这个区别源于一个简单的问题:“这个构造函数的实现代码,到底是谁写的?”
C++ 构造函数的两种极其常见的写法:
写法 1:空的函数体。
struct A {
int data;
A() {}
};
写法 2:用 = default。
struct B {
int data;
B() = default;
};
A(){}的本质:用户自定义的 构造函数。虽然函数体是空的,但从编译器的角度来看,这个函数已经从“编译器自动生成”的范畴,变成了“用户提供的 ”范畴。A() = default;的本质:显式告诉编译器 生成一个默认的 构造函数。= default 就是授权编译器生成一个跟它在没有任何用户干预时所生成的完全相同的构造函数。
最重要、最本质的区别:类是否是 Trivial 类型或 POD (Plain Old Data) 类型。 这个会影响性能和行为。
二、核心区别
可能有人不知道什么是Trivial 类型和 POD (Plain Old Data) 类型。
- POD (Plain Old Data) :基本上就是一个 C 语言风格的结构体(
struct),里面只包含一些基本数据类型或其他的 POD 类型。内存布局是连续、紧凑、可预测的。可以用 memcpy 复制,或者把它写入文件再读出来。
- Trivial 类型:比 POD 更宽泛一些的概念。一个 Trivial 类型的构造、析构、拷贝、移动等特殊成员函数都是“微不足道”的(trivial)。这里的“微不足道”特指它们可以被编译器优化掉,或者其行为像简单的内存操作一样。所有 POD 类型都是 Trivial 类型,但反之不一定。成为 Trivial 类型可以获得极致性能。
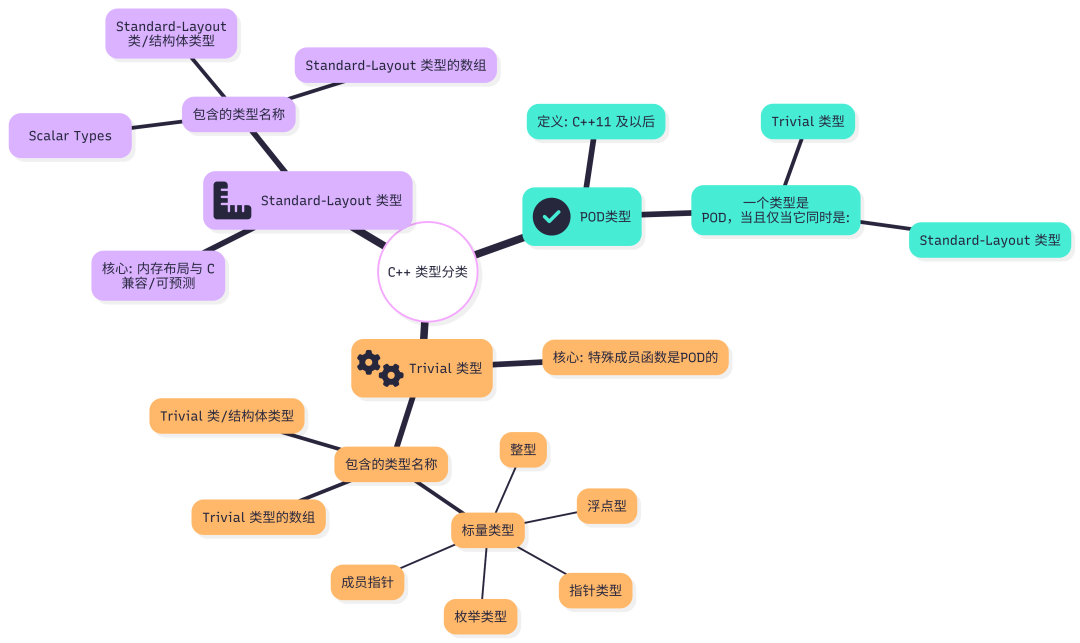
一个类型是 Trivial 的,编译器就可以对它进行大刀阔斧的优化。处理大量数据时,性能差异是天壤之别。
{} 是Trivial 属性的终结。 C++ 标准规定,只要一个类有任何一个用户提供的 特殊成员函数(包括构造函数、析构函数、拷贝/移动操作),它就不能是 Trivial 类型。即使什么也没做,这个“提供”的行为本身就跨过了红线,直接剥夺类成为 Trivial 类型或 POD 类型的资格。如果你希望深入了解类型系统及其对程序行为的影响,可以阅读云栈社区关于计算机基础的更多讨论。
相反,A() = default; 的含义是请求编译器生成一个默认实现。根据 C++ 标准,这种显式默认的 函数,如果其行为本来就是 trivial 的,那么它就被视为非用户提供的。只要类的所有成员和基类本身都是 Trivial 的,用 = default 就不会破坏 Trivial 属性。
三、性能影响
口说无凭,用 C++ 标准库的Type Traits工具来验证。std::is_trivial 和 std::is_pod 可以告诉一个类型是否符合这些属性。
#include <iostream>
#include <type_traits>
// 用户提供的空构造函数
struct NonTrivial {
int data;
NonTrivial() {}
};
// 默认构造函数
struct Trivial {
int data;
Trivial() = default;
};
// 作为对比,一个什么都不写的结构体
struct ImplicitlyTrivial {
int data;
};
int main()
{
std::cout << std::boolalpha;
std::cout << "Is NonTrivial trivial? "
<< std::is_trivial<NonTrivial>::value << std::endl;
std::cout << "Is NonTrivial a POD? "
<< std::is_pod<NonTrivial>::value << std::endl;
std::cout << "\n-----------------------------------\n\n";
std::cout << "Is Trivial trivial? "
<< std::is_trivial<Trivial>::value << std::endl;
std::cout << "Is Trivial a POD? "
<< std::is_pod<Trivial>::value << std::endl;
std::cout << "\n-----------------------------------\n\n";
// ImplicitlyTrivial 的行为和 Trivial 完全一致
std::cout << "Is ImplicitlyTrivial trivial? "
<< std::is_trivial<ImplicitlyTrivial>::value << std::endl;
std::cout << "Is ImplicitlyTrivial a POD? "
<< std::is_pod<ImplicitlyTrivial>::value << std::endl;
}
输出:
Is NonTrivial trivial? false
Is NonTrivial a POD? false
-----------------------------------
Is Trivial trivial? true
Is Trivial a POD? true
-----------------------------------
Is ImplicitlyTrivial trivial? true
Is ImplicitlyTrivial a POD? true
仅仅因为一个 {},NonTrivial 类就失去了 Trivial 和 POD 身份。了解这些底层细节,能帮助你写出性能更优的代码,这是C/C++开发者需要掌握的重要技能。
用 = default 的 Trivial 类,其行为更我们什么都不写时编译器自动生成的 ImplicitlyTrivial 类完全一致,保持 Trivial 和 POD 身份。
这是 {} 与 = default 之间最重要、最本质的区别。选择 {}, 就等于主动放弃编译器准备的性能优化大礼包。
四、深远影响
除了对 Trivial 类型和 POD 的决定性影响外,{} 和 = default 在现代 C++ 的 constexpr 和 noexcept 也有差异。
constexpr让函数或对象的值在编译期就计算出来。一个 constexpr 构造函数可以在编译期创建类的实例,对定义编译期常量、元编程以及提升运行时性能非常重要。
那么,两种构造函数写法,谁能更好跟 constexpr 协作?
- 如果一个类的所有成员都可以在编译期进行初始化,那么一个
= default 的构造函数可以非常好的声明为 constexpr。编译器知道如何生成一个符合 constexpr 要求的、标准的默认构造过程。
- 相比之下,
constexpr T() {} 的写法就麻烦多了。
- C++20 之前,这是非法的! C++11/14/17 标准对
constexpr 函数体有严格限制,一个非空的函数体(即使是 {}, 也不是“真正”的空)不满足要求,导致编译失败。
- C++20 之后,虽然语法上可能合法,但依然传达错误的信号。
constexpr 的核心是“行为可在编译期确定”,而 = default 恰恰是“使用编译器确定的标准行为”的完美表达。用户提供的 {} 则暗示了某种自定义逻辑,这跟 constexpr 的意图有所冲突。
noexcept 关键字向编译器和调用者承诺“这个函数不会抛出任何异常”。这个承诺能带来两方面的好处:首先,它是一种强有力的接口文档;其次,编译器可以用这个信息生成更优化的代码,特别是移动语义和标准库容器。
看看两种写法在 noexcept 规范上的默认行为。
- 一个特殊成员函数被声明为
= default 时,编译器会自动为其推断 noexcept 规范。规则很简单:如果所有用来实现该函数的操作(即对所有基类和成员的相应操作)都是 noexcept 的,那么这个默认生成的函数也是 noexcept 的。
- 相反,一个用户提供的构造函数(即使是
{})默认不是 noexcept 的,除非显式声明,要达到跟 = default 相同的效果,必须手动添加 noexcept。
遵循明确的编码原则,例如在合适的情况下优先使用= default,能使代码意图更清晰,也便于编译器进行代码优化,这在构建高性能系统时尤为重要。
五、总结
一张图看懂所有区别:
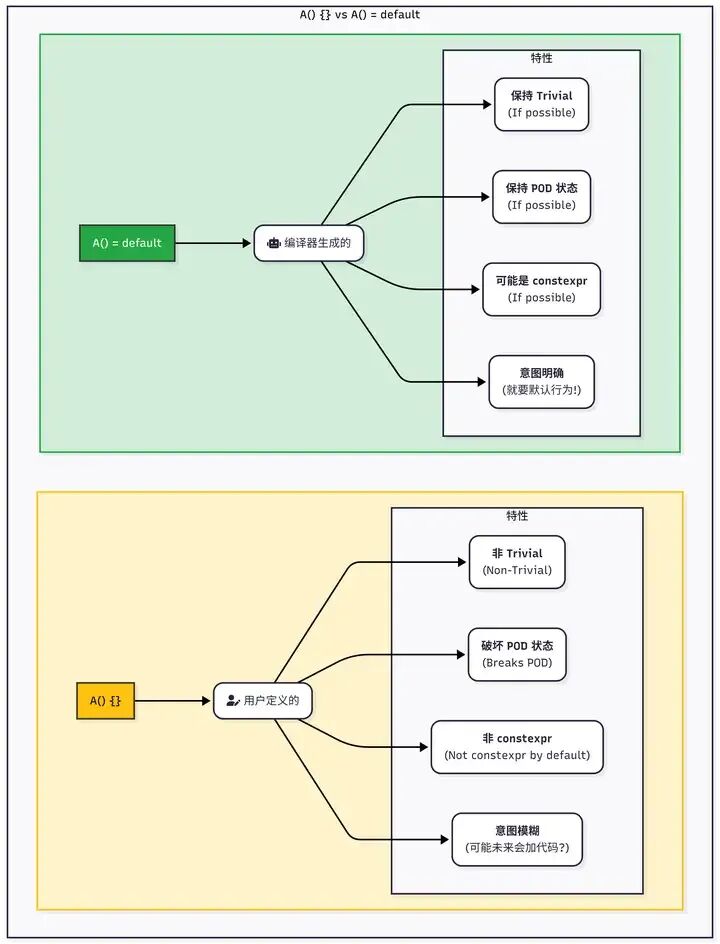
| 特性/行为 |
A(){} |
A() = default; |
| 实现来源 |
用户 |
编译器 |
| Trivial/POD 属性 |
破坏 Trivial/POD 属性 |
保持 Trivial/POD 属性(如果可能) |
constexpr 兼容性 |
不能(C++20前非法,C++20后语义模糊) |
可以 |
noexcept 规范 |
默认不是noexcept |
自动推断 noexcept |
| 代码意图表达 |
自定义了一个空实现 |
要编译器生成的默认实现 |
| 可读性 |
易引起误解 |
清晰明确 |
| 性能影响 |
阻止编译器优化 |
编译器进行最大程度的优化 |
永远优先用 A() = default;。
这类细微但关键的语法差异,对于设计高性能、高可用的系统至关重要,也值得在技术社区深入探讨。想了解更多C++及软件开发的知识,欢迎访问云栈社区进行交流学习。
 发表于 2026-1-17 11:30:59
|
查看: 145|
回复: 0
发表于 2026-1-17 11:30:59
|
查看: 145|
回复: 0
