在智能体系统的设计中,我们常常默认:只要模型足够强大、提供的上下文足够多,所有的推理和决策都可以在系统内部完成。
但在真实的工程实践中,这个假设并不总是成立。当推理需要依赖尚未被模型明确“知道”的信息、需要更精确的结构化输入,或是必须与实时变化的真实世界状态保持同步时,继续强行进行内部推理,往往会降低系统的整体可靠性与质量。
本文将探讨一种经过实践验证的路径:在智能体的推理流程中,显式地引入一个外部决策步骤(Externalized Cognitive Step)。这个步骤并非交互层的临时补丁,而是执行模型中的一个核心、可设计的一等公民。
以下内容基于一个名为 Wenko 的真实桌面智能体系统。Wenko 基于 LangGraph 构建,其执行图中包含了一个可暂停、可恢复的外部决策节点。我们以该实现为例,说明这一设计理念如何转化为具体的工程实践。
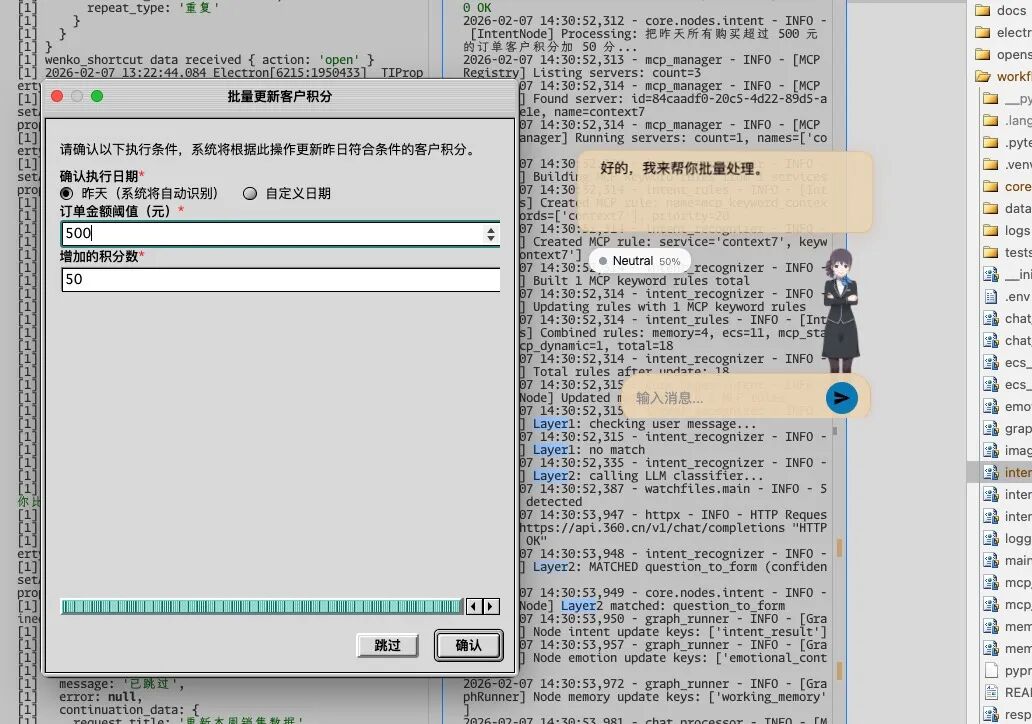
图中展示了 Wenko 智能体在处理用户指令时,识别出需要明确的参数(如订单金额阈值、积分数量),于是触发并展示了一个结构化的表单,请求用户确认。这是一种典型的外部决策介入场景。
一、为什么内部推理并不总是最优选择
智能体推理失败,很多时候并非因为模型本身“不聪明”,而是由于以下几类关键信息的缺失:
- 模糊但至关重要的参数:如具体的时间范围、操作界限、个人偏好等。
- 隐含但未明确表达的约束条件。
- 需要结构化表示而非自然语言描述的内容。
- 系统必须与外部世界实时保持一致的状态。
在这些场景下,如果继续让模型依靠有限的上下文去“猜测”,往往会带来两个核心问题:
- 推理结果高度不稳定:模型的猜测带有随机性,同一问题在不同上下文中可能得出不同答案。
- 错误被层层放大:在前序步骤中产生的微小偏差或错误,可能在后续复杂的处理流程中被指数级放大。
因此,一个更理性、更工程化的做法,不是一味强化模型的猜测能力,而是主动中断当前的内部推理循环,转而向外部(通常是人或更确定的系统)获取更可靠的信息来源。
二、什么是“外部决策步骤”
这里所说的“外部决策步骤”,并非让系统“放弃智能”,而是指:在推理链条中,将一个无法在当前上下文中完成的决策,显式地“外包”为一个独立、可暂停、可恢复的步骤。
它具备几个关键特征:
- 由系统主动触发:基于自身的推理判断,而非用户随意插入的对话。
- 结构化请求:以定义清晰的格式(如表单、选项列表)表达需求,而非模糊的自然语言追问。
- 中断流程:会暂停当前正在进行的推理任务。
- 依赖输入:只有在获得明确的外部输入后,流程才会继续。
从系统的视角看,这是一次受控的、设计好的推理暂停。
在 Wenko 中的对应结构
这个“受控的推理暂停”在 Wenko 中被实现为 GraphState 上的一次状态转移。GraphState 是整个执行图的单一状态源(Single Source of Truth),其中与外部决策相关的核心字段如下:
# workflow/core/state.py
class GraphState(BaseModel):
status: Literal["idle", "processing", "suspended", "error"] = "idle"
ecs_request: Optional[ECSRequest] = None
ecs_full_request: Optional[Dict[str, Any]] = None
last_human_input: Optional[Dict[str, Any]] = None
其中 ECSRequest 定义了一个决策请求的最小数据契约:
class ECSRequest(BaseModel):
type: str # 'form', 'confirmation', 'visual_display'
message: str
options: List[Dict[str, Any]]
context_data: Dict[str, Any]
几个设计要点:
status 的四种状态(idle → processing → suspended → idle)构成了一个显式的生命周期。suspended 不是错误,也不是被动的等待——它是一种被设计出来的正常执行状态。ecs_request 是由推理节点主动写入的,而不是由某个外部控制器强制注入的。这意味着,是推理过程自身判定“我需要外部信息来继续”。last_human_input 字段只在恢复阶段被填充,其内容将作为高置信度的上下文注入到下一轮推理中。
三、为何要将它设计为“步骤”,而不是“对话”
一个常见的替代方案是:让智能体通过多轮对话来逐步澄清信息。这种方式在简单场景下有效,但在追求确定性的工程系统中存在明显短板:
- 信息分散:关键信息分散在多轮对话的上下文中,难以被后续流程结构化地提取和处理。
- 版本模糊:模型需要自行判断用户的哪一句回复是“最终确认”,增加了逻辑复杂度。
- 阶段混淆:无法在系统中明确区分“信息收集阶段”和“基于完整信息的推理阶段”。
将外部决策设计为一个独立步骤,可以带来清晰的边界:
- 在进入该步骤前,系统停止推进任何内部推理。
- 在该步骤完成前,不会发生任何基于猜测的后续决策。
- 外部输入以完整、一次性、结构化的形式返回给系统。
这使得整个推理流程在时间(何时暂停)和语义(暂停以获取什么)上都变得高度可控。
对话澄清 vs. 结构化决策步骤
为什么不用自然语言对话?根本原因在于信息的结构保真度。
在 Wenko 的实现中,外部决策请求携带的不是一个开放的自然语言问题,而是一个完整的结构化 Schema。后端的 ECSField 定义了每个待采集字段的精确约束:
# workflow/ecs_schema.py
class ECSField(BaseModel):
name: str
type: ECSFieldType # TEXT, SELECT, NUMBER, SLIDER, DATE, BOOLEAN...
label: str
required: bool = False
placeholder: Optional[str] = None
default: Optional[Any] = None
options: Optional[List[ECSOption]] = None
min: Optional[float] = None
max: Optional[float] = None
当系统需要了解用户的“音乐偏好”时,它不会模糊地问“你喜欢什么音乐?”。相反,它会生成一个包含 SELECT(音乐类型选择)、SLIDER(收听频率)、TEXT(补充说明)等字段的集合。用户返回的数据是标准的 Dict[str, Any],而不是一句需要模型再次解析和猜测的自然语言。
这是一个关键的设计判断:在关键的决策边界上,用结构化的契约替代开放的语言。
四、工程实现:一个可暂停的推理模型
在实现层面,引入外部决策步骤意味着需要对执行模型做出明确的约束。
1. 推理结果不直接驱动执行
当智能体经过推理判断需要外部决策时,它不会继续生成一个可能不准确的“最终答案”,而是生成一个决策请求对象。这个对象通常包含:
- 当前的推理意图摘要。
- 所需信息的结构化定义(字段列表、类型、约束)。
- 可提供的选项或合理的默认值。
- 对这些输入结果的预期用途说明。
这个请求对象本身是推理流程的输出产物,而不是事后由 UI 层生成的补丁。
触发机制
在 Wenko 中,ReasoningNode 是执行图中唯一的 LLM 调用节点。它在完成 LLM 调用并解析响应后,会主动检查输出中是否包含了外部决策请求:
# workflow/core/nodes/reasoning.py — ReasoningNode.compute()
if is_ecs_enabled():
ecs_request = extract_ecs_from_llm_response(full_response)
if ecs_request:
updates["ecs_request"] = ECSRequest(
type=ecs_request.type,
message=ecs_request.title,
options=[],
context_data={"ecs_id": ecs_request.id},
)
updates["status"] = "suspended"
updates["ecs_full_request"] = ecs_request.model_dump(mode='json')
return updates
注意这里的控制流:return updates 意味着 ReasoningNode 不再产生常规的 response 文本,不再更新对话历史,也不会执行任何后续工具调用。它的唯一输出变成了一个决策请求 (ecs_request) 和一个状态标记 (status: "suspended")。
为什么不让模型同时输出回复和决策请求?因为这会模糊决策的边界——如果模型已经给出了一个看似完整的回复,那随后获得的外部决策结果还能改变什么?外部决策步骤存在的前提是:当前推理必须等待外部信息才能产出有效、准确的结果。
2. 推理流程进入显式暂停状态
一旦外部决策步骤被触发,系统会立即:
- 终止当前执行图的遍历。
- 将系统状态标记为
"suspended"(等待外部输入)。
- 不再发生任何隐式的后台推理或自动流程推进。
这种暂停是结构性的,不是通过 sleep、await 或轮询等临时机制实现的。
执行图中的路由与终止
暂停的实现依赖于 LangGraph 的条件边(conditional edge) 机制。ReasoningNode 的输出会经过一个路由函数来决定下一步走向:
# workflow/core/graph.py — GraphOrchestrator._build_text_graph()
def route_reasoning(state: GraphState):
if state.pending_tool_calls:
return "tools"
if state.ecs_request:
return "ecs"
return END
当 ecs_request 不为空时,执行流会进入一个名为 ECSNode 的节点。而 ECSNode 本身几乎不做任何计算——它只是确认并维持这个暂停状态:
# workflow/core/nodes/ecs.py
class ECSNode:
async def execute(self, state: GraphState) -> Dict[str, Any]:
if not state.ecs_request:
return {"status": "processing"}
return {"status": "suspended"}
紧接着,一条无条件边将 ECSNode 连接到 END(图终止点):
workflow.add_edge("ecs", END) # 挂起,等待恢复
至此,整个执行图的单次遍历彻底结束。这不是“暂停在某个节点等待回调”,而是图的执行已经完成。系统状态被持久化,外部决策请求通过事件流(如 SSE)被推送到前端界面。
完整的执行图拓扑可以简化为:
IntentNode → EmotionNode → MemoryNode → ReasoningNode → ?
│
┌───────────────┼───────────────┐
▼ ▼ ▼
ToolNode ECSNode END
│ │ (正常完成)
│ ▼
│ END
│ (挂起等待)
▼
ReasoningNode
(循环)
为什么 ECSNode 要直接连接到 END,而不是某个“挂起等待”的虚拟节点?因为 LangGraph 的执行模型本质上是流式、一次性的——每次 astream() 调用对应一次从起点到终点的完整图遍历。图中没有“在中间暂停”的原生语义。
因此,暂停必须被建模为当前推理链的结束,而恢复则对应着一次全新推理链的开始。这不是实现上的妥协,反而是一种更干净、更符合状态机理念的设计。
3. 外部输入作为新上下文重新注入
当用户完成表单填写并提交后,系统并不是简单地“接着刚才的地方往下跑”。相反,它会:
- 构建一个全新的推理起点。
- 将外部决策的结果作为高置信度、结构化的初始上下文注入。
- 重新执行一次完整的推理流程(包括意图识别、情绪分析、记忆检索等)。
恢复路径
GraphRunner.resume() 方法负责处理恢复逻辑。它不会去加载之前的执行中间状态,而是构建一个全新的 GraphState 实例:
# workflow/graph_runner.py — GraphRunner.resume()
ecs_context = build_continuation_context(continuation_data)
initial_state = GraphState(
conversation_id=session_id,
semantic_input=SemanticInput(
text=f"请根据我刚才提交的表单信息给出回复。\n\n{ecs_context}",
),
last_human_input={
"action": continuation_data.action,
"form_data": continuation_data.form_data,
"field_labels": continuation_data.field_labels,
},
)
orchestrator = GraphOrchestrator(...)
workflow = orchestrator.build()
app = workflow.compile()
async for output in app.astream(initial_state, config={"recursion_limit": 50}):
...
这里有几个关键的设计选择:
为什么不断点续跑?
系统其实具备检查点(checkpoint)机制,但恢复流程故意没有使用它。原因是:外部决策返回的结果可能彻底改变推理的所有前提——意图判断、情绪推断、记忆检索都可能因为这条新信息而得出完全不同的结论。如果从旧断点继续,这些前置节点的输出是基于旧信息的,系统就会在新信息和旧推理之间产生不一致。从头开始确保了状态的一致性。
上下文注入如何工作?
build_continuation_context() 函数会将结构化的表单数据,转换、格式化为一段 LLM 易于理解的上下文字符串。外部输入不是被当作原始数据直接丢给模型,而是经过精心格式化、带有明确元信息(如“这是您刚才确认的信息”)的上下文块。
last_human_input 的作用是什么?
它以原始的结构化格式保留外部输入,与 semantic_input.text 中的自然语言表述形成互补。下游的节点(或未来的工具调用)可以根据需要,直接读取这些结构化数据,而不必再从模型的自然语言回复中费力地重新提取信息。
这种设计的好处显而易见:
- 推理路径始终完整:每次推理都基于完整的上下文重新评估,逻辑链条清晰。
- 系统状态一致:新信息能够自然地影响到意图、情绪等所有环节的重新计算。
- 输入融入度高:外部输入不是临时补丁,而是被正式地、结构化地整合进推理的上下文环境。
链式外部决策
恢复后的全新推理流程,完全有可能再次触发外部决策。GraphRunner.resume() 在流式输出中会持续检测 ecs_request:
# 恢复执行中检测链式 ECS
if "ecs_request" in update and update["ecs_request"]:
ecs_req = update.get("ecs_full_request")
if ecs_req:
store_ecs_request(ecs_req, session_id)
ecs_payload = self._format_ecs_payload(ecs_req, session_id)
yield self._format_sse("ecs", {"type": "ecs", "payload": ecs_payload})
这意味着外部决策不是一次性机制,而是可递归、可组合的。一次恢复后的推理,如果基于新信息又引发了新的不确定性,系统会再次优雅地挂起。这种能力,正是将外部决策建模为执行图中“一等节点”所带来的自然结果。
五、为什么这种设计更可靠
1. 不确定性被显式建模
系统不再假装“我已经知道所有答案”,而是坦率地承认:“在当前状态下,我掌握的内部信息不足以做出可靠决策,需要您的帮助。”
这种“承认”本身,就是一种工程上的成熟。在 Wenko 中,这表现为 status: “suspended” 是一个与 “processing” 和 “error” 平级的、正常的状态分支——不是异常,不是降级,而是执行模型设计的一部分。
2. 外部输入的价值被最大化
结构化的外部决策输入,直接带来了三大优势:
- 减少歧义:明确的选项和约束避免了模棱两可。
- 降低解释成本:模型无需费力解析自由文本。
- 提高稳定性:后续推理建立在确定的数据基础上。
在实现上,这依赖于两个配套机制:
结构化采集:ECSField 的类型系统确保了返回数据的类型安全和意义明确。模型不会收到“我大概每周听三次”这样的描述,而是直接得到 {“frequency”: 3, “unit”: “per_week”} 这样的键值对。
持久化与复用:决策结果会被写入工作记忆,并附上如 ecs_{request_title} 这样的标识键。这意味着同一决策的结果可以在后续的多次推理中被直接复用,无需反复向用户询问,提升了交互效率。
3. 推理与交互职责清晰分离
整个流程被清晰地划分为三个阶段,每个阶段职责单一:
- 推理阶段:系统负责判断“我缺什么信息”。
- 外部决策阶段:用户(或外部系统)负责“我给你什么信息”。
- 恢复阶段:系统负责“我如何使用这些信息”来完成任务。
在执行图中,这三个阶段对应三段独立的代码路径,它们之间通过定义良好的 GraphState 数据契约进行通信,没有共享的、隐晦的中间状态。
六、适合这种设计的典型场景
这种外部决策步骤的设计模式,尤其适用于以下对准确性要求较高的场景:
- 需要结构化参数的任务:如制定计划、配置系统、筛选数据等,其中的数值、日期、枚举项必须明确。
- 与真实世界状态强相关的操作:例如,“请关闭我现在正在看的浏览器标签页”,系统需要知道“现在正在看”的具体是哪一个。
- 用户偏好尚未明确、但对结果影响显著的决策:比如推荐系统中的冷启动问题,直接询问偏好比盲目猜测更好。
- 任何“继续猜测会显著降低输出质量”的情况。
它并不旨在取代所有对话,而是作为一种精准的工具,被用于那些高价值、低容错的关键推理节点上。
结语
为智能体推理引入外部决策步骤,并不是在削弱智能体的能力,而是清醒地承认一个事实:并非所有的认知和决策,都适合被压缩进一次封闭的语言生成过程中。
通过将关键的不确定性显式外包、通过设计良好的暂停与恢复机制、通过将外部输入结构化地重新注入上下文,系统获得了一个更加稳定、可靠的推理基础,也获得了与真实世界进行有效、可控协作的能力。
在 Wenko 的实现中,这套机制最终被凝练为几个简洁而有力的工程约束:一个四状态的生命周期、一条指向终止的图边、一个基于全新上下文的恢复方法,以及一份贯穿始终的结构化数据契约。这些实践为构建更可靠、更实用的AI系统提供了可借鉴的思路。
 发表于 2026-3-11 01:28:23
|
查看: 163|
回复: 0
发表于 2026-3-11 01:28:23
|
查看: 163|
回复: 0
