许多Java开发者在工作数年后,依然深陷于日常的增删改查(CRUD)循环。简历投递后石沉大海,面试中一旦被深入追问技术细节便难以应对,这已成为一个普遍的职业发展瓶颈。
问题的核心往往不在于工作内容本身,而在于表述方式。面试官深知大部分业务本质是数据处理,他们真正考量的是开发者面对问题时的思考深度和系统化设计能力。将基础的Controller-Service-Dao项目,通过合理的“包装”与深挖,呈现出架构层面的考量,是突破薪资天花板的关键。
下面分享三个核心技巧,帮助你将简单的业务实现,转化为能体现技术深度的项目经验。
技巧一:从“功能实现”转向“故障解决”
流水账式的功能描述很难引起面试官的兴趣。高段位的回答需要构建一个“问题-排查-解决”的叙事闭环,尤其是围绕生产环境中的真实故障展开。
低阶表述:我使用了Redis来提升查询性能。
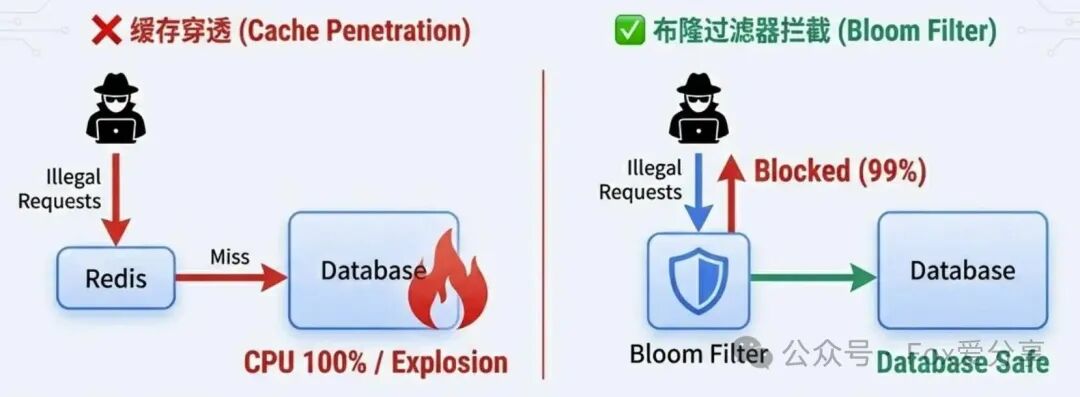
高阶表述:我主导解决了因缓存穿透导致的数据库CPU瞬时飙升至100%的生产故障。
包装核心(故障驱动法):故事的重点不在于一帆风顺的实现,而在于系统遭遇危机时的应对。一个经典的叙事结构是:系统平稳运行 -> 突发异常指标(如CPU飙升、响应超时)-> 多维度日志与链路排查 -> 定位根本原因 -> 设计并实施解决方案。
参考话术:
“在这个项目中,虽然业务逻辑相对标准,但在应对高并发场景时,我们遭遇了严重的缓存穿透问题。监控系统告警显示数据库主节点CPU使用率瞬间达到100%,业务响应时间激增。通过分析应用日志和慢查询,我们发现存在大量对不存在商品ID的恶意请求,这些请求在Redis层全部未命中,导致流量直接穿透到MySQL数据库,造成巨大压力。
我并没有选择简单地增加请求频率限制,而是决定在架构层面引入布隆过滤器作为前置屏障。在缓存查询之前,先通过布隆过滤器校验请求Key的有效性,成功拦截了超过99%的非法请求。同时,为了处理极少数因布隆过滤器误判而导致合法请求被拦截的边缘情况,我额外设计了一套基于消息队列的异步缓存重建与过滤器数据同步机制,确保系统的最终一致性和高可用性。”
技巧二:将“技术选型”提升为“架构思考”
简单地罗列使用的技术栈(如:用了Redis做缓存)价值有限。面试官更希望听到你在诸多可选方案中,基于何种考量做出最终决策,尤其是对稳定性、边界情况和潜在风险的权衡。
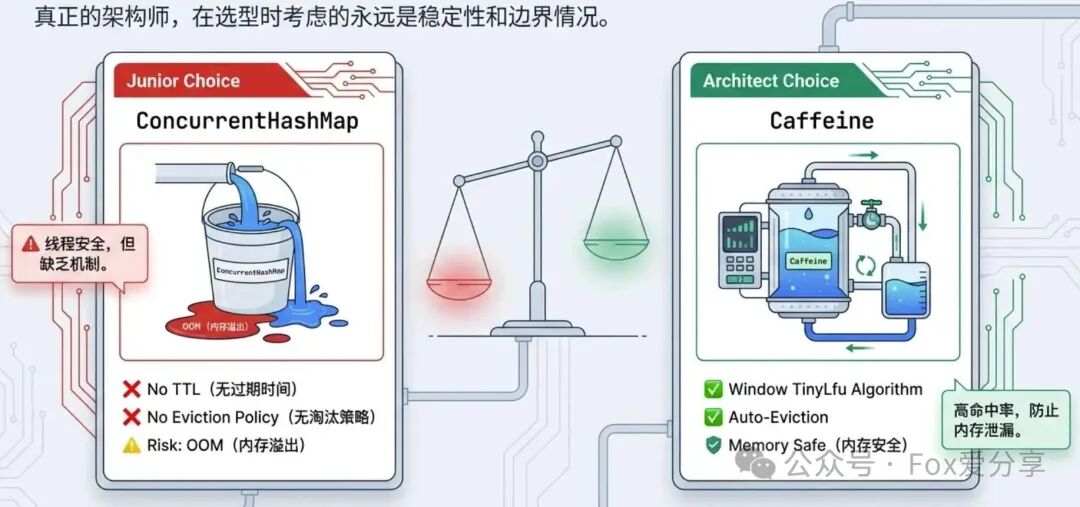
低阶表述:我们使用ConcurrentHashMap作为本地缓存,因为它线程安全。
潜在面试官印象:候选人可能缺乏生产环境经验,未考虑内存无限制增长的风险。
包装核心(防患于未然):展示你在技术选型时,不仅关注其基本功能,更深入评估了其在极端情况下的表现,并选择了具备完备生产级特性的组件。
参考话术:
“在项目初期,我们确实考虑过使用JDK原生的ConcurrentHashMap来实现应用内缓存。但经过评估,它存在两个致命缺陷:第一,不具备条目自动过期(TTL)能力;第二,没有内置的内存淘汰策略。这意味着在长期运行的Spring Boot服务中,缓存数据会只增不减,极易引发内存泄漏最终导致OutOfMemoryError,对系统稳定性构成严重威胁。
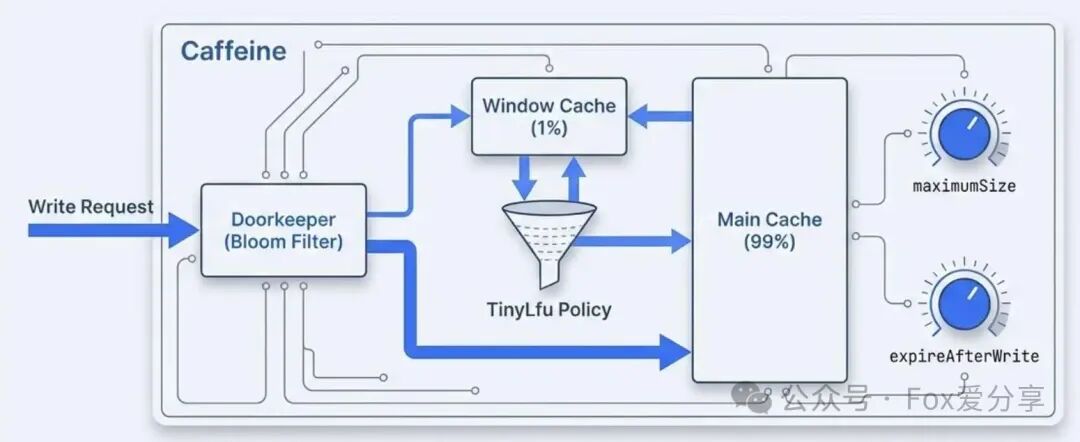
因此,我主导将本地缓存组件迁移到了Caffeine。我深入研究过其采用的Window TinyLfu淘汰算法,相比传统的LRU,它能更精准地识别并保留真正的热点数据,从而获得更高的缓存命中率。在配置上,我们明确了maximumSize上限和expireAfterWrite写后过期时间,这样既保证了高频数据的快速访问,又从根本上杜绝了因缓存无限膨胀而导致JVM崩溃的风险。这种对稳定性和边界情况的考量,正是面向对象设计模式与系统设计原则在实际中的体现。”
技巧三:为“简单业务”设计“极限兜底”方案
资深工程师与初阶工程师的一个显著区别在于“面向失败设计”的思维。你需要假设所有外部依赖(如Redis缓存、消息队列、MySQL数据库)都可能失效,并为此准备好降级预案。
包装核心(防御性编程):展示你的系统具备分层防御的能力,即使部分非核心组件故障,核心业务流依然能够以某种可接受的形式(如返回默认值、使用本地缓存)继续运行,保障整体服务的可用性。
参考话术:
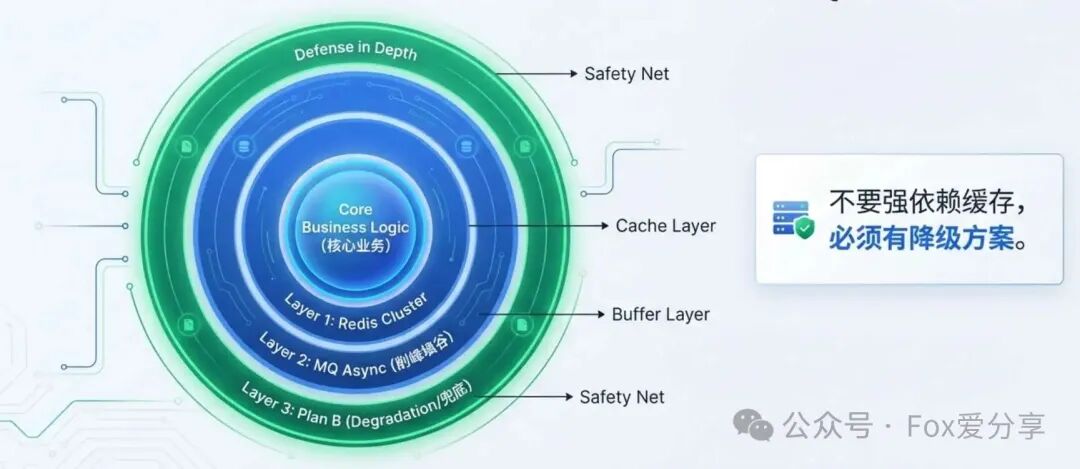
“尽管我们的Redis集群保证了高达99.99%的可用性,但我始终坚持一个原则:核心业务逻辑不能强依赖于任何外部中间件。为此,我设计并实现了一套多级降级方案。
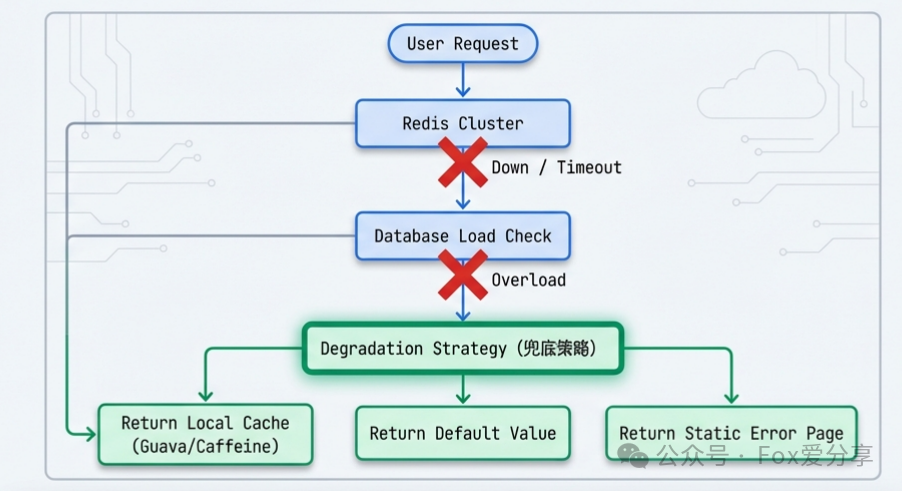
整个系统的保护策略分为三层:第一层是Redis集群缓存,应对常规峰值;第二层引入消息队列进行异步化处理,实现‘削峰填谷’;而第三层,也是最重要的,就是全面的降级兜底方案。我清晰地定义了降级触发条件(如Redis集群连接超时、数据库响应时间超过阈值),以及各级降级策略(如返回本地Guava/Caffeine缓存中的数据、返回预设的友好默认值、或返回静态化页面)。这样,即使缓存和数据库同时出现压力,系统也能‘有损’运行,而不是彻底崩溃,为运维人员争取宝贵的修复时间。”
总结:高价值项目表述公式
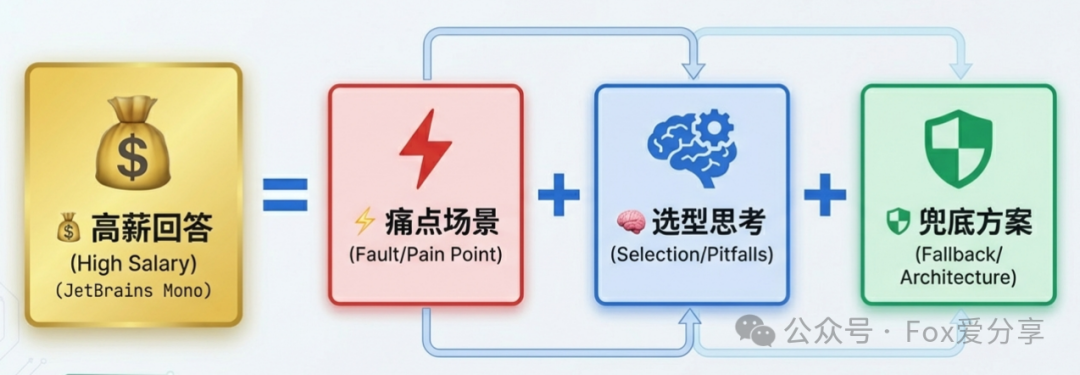
下次面试描述项目时,可以尝试套用以下公式来组织你的回答,这能有效引导你展示出全面的技术视野:
高价值回答 = 具体的痛点/故障场景 + 深入的技术选型与对比思考 + 完备的降级与兜底架构
所谓的“包装”,绝非鼓励编造未曾涉足的技术。其本质是倡导开发者以更深入、更系统化的视角去审视自己做过的每一项工作。即使是看似重复的CRUD,其中也必然涉及数据库索引优化、事务控制、并发处理、JVM参数调优等可深挖的点。
关键在于转换思维,从“我实现了什么功能”转变为“我解决了什么问题、规避了什么风险、保障了系统何种特性”。通过这种方式,你不仅能更好地在面试中展现自己,也能在实际工作中培养出更严谨的工程素养。希望这些思路能帮助你在技术社区如云栈社区的交流中,以及未来的职业生涯里,更清晰地表达自己的技术价值。
 发表于 2026-1-17 14:34:58
|
查看: 285|
回复: 0
发表于 2026-1-17 14:34:58
|
查看: 285|
回复: 0
