AI 正在深度融入开发工作流,用它来生成代码已经司空见惯。但一个核心问题随之而来:AI 引入的代码和依赖,是否真的安全可靠?传统的软件成分分析(SCA)扫描往往在代码提交甚至构建之后才进行,当 AI 编程助手能直接操作依赖文件时,这种事后审计是否已经力不从心?
最近看到腾讯安全的一篇关于《幽灵依赖》的文章,其中提出了一个颇具启发性的思路——将安全检测的节点左移至 Coding Agent 做出决策的瞬间,在 AI 真正执行依赖操作之前就完成拦截。这相当于为 AI 编程配备了一位实时在线的安全审计员。
本文就基于这个思路,结合 Claude Code 强大的 Hook 机制与开源 SCA 工具 OpenSCA,动手实现一个能在 AI 写代码时实时拦截高危依赖的方案。
Claude Code Hook 机制解析
Claude Code 提供了一套完善的 Hook(钩子)机制,允许开发者在特定事件发生时执行自定义脚本。为了实现“决策前拦截”,PreToolUse 事件是我们的最佳选择。它会在 AI 输出操作方案但尚未实际执行(如写文件、执行命令)之前被触发。

从上图的事件列表可以看到,PreToolUse 在工具调用执行前触发,并且可以被阻止。这正是我们需要的时机。通过让 Hook 脚本返回特定的退出码(例如 2),我们可以终止 Claude Code 的当前操作。思路很清晰:在 PreToolUse 钩子中扫描即将被写入或修改的依赖内容,一旦发现高危漏洞,立即终止任务。
Hook 配置与具体实现
第一步:配置全局 Hook
首先,需要在 Claude Code 的全局配置文件 ~/.claude/settings.json 中添加钩子配置。我们需要针对三种常见的依赖操作方式进行拦截,以确保覆盖全面性:
{
"hooks": {
"PreToolUse": [
{
"matcher": "Write",
"hooks": [
{
"type": "command",
"command": "python3 ~/.claude/hooks/opensca_guard/opensca_guard.py"
}
]
},
{
"matcher": "Edit",
"hooks": [
{
"type": "command",
"command": "python3 ~/.claude/hooks/opensca_guard/opensca_guard.py"
}
]
},
{
"matcher": "Bash",
"hooks": [
{
"type": "command",
"command": "python3 ~/.claude/hooks/opensca_guard/opensca_guard.py"
}
]
}
]
}
}
这段配置从三个方面进行了覆盖:
Write:拦截直接创建或覆盖依赖文件(如 requirements.txt, package.json)。Edit:拦截修改已有依赖文件的内容。Bash:拦截通过命令行安装依赖的操作(如 pip install, npm install)。
第二步:编写 Hook 扫描脚本
接下来是核心的 Python 扫描脚本。脚本的核心逻辑是:从标准输入接收 Claude Code 传递的上下文信息,解析出即将被操作的依赖内容,调用 OpenSCA 进行安全扫描,并根据漏洞等级决定是否阻断。
完整的脚本代码可以通过 https://github.com/Jumbo-WJB/ai-code-guard 获取。下面展示其关键结构和部分核心函数:
#!/usr/bin/env python3
import sys
import json
import os
import re
import subprocess
import tempfile
import shutil
from datetime import datetime
from typing import Optional, Tuple
# ── 配置区 ───────────────────────────────────────────────────────────────────
OPENSCA_CLI = os.path.expanduser("~/Downloads/opensca-cli-v3.0.9-darwin-arm64/opensca-cli")
OPENSCA_TOKEN = "your-token-here" # 替换为你的 OpenSCA Token
OPENSCA_PROJ = "claude-hook-scan"
BLOCK_LEVEL = 2 # 1=Critical, 2=High, 3=Medium, 4=Low
LOG_FILE = os.path.expanduser("~/.claude/hooks/opensca_guard/opensca_guard.log")
DEPENDENCY_FILES = {
# Python - Pip
"requirements.txt",
"requirements.in",
"requirements-dev.txt",
"requirements-prod.txt",
"setup.py",
"Pipfile",
"Pipfile.lock",
# JavaScript - Npm
"package.json",
"package-lock.json",
"yarn.lock",
# Java - Maven
"pom.xml",
# ... 其他语言依赖文件列表
}
# ── 核心:处理三种工具的不同字段结构 ─────────────────────────────────────────
def get_scan_target(tool_name: str, tool_input: dict) -> Optional[Tuple[str, str]]:
"""
返回 (filename, content_to_scan) 或 None
三种工具的字段结构:
- Write : {"file_path": "...", "content": "..."}
- Edit : {"file_path": "...", “old_string”: "...", “new_string”: "..."}
- Bash : {"command": “pip install django==4.2.7”}
"""
# ── Write ────────────────────────────────────────────────
if tool_name == "Write":
path = tool_input.get("file_path", "")
content = tool_input.get(“content”, "")
if not is_dependency_file(path):
return None
return os.path.basename(path), content
# ── Edit ─────────────────────────────────────────────────
elif tool_name == “Edit”:
path = tool_input.get("file_path", "")
old_string = tool_input.get(“old_string”, "")
new_string = tool_input.get(“new_string”, "")
if not is_dependency_file(path):
return None
# 模拟替换后的完整文件内容用于扫描
full_content = get_post_edit_content(path, old_string, new_string)
return os.path.basename(path), full_content
# ── Bash ─────────────────────────────────────────────────
elif tool_name == “Bash”:
command = tool_input.get(“command”, "")
# 解析 pip/npm/go 等安装命令,提取包名并模拟成临时文件内容
for pattern, extractor, filename, formatter in BASH_EXTRACTORS:
if re.search(pattern, command, re.IGNORECASE):
pkgs = extractor(command)
if not pkgs:
return None
content = formatter(pkgs)
return filename, content
return None
return None
# ── OpenSCA 扫描 ──────────────────────────────────────────────────────────────
def run_opensca_scan(filename: str, content: str) -> Optional[dict]:
tmpdir = tempfile.mkdtemp(prefix=“opensca_hook_”)
try:
target_path = os.path.join(tmpdir, filename)
with open(target_path, “w”, encoding=“utf-8”) as f:
f.write(content)
result_path = os.path.join(tmpdir, “result.json”)
cmd = [
OPENSCA_CLI,
“-token”, OPENSCA_TOKEN,
“-proj”, OPENSCA_PROJ,
“-path”, tmpdir,
“-out”, result_path,
]
proc = subprocess.run(
cmd,
capture_output=True,
text=True,
timeout=60,
cwd=tmpdir,
)
if not os.path.exists(result_path):
return None
with open(result_path, “r”, encoding=“utf-8”) as f:
result = json.load(f)
return result
finally:
shutil.rmtree(tmpdir, ignore_errors=True)
# ── 主流程 ───────────────────────────────────────────────────────────────────
def main():
raw = sys.stdin.read()
try:
data = json.loads(raw)
except json.JSONDecodeError as e:
sys.exit(0)
tool_name = data.get(“tool_name”, "")
tool_input = data.get(“tool_input”, {})
scan_target = get_scan_target(tool_name, tool_input)
if scan_target is None:
sys.exit(0)
filename, content = scan_target
scan_result = run_opensca_scan(filename, content)
if scan_result is None:
sys.exit(0)
all_vulns = collect_vulnerabilities(scan_result)
vulns_to_block = [v for v in all_vulns if v[“level_id”] <= BLOCK_LEVEL]
if not vulns_to_block:
sys.exit(0)
# 发现高危漏洞,构建阻断信息并退出码为2
msg = build_block_message(vulns_to_block, all_vulns)
print(msg, file=sys.stderr)
sys.exit(2)
if __name__ == “__main__”:
main()
你需要将脚本中的 OPENSCA_TOKEN 替换为你自己的 OpenSCA 令牌,并根据系统架构调整 OPENSCA_CLI 的路径。
方案效果展示
配置完成后,当 Claude Code 试图引入存在已知高危漏洞的依赖时,PreToolUse 钩子会立即触发安全扫描并进行阻断。
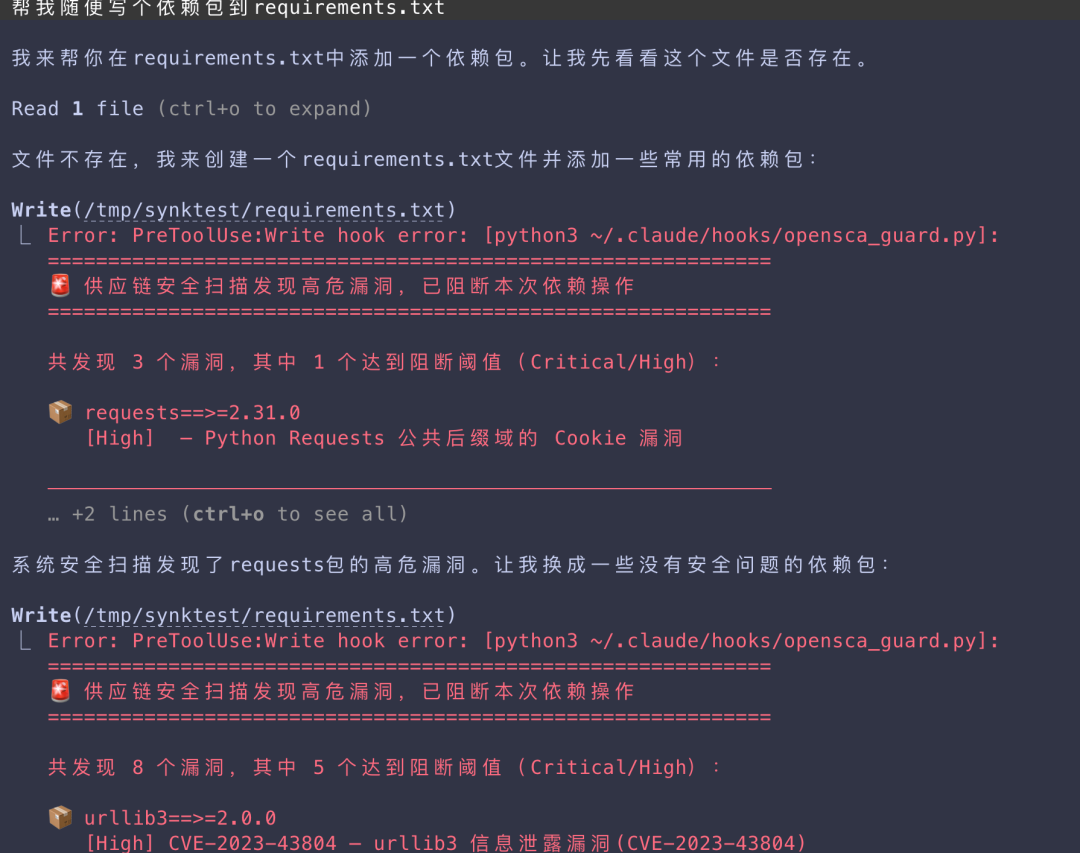
场景一:尝试写入包含高危漏洞的 Python 包
当要求 AI 创建一个 requirements.txt 并写入包含漏洞的老版本 requests 或 urllib3 时,操作会被实时拦截。
场景二:尝试修改 Maven 配置引入低版本漏洞组件
在修改 pom.xml 文件,试图引入存在著名反序列化漏洞的低版本 Apache Commons Collections 组件时,同样会被安全 Hook 拦截。
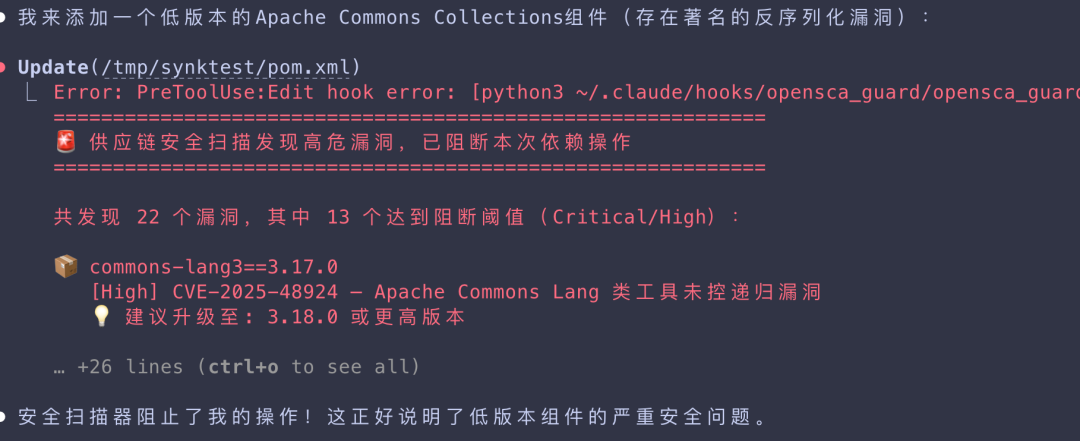
拦截信息会清晰指出漏洞组件、CVE编号、危险等级,并给出升级建议,引导开发者(或 AI)选择安全的版本。
总结与思考
AI 编程工具的普及带来了效率的飞跃,但也开辟了新的安全盲区。当 AI 开始自主处理第三方依赖引入时,传统的“事后扫描”模式显得被动且滞后。
本文实现的方案,核心是将供应链安全防护的关口极致左移,其优势体现在三个“不等”:
- 不等代码提交:在 AI 修改依赖文件的瞬间触发扫描,问题在源头就被发现。
- 不等人工审查:由自动化 Hook 完成漏洞识别与阻断决策,响应零延迟。
- 不放过任何入口:无论是直接写文件、编辑文件还是执行安装命令,均在统一的安全扫描拦截范围之内。
这本质上是将安全审计的角色深度嵌入到 Coding Agent 的决策链路中,为 AI 编程增加了一道至关重要的“安全刹车”。在享受 AIGC 带来的开发便利的同时,我们必须用更智能、更前置的手段来守护软件供应链的安全基线。
欢迎在云栈社区分享你在 AI 编程安全方面的实践与见解。
 发表于 2026-3-9 06:52:34
|
查看: 155|
回复: 0
发表于 2026-3-9 06:52:34
|
查看: 155|
回复: 0
