一、事故回放:当“小气”的存储规划遇上业务增长
大清早,一个电话打破了平静。电话那头的声音已经带着压抑不住的颤抖:“糟了,我们生产环境全瘫了!9台虚拟服务器,没一台起得来,PVE界面点‘启动’完全没反应,急死人了!”
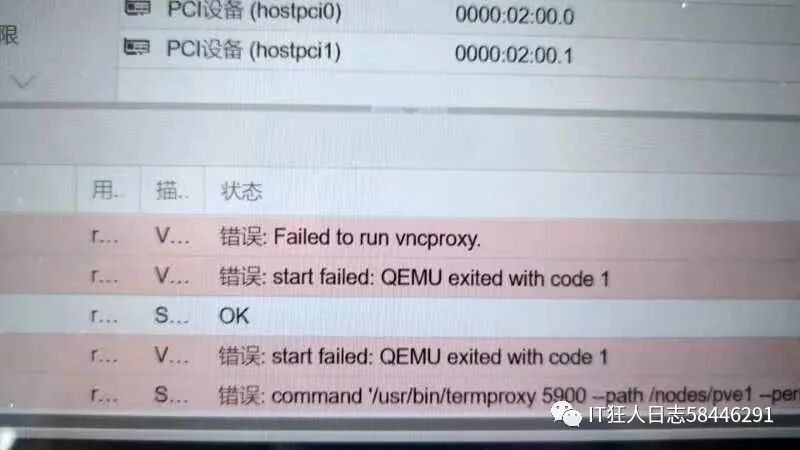
半小时后赶到现场,打开 Proxmox VE 管理界面,情况一目了然——9台运行着核心业务的虚拟机全部显示为“已暂停”状态,尝试点击启动按钮,系统没有任何响应。
更诡异的是,PVE宿主机本身可以正常登录,但执行 df -h 命令查看,根分区的使用率赫然显示为100%。同时,dmesg 系统日志里在不断刷出 “no space left on device” 的错误信息。
🔍 关键线索
- 宿主机仅配置了2块500GB SSD并做了RAID1,作为主要的存储盘 (
/dev/sda)。
- 这9台虚拟机均配置了100GB的精简配置 (Thin Provisioning) 虚拟硬盘。
- 单看理论值:9 × 100GB = 900GB > 500GB,明显超配。
- 实际排查发现,由于Thin Provisioning(精简配置)带来的“空间假象”,系统在初始分配时并未报错。但随着虚拟机持续写入数据,实际占用的物理空间逐渐超过了磁盘的真实容量,最终触发存储锁死,导致所有虚拟机被挂起。
💡 事故本质
这是一起典型的“存储超配+精简配置”引发的资源耗尽事件。PVE在使用LVM-Thin或ZFS存储池时,Thin Provisioning机制允许“超额分配”,即承诺给虚拟机的总逻辑空间可以超过实际的物理空间。但当底层物理空间被完全写满后,所有依赖该存储的虚拟机将因无法分配新的数据块而被迫挂起,并且无法正常启动。
二、救火方案:热插拔扩容与直接启动,实现业务快速恢复
阶段1:紧急诊断
登录PVE宿主机,执行以下命令查看所有存储池的状态:
pvesm status
输出结果显示 local-lvm 存储池的使用率已达到100%。毫无疑问,必须通过扩容来解决这个根本问题。
阶段2:硬件扩容
⚠️ 重要提示:别被“热插拔”吓到,并非只有SAS硬盘才能热插拔。在大多数现代服务器上,SATA硬盘同样支持热插拔操作。因此,在这种紧急情况下,直接插入新硬盘是可行的。
我们新增了一块1TB的SATA SSD。将硬盘插入服务器后,在PVE宿主机上执行命令查看新设备:
lsblk
列表中果然出现了一块新硬盘:sdb,容量约为931.5G,这正是刚才插入的新盘。
阶段3:扩容原LVM-Thin存储池
核心目标:将新硬盘的所有空间都加入到原有的卷组 (pve) 和Thin Pool (data) 中,以恢复存储池的可用空间。
操作步骤:
-
分区 (采用GPT格式,创建单个分区,并标记为LVM类型)
parted /dev/sdb
(在parted交互界面中执行:mklabel gpt, mkpart primary 0% 100%, set 1 lvm on, quit)
-
创建物理卷(PV)并扩展到原卷组(VG)
pvcreate /dev/sdb1
vgextend pve /dev/sdb1
-
扩展原Thin Pool逻辑卷(LV)
lvextend -l +100%FREE /dev/pve/data
-
刷新Thin Pool元数据 (确保PVE管理界面能识别新增的空间)
lvchange --refresh pve/data
验证扩容结果:
查看逻辑卷的详细信息,确认容量已增加:
lvdisplay /dev/pve/data
再次查看挂载点容量,确认空间已释放:
df -h /var/lib/vz
阶段4:直接启动虚拟机
完成对原LVM存储池的扩容后,虚拟机应当无需进行任何迁移或配置更改,可以直接启动!
关键原理:虚拟机被挂起是由于底层存储空间耗尽,导致无法为新写入的数据分配块,而并非虚拟机磁盘文件本身损坏。我们通过新增硬盘扩容了原LVM的Thin Pool,恢复了物理空间。原有的虚拟机磁盘文件(仍然位于原存储路径下)变得可正常访问,因此直接启动即可恢复。
操作步骤:
-
刷新PVE存储状态
登录PVE Web管理界面 → 进入“数据中心” → 点击“存储” → 选中 local-lvm → 点击“刷新”按钮。此时应能看到该存储的使用率已大幅下降。
-
逐台启动虚拟机
- 在PVE界面选中一台虚拟机,例如VM101,点击“启动”。
- 观察任务日志,如果提示“成功启动”,则说明该虚拟机已恢复正常。
-
批量启动剩余虚拟机
按照业务优先级,依次启动其他虚拟机。无需修改任何硬件配置,因为虚拟机的硬盘仍然指向原来的 local-lvm 存储。
关键验证点:
- 启动后,通过命令
qm status <vmid> 确认虚拟机状态为 running。
- 登录虚拟机内部,执行
df -h 命令,确认系统盘(例如100GB)的可用空间显示正常,证明原有数据未丢失。
- 进行基本的业务测试,如应用登录、数据库查询或文件传输,确保服务完全恢复。
三、经验总结:三条铁律与热插拔操作指南
🚨 铁律1:遵循科学的存储规划公式
物理容量 ≥ (单台虚拟机最大磁盘需求 × 虚拟机数量) × 1.5 (冗余系数)
- 错误案例:500GB物理空间承载9台100GB虚拟机,超配达80%,翻车是必然的。
- 正确做法:
- 对于9台100GB的虚拟机,至少需要规划:9 × 100GB × 1.5 = 1350GB 的物理容量。
- 或者在现有500GB容量下,最多安全运行:500GB / (100GB × 1.5) ≈ 3 台同类虚拟机。
🔧 铁律2:热插拔操作前的“三查”
- 查服务器支持:确认服务器的硬盘背板明确支持热插拔功能(通常SAS背板都支持)。
- 查硬盘兼容性:确认所使用的硬盘型号支持热插拔。通常企业级硬盘都支持,而消费级硬盘可能不支持。
- 查系统识别:插入硬盘后,务必使用
lsblk 或 fdisk -l 命令查看系统分配的设备名(可能是 sdb、sdc 等,取决于插入顺序),切勿想当然。
📊 铁律3:建立完善的监控预警机制
完善的监控是 运维 工作的生命线,很多故障在发生前其实早有征兆。
建议监控的核心指标:
- 存储使用率:设置阈值,例如80%触发警告,90%触发严重告警。
- Thin Pool使用率:对于使用了精简配置的存储池,此项监控至关重要。
- 虚拟机磁盘实际使用量:监控虚拟机内部文件系统的真实使用情况,而非分配的虚拟大小。
- 系统日志:定期扫描系统日志(如
/var/log/syslog, dmesg)中与磁盘、存储相关的错误信息。
💾 铁律4:备份是最后的防线
备份,备份,再备份! 除了在线热备,必须建立可靠的离线备份机制。
推荐的备份策略:
- 每日增量备份:减少数据丢失窗口。
- 每周全量备份:建立完整的恢复基点。
- 异地备份:防范机房级灾难。
- 定期恢复演练:确保备份数据的有效性和恢复流程的可靠性。
四、后续优化建议
-
配置RAID提供数据保护:本次扩容仅是应急修复,新增的硬盘以单盘模式运行存在风险。建议规划停机窗口,配置RAID 1(镜像)、RAID 10(性能与冗余兼顾)或至少RAID 5(单盘容错)来保护数据。
-
实施存储配额管理:在PVE或存储层面,为每台虚拟机设置磁盘使用配额(Quota),防止单一虚拟机过度占用空间,影响其他业务。
-
建立定期清理制度:
- 定期清理陈旧的、不必要的虚拟机快照。
- 制定日志轮转策略,自动清理过期的应用和系统日志文件。
- 清理各系统产生的临时文件。
希望这次真实的故障处理经历和总结,能为大家的服务器管理带来一些启发。更多运维实战经验,欢迎到 云栈社区 交流探讨。 |  发表于 2026-1-17 10:27:50
|
查看: 352|
回复: 0
发表于 2026-1-17 10:27:50
|
查看: 352|
回复: 0
