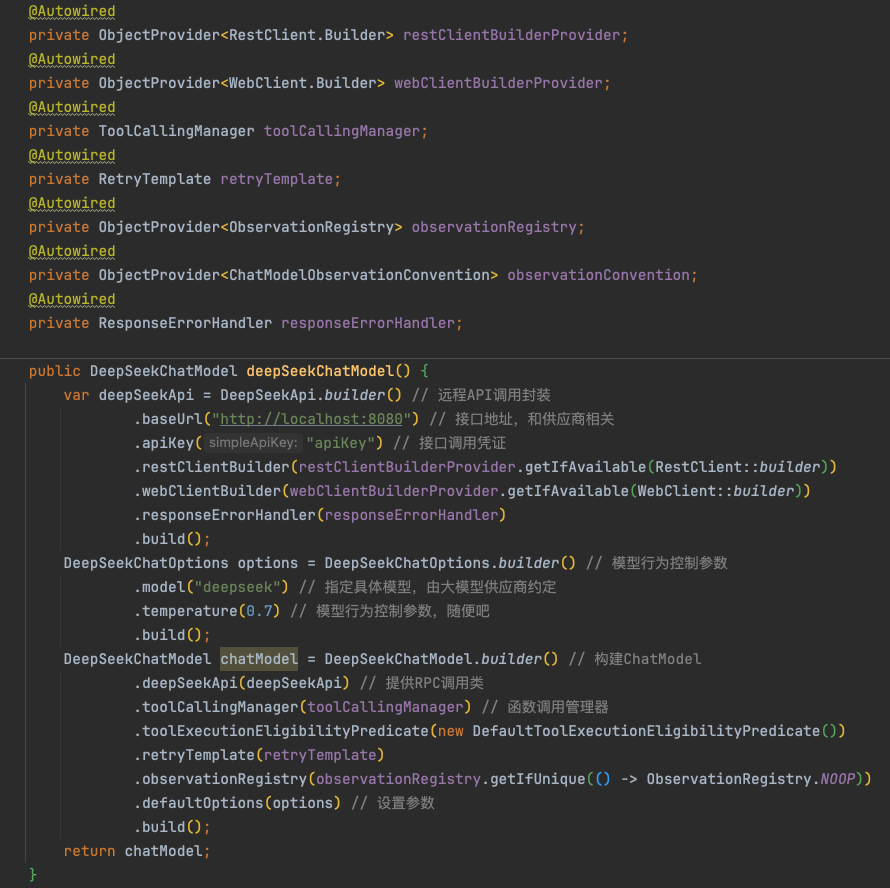
基于供应商构建 ChatModel
以下示例展示了如何配置并构建一个 DeepSeek 的 ChatModel:
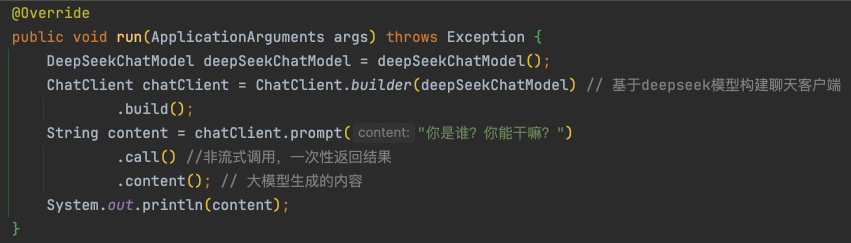
构建 ChatClient 发起会话
构建好 ChatModel 后,即可轻松创建 ChatClient 并发起会话:
智能体示例
至此,我们已经自上而下地理解了大模型工程化的核心概念。现在,让我们动手开发一个简单的【DJob 智能助手】吧!
接口骨架
首先,我们定义一个支持 Server-Sent Events (SSE) 流式输出的 HTTP 接口作为入口:
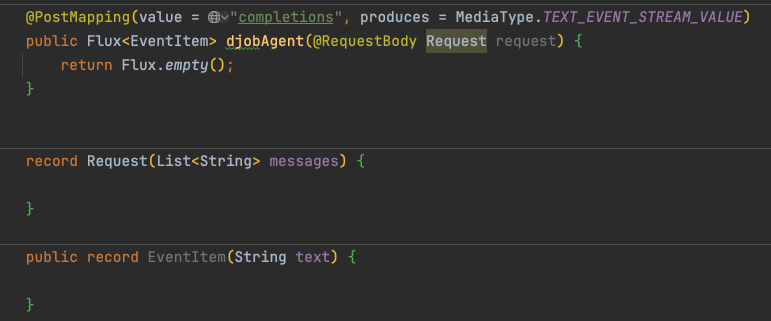
该接口通过 POST 方式接收请求,并设置 Content-Type 为 text/event-stream 以支持流式响应。
构造外部函数定义
假设我们有以下几个与 DJob 系统交互的本地方法,可以提供给大模型调用:
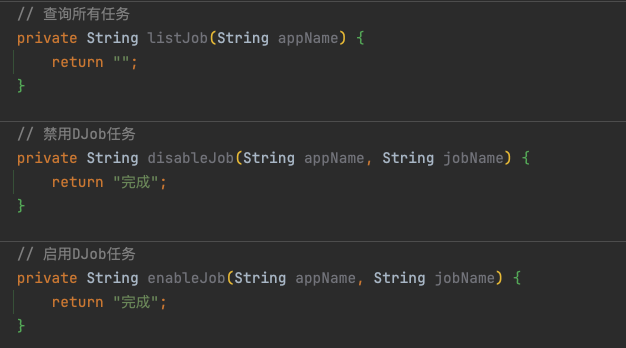
接下来,我们需要将上述三个本地方法封装成 ChatClient API 能够识别的 ToolCallback(工具回调):
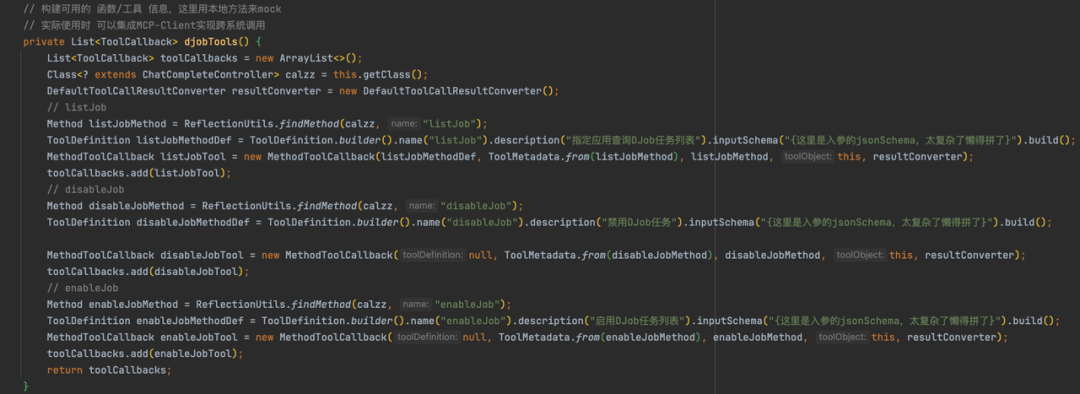
这段代码构建了可供大模型调用的函数/工具信息列表。此处我们用本地方法进行模拟。在实际生产环境中,你可以利用 MCP、HTTP、gRPC 或 Dubbo 等任何跨系统调用方式来实现真正的业务逻辑。
系统提示词
我们不能让大模型完全自由发挥,尤其是处理专业领域任务时。因此,除了用户输入,我们还需要给大模型提供一些定向的上下文信息或场景约束,以帮助它更好地扮演角色、解决问题。

发起调用
最后,在接口实现中,我们将所有部分组合起来:
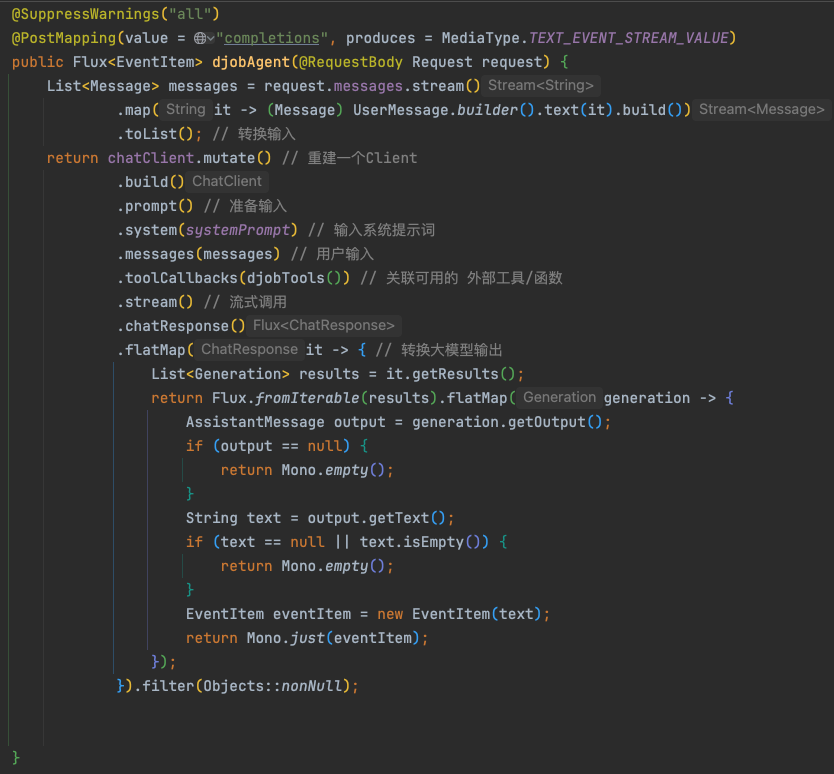
有两点需要注意:
- 由于大模型本身无状态,每次会话时,相关的历史消息也需要一并传入。这些历史消息可以由前端收集后提交,也可以由后端在每次会话时进行存储和管理。
- 代码中使用了
.stream() 方法进行流式调用,并将结果转换为 SSE 事件流返回给客户端。
总结
综上所述,技术领域常常是“太阳底下无新事”。对于工程领域出现的新事物,我们不妨先把它当作一个新型的“数据库”来理解——毕竟,没有谁比 Java 工程师更懂得如何与数据存储层打交道了(开个玩笑)。
以上内容,除了具体的 Java 代码示例,大部分都是通过“盲人摸象”式的实践探索和类比总结得出的。如果文中存在任何理解偏差或错误,欢迎大家在技术社区中进行指正和交流。技术的进步正是在不断的分享、讨论与修正中得以实现。更多关于 Java 和 人工智能 的深度讨论,欢迎访问 云栈社区 与广大开发者一同探索。
 发表于 2026-1-16 17:15:27
|
查看: 169|
回复: 0
发表于 2026-1-16 17:15:27
|
查看: 169|
回复: 0
