昨晚凌晨2点,一个焦急的电话把我惊醒。电话那头是阿强,他的声音有些颤抖:“线上那个每天凌晨1点跑的‘每日财务报表’任务,今天居然没执行!老板早上等着看数据,我查遍了后台日志,没有任何报错,没有任何异常,就像这个任务凭空消失了一样!”
我问他:“你是不是在同一个项目里写了多个 @Scheduled 任务?”
阿强回答:“对啊,除了财务报表,还有一个每分钟执行的心跳检测,以及一个每小时同步一次的第三方数据任务。”
我接着问:“那你为这些定时任务配置过自定义线程池吗?”
阿强懵了:“啊?@Scheduled 不是 Spring Boot 自带的吗?还需要配线程池?它不应该是多线程自动执行的吗?”
如果面试官听到这个回答,估计简历已经进了碎纸机。Spring 的 @Scheduled 注解,默认使用的是单线程调度器! 这正是导致阿强线上任务“神秘消失”的罪魁祸首。下面,我们来逐一拆解 Spring 定时任务在生产环境中常见的三个“隐形杀手”。
💣 地雷一:默认单线程 = 全线堵车
这是超过90%的开发者初次使用 @Scheduled 时会踩中的大坑。
【事故现场还原】
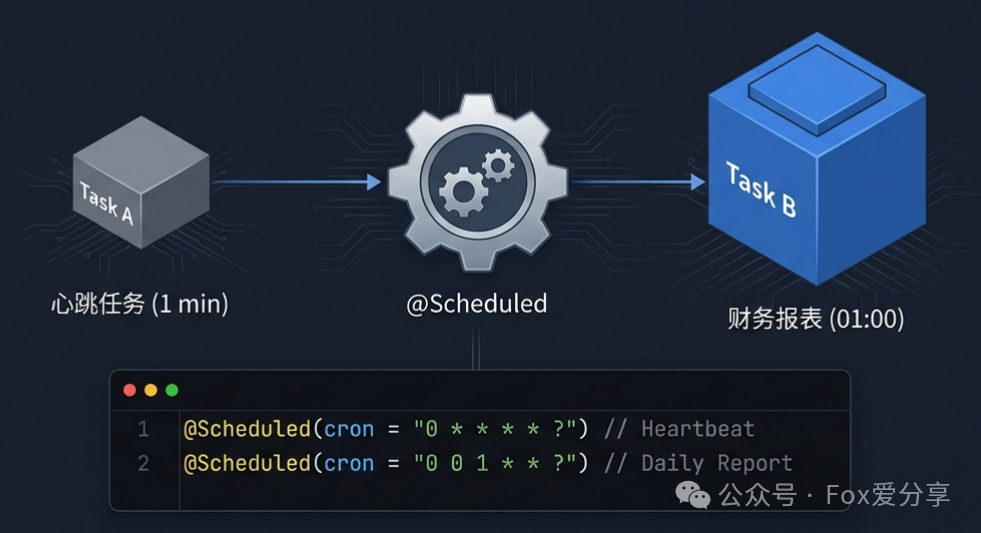
阿强的代码大致如下:
@Component
public class MyTasks {
// 任务A:每分钟执行一次,模拟一个耗时操作(例如卡住了)
@Scheduled(cron = "0 * * * * ?")
public void heartbeat() {
// 假设此处调用第三方接口超时,卡住了10分钟
Thread.sleep(600000);
}
// 任务B:每天凌晨1点执行(关键业务)
@Scheduled(cron = "0 0 1 * * ?")
public void dailyReport() {
log.info("开始生成报表..."); // 如果心跳任务卡住,这里的日志永远不会出现
}
}
【问题本质分析】
Spring Boot 默认使用的 ThreadPoolTaskScheduler,其核心线程池大小(poolSize)是 1。这意味着,整个应用内所有由 @Scheduled 标注的任务,都在同一条线程车道上排队执行。
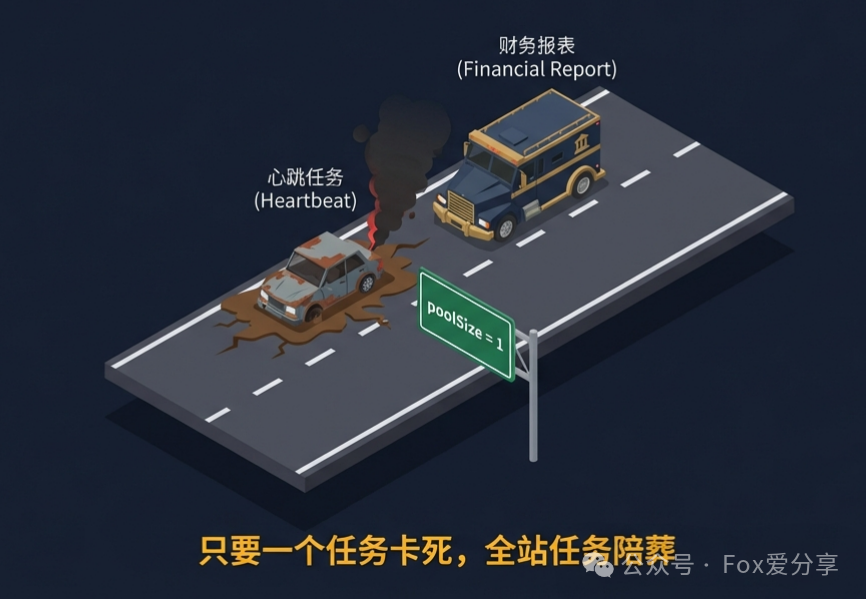
场景推演:
- 01:00:00,
dailyReport 任务本应准时执行。
- 然而,此时
heartbeat 任务正在执行,并且因为某种原因(如网络超时)被卡住了。
- 由于只有一个工作线程,
dailyReport 任务只能干等着,无法被调度。
- 等到
heartbeat 任务终于执行完毕,可能早已过了报表任务的执行窗口,导致任务严重延迟或彻底错过。
结论: 在默认配置下,只要有一个定时任务发生阻塞,全站的所有定时任务都会受到牵连,甚至“停摆”。
✅ 解决方案:配置自定义线程池
必须实现 SchedulingConfigurer 接口,为任务调度器配备“多条车道”。
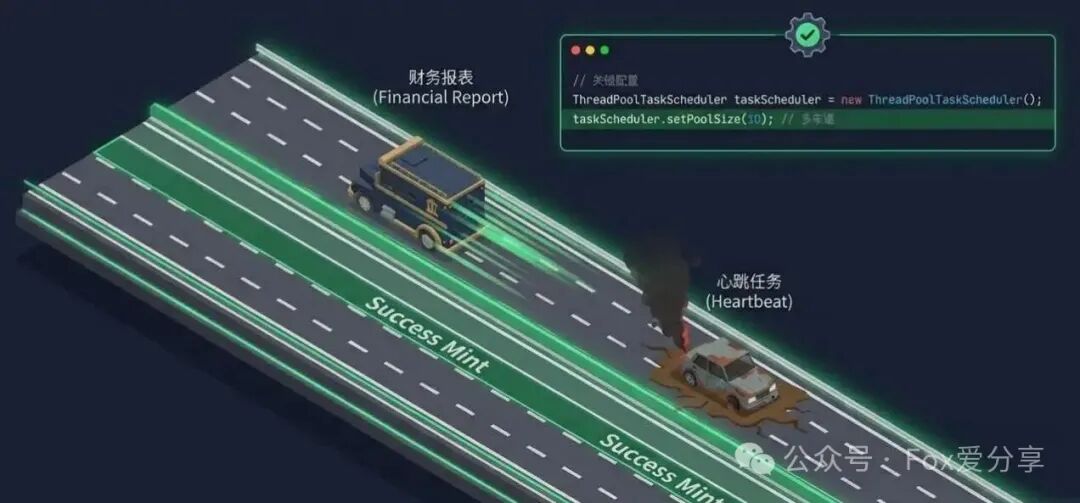
@Configuration
public class ScheduledConfig implements SchedulingConfigurer {
@Override
public void configureTasks(ScheduledTaskRegistrar taskRegistrar) {
ThreadPoolTaskScheduler taskScheduler = new ThreadPoolTaskScheduler();
// 核心线程数:根据任务数量和耗时合理设置,例如 CPU核数 * 2
taskScheduler.setPoolSize(10);
taskScheduler.setThreadNamePrefix("my-scheduled-task-");
// 关键:设置优雅停机,等待任务完成
taskScheduler.setWaitForTasksToCompleteOnShutdown(true);
taskScheduler.initialize();
taskRegistrar.setTaskScheduler(taskScheduler);
}
}
注意: 不要仅仅依赖在 application.properties 中配置 spring.task.scheduling.pool.size,特别是在一些较低版本的 Spring Boot 中可能不生效。通过代码配置是更稳妥的方式,这涉及到对 JVM 线程模型的深入理解,是后端架构设计的一部分。
💣 地雷二:集群部署 = 灾难性重复执行
如果你成功解决了第一个问题,恭喜,你的定时任务在单机环境下将运行良好。然而,当你将应用部署到生产环境(假设采用3台服务器做负载均衡集群)时,新的灾难接踵而至。
【事故现场还原】
老板质问:“阿强,为什么我今天早上收到了3封一模一样的促销邮件?用户的奖励积分也发放了3次?”
阿强一脸困惑:“我代码里明明只写了一次发送逻辑啊!”

【问题本质分析】
@Scheduled 是应用层面的调度机制。当你部署了3个独立的服务实例(Instance A, B, C),就会有3个独立的 JVM 进程。到了预设的时间点,实例A会执行任务,实例B会执行任务,实例C同样也会执行任务。
如果这个任务是“发放唯一优惠券”、“执行银行扣款”这类非幂等性操作,那么重复执行将直接导致 P0级生产事故。
✅ 解决方案:引入分布式锁(如 ShedLock)
如果不想引入重量级的任务调度中间件,可以选用轻量级的 ShedLock。它通过数据库表或 Redis 等存储,确保在分布式环境下,同一时间只有一个节点能够成功获取锁并执行任务。

// 在定时任务方法上增加 @SchedulerLock 注解
@Scheduled(cron = "...")
@SchedulerLock(name = "dailyReport", lockAtMostFor = "10m", lockAtLeastFor = "1m")
public void dailyReport() {
// 只有成功抢到分布式锁的节点才会执行此段逻辑
}
其中两个参数至关重要:
lockAtLeastFor:锁的最短持有时间。用于防止“抖动”——节点A刚执行完任务并释放锁,节点B因为极小时的时间差又立即抢到锁并重复执行。lockAtMostFor:这是核心的兜底机制! 假设抢到锁的节点A在执行任务时突然宕机(如断电、OOM),这把锁将在设定的时间(例如10分钟)后自动释放。如果没有这个机制,锁将被已死亡的节点永久占用,导致该任务在整个集群中“死锁”,永远无法再次执行。

💣 地雷三:异常吞没 = 静默的杀手
你是否遇到过这种情况:定时任务看似在正常运行,没有中断,但其内部的业务逻辑早已出错,直到业务方反馈甚至老板过问,你才后知后觉?
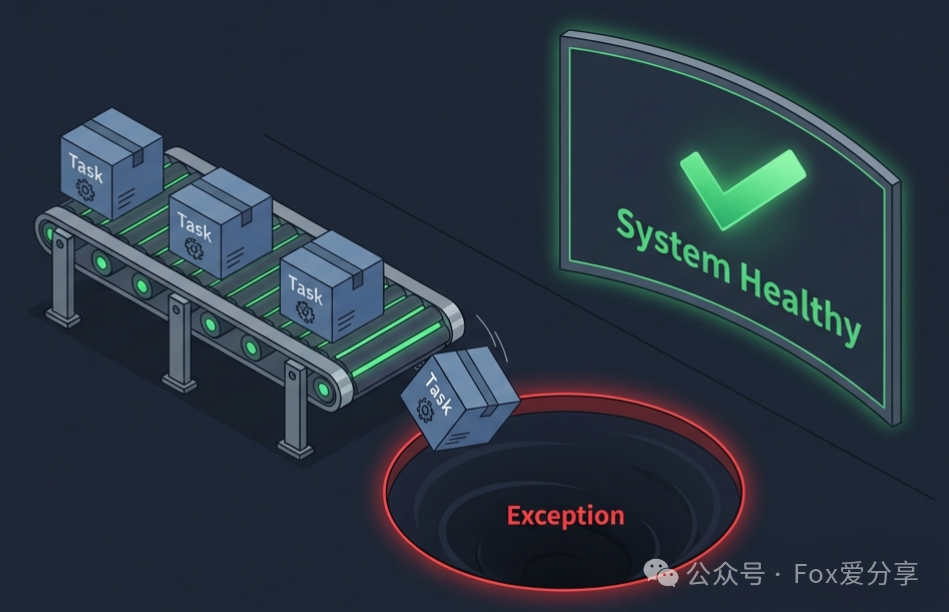
【事故现场还原】
@Scheduled(fixedRate = 5000)
public void syncData() {
// 假设此处抛出了一个RuntimeException(例如空指针、数据库连接失败)
throw new RuntimeException("数据库连接异常");
}
【问题本质分析】
Spring 的默认机制确实会记录错误日志,但在生产环境海量的 INFO 日志中,这几行报错信息瞬间就会被淹没。更可怕的隐患在于:
- 日志被淹没:运维和开发人员如果不主动、精准地搜索错误日志,根本无法感知到任务已经失败。
- 线程级故障:如果任务抛出的是
OutOfMemoryError 或某些致命 Error,执行线程可能会直接终止,导致后续调度彻底失效。
你以为任务在奔跑,实际上它可能早已“猝死”,或在持续“报错裸奔”,而整个系统却没有任何报警。
✅ 解决方案:AOP统一异常拦截与监控
任何核心的定时任务,都必须在最外层进行 try-catch 捕获,或者使用 AOP 切面进行统一的异常监控和告警。
@Aspect
@Component
@Slf4j
public class ScheduledExceptionAspect {
// 拦截所有被 @Scheduled 注解的方法
@AfterThrowing(pointcut = "@annotation(org.springframework.scheduling.annotation.Scheduled)", throwing = "e")
public void handleException(JoinPoint joinPoint, Throwable e) {
// 1. 记录详细的错误堆栈信息
log.error("【严重告警】定时任务执行异常: method={}", joinPoint.getSignature().getName(), e);
// 2. 发送即时告警(接入钉钉、企业微信、短信或邮件)
AlertUtils.send("生产环境定时任务失败!任务方法:" + joinPoint.getSignature().getName() + ",请立即检查!");
}
}
💡 架构视角总结(面试要点)
当下次面试官提问:“在使用 Spring 定时任务时,需要注意哪些坑?” 你可以直接给出这套系统性的解答:
“Spring 的 @Scheduled 注解非常适合单机环境下的轻量级任务调度。但在生产级、分布式架构中,必须遵循三条核心原则:
第一,拒绝默认单线程池:默认的单线程模型极易因一个任务阻塞导致级联故障。必须通过实现 SchedulingConfigurer 接口来配置自定义线程池,隔离任务资源。
第二,集群环境必须防重:在微服务多实例部署下,@Scheduled 会在每个实例上触发,必须引入基于数据库或Redis的分布式锁(如ShedLock)来保证幂等性。特别要重视 lockAtMostFor 参数的配置,这是防止节点宕机后产生死锁的关键兜底。
第三,建立异常兜底与监控:定时任务作为后台线程,其异常容易被忽略,不能依赖人工查看日志来发现问题。必须通过AOP全局拦截或包裹 try-catch,将异常信息对接至监控告警平台(如Prometheus、Grafana或内部IM工具),实现故障的即时感知,杜绝‘静默失败’。”
定时任务犹如系统的脉搏,平稳运行时无人察觉,一旦停跳,整个业务便面临危机。不要为了节省几行配置代码,而给系统埋下深夜加班排查的隐患。
希望这篇深入的问题剖析与解决方案能对你有所启发。如果你想持续获取此类系统性的技术干货,欢迎关注 云栈社区 的更多讨论。
 发表于 2026-1-17 14:40:09
|
查看: 244|
回复: 0
发表于 2026-1-17 14:40:09
|
查看: 244|
回复: 0
