在数据驱动的业务环境中,业务人员经常面临这样的挑战:需要从数据库中提取数据,却受限于SQL编写技能,不得不依赖技术团队支持。这不仅影响工作效率,还增加了沟通成本。Text2SQL技术的出现改变了这一局面——用户只需用自然语言描述需求,系统就能自动生成并执行SQL查询。
本文深入解析一个生产级Text2SQL系统的完整实现,从架构设计到核心算法,全面介绍如何构建实用的智能数据问答系统。
一、系统架构概览
1.1 整体设计思路
该系统采用基于LangGraph的流式处理架构,将复杂查询过程拆分为多个独立节点,每个节点专注特定任务。整个流程如同数据处理流水线,环环相扣,最终将自然语言问题转化为可视化数据洞察。
1.2 核心处理流程
用户提问 → 表结构检索 → 表关系分析 → SQL生成 → SQL执行 → 数据总结 → 可视化渲染
每个环节都经过精心设计,确保系统准确理解用户意图,生成正确SQL,并以直观方式呈现结果。
1.3 技术栈选型
| 技术组件 |
用途 |
选型理由 |
| LangGraph |
工作流编排 |
提供状态管理和流式处理能力 |
| FAISS |
向量检索 |
高效的相似度搜索,支持大规模数据 |
| BM25 |
关键词匹配 |
经典的文本检索算法,补充语义检索 |
| DashScope |
嵌入模型 |
阿里云提供的高质量中文嵌入服务 |
| Neo4j |
图数据库 |
存储和查询表之间的关系 |
| SQLAlchemy |
数据库连接池 |
统一的数据库访问接口 |
| Langfuse |
链路追踪 |
监控和调试LLM调用过程 |
二、核心技术解析
2.1 混合检索:BM25 + 向量检索 + 重排序
面对包含数十甚至上百张表的数据库时,快速定位与用户问题相关的表是关键挑战。系统采用三层检索策略:
第一层:BM25关键词匹配
BM25算法通过分词和关键词匹配,快速筛选可能相关的表。系统对中文进行了特殊优化:
def _tokenize_text(text_str: str) -> List[str]:
"""对中文/英文文本进行分词"""
filtered_text = re.sub(r"[^\u4e00-\u9fa5a-zA-Z0-9]", " ", text_str)
tokens = jieba.lcut(filtered_text, cut_all=False)
return [token.strip() for token in tokens if token.strip()]
特别地,系统还会提升表注释的权重。如果用户查询词出现在表注释中,该表的相关性分数会得到额外加成:
overlap = set(query_tokens) & set(comment_tokens)
if overlap:
overlap_ratio = len(overlap) / len(set(query_tokens))
enhanced_scores[i] += score * overlap_ratio * 1.5
第二层:向量语义检索
使用FAISS进行向量相似度搜索,捕捉语义层面的相关性。系统构建了持久化的向量索引,并通过MD5指纹检测数据库结构变化:
def _generate_schema_fingerprint(table_info: Dict[str, Dict]) -> str:
"""生成schema的指纹,用于检测变更"""
fingerprint_data = {}
for table_name, info in table_info.items():
fingerprint_data[table_name] = {
"comment": info.get("table_comment", ""),
"columns": sorted([
f"{col_name}:{col_info.get('comment', '')}"
for col_name, col_info in info["columns"].items()
]),
}
json_str = json.dumps(fingerprint_data, sort_keys=True, ensure_ascii=False)
return hashlib.md5(json_str.encode("utf-8")).hexdigest()
这种设计避免了每次查询都重建索引,大幅提升系统性能。
第三层:RRF融合与重排序
系统使用RRF(Reciprocal Rank Fusion)算法融合BM25和向量检索的结果:
def _rrf_fusion(bm25_indices: List[int], vector_indices: List[int], k: int = 60) -> List[int]:
"""使用RRF融合两种检索结果"""
scores = {}
for rank, idx in enumerate(bm25_indices):
scores[idx] = scores.get(idx, 0) + 1 / (k + rank + 1)
for rank, idx in enumerate(vector_indices):
scores[idx] = scores.get(idx, 0) + 1 / (k + rank + 1)
sorted_indices = sorted(scores.items(), key=lambda x: -x[1])
return [idx for idx, _ in sorted_indices]
最后,使用DashScope的GTE-Rerank-V2模型对候选表进行精排,确保最相关的表排在前面。
2.2 检索策略对比
| 检索方法 |
优势 |
劣势 |
适用场景 |
| BM25 |
精确匹配关键词,速度快 |
无法理解语义,易受同义词影响 |
用户明确提到表名或字段名 |
| 向量检索 |
理解语义相似性,泛化能力强 |
计算成本高,可能召回不相关结果 |
模糊查询,概念性问题 |
| 重排序 |
综合多维度信息,精度高 |
需要额外API调用 |
最终排序优化 |
| 混合检索 |
结合各方法优势,鲁棒性强 |
实现复杂度高 |
生产环境推荐方案 |
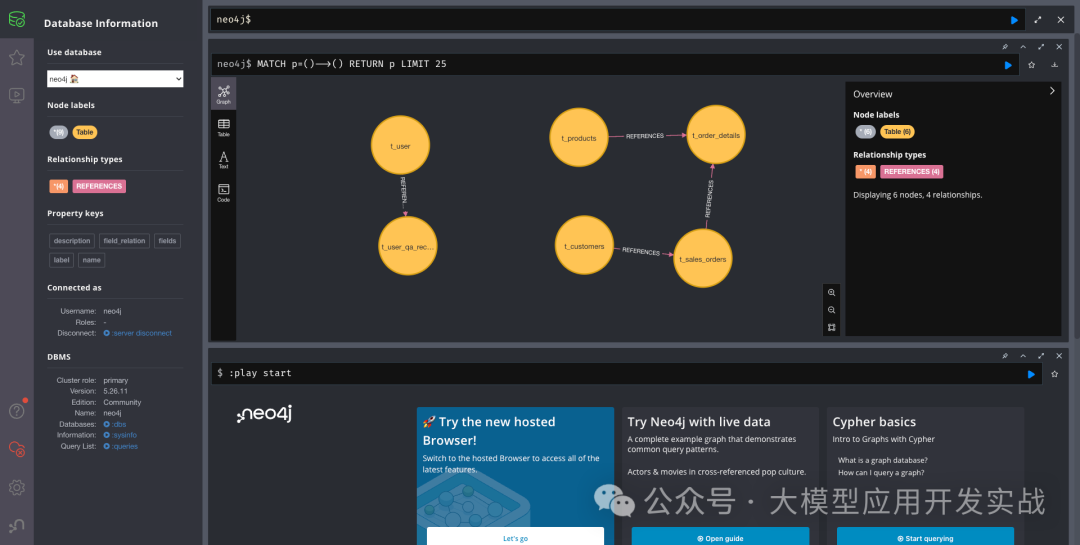
2.3 表关系图谱:Neo4j的妙用
在多表关联查询中,了解表之间的外键关系至关重要。系统使用Neo4j图数据库存储表关系,并通过Cypher查询快速获取相关表的连接关系:
MATCH (t1:Table)-[r:REFERENCES]-(t2:Table)
WHERE t1.name IN $table_names
AND t2.name IN $table_names
AND t1.name < t2.name
RETURN
t1.name AS from_table,
r.field_relation AS relationship,
t2.name AS to_table
这种设计有两个关键优势:
- 性能优化:图数据库天然适合关系查询,比在关系型数据库中递归查询外键快得多
- 灵活扩展:可以轻松添加更多元数据,如表的业务分类、数据质量标签等
2.4 SQL生成:Prompt工程的艺术
SQL生成是整个系统的核心。一个精心设计的Prompt需要平衡多个目标:
关键约束条件
prompt = """你是一位专业的数据库管理员(DBA),任务是根据提供的数据库结构、表关系以及用户需求,生成优化的MYSQL SQL查询语句,并推荐合适的可视化图表。
## 约束条件
1. 你必须仅生成一条合法、可执行的SQL查询语句
2. 严格且完整地仅使用所提供的表结构和表关系中明确定义的表名与列名
3. 严格遵守数据类型、外键关系及表结构中定义的约束
4. 使用适当的SQL子句(JOIN、WHERE、GROUP BY、HAVING、ORDER BY、LIMIT等)
5. 若问题涉及时序,请合理使用提供的"当前时间"上下文
6. 不得假设表结构中未明确定义的列或表
7. 如果用户问题模糊或缺乏足够信息,请返回:NULL
8. 当用户明确要求查看明细数据且未指定具体数量时,应适当限制返回结果数量(如LIMIT 50)
9. 对于聚合查询或统计类查询,不应随意添加LIMIT子句"""
图表类型推荐
系统不仅生成SQL,还会根据查询逻辑推荐最合适的可视化图表类型。Prompt中定义了20多种图表类型及其适用场景:
| 图表类型 |
适用场景 |
示例 |
| 折线图 |
时间序列趋势 |
最近7天的销售额变化 |
| 柱状图 |
类别对比 |
各地区销售额对比 |
| 饼图 |
占比分析 |
各产品类别销售占比 |
| 散点图 |
相关性分析 |
价格与销量的关系 |
| 桑基图 |
流向分析 |
用户转化漏斗 |
| 表格 |
明细数据展示 |
订单明细列表 |
2.5 流式响应:提升用户体验
系统采用SSE(Server-Sent Events)实现流式响应,让用户能够实时看到处理进度:
async for chunk_dict in graph.astream(**stream_kwargs):
langgraph_step, step_value = next(iter(chunk_dict.items()))
# 动态显示处理步骤
if new_step not in ["summarize", "data_render", "data_render_apache"]:
think_html = f"""<details style="color:gray;">
<summary>{new_step}...</summary>"""
await response.write(think_html)
用户可以看到系统正在执行的步骤:
- schema_inspector:检索相关表结构
- table_relationship:分析表关系
- sql_generator:生成SQL语句
- sql_executor:执行SQL查询
- summarize:总结数据洞察
- data_render:渲染可视化图表
2.6 数据总结:从数字到洞察
原始数据往往难以直接理解,系统使用LLM对查询结果进行智能总结。通过精心设计的角色Prompt,让AI扮演"数据趋势分析师":
prompt = """# Role: 数据趋势分析师
## Profile
- language: 简体中文
- description: 一位专注于从复杂数据中提取关键趋势与结构信号的资深分析师
- expertise: 时间序列分析、结构洞察、异常检测、模式识别、趋势推断
## Skills
1. 数据分析核心技能
- 趋势识别:判断时间序列数据的变动方向、拐点、周期性及持续性
- 结构洞察:在截面数据中识别分布特征、集中度、异常值
- 模式归纳:提炼可解释的品类/用户/行为差异信号
- 异常检测:发现偏离常规趋势的异常数值
## OutputFormat
## 🧩 数据分析
当前销售数据呈现明显的集中趋势,前**10**名商品中饮料类占据主导。
## **📌 关键发现**
- 🔍 **销售额环比增长6.2%**,低于前两周平均**12.5%**,存在增速放缓迹象
- 📈 **订单密度下降5.3%**,表明用户活跃度可能减弱
- 📦 **客单价提升11%**,主要由高单价商品销量增加驱动"""
这种设计让系统输出的不仅是冷冰冰的数据,而是有温度的业务洞察。
三、工程化实践
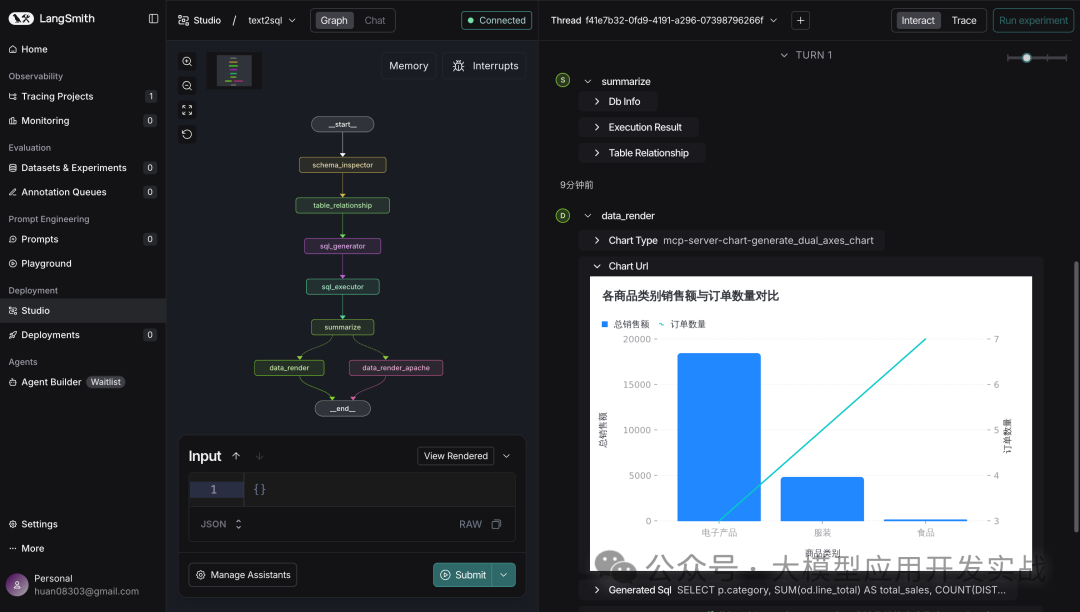
3.1 状态管理:LangGraph的优势
系统使用TypedDict定义了完整的状态结构,确保类型安全:
class AgentState(TypedDict):
user_query: str # 用户问题
db_info: Optional[Dict] # 数据库信息
table_relationship: Optional[List[Dict]] # 表关系
generated_sql: Optional[str] # 生成的SQL
execution_result: Optional[ExecutionResult] # 执行结果
report_summary: Optional[str] # 报告摘要
chart_type: Optional[str] # 图表类型
apache_chart_data: Optional[Dict] # 图表数据
attempts: int # 尝试次数
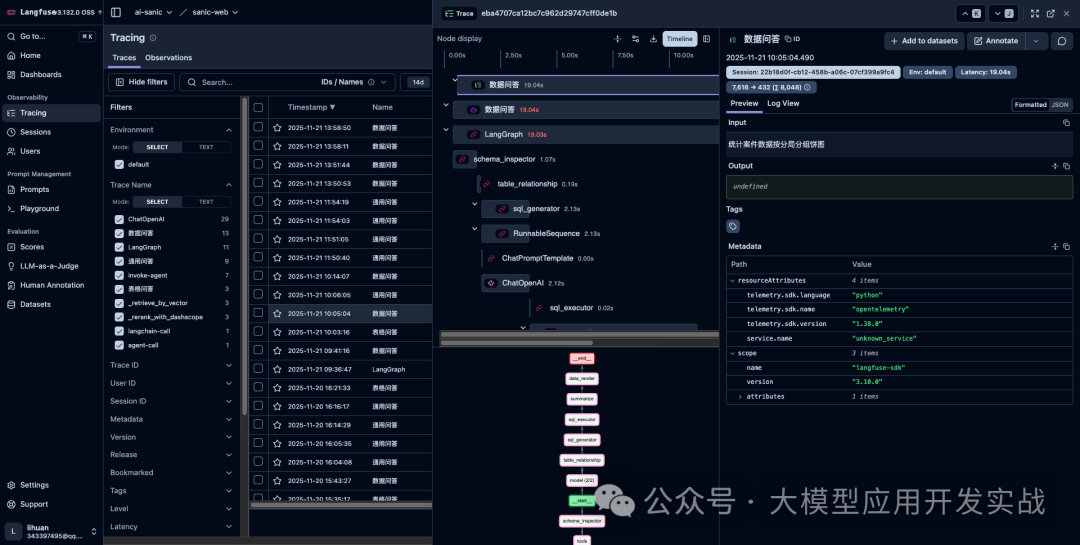
3.2 可观测性:Langfuse链路追踪
生产环境中,监控和调试LLM应用至关重要。系统集成了Langfuse进行全链路追踪:
if self.ENABLE_TRACING:
langfuse = get_client()
with langfuse.start_as_current_observation(
input=query,
as_type="agent",
name="数据问答",
) as rootspan:
rootspan.update_trace(session_id=chat_id, user_id=user_id)
async for chunk_dict in graph.astream(**stream_kwargs):
# 处理流式数据
这样可以清晰地看到:
- 每个LLM调用的输入输出
- Token消耗统计
- 响应时间分析
- 错误堆栈追踪
3.3 性能优化策略
| 优化点 |
实现方式 |
效果 |
| 向量索引缓存 |
使用LRU缓存和文件持久化 |
避免重复构建,提升90%启动速度 |
| 数据库连接池 |
SQLAlchemy连接池 |
减少连接开销,提升并发能力 |
| 批量嵌入 |
批量调用嵌入API |
减少网络往返,提升3倍速度 |
| 异步流式处理 |
async/await + SSE |
降低首字节时间,提升用户体验 |
| 表结构缓存 |
@lru_cache装饰器 |
避免重复查询元数据 |
3.4 错误处理与容错
系统在多个层面实现了容错机制:
try:
# 执行SQL
result = session.execute(text(generated_sql))
state["execution_result"] = ExecutionResult(success=True, data=result_data)
except Exception as e:
error_msg = f"执行SQL失败: {e}"
logger.error(error_msg, exc_info=True)
state["execution_result"] = ExecutionResult(success=False, error=str(e))
当检索失败时,系统会降级使用BM25结果:
if not candidate_indices:
candidate_indices = bm25_top_indices[:4] # 降级
logger.info("⚠️ 候选表为空,降级使用BM25前4个结果")
3.5 任务取消机制
在实际使用中,用户可能会中途取消查询。系统实现了优雅的取消机制:
async def cancel_task(self, task_id: str) -> bool:
"""取消指定的任务"""
if task_id in self.running_tasks:
self.running_tasks[task_id]["cancelled"] = True
return True
return False
# 在处理流程中检查取消状态
if task_id in self.running_tasks and self.running_tasks[task_id]["cancelled"]:
await response.write(self._create_response("\n> 这条消息已停止", "info"))
raise asyncio.CancelledError()
四、实战案例分析
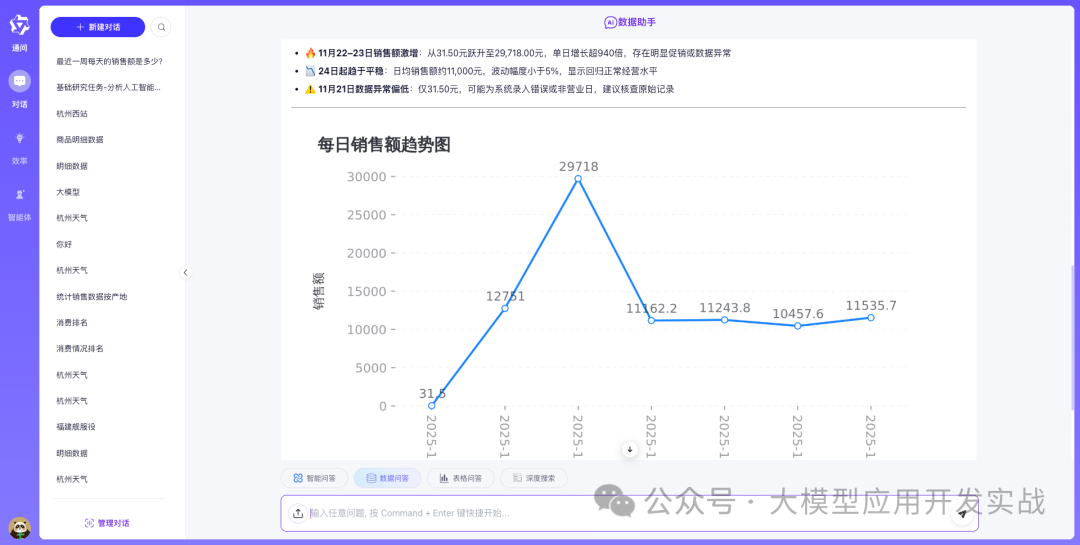
案例1:时间序列分析
用户提问:"最近一周每天的销售额是多少?"
系统处理流程:
- 表结构检索:
- BM25匹配到包含"销售"、"订单"关键词的表
- 向量检索补充语义相关的表
- 最终锁定:t_sales_orders(销售订单表)
- 表关系分析:
- 查询Neo4j,发现t_sales_orders与t_order_details有外键关系
- 确定需要关联查询
- SQL生成:
SELECT
DATE(order_date) as 日期,
SUM(total_amount) as 销售额
FROM t_sales_orders
WHERE order_date >= DATE_SUB(CURDATE(), INTERVAL 7 DAY)
GROUP BY DATE(order_date)
ORDER BY 日期 DESC
- 图表推荐:generate_line_chart(折线图)
案例2:多维度对比分析
用户提问:"各地区各产品类别的销售情况对比"
系统处理流程:
- 表结构检索:
- 识别需要:t_sales_orders、t_order_details、t_products、t_customers
- 表关系分析:
t_sales_orders → t_order_details (order_id)
t_order_details → t_products (product_id)
t_sales_orders → t_customers (customer_id)
- SQL生成:
SELECT
c.region as 地区,
p.category as 产品类别,
SUM(od.quantity * od.unit_price) as 销售额,
COUNT(DISTINCT so.order_id) as 订单数
FROM t_sales_orders so
JOIN t_order_details od ON so.order_id = od.order_id
JOIN t_products p ON od.product_id = p.product_id
JOIN t_customers c ON so.customer_id = c.customer_id
GROUP BY c.region, p.category
ORDER BY 销售额 DESC
- 图表推荐:generate_column_chart(柱状图)
五、系统优势与局限
5.1 核心优势
| 优势 |
说明 |
| 零SQL门槛 |
业务人员无需学习SQL即可查询数据 |
| 智能推荐 |
自动推荐最合适的可视化方式 |
| 实时反馈 |
流式处理,用户可见处理进度 |
| 高准确率 |
混合检索+重排序,确保表选择准确 |
| 可扩展性 |
模块化设计,易于二开添加新功能 |
| 可观测性 |
完整的链路追踪和监控 |
5.2 当前局限
- 复杂查询支持有限:对于涉及窗口函数、递归查询等高级SQL特性的需求,可能生成不准确
- 表数量限制:当数据库包含数百张表时,检索精度可能下降
- 语义理解边界:对于模糊或歧义的问题,可能需要用户澄清
- 成本考量:大量使用嵌入和重排序API会产生一定成本
- 多数据源支持:目前只支持MySQL数据库
- Neo4j表关系维护:目前只支持手动维护
5.3 未来优化方向
- 多数据源管理:支持更多类型数据库
- SQL验证与修正:增加人工SQL语法检查和手动修正节点
- 多轮对话支持:支持追问和上下文理解
- 查询缓存:对相似问题复用之前的查询结果
- 权限控制:根据用户角色限制可访问的表和字段
- Neo4j表关系:使用llm-graph-builder+UI页面化配置
六、总结
Text2SQL技术正在改变数据分析的方式,让数据查询从专业技能变成人人可用的工具。本文介绍的系统通过以下关键设计实现了生产级的可用性:
- 混合检索策略:BM25 + 向量检索 + 重排序,确保表选择准确
- 图谱增强:利用Neo4j存储表关系,支持复杂关联查询
- Prompt工程:精心设计的约束条件,提升SQL生成质量
- 流式处理:实时反馈处理进度,提升用户体验
- 智能总结:从数据到洞察,提供业务价值
该系统基于Python技术栈开发,结合了传统检索算法与现代人工智能技术,为企业级数据问答场景提供了实用解决方案。如果你也在构建类似的系统,希望本文的技术解析能给你带来启发。
 发表于 2025-11-29 03:00:51
|
查看: 367|
回复: 0
发表于 2025-11-29 03:00:51
|
查看: 367|
回复: 0
