一、分层存储的诞生:解决海量数据存储成本问题
1.1 传统消息系统的存储困境
在传统消息系统中,所有消息无论新旧都存储在昂贵的本地存储或高性能集群中,导致存储成本随着数据量的增长呈线性上升。这种“一刀切”的存储方式,对于访问频率迥异的数据来说,造成了极大的资源浪费。
让我们通过一个时间维度分析来看看具体困境:
┌─────────────────────────────────────────────────────────────┐
│ 传统消息系统的存储成本困境 │
├─────────────────────────────────────────────────────────────┤
│ 时间维度分析: │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ 第1个月:活跃数据100GB,访问频率:每秒1000次 │ │
│ │ 存储成本:高性能SSD,成本高但必要 │ │
│ │ │ │
│ │ 第6个月:历史数据600GB,访问频率:每天几次 │ │
│ │ 存储成本:仍用高性能SSD,成本浪费严重 │ │
│ │ │ │
│ │ 第12个月:历史数据1.2TB,访问频率:每月几次 │ │
│ │ 存储成本问题更加突出,但数据仍需保留(合规要求) │ │
│ └───────────────────────────────────────────────────────┘ │
│ │
│ 成本对比: │
│ ┌────────────────┬─────────────┬──────────────┐ │
│ │ 存储类型 │ 成本/GB/月 │ 适用场景 │ │
│ ├────────────────┼─────────────┼──────────────┤ │
│ │ BookKeeper │ $1.50 │ 热数据 │ │
│ │ (高性能SSD) │ │ (高频访问) │ │
│ ├────────────────┼─────────────┼──────────────┤ │
│ │ 云对象存储 │ $0.023 │ 温数据 │ │
│ │ (S3标准层) │ │ (低频访问) │ │
│ ├────────────────┼─────────────┼──────────────┤ │
│ │ 云归档存储 │ $0.004 │ 冷数据 │ │
│ │ (Glacier) │ │ (极少访问) │ │
│ └────────────────┴─────────────┴──────────────┘ │
│ │
│ 按1PB数据计算: │
│ • 全量存储在BookKeeper:$1.5M/月 │
│ • 90%冷数据使用分层存储:$0.15M/月 │
│ • 成本节省:90% │
└─────────────────────────────────────────────────────────────┘
从上表可以看出,将极少访问的“冷数据”从昂贵的高性能存储迁移到廉价的对象存储(如S3、GCS),可以带来高达90%的成本节省。这正是Apache Pulsar分层存储(Tiered Storage)要解决的核心问题。
1.2 分层存储的核心价值主张
Apache Pulsar的分层存储特性,本质上是解决了“存储成本”与“数据可用性”之间的核心矛盾。它并非简单地删除旧数据,而是根据数据的“温度”(访问频率)将其智能地迁移到成本更合适的存储介质中。
传统方案面临哪些具体问题?Pulsar的分层存储又是如何解决的?
┌─────────────────────────────────────────────────────────────┐
│ 分层存储解决的核心问题 │
├─────────────────────────────────────────────────────────────┤
│ 问题1: 数据生命周期管理缺失 │
│ • 所有数据同等对待,无差别使用昂贵存储 │
│ • 无法根据访问频率优化存储成本 │
│ │
│ 问题2: 存储扩展性限制 │
│ • BookKeeper集群容量有限,扩展成本高 │
│ • 无法利用廉价的海量对象存储 │
│ │
│ 问题3: 运维复杂性 │
│ • 需要手动归档和删除旧数据 │
│ • 数据恢复流程复杂,容易出错 │
│ │
│ Pulsar分层存储解决方案: │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ 自动数据分层 │ │
│ │ • 根据策略自动将冷数据移动到廉价存储 │ │
│ │ • 对客户端透明,无需修改代码 │ │
│ │ │ │
│ │ 统一命名空间访问 │ │
│ │ • 无论数据在何处存储,访问方式不变 │ │
│ │ • 支持跨层数据检索 │ │
│ │ │ │
│ │ 智能缓存策略 │ │
│ │ • 热点数据自动缓存加速 │ │
│ │ • 减少远程读取延迟 │ │
│ └───────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
二、分层存储架构设计
2.1 整体架构概览
Pulsar的分层存储采用经典的“热-温-冷”分层架构,将对延迟敏感的热数据保留在性能最高的存储层,而将历史冷数据下沉到成本更低的存储层。
┌─────────────────────────────────────────────────────────────┐
│ Pulsar分层存储整体架构 │
├─────────────────────────────────────────────────────────────┤
│ ┌───────────────────────────────────────────────────────┐ │
│ │ Pulsar Client │ │
│ │ (无需感知数据位置,统一API访问) │ │
│ └──────────────────────────┬────────────────────────────┘ │
│ │ │
│ ┌──────────────────────────▼────────────────────────────┐ │
│ │ Pulsar Broker │ │
│ │ ┌─────────────────────────────────────────────────┐ │ │
│ │ │ 分层存储管理器 (TieredStorageManager) │ │ │
│ │ │ • 数据卸载决策 │ │ │
│ │ │ • 元数据管理 │ │ │
│ │ │ • 跨层读取协调 │ │ │
│ │ └─────────────────────────────────────────────────┘ │ │
│ └──────────────────────────┬────────────────────────────┘ │
│ │ │
├─────────────────────────────┼────────────────────────────────┤
│ 热数据层 (Hot Tier) │ 温/冷数据层 (Warm/Cold Tier) │
│ ┌──────────────────────┐ │ ┌─────────────────────────┐ │
│ │ Apache BookKeeper │ │ │ 云对象存储/文件系统 │ │
│ │ • 高性能分布式日志 │ │ │ • AWS S3 │ │
│ │ • 低延迟读写 │ │ │ • Google Cloud Storage │ │
│ │ • 数据强一致性 │ │ │ • Azure Blob Storage │ │
│ │ • 多副本保障 │ │ │ • HDFS │ │
│ └──────────────────────┘ │ └─────────────────────────┘ │
│ │ │
│ ┌──────────────────────┐ │ ┌─────────────────────────┐ │
│ │ 数据特征: │ │ │ 数据特征: │ │
│ │ • 最近几小时/天 │ │ │ • 几天到几年的历史数据 │ │
│ │ • 高频访问 │ │ │ • 低频访问 │ │
│ │ • 实时处理需要 │ │ │ • 批处理或合规访问 │ │
│ │ • 延迟敏感 │ │ │ • 延迟不敏感 │ │
│ └──────────────────────┘ │ └─────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
对于客户端而言,这一切都是透明的。无论是生产消息还是消费历史数据,都使用完全相同的API,Broker会负责在后台定位和获取数据,无论它实际存储在BookKeeper还是远端的S3中。
2.2 核心组件详解
分层存储的功能由Broker内一系列协同工作的核心组件实现。
┌─────────────────────────────────────────────────────────────┐
│ 分层存储核心组件交互关系 │
├─────────────────────────────────────────────────────────────┤
│ ┌───────────────────────────────────────────────────────┐ │
│ │ ManagedLedger (原始数据源) │ │
│ │ • 管理Ledger的生命周期 │ │
│ │ • 触发卸载条件检查 │ │
│ └──────────────────────────┬────────────────────────────┘ │
│ │ │
│ ┌──────────────────────────▼────────────────────────────┐ │
│ │ 分层存储管理器 (TieredStorageManager) │ │
│ ├───────────────────────────────────────────────────────┤ │
│ │ ┌─────────────────┐ ┌─────────────────┐ │ │
│ │ │ 卸载调度器 │ │ 卸载执行器 │ │ │
│ │ │ (OffloadScheduler)│ (OffloadExecutor) │ │ │
│ │ │ • 定期扫描 │ │ • 执行卸载任务 │ │ │
│ │ │ • 策略评估 │ │ • 数据上传 │ │ │
│ │ │ • 优先级排序 │ │ • 状态跟踪 │ │ │
│ │ └─────────────────┘ └─────────────────┘ │ │
│ └──────────────────────────┬────────────────────────────┘ │
│ │ │
│ ┌──────────────────────────▼────────────────────────────┐ │
│ │ 卸载器 (Offloader) │ │
│ │ ┌─────────────────────────────────────────────────┐ │ │
│ │ │ 工厂模式创建特定实现的卸载器 │ │ │
│ │ │ • S3Offloader (AWS S3) │ │ │
│ │ │ • GCSOffloader (Google Cloud Storage) │ │ │
│ │ │ • AzureOffloader (Azure Blob Storage) │ │ │
│ │ │ • FileSystemOffloader (HDFS/NFS) │ │ │
│ │ └─────────────────────────────────────────────────┘ │ │
│ └──────────────────────────┬────────────────────────────┘ │
│ │ │
│ ┌──────────────────────────▼────────────────────────────┐ │
│ │ 元数据存储 (Metadata Store) │ │
│ │ ┌─────────────────────────────────────────────────┐ │ │
│ │ │ /managed-ledgers/{tenant}/{namespace}/{topic} │ │ │
│ │ │ • ledger元数据: 位置、大小、卸载状态 │ │ │
│ │ │ • 卸载段信息: 存储位置、索引、校验和 │ │ │
│ │ │ • 使用ZooKeeper持久化 │ │ │
│ │ └─────────────────────────────────────────────────┘ │ │
│ └───────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
组件职责解析:
- ManagedLedger:Pulsar底层管理数据的抽象。当某个Ledger(数据段)被关闭且满足条件时,会通知分层存储管理器。
- TieredStorageManager:总指挥,协调卸载调度、执行和读取。
- OffloadScheduler:定时扫描已关闭的Ledger,根据配置的策略(时间、大小)决定哪些需要卸载。
- OffloadExecutor:负责执行具体的卸载任务,从BookKeeper读取数据并交给对应的Offloader。
- Offloader:与具体存储服务交互的驱动,如将数据上传到S3或GCS。采用工厂模式,支持灵活扩展。
- Metadata Store:使用ZooKeeper记录每个Ledger的卸载状态、在对象存储中的位置等关键元数据,这是实现跨层透明读取的基石。
2.3 数据单元:Offload Segment
分层存储操作的基本单位不是单条消息,而是 Offload Segment(卸载段)。一个Segment对应BookKeeper中一个已关闭Ledger的全部或部分数据。
public class OffloadSegment {
// 段元数据
private long segmentId; // 段ID
private long ledgerId; // 对应的Ledger ID
private long startEntryId; // 起始Entry ID
private long endEntryId; // 结束Entry ID
// 存储位置信息
private String bucket; // 存储桶(如S3 bucket)
private String key; // 对象键(如S3 key)
private String driver; // 驱动类型(s3, gcs等)
// 数据完整性
private long sizeBytes; // 段大小(字节)
private String checksum; // 数据校验和(CRC32/MD5)
private long timestamp; // 创建时间戳
// 索引信息(用于快速定位)
private Map<Long, Long> indexMap; // Entry ID -> 段内偏移量映射
public OffloadSegmentMetadata toMetadata(){
return OffloadSegmentMetadata.builder()
.segmentId(segmentId)
.ledgerId(ledgerId)
.startEntryId(startEntryId)
.endEntryId(endEntryId)
.bucket(bucket)
.key(key)
.driver(driver)
.sizeBytes(sizeBytes)
.checksum(checksum)
.timestamp(timestamp)
.build();
}
}
为了高效存储和读取,每个Offload Segment在对象存储中通常以两个文件的形式存在:
┌─────────────────────────────────────────────────────────────┐
│ Offload Segment 存储结构 │
├─────────────────────────────────────────────────────────────┤
│ 在对象存储中的文件组织: │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ bucket: pulsar-offload │ │
│ │ └── tenantA │ │
│ │ └── namespaceB │ │
│ │ └── topicC │ │
│ │ ├── segment-1001-0-999.data │ │
│ │ ├── segment-1001-0-999.index │ │
│ │ ├── segment-1002-1000-1999.data │ │
│ │ ├── segment-1002-1000-1999.index │ │
│ │ └── metadata.json │ │
│ └───────────────────────────────────────────────────────┘ │
│ │
│ 数据文件格式: │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ segment-{ledgerId}-{start}-{end}.data │ │
│ ├───────────────────────────────────────────────────────┤ │
│ │ [Entry Header][Entry Data][Entry Header][Entry Data]...│ │
│ │ • Entry Header: 长度(4B) + 校验和(4B) + 时间戳(8B) │ │
│ │ • Entry Data: 实际消息内容 │ │
│ └───────────────────────────────────────────────────────┘ │
│ │
│ 索引文件格式: │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ segment-{ledgerId}-{start}-{end}.index │ │
│ ├───────────────────────────────────────────────────────┤ │
│ │ [EntryID:8B][Offset:8B][EntryID:8B][Offset:8B]... │ │
│ │ • 排序的EntryID到文件偏移量的映射 │ │
│ │ • 支持二分查找快速定位 │ │
│ └───────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
- .data文件:存储实际的消息内容,格式与BookKeeper中基本一致。
- .index文件:一个紧凑的索引,记录每个Entry ID在.data文件中的起始偏移量。这是实现高效随机读取的关键,避免了下载整个数据文件来寻找一条消息。
三、分层存储工作原理
3.1 数据卸载(Offload)流程
数据从BookKeeper迁移到对象存储的过程称为“卸载”(Offload)。这是一个多阶段的异步流程。
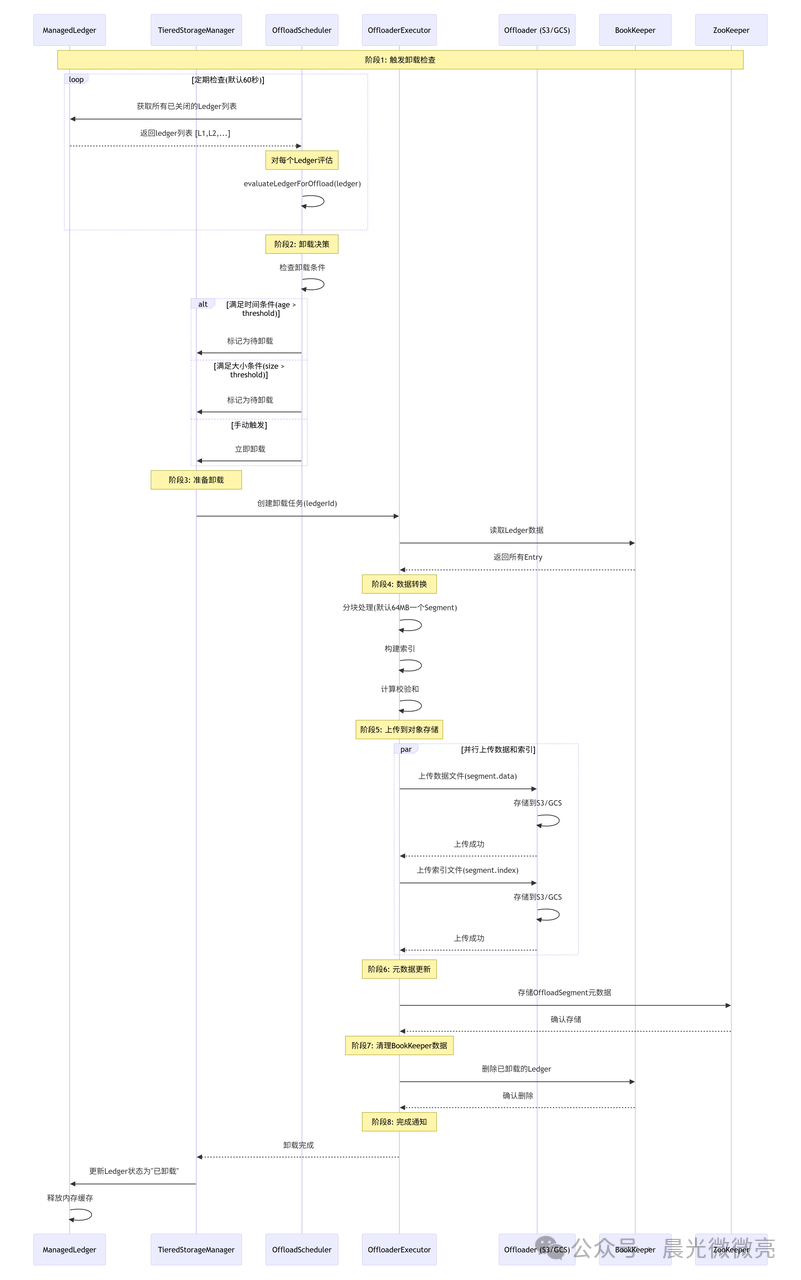
卸载决策是自动化的核心。OffloadPolicies 类封装了决策逻辑:
public class OffloadPolicies {
// 卸载策略配置
private Long offloadThresholdInBytes; // 大小阈值
private Long offloadThresholdInSeconds; // 时间阈值
private String offloadDeletionLagInMillis; // 删除延迟
// 卸载决策逻辑
public boolean shouldOffload(LedgerMetadata metadata){
// 检查Ledger是否已关闭
if (!metadata.isClosed()) {
return false; // 只有关闭的Ledger才能卸载
}
// 检查是否已卸载
if (metadata.isOffloaded()) {
return false; // 已卸载的不再处理
}
long currentTime = System.currentTimeMillis();
long ledgerAge = currentTime - metadata.getCloseTime();
// 时间阈值检查
if (offloadThresholdInSeconds != null &&
ledgerAge > TimeUnit.SECONDS.toMillis(offloadThresholdInSeconds)) {
return true;
}
// 大小阈值检查
if (offloadThresholdInBytes != null &&
metadata.getSize() > offloadThresholdInBytes) {
return true;
}
// 手动触发检查
if (metadata.isOffloadRequested()) {
return true;
}
return false;
}
// 计算卸载优先级(用于调度)
public double calculatePriority(LedgerMetadata metadata){
double priority = 0.0;
// 基于年龄的优先级(越老优先级越高)
long age = System.currentTimeMillis() - metadata.getCloseTime();
priority += age / (double)TimeUnit.DAYS.toMillis(1);
// 基于大小的优先级(越大优先级越高)
priority += metadata.getSize() / (double)(1024 * 1024 * 1024); // GB
// 基于手动请求的优先级
if (metadata.isOffloadRequested()) {
priority += 1000; // 手动请求具有最高优先级
}
return priority;
}
}
决策器会综合考虑Ledger的关闭时间、数据大小以及是否有手动触发请求。调度器则根据优先级对候选Ledger进行排序,确保最“冷”或最“大”的数据优先被处理。
3.2 跨层数据读取流程
当消费者或Reader需要读取已经卸载到对象存储的历史数据时,Broker会协调一次跨层读取。这个过程对客户端是完全透明的。
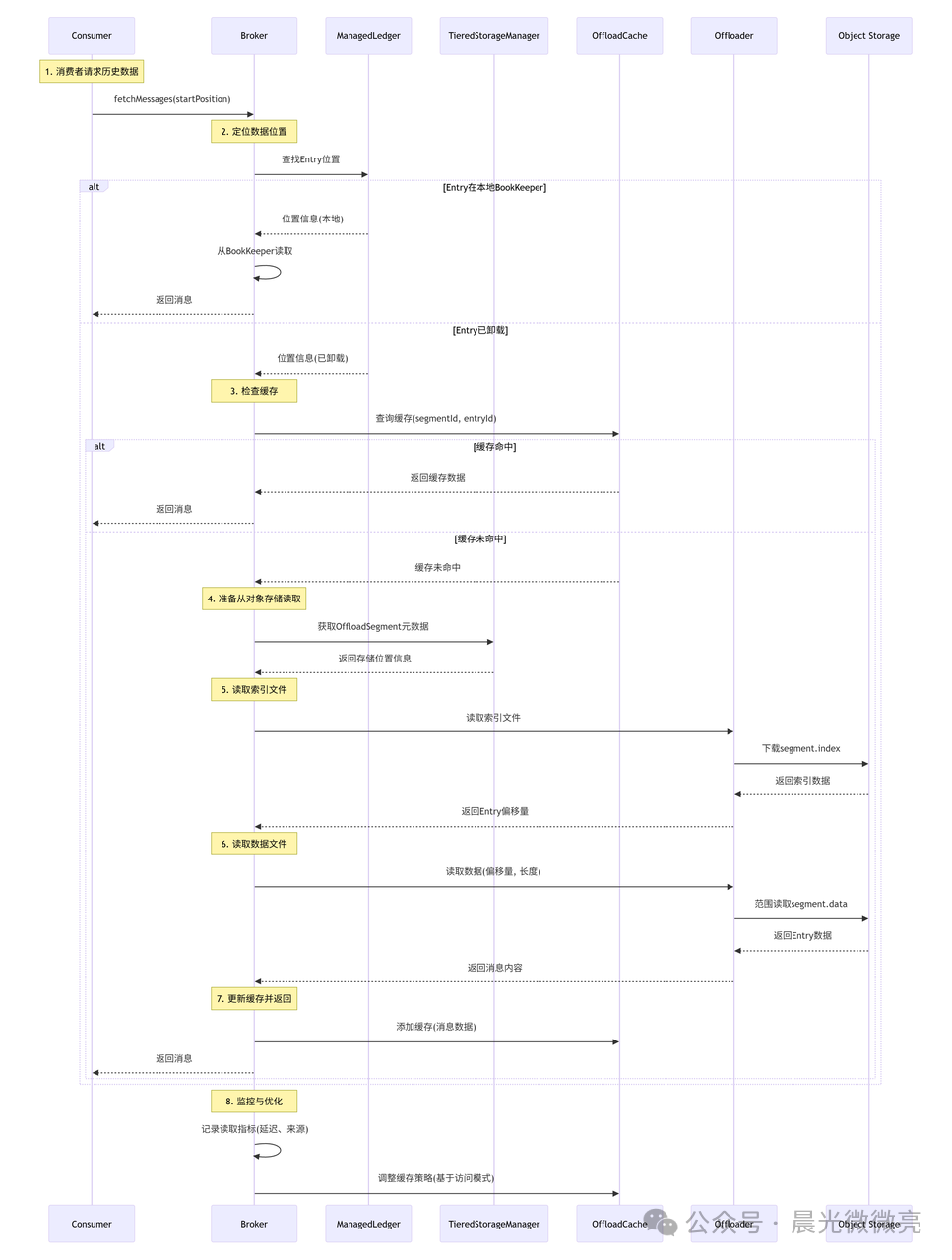
为了优化读取性能,特别是减少远程对象存储访问带来的延迟,Pulsar实现了带智能预读的缓存机制。
public class TieredStorageFetcher {
private final OffloadCache cache;
private final Offloader offloader;
private final ExecutorService prefetchExecutor;
// 读取已卸载的数据
public CompletableFuture<ByteBuf> fetchOffloadedData(
OffloadSegmentMetadata segment,
long entryId) {
// 1. 检查缓存
CacheKey key = new CacheKey(segment.getSegmentId(), entryId);
ByteBuf cached = cache.get(key);
if (cached != null) {
return CompletableFuture.completedFuture(cached.retain());
}
// 2. 从对象存储读取
return readFromObjectStore(segment, entryId)
.thenApply(data -> {
// 3. 存入缓存
cache.put(key, data.retain());
return data;
});
}
// 从对象存储读取(带预读优化)
private CompletableFuture<ByteBuf> readFromObjectStore(
OffloadSegmentMetadata segment,
long entryId) {
return CompletableFuture.supplyAsync(() -> {
try {
// 读取索引文件,找到Entry位置
long[] positions = readIndexFile(segment, entryId);
long offset = positions[0];
long size = positions[1];
// 范围读取数据文件
ByteBuf data = offloader.readOffloaded(
segment.getBucket(),
segment.getKey(),
offset,
size);
// 异步预读相邻Entry
schedulePrefetch(segment, entryId);
return data;
} catch (Exception e) {
throw new CompletionException(e);
}
}, prefetchExecutor);
}
// 预读优化
private void schedulePrefetch(OffloadSegmentMetadata segment, long currentEntryId) {
// 预读接下来的N个Entry
int prefetchCount = 10;
for (int i = 1; i <= prefetchCount; i++) {
long prefetchEntryId = currentEntryId + i;
if (prefetchEntryId <= segment.getEndEntryId()) {
CompletableFuture.runAsync(() -> {
CacheKey key = new CacheKey(segment.getSegmentId(), prefetchEntryId);
if (!cache.containsKey(key)) {
readFromObjectStore(segment, prefetchEntryId)
.thenAccept(data -> cache.put(key, data));
}
}, prefetchExecutor);
}
}
}
}
这个读取器首先检查多级缓存(见下文),如果未命中,则从对象存储精确读取所需的数据范围(利用.index文件定位),并异步触发对后续数据的预读,以应对顺序消费的场景。
3.3 分层存储缓存机制
为了弥补本地存储与远程对象存储之间的性能差距,Pulsar设计了一个高效的多级缓存架构。
┌─────────────────────────────────────────────────────────────┐
│ 分层存储的多级缓存架构 │
├─────────────────────────────────────────────────────────────┤
│ ┌───────────────────────────────────────────────────────┐ │
│ │ 消费者请求 │ │
│ └──────────────────────────┬────────────────────────────┘ │
│ │ │
│ ┌──────────────────────────▼────────────────────────────┐ │
│ │ L1缓存:内存缓存 (LRU, 1-5GB) │ │
│ │ ┌─────────────────────────────────────────────────┐ │ │
│ │ │ CacheKey = (SegmentId, EntryId) │ │ │
│ │ │ • 存储最近访问的Entry │ │ │
│ │ │ • 命中率:~30% (热点数据) │ │ │
│ │ │ • 延迟:< 1ms │ │ │
│ │ └─────────────────────────────────────────────────┘ │ │
│ └──────────────────────────┬────────────────────────────┘ │
│ │ │
│ ┌──────────────────────────▼────────────────────────────┐ │
│ │ L2缓存:本地磁盘缓存 (SSD, 10-100GB) │ │
│ │ ┌─────────────────────────────────────────────────┐ │ │
│ │ │ • 存储完整的Offload Segment │ │ │
│ │ │ • 文件系统组织:/cache/{segmentId}/ │ │ │
│ │ │ • 命中率:~50% (温数据) │ │ │
│ │ │ • 延迟:5-10ms │ │ │
│ │ └─────────────────────────────────────────────────┘ │ │
│ └──────────────────────────┬────────────────────────────┘ │
│ │ │
│ ┌──────────────────────────▼────────────────────────────┐ │
│ │ L3缓存:对象存储 (S3/GCS) │ │
│ │ ┌─────────────────────────────────────────────────┐ │ │
│ │ │ • 原始存储位置 │ │ │
│ │ │ • 命中率:100% (所有数据) │ │ │
│ │ │ • 延迟:50-500ms (取决于网络) │ │ │
│ │ └─────────────────────────────────────────────────┘ │ │
│ └───────────────────────────────────────────────────────┘ │
│ │
│ 缓存策略: │
│ • 写透缓存 (Write-through):上传时同时写入L2缓存 │
│ • 读回缓存 (Read-through):读取时填充L1/L2缓存 │
│ • 自适应预读:基于访问模式动态调整预读大小 │
│ • 缓存预热:Broker启动时加载热点数据到缓存 │
└─────────────────────────────────────────────────────────────┘
这种多级缓存策略在成本和性能之间取得了良好平衡,确保高频访问的历史数据能够快速返回,而真正的冷数据则按需从廉价存储中读取。
四、分层存储使用指南
4.1 配置分层存储
4.1.1 Broker端配置
首先需要在 broker.conf 中启用并配置分层存储。以下是一个针对AWS S3的配置示例:
# broker.conf 分层存储配置
# 启用分层存储
managedLedgerOffloadDriver=S3 # 可选: S3, GCS, Azure, filesystem
managedLedgerOffloadMaxThreads=2
# S3配置
s3ManagedLedgerOffloadRegion=us-west-2
s3ManagedLedgerOffloadBucket=pulsar-offload-bucket
s3ManagedLedgerOffloadServiceEndpoint=https://s3.us-west-2.amazonaws.com
s3ManagedLedgerOffloadMaxBlockSize=67108864 # 64MB
# 认证配置(可选,如果使用IAM角色则不需要)
s3ManagedLedgerOffloadCredentialId=AKIAIOSFODNN7EXAMPLE
s3ManagedLedgerOffloadCredentialSecret=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
# 卸载策略
managedLedgerOffloadAutoTriggerSizeThresholdBytes=10737418240 # 10GB
managedLedgerOffloadAutoTriggerTimeThresholdSeconds=86400 # 24小时
# 删除策略(卸载后多久从BookKeeper删除)
managedLedgerOffloadDeletionLagMs=14400000 # 4小时
# 缓存配置
managedLedgerOffloadCacheEnabled=true
managedLedgerOffloadCacheSizeBytes=10737418240 # 10GB
managedLedgerOffloadCacheDirectory=/data/pulsar/offload-cache
# 压缩配置(可选)
managedLedgerOffloadCompression=SNAPPY # 可选: SNAPPY, LZ4, ZLIB, ZSTD
4.1.2 命名空间级别配置
更细粒度的策略可以在命名空间级别设置,并支持动态更新。
# 设置命名空间的卸载策略
$ pulsar-admin namespaces set-offload-threshold \
--size 10G \
public/default
$ pulsar-admin namespaces set-offload-deletion-lag \
--lag 4h \
public/default
# 设置特定驱动配置
$ pulsar-admin namespaces set-offload-policies \
--driver "S3" \
--region "us-west-2" \
--bucket "my-offload-bucket" \
--endpoint "https://s3.us-west-2.amazonaws.com" \
--maxBlockSize 67108864 \
public/default
# 查看配置
$ pulsar-admin namespaces get-offload-policies public/default
4.2 手动管理操作
除了自动策略,Pulsar也提供了丰富的手动管理命令。
# 1. 手动触发主题卸载
$ pulsar-admin topics offload \
--size-threshold 10G \
persistent://public/default/my-topic
# 2. 强制立即卸载
$ pulsar-admin topics offload \
--size-threshold 0 \
persistent://public/default/my-topic
# 3. 查看卸载状态
$ pulsar-admin topics offload-status \
persistent://public/default/my-topic
# 4. 暂停卸载(维护时使用)
$ pulsar-admin namespaces set-offload-threshold \
--size -1 \
public/default
# 5. 触发已卸载数据的回迁(如果SSD空间充足)
$ pulsar-admin topics unload \
persistent://public/default/my-topic
# 6. 检查存储使用情况
$ pulsar-admin topics stats \
--get-precise-backlog \
persistent://public/default/my-topic
# 7. 监控卸载指标
$ pulsar-admin topics stats-internal \
persistent://public/default/my-topic
4.3 客户端使用示例
分层存储对客户端完全透明,这是其最大的优势之一。生产者和消费者代码无需任何修改。
// 生产者 - 无需任何修改
Producer<byte[]> producer = client.newProducer()
.topic("persistent://public/default/my-topic")
.create();
// 发送消息(可能最终被卸载到S3)
for (int i = 0; i < 1000000; i++) {
producer.send(("Message " + i).getBytes());
}
// 消费者 - 也无需修改
Consumer<byte[]> consumer = client.newConsumer()
.topic("persistent://public/default/my-topic")
.subscriptionName("my-subscription")
.subscriptionInitialPosition(SubscriptionInitialPosition.Earliest)
.subscribe();
// 读取消息(可能来自BookKeeper或S3,对消费者透明)
while (true) {
Message<byte[]> msg = consumer.receive();
try {
System.out.println("Received: " + new String(msg.getData()));
// 无论数据来源,确认方式相同
consumer.acknowledge(msg);
} catch (Exception e) {
consumer.negativeAcknowledge(msg);
}
}
// Reader API - 同样透明
Reader<byte[]> reader = client.newReader()
.topic("persistent://public/default/my-topic")
.startMessageId(MessageId.earliest)
.create();
while (reader.hasMessageAvailable()) {
Message<byte[]> msg = reader.readNext();
// 数据可能来自S3,但读取方式相同
System.out.println("Read: " + new String(msg.getData()));
}
五、高级特性与优化
5.1 多级分层存储
Pulsar的分层存储概念上可以支持多于两级的存储层,实现更精细化的数据生命周期管理(尽管当前版本配置上通常体现为两级)。其思想可以扩展到“热-温-冷-归档”多级策略。
# 多级分层存储配置示例
tieredStorage:
levels:
- name: "hot"
driver: "bookkeeper"
retention: 24h
trigger:
size: 10G
time: 6h
- name: "warm"
driver: "s3-standard"
bucket: "pulsar-warm-bucket"
retention: 30d
trigger:
size: 50G
time: 72h
compression: "LZ4"
- name: "cold"
driver: "s3-glacier"
bucket: "pulsar-cold-bucket"
retention: 365d
trigger:
time: 30d
compression: "ZSTD"
- name: "archive"
driver: "azure-archive"
container: "pulsar-archive"
retention: "forever"
trigger:
time: 365d
# 数据流动规则
dataMovement:
policies:
- from: "hot"
to: "warm"
condition: "age > 72h OR size > 50G"
- from: "warm"
to: "cold"
condition: "age > 30d AND access_frequency < 0.01"
- from: "cold"
to: "archive"
condition: "age > 365d"
5.2 智能卸载策略
未来的发展方向包括基于数据访问模式的更智能的卸载决策,而不仅仅是基于时间和大小。
public class IntelligentOffloadStrategy {
// 基于访问频率的卸载决策
public boolean shouldOffload(LedgerMetadata metadata,
AccessPatternStats stats) {
// 基本条件检查
if (!metadata.isClosed()) {
return false;
}
// 分析访问模式
double accessFrequency = stats.getAccessFrequencyPerHour();
long timeSinceLastAccess = stats.getTimeSinceLastAccess();
// 动态调整阈值
long dynamicTimeThreshold = calculateDynamicThreshold(accessFrequency);
long dynamicSizeThreshold = calculateSizeThreshold(stats);
// 综合决策
boolean byAge = metadata.getAge() > dynamicTimeThreshold;
boolean bySize = metadata.getSize() > dynamicSizeThreshold;
boolean byAccessPattern = shouldOffloadByPattern(stats);
// 使用决策树
if (byAccessPattern) {
return true;
} else if (accessFrequency < 0.001) { // 极少访问
return byAge || bySize;
} else if (accessFrequency < 0.01) { // 低频访问
return byAge && bySize;
} else { // 较高频率访问
return false; // 保持热存储
}
}
}
5.3 数据压缩与加密
在卸载过程中,可以集成数据压缩和加密,进一步优化存储成本和保障数据安全。
public class CompressedEncryptedOffloader implements Offloader {
private final Offloader delegate;
private final CompressionCodec codec;
private final EncryptionKey encryptionKey;
@Override
public CompletableFuture<OffloadResult> offload(
LedgerHandle ledger,
UUID uid,
Map<String, String> metadata) {
return CompletableFuture.supplyAsync(() -> {
try {
// 1. 读取原始数据
List<ByteBuf> entries = readAllEntries(ledger);
// 2. 压缩数据
List<ByteBuf> compressed = compressEntries(entries, codec);
// 3. 加密数据
List<ByteBuf> encrypted = encryptEntries(compressed, encryptionKey);
// 4. 构建索引
ByteBuf index = buildIndex(encrypted);
// 5. 上传压缩加密后的数据
String dataKey = uploadData(encrypted, uid);
String indexKey = uploadIndex(index, uid);
// 6. 返回结果(包含压缩比和加密信息)
return OffloadResult.builder()
.bucket(bucket)
.dataKey(dataKey)
.indexKey(indexKey)
.originalSize(calculateOriginalSize(entries))
.compressedSize(calculateCompressedSize(compressed))
.compressionRatio(calculateRatio(entries, compressed))
.encryptionAlgorithm(encryptionKey.getAlgorithm())
.build();
} catch (Exception e) {
throw new CompletionException(e);
}
});
}
// 读取时解压解密
@Override
public CompletableFuture<ByteBuf> readOffloaded(
String bucket, String key, long offset, long length) {
return delegate.readOffloaded(bucket, key, offset, length)
.thenApply(encryptedData -> {
// 1. 解密
ByteBuf decrypted = decrypt(encryptedData, encryptionKey);
// 2. 解压
ByteBuf decompressed = decompress(decrypted, codec);
return decompressed;
});
}
}
六、监控与管理
6.1 关键监控指标
有效的监控是保障分层存储稳定运行的关键。以下是一些核心监控指标:
┌─────────────────────────────────────────────────────────────┐
│ 分层存储关键监控指标 │
├─────────────────────────────────────────────────────────────┤
│ 类别 指标名 说明 │
├─────────────────────────────────────────────────────────────┤
│ 卸载统计 pulsar_offload_ledger_count 已卸载Ledger数 │
│ pulsar_offload_bytes_total 已卸载字节数 │
│ pulsar_offload_segment_count 已卸载段数 │
│ pulsar_offload_success_rate 卸载成功率 │
│ │
│ 性能指标 pulsar_offload_latency 卸载延迟 │
│ pulsar_offload_throughput 卸载吞吐量 │
│ pulsar_offload_queue_size 卸载队列大小 │
│ │
│ 存储使用 pulsar_storage_bookkeeper_size BookKeeper大小│
│ pulsar_storage_offloaded_size 已卸载数据大小 │
│ pulsar_storage_ratio 分层存储比例 │
│ │
│ 缓存效率 pulsar_offload_cache_hits 缓存命中数 │
│ pulsar_offload_cache_misses 缓存未命中数 │
│ pulsar_offload_cache_hit_rate 缓存命中率 │
│ pulsar_offload_cache_size 缓存大小 │
│ │
│ 读取性能 pulsar_offload_read_latency 卸载数据读取延迟│
│ pulsar_offload_read_count 卸载数据读取次数│
│ pulsar_offload_read_bytes 卸载数据读取字节│
│ │
│ 错误监控 pulsar_offload_errors 卸载错误数 │
│ pulsar_offload_timeout_errors 超时错误数 │
│ pulsar_offload_io_errors IO错误数 │
└─────────────────────────────────────────────────────────────┘
6.2 监控配置示例
可以集成Prometheus和Grafana进行可视化监控和告警。
# 配置Prometheus监控
metrics:
# 启用分层存储特定指标
enableTieredStorageMetrics: true
# 指标采样频率
metricsCollectionIntervalSeconds: 60
# 详细指标
detailedOffloadMetrics: true
# 告警规则
alerts:
- alert: HighOffloadLatency
expr: pulsar_offload_latency_seconds{quantile="0.99"} > 30
for: 5m
labels:
severity: warning
annotations:
summary: "Offload latency is high"
description: "Offload P99 latency is {{ $value }} seconds"
- alert: OffloadFailureRateHigh
expr: rate(pulsar_offload_errors_total[5m]) > 0.1
for: 5m
labels:
severity: critical
annotations:
summary: "High offload failure rate"
description: "Offload error rate is {{ $value }}"
- alert: LowCacheHitRate
expr: pulsar_offload_cache_hit_rate < 0.3
for: 10m
labels:
severity: warning
annotations:
summary: "Low offload cache hit rate"
description: "Cache hit rate is {{ $value }}"
6.3 运维管理命令
# 1. 实时监控卸载状态
$ pulsar-admin topics stats-internal \
persistent://public/default/my-topic \
--get-ledger-info
# 输出示例:
# Ledger 1001: Size=5GB, Status=OPEN, Location=BookKeeper
# Ledger 1002: Size=8GB, Status=OFFLOADED, Location=S3://bucket/segment-1002
# Ledger 1003: Size=12GB, Status=OFFLOADING, Progress=65%
# 2. 查看存储分布
$ pulsar-admin topics stats \
--get-storage-size \
persistent://public/default/my-topic
# 3. 强制重新加载元数据(修复不一致)
$ pulsar-admin topics reload \
persistent://public/default/my-topic
# 4. 检查数据完整性
$ pulsar-admin topics check-offloaded-data \
--verify-checksum \
persistent://public/default/my-topic
# 5. 导出卸载报告
$ pulsar-admin topics offload-report \
--format csv \
--output /tmp/offload-report.csv \
persistent://public/default/my-topic
# 6. 调整卸载参数(动态生效)
$ pulsar-admin topics set-offload-throttle \
--rate 100MB/s \
persistent://public/default/my-topic
# 7. 查看缓存状态
$ pulsar-admin topics cache-stats \
persistent://public/default/my-topic
七、故障排查与恢复
7.1 常见问题排查
遇到问题时,可以遵循系统化的排查路径。
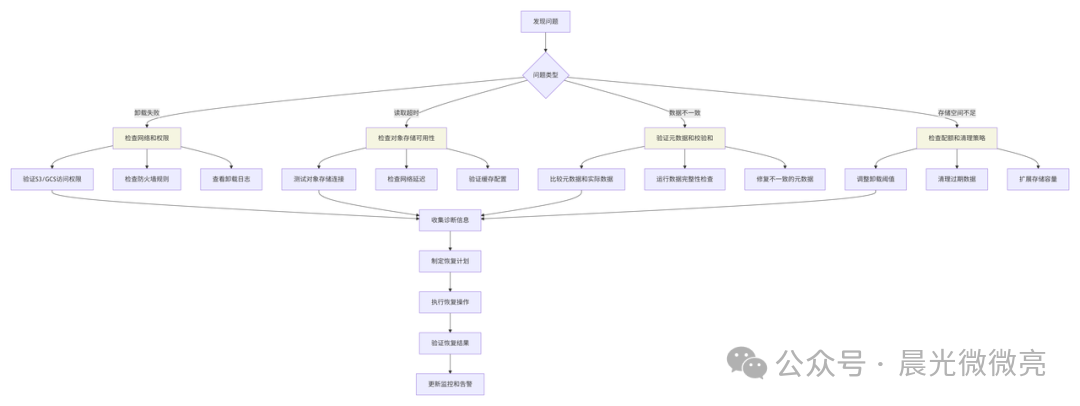
7.2 数据恢复流程
当对象存储中的数据因误删、损坏或云服务故障而丢失时,需要有一套恢复机制。Pulsar的恢复流程通常依赖于元数据记录和可能的备份。
public class TieredStorageRecovery {
// 数据恢复流程
public CompletableFuture<RecoveryResult> recoverOffloadedData(
String topic,
RecoveryPlan plan) {
return CompletableFuture.supplyAsync(() -> {
RecoveryResult result = new RecoveryResult();
// 1. 分析受损数据
List<DamagedSegment> damagedSegments =
analyzeDamagedSegments(topic, plan);
result.setTotalSegments(damagedSegments.size());
// 2. 逐段恢复
for (DamagedSegment segment : damagedSegments) {
try {
recoverSegment(segment, plan);
result.incrementRecovered();
} catch (Exception e) {
result.addFailedSegment(segment, e);
log.error("Failed to recover segment: {}", segment, e);
}
}
// 3. 更新元数据
if (result.getFailedCount() == 0) {
updateMetadataAfterRecovery(topic);
result.setStatus(RecoveryStatus.COMPLETED);
} else {
result.setStatus(RecoveryStatus.PARTIAL);
}
return result;
});
}
// 恢复单个段
private void recoverSegment(DamagedSegment segment, RecoveryPlan plan) {
switch (segment.getDamageType()) {
case COMPLETE_LOSS:
// 完全丢失,从备份恢复
restoreFromBackup(segment, plan.getBackupLocation());
break;
case CORRUPTED_DATA:
// 数据损坏,尝试修复
repairCorruptedData(segment);
break;
case METADATA_INCONSISTENCY:
// 元数据不一致,重建元数据
rebuildMetadata(segment);
break;
case PARTIAL_LOSS:
// 部分丢失,从其他副本恢复
restoreFromReplica(segment, plan.getReplicaLocations());
break;
}
// 验证恢复后的数据
verifyRecoveredSegment(segment);
}
}
最佳实践建议: 为生产环境中的重要数据启用对象存储的版本控制(Versioning)和跨区域复制(Cross-Region Replication),这是最有效的数据保护措施。
八、最佳实践
8.1 容量规划建议
合理的容量规划是保证分层存储效果和系统稳定性的基础。
┌─────────────────────────────────────────────────────────────┐
│ 分层存储容量规划指南 │
├─────────────────────────────────────────────────────────────┤
│ 步骤1: 分析数据访问模式 │
│ • 监控消息访问频率分布 │
│ • 识别热点数据和冷数据 │
│ • 确定合理的分层边界 │
│ │
│ 步骤2: 计算各层容量需求 │
│ ┌────────────────┬─────────────┬──────────────────────┐ │
│ │ 层级 │ 保留时间 │ 预估容量 │ │
│ ├────────────────┼─────────────┼──────────────────────┤ │
│ │ 热数据层 │ 最近24小时 │ 日均流量 × 1天 │ │
│ │ (BookKeeper) │ │ │ │
│ ├────────────────┼─────────────┼──────────────────────┤ │
│ │ 温数据层 │ 30天 │ 日均流量 × 30天 │ │
│ │ (S3标准层) │ │ │ │
│ ├────────────────┼─────────────┼──────────────────────┤ │
│ │ 冷数据层 │ 1年 │ 日均流量 × 365天 │ │
│ │ (S3冰川层) │ │ │ │
│ └────────────────┴─────────────┴──────────────────────┘ │
│ │
│ 步骤3: 配置卸载策略 │
│ • 热→温: 当数据超过24小时或BookKeeper使用率>80% │
│ • 温→冷: 当数据超过30天且访问频率<1次/天 │
│ • 设置合理的卸载批次大小和并发度 │
│ │
│ 步骤4: 监控和调整 │
│ • 监控各层存储使用率和成本 │
│ • 根据实际访问模式调整分层策略 │
│ • 定期审查和优化配置 │
└─────────────────────────────────────────────────────────────┘
8.2 成本优化策略
分层存储的最终目的是降本增效。通过精细化的策略,可以进一步优化总拥有成本(TCO)。
public class CostOptimizer {
// 基于成本的卸载决策
public CostOptimizedPlan optimizeForCost(
StorageRequirements requirements,
CostConstraints constraints) {
CostOptimizedPlan plan = new CostOptimizedPlan();
// 1. 分析成本构成
CostAnalysis analysis = analyzeCosts(requirements);
// 2. 优化热数据层大小
double optimalHotTierSize = calculateOptimalHotTierSize(
analysis.getAccessPattern(),
constraints.getMaxHotTierCost());
plan.setHotTierSize(optimalHotTierSize);
// 3. 选择最经济的冷存储
ColdStorageOption bestOption = selectBestColdStorage(
analysis.getRetentionRequirements(),
constraints.getBudget());
plan.setColdStorage(bestOption);
// 4. 优化压缩算法(权衡CPU和存储成本)
CompressionAlgorithm bestCompression = selectBestCompression(
analysis.getDataCharacteristics(),
constraints.getCpuBudget());
plan.setCompressionAlgorithm(bestCompression);
return plan;
}
}
关键优化点:
- 动态调整热层容量:根据业务高峰和低谷,动态调整BookKeeper集群规模或卸载阈值。
- 利用存储类别:根据数据访问预测,在S3标准层、智能分层(Intelligent-Tiering)和冰川层之间选择最优存储类别。
- 选择压缩算法:对于文本类日志,压缩率很高(如ZSTD),可大幅节省存储和传输成本;对于已压缩的二进制数据(如图片、视频),压缩收益有限,可关闭压缩以减少CPU开销。
- 错峰卸载:将卸载任务安排在业务低峰期或网络成本较低的时段执行。
九、未来发展方向
分层存储技术仍在不断演进,未来的方向将更加智能和自动化。
┌─────────────────────────────────────────────────────────────┐
│ 智能化分层存储演进方向 │
├─────────────────────────────────────────────────────────────┤
│ 1. 基于机器学习的智能分层 │
│ • 预测数据访问模式 │
│ • 动态调整分层策略 │
│ • 自动优化存储成本 │
│ │
│ 2. 多云混合存储 │
│ • 跨云厂商存储透明切换 │
│ • 基于价格自动选择存储层 │
│ • 避免云厂商锁定 │
│ │
│ 3. 边缘计算集成 │
│ • 边缘节点本地缓存 │
│ • 减少云端数据传输 │
│ • 支持离线访问 │
│ │
│ 4. 实时分析集成 │
│ • 直接对分层存储数据进行分析 │
│ • 减少数据移动开销 │
│ • 统一流批处理接口 │
│ │
│ 5. 增强的数据服务 │
│ • 数据版本管理 │
│ • 数据血缘追踪 │
│ • 合规性和审计支持 │
└─────────────────────────────────────────────────────────────┘
十、总结
Apache Pulsar的分层存储是一个革命性的特性,它通过智能的数据生命周期管理,在保证数据可用性的同时大幅降低存储成本。其核心优势包括:
- 成本效益:将冷数据自动迁移到廉价存储,节省高达90%的存储成本。
- 透明访问:客户端无需修改代码,API完全兼容,为分布式系统的架构简化提供了巨大便利。
- 智能管理:基于策略的自动卸载和智能的多级缓存优化,减轻运维负担。
- 企业级可靠性:完整的数据完整性保障、元数据管理和故障恢复机制。
分层存储使Pulsar能够轻松应对海量数据的历史保留需求,特别适合以下场景:
- 金融行业:交易记录长期保存(合规要求)。
- 物联网:海量设备数据的低成本存储和回溯分析。
- 日志管理:应用日志的集中存储和长期查询。
- 媒体流:视频点播、直播回看等历史数据归档。
通过深入理解其架构原理、熟练配置管理策略并遵循最佳实践,您可以充分发挥Apache Pulsar分层存储在现代化数据架构设计中的价值,构建既高效又经济的数据流处理平台。希望本文能为您在云栈社区及其他技术平台上的学习和实践提供清晰的指引。
 发表于 2026-1-17 06:31:46
|
查看: 147|
回复: 0
发表于 2026-1-17 06:31:46
|
查看: 147|
回复: 0
