在最近的一次 Amlogic S905x5 平台适配高通 Wi-Fi 6/7(PCIe 接口)芯片时,遇到了一个强有力的挑战:
S905x5 的 MSI_ADDR 被固化为 0x190(平台原因),同时高通的 Wi-Fi 6/7 芯片也无法使用 0 ~ 0x2000(平台原因),导致在加载 Wi-Fi 驱动时,莫名其妙的失败,适配工作直接“Block”了。我们先来看看平台 PCIe 的日志:
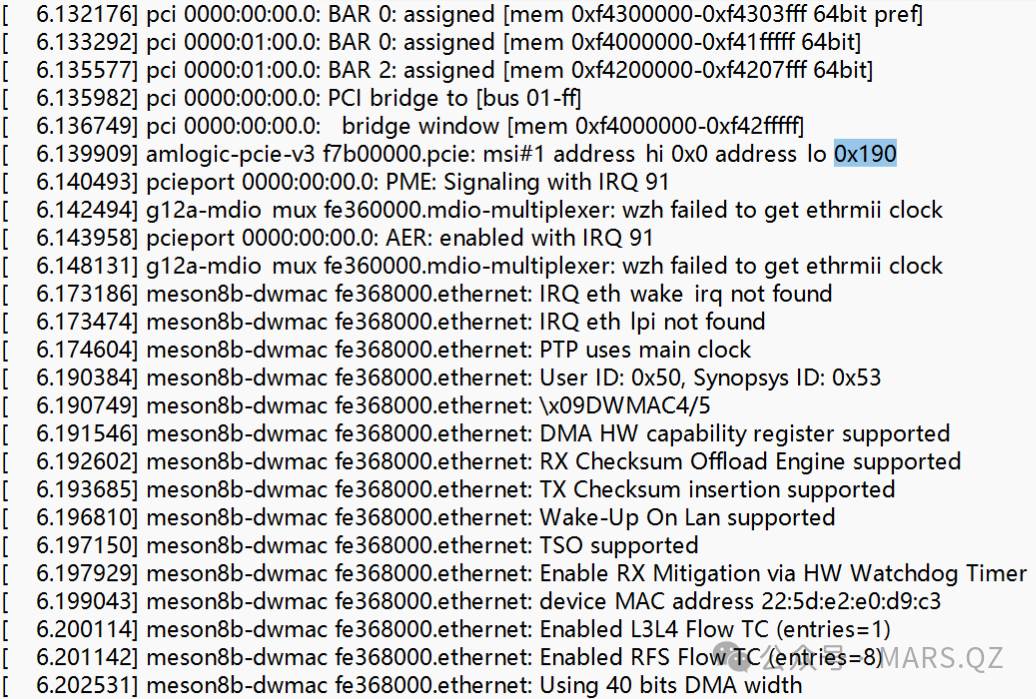
此问题,乍看无解,那最后是如何解决的呢?我们来具体讲讲。
方案一:利用 PCIe RC iATU 的地址转换能力。
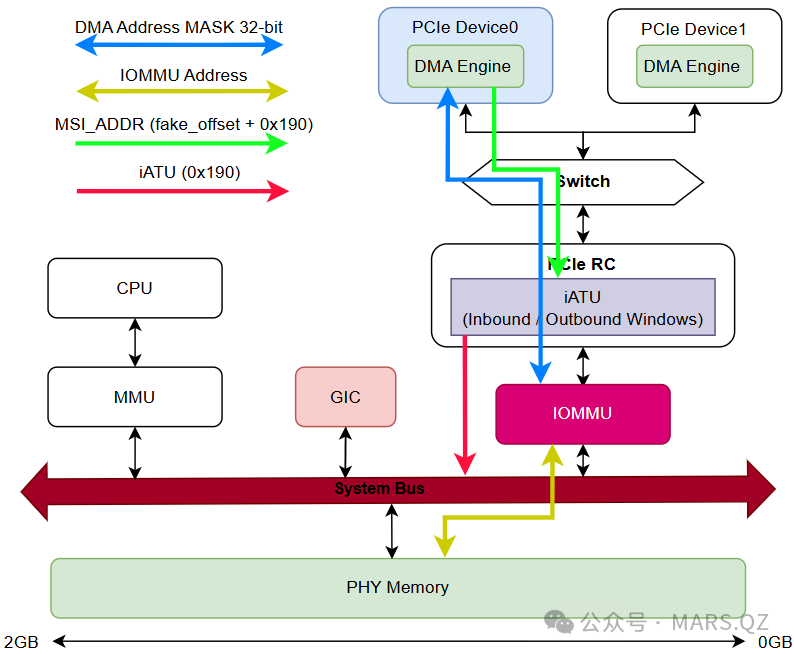
第一步:在枚举过程中,将 Wi-Fi PCIe MSI_ADDR 配置为 fake_offset + 0x190,同时确保 fake_offset + 0x190 不位于当前任何物理内存区域。我们选择了 fake_offset 地址为 BAR 空间的基地址(0xF4000000)。
第二步:修改平台 PCIe RC 的 iATU 设置,添加一个地址转换条目(tgt_addr = src_addr - fake_offset),例如:src_addr = 0xF4000000(Wi-Fi 发起的地址),tgt_addr = 0x00000000(iATU 转化后,SoC 实际看到的地址)。
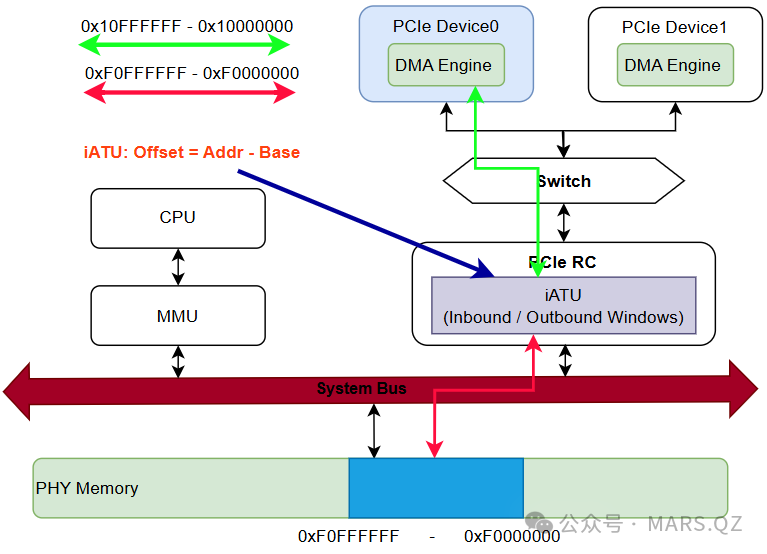
完成上述 iATU 设置后,Wi-Fi 发起的 MSI_Adress(0xF4000190),离开 RC 后,都会被转换成 0x190(SoC 实际看到的地址),具体如下图。
方案二:Qualcomm Wi-Fi FW 针对 MSI_ADDR 直接做重映射。
上述方案一,不知道大家有没有注意到,特意提了一句:确保 fake_offset + 0x190 不位于当前任何物理内存区域。
那么,为何 fake_offset 必须避开真实的物理内存?在讲解 iATU 之前,我们先来讲讲两个常见的误区概念:
- PCIe BAR 的基地址是否对应具体物理内存吗?
- 为什么 fake_offset 不能指向真实的物理内存?
重新理解 PCIe BAR:是“窗口”而非“仓库”
常见误区:认为 BAR 必须对应一段真实的物理内存,像硬盘一样用来存东西。其实:
BAR 不应该对应真实的物理内存,更准确的说法是:BAR 描述的是“PCIe 地址空间中的一个可响应窗口”,它只是一个门牌号,进去之后是也是一片虚空。它只负责向 RC 声明:我在 PCIe 总线地址空间里占了这么大的坑,如果有 TLP 命中这个地址范围,请转发给我。
至于这个地址最终是否落到物理内存,完全取决于 RC(iATU / Interconnect)的映射配置。BAR 不承诺:
- 这段地址背后有真实的 DRAM 内存。
- 这段地址一定能被 CPU 直接 load/store。
- 这段地址在系统物理内存映射图中有“实体”。
为什么 fake_offset 不能(也不该)是物理内存?
MSI 中断的本质不是“写内存”,而是“用一次 PCIe Memory Write TLP(写操作),编码一个中断事件”。
目标地址的意义:由于是中断信号,它必须被中断控制器(GIC/APIC)捕获,而不是被当作普通内存存储。
如果 fake_offset 指向真实的物理内存,RC 可能会将其当作普通的 DMA 写操作处理,直接写入物理内存。这将导致灾难性的后果:
- 中断丢失:中断控制器收不到信号,CPU 无法响应中断。
- 数据踩踏:MSI 的 Payload(数据)会被写入内存,覆盖该地址原有的数据。
- 系统崩溃:导致不可预期的内存破坏。
在 MSI 场景下,上述方案一利用 BAR 地址作为一个“安全的虚拟目标地址”,再通过 Root Complex 的 iATU 将该地址重定向到实际的中断控制寄存器,避免了 MSI 写操作落入真实内存。这也充分体现了 iATU 在 PCIe 协议域与 SoC 地址域之间的桥梁作用,是理解计算机基础中地址映射的关键。
什么是 iATU?(Internal Address Translation Unit)
首先纠正一个概念:iATU 不是通用的系统组件,它是 Synopsys DesignWare PCIe IP 核内部的一个模块。 因为这个 IP 核被海量 SoC 厂商(瑞芯微、高通、三星、NXP)采用,所以 iATU 成了嵌入式 PCIe 驱动开发绕不开的坎。
它的本质是:PCIe 协议域(PCIe Domain)与 SoC 系统总线域(AXI Domain)之间的 “地址转换器” 。
为什么必须要有 iATU?
大家是否思考过一个问题:在关闭 IOMMU 的 SoC 平台上,PCIe 设备为啥依然能够正常 DMA?
这件事初看之下是反直觉的:既然没有 IOMMU,PCIe 设备究竟是如何“知道”系统物理内存在哪里的?
其实,答案并不在 DMA Engine 本身,而是在 PCIe Root Complex 内部的 iATU(internal Address Translation Unit)。
在讨论 iATU 之前,我们需要先明确一件事:PCIe 的地址空间和 SoC 的物理地址空间是两个平行的宇宙,并不共享同一套地址语义。
1. PCIe 世界看到的是什么?
对 PCIe Endpoint 而言,它能理解的地址包括:
- BAR(Base Address Register)对应的 PCIe 地址
- DMA 时使用的 Bus Address
这些地址最终都体现在 PCIe TLP(Memory Read / Write)的 Address 字段中。这些地址只在 PCIe 协议域内有意义,并不等价于 SoC 的物理地址。
2. SoC 世界看到的是什么?
SoC 内部的系统互连(System bus)只理解:
- Physical Address(PA)
- 系统寄存器
对 SoC 而言:不存在“PCIe 地址”这个概念。
3. 关键问题出现了
如果没有额外机制:SoC 为 PCIe DMA 分配的内存地址,PCIe 设备根本不认识;PCIe 发出的地址,SoC 根本不知道该往哪里送。
iATU 正是为了解决这个最原始、也最基础的问题而存在:负责在进出 PCIe 控制器大门的那一瞬间,把地址换掉,如果没有它,地址无法匹配,总线将直接死锁。
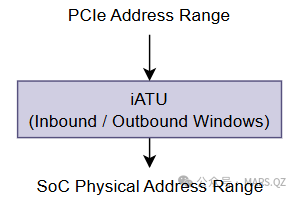
iATU 的工作机制:窗口,而不是页表
1. iATU 的核心模型
在 DesignWare 的 IP 中,iATU 由一组 Viewports(视窗)组成。每一个 Viewport 就是一个独立的硬件翻译单元。
一个标准的 iATU 窗口,由三个核心坐标定义:
- Base Address(基地址):入口。捕获什么样的地址?(即:CPU 发过来的地址落在哪才归我管?)
- Limit Address / Size(边界):范围。这个窗口管多宽?
- Target Address(目标地址):出口。翻译后的新地址起点是哪里?
iATU 的映射模型非常简单,它不做逐页翻译和查找,而是“匹配 + 偏移计算”。如下图所示:
假设 CPU 发出了一个地址 Incoming_Addr。iATU 硬件会并行扫描所有启用的 Viewport,逻辑如下:
匹配阶段(Hit Test)
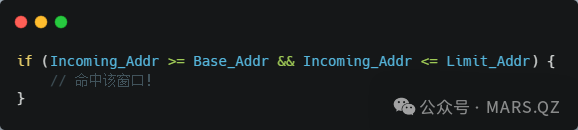
翻译阶段(Translation):一旦命中,硬件立即执行简单的加减法:
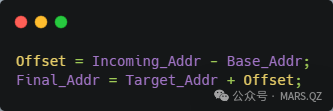
2. 一个典型的 iATU 映射示例
Inbound 与 Outbound iATU
在一个系统中,对 PCIe 设备而言有两个传输事务(Transaction):一个是 Inbound 传输事务,另外一个是 Outbound 传输事务。
Inbound 传输指的是从设备的 DMA 引擎发起读写内存的访问。这些访问通常涉及数据传输、命令或请求,目的是访问系统内存和资源。IOMMU 会对这些事务进行地址转换和保护,以确保只有授权的设备可以访问特定的物理地址。
Outbound 传输事务是指 CPU 发起访问设备的传输事务,例如系统软件想访问设备的 MMIO 寄存器,对设备进行配置。这些事务通常涉及数据传输、命令或请求,用于将数据或指令发送到外部设备,比如对设备进行初始化和配置。
IOMMU 不会干预这些 Outbound 传输事务的地址转换,因为它主要负责处理 Inbound 传输的安全性和地址映射。Outbound 传输事务通常涉及从系统到设备的数据流动,经常用到系统的 MMU 进行地址翻译。
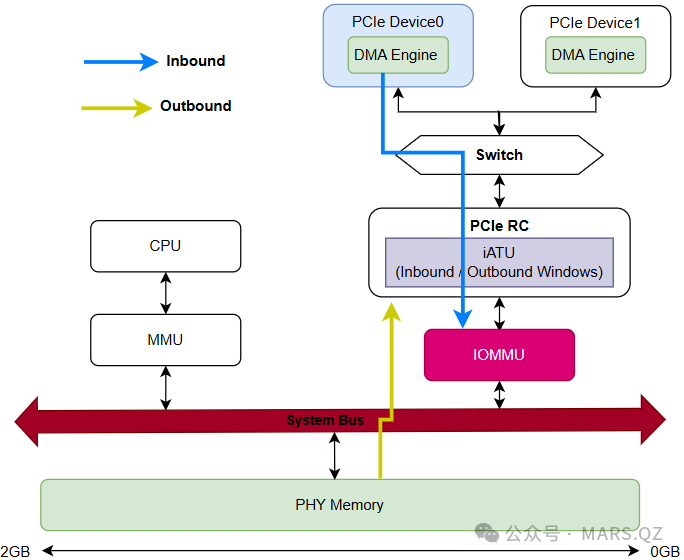
所以:
- Outbound:CPU 想要控制设备(CPU -> 设备)。
- Inbound:设备想要读写内存(设备 -> 内存)。
实际上方案一是在处理 MSI,本质是设备发起的写操作,即 Inbound 路径的变种,利用 iATU 重定向到 GIC/中断控制器。
实战案例:Outbound 与 Inbound
为了理解“窗口”的局限性,我们看两个具体场景。
场景 A:Outbound(CPU 访问 PCIe 显存)
- 需求:CPU 想访问网卡上 16MB 的 BAR 空间。
- SoC 物理地址预留:0x4000_0000 ~ 0x40FF_FFFF(16MB)。
- PCIe 总线地址(BAR):0x8000_0000 ~ 0x80FF_FFFF。
- iATU 配置:
- Base:0x40FF_FFFF
- Size:16MB
- Target:0x80FF_FFFF
- 结果:CPU 读 0x40000010 -> iATU 转换为 0x80000010 -> PCIe TLP 发出。
场景 B:Inbound(网卡 DMA 写 DDR)—— 这里的“窗口”特性最明显
- 需求:网卡要写系统内存。
- 问题:物理内存是支离破碎的。
- Page A:PA 0x1000_0000
- Page B:PA 0x3000_0000(这俩不连续!)
- iATU 的尴尬:
- 因为 iATU 只是线性平移,如果你配置一个大窗口(比如 1GB),它只能把一段连续的 PCIe 地址映射到一段连续的物理地址。
- 它不能像 MMU 那样,把连续的虚拟地址映射到离散的物理页。
这就是为什么网卡通常要使用预留的大块连续内存(CMA / Coherent Pool),或者利用 iATU 的“多窗口”特性。这涉及到系统底层资源的管理与优化。
Linux 内核中的实现
你可以在 Linux Kernel drivers/pci/controller/dwc/pcie-designware.c 中看到如下代码的实现:
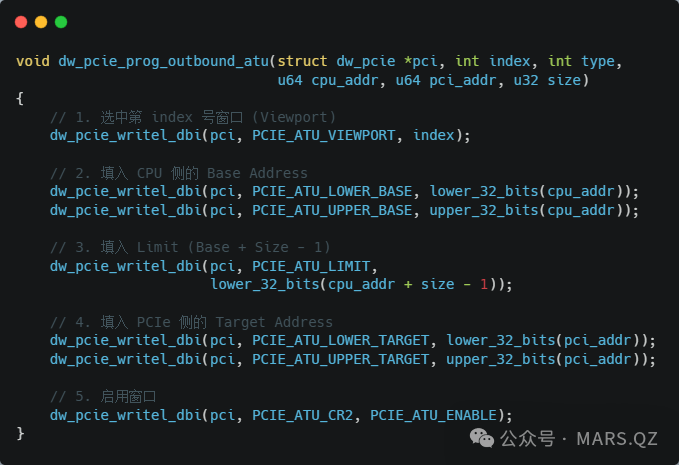
这段代码清晰地展示了:没有任何查表逻辑,就是单纯的“填寄存器”。
iATU 的特点
- 基于窗口(Window-based):它不像 MMU 那样查页表,而是配置固定的“窗口”。比如“只要落在 A 范围的地址,就减去 X,加上 Y”。
- 数量有限:通常只有 8 个或 16 个 Outbound/Inbound Viewport。
- 静态:通常在驱动初始化时配置好,运行过程中很少改。
开启 IOMMU 后的“双重翻译”
当开启 IOMMU 后,iATU 的角色依然存在,但“输出”的含义变了。请在脑海中构建这样一条数据流(以网卡 DMA 写入 DDR 为例):
路径:PCIe Device -> PCIe Link -> PCIe RC(iATU)-> IOMMU(SMMU)-> System Bus(AXI/NoC)-> DDR
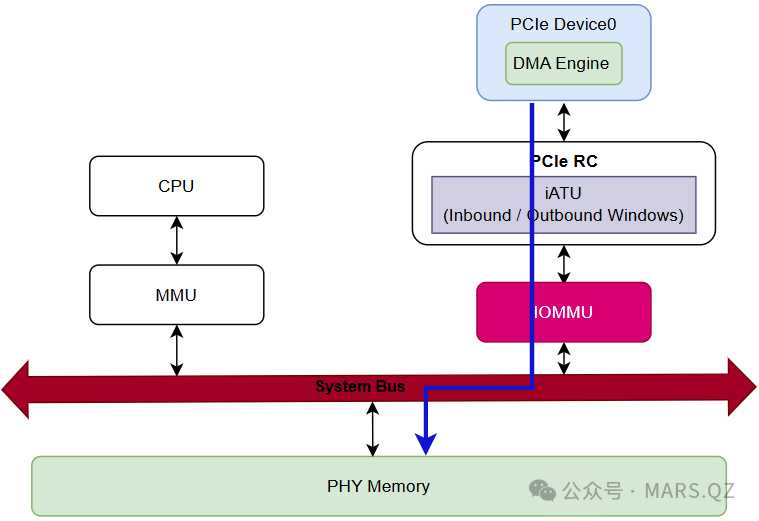
在这个流水线上,发生了两次翻译:
阶段一:iATU 翻译(协议层适配)
- 输入:PCIe 总线地址(Bus Address)。这是设备发出的 TLP 包里的地址。
- 动作:iATU 根据 Inbound 窗口配置,将其转换为总线地址(在没有 IOMMU 时,这就是最终物理地址 PA;在有 IOMMU 时,这其实是 IOVA)。
阶段二:IOMMU 翻译(系统层管控)
- 输入:来自 PCIe 控制器 Master 接口的 AXI 地址(即 iATU 的输出)。
- 动作:IOMMU 拦截这个请求,查询内存中的页表。
- 输出:最终物理地址,指向具体的内存地址。
iATU 并不是一个复杂的模块,但它是 PCIe 与 SoC 之间不可或缺的桥梁。理解 iATU,本质上是在理解 PCIe 系统中最底层的地址接入逻辑。之后再理解 IOMMU、DMA mask、SWIOTLB 等网络与系统相关的机制,才会真正变得更加清楚。这种从底层硬件机制到内核软件协同工作的全景理解,对于解决复杂驱动问题至关重要,也是技术社区中常被深入讨论的话题。
在你的驱动开发生涯中,有没有遇到过类似地址映射的“坑”呢?欢迎在评论区分享你的经历。
 发表于 2026-1-17 02:06:44
|
查看: 172|
回复: 0
发表于 2026-1-17 02:06:44
|
查看: 172|
回复: 0
