继上一篇文章探讨了Calcite的关系代数基础后,本文将聚焦于Algebra builder部分,即如何使用RelBuilder API手动构建关系代数表达式。通过完整的代码示例,我们将从最简单的TableScan开始,逐步实现Project、Filter、Aggregate乃至复杂的Join操作,并深入理解其背后的执行原理与栈机制。
Algebra builder 概述
Apache Calcite 的关系代数既支持通过SQL语句间接构造,也支持使用 RelBuilder 直接编程构建。在通常的SQL查询中,我们可能不关心SQL是如何转换为关系代数的,但会通过 EXPLAIN 来查看执行计划以了解性能。而在实际开发中,直接使用 Calcite RelBuilder 构建查询,能让我们更贴近 关系代数表达式(relational-algebra expression)、优化器(optimizer) 和执行计划(execution plan) 的核心流程,从而对SQL引擎的工作原理有更深刻的理解。
官方文档的示例代码可以在 RelBuilderExample 单元测试中找到。为了便于理解,下文会将关键示例拆解为独立的、可运行的代码块。
TableScan:从扫描开始
RelBuilder 是构建关系表达式最直接的工具。下面这个示例 YzhouCsvTest_withoutjson_withrelbuilder_tablescan 展示了如何扫描一个CSV文件。RelBuilder 的 scan("scott", "emp") 方法会扫描 javamain-calcite/src/main/resources/scott 目录下的 emp.csv 文件,其语义等同于SQL SELECT * FROM scott.emp。最后通过 build() 方法生成一个 RelNode 对象,并使用 RelOptUtil.toString(rel) 将其打印出来。
关键思考:RelNode 是什么?
通过 RelOptUtil.toString() 方法的注释(“Converts a relational expression to a string”)以及 RelBuilder 类的描述(“Builder for relational expressions”)可以明确,RelNode 对象代表的就是一个关系代数表达式。在Calcite的语境中,我们应优先使用“关系代数表达式”而非容易引起混淆的“逻辑计划”这一术语。
流程对照:
无论是《Calcite数据管理实战》中提到的“逻辑计划优化”步骤,还是《Database System Concepts》中阐述的 Query Processing 流程,其核心都是将查询转换为内部的关系代数表达式进行优化和执行。因此,理解 RelBuilder 生成的表达式树至关重要。
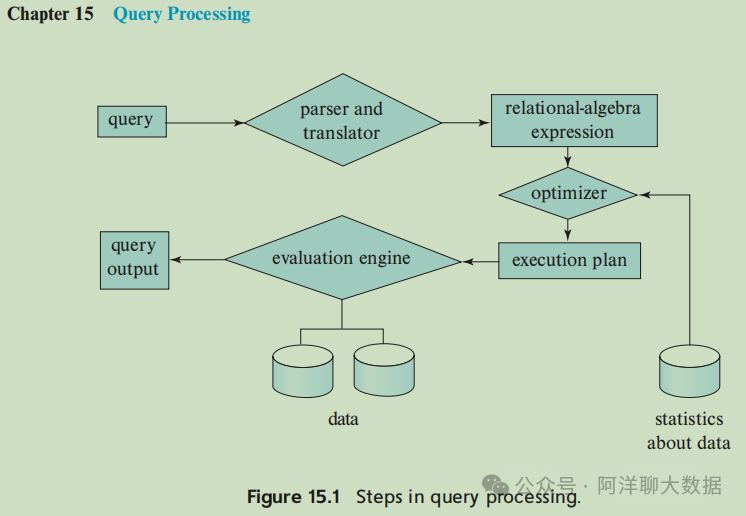
测试数据准备:
在 javamain-calcite/src/main/resources/scott 目录下放置 dept.csv 和 emp.csv 文件。
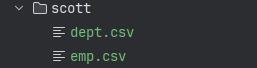
dept.csv 内容:
DEPTNO,DNAME,LOC
10,ACCOUNTING,NEW YORK
20,RESEARCH,DALLAS
30,SALES,CHICAGO
40,OPERATIONS,BOSTON
emp.csv 内容:
EMPNO,ENAME,JOB,MGR,HIREDATE,SAL,COMM,DEPTNO
7369,SMITH,CLERK,7902,1980-12-17,800,,20
7499,ALLEN,SALESMAN,7698,1981-02-20,1600,300,30
7521,WARD,SALESMAN,7698,1981-02-22,1250,500,30
7566,JONES,MANAGER,7839,1981-04-02,2975,,20
7654,MARTIN,SALESMAN,7698,1981-09-28,1250,1400,30
7698,BLAKE,MANAGER,7839,1981-05-01,2850,,30
7782,CLARK,MANAGER,7839,1981-06-09,2450,,10
7788,SCOTT,ANALYST,7566,1982-12-09,3000,,20
7839,KING,PRESIDENT,,1981-11-17,5000,,10
7844,TURNER,SALESMAN,7698,1981-09-08,1500,0,30
7876,ADAMS,CLERK,7788,1983-01-12,1100,,20
7900,JAMES,CLERK,7698,1981-12-03,950,,30
7902,FORD,ANALYST,7566,1981-12-03,3000,,20
7934,MILLER,CLERK,7782,1982-01-23,1300,,10
示例代码:YzhouCsvTest_withoutjson_withrelbuilder_tablescan.java
public class YzhouCsvTest_withoutjson_withrelbuilder_tablescan {
public static void main(String[] args) throws SQLException {
Properties props = new Properties();
props.setProperty("caseSensitive", "false");
props.setProperty("lex", Lex.JAVA.toString());
try (Connection connection = DriverManager.getConnection("jdbc:calcite:", props);
CalciteConnection calciteConnection = connection.unwrap(CalciteConnection.class)) {
SchemaPlus rootSchema = calciteConnection.getRootSchema();
File csvDir = new File("javamain-calcite\\src\\main\\resources\\scott");
CsvSchema csvSchema = new CsvSchema(csvDir, CsvTable.Flavor.SCANNABLE);
SchemaPlus scottSchema = rootSchema.add("scott", new AbstractSchema());
scottSchema.add("dept", csvSchema.getTable("dept"));
scottSchema.add("emp", csvSchema.getTable("emp"));
FrameworkConfig config = Frameworks.newConfigBuilder()
.parserConfig(
SqlParser.config()
.withLex(Lex.JAVA)
.withCaseSensitive(false)
)
.defaultSchema(rootSchema)
.build();
RelBuilder builder = RelBuilder.create(config);
final RelNode rel = builder
.scan("scott", "emp")
.build();
System.out.println(RelOptUtil.toString(rel));
RelRunner runner = connection.unwrap(RelRunner.class);
try (PreparedStatement preparedStatement = runner.prepareStatement(rel);
ResultSet resultSet = preparedStatement.executeQuery()) {
print(resultSet);
}
}
}
private static void print(ResultSet resultSet) throws SQLException {
final ResultSetMetaData metaData = resultSet.getMetaData();
final int columnCount = metaData.getColumnCount();
while (resultSet.next()) {
for (int i = 1; ; i++) {
System.out.print(resultSet.getString(i));
if (i < columnCount) {
System.out.print(", ");
} else {
System.out.println();
break;
}
}
}
}
}
输出结果:
LogicalTableScan(table=[[scott, emp]])
7369, SMITH, CLERK, 7902, 1980-12-17, 800, , 20
7499, ALLEN, SALESMAN, 7698, 1981-02-20, 1600, 300, 30
7521, WARD, SALESMAN, 7698, 1981-02-22, 1250, 500, 30
7566, JONES, MANAGER, 7839, 1981-04-02, 2975, , 20
7654, MARTIN, SALESMAN, 7698, 1981-09-28, 1250, 1400, 30
... 省略部分数据
转换为SQL:
我们还可以使用 RelToSqlConverter 将 RelNode 对象转换回SQL语句,这验证了关系表达式与SQL的等价性。
private static void relToSql(RelNode rel){
SqlDialect dialect = CalciteSqlDialect.DEFAULT;
RelToSqlConverter converter = new RelToSqlConverter(dialect);
SqlNode sqlNode = converter.visitRoot(rel).asStatement();
String generatedSql = sqlNode.toSqlString(dialect).getSql();
System.out.println("\n=== Generated SQL ===");
System.out.println(generatedSql);
}
小结
通过 TableScan 示例,我们体会到 RelBuilder 让我们能够直接操作关系代数表达式。请务必重视 RelOptUtil.toString() 输出的表达式树,读懂它们是深入理解Calcite的关键。
添加 Project(投影)操作
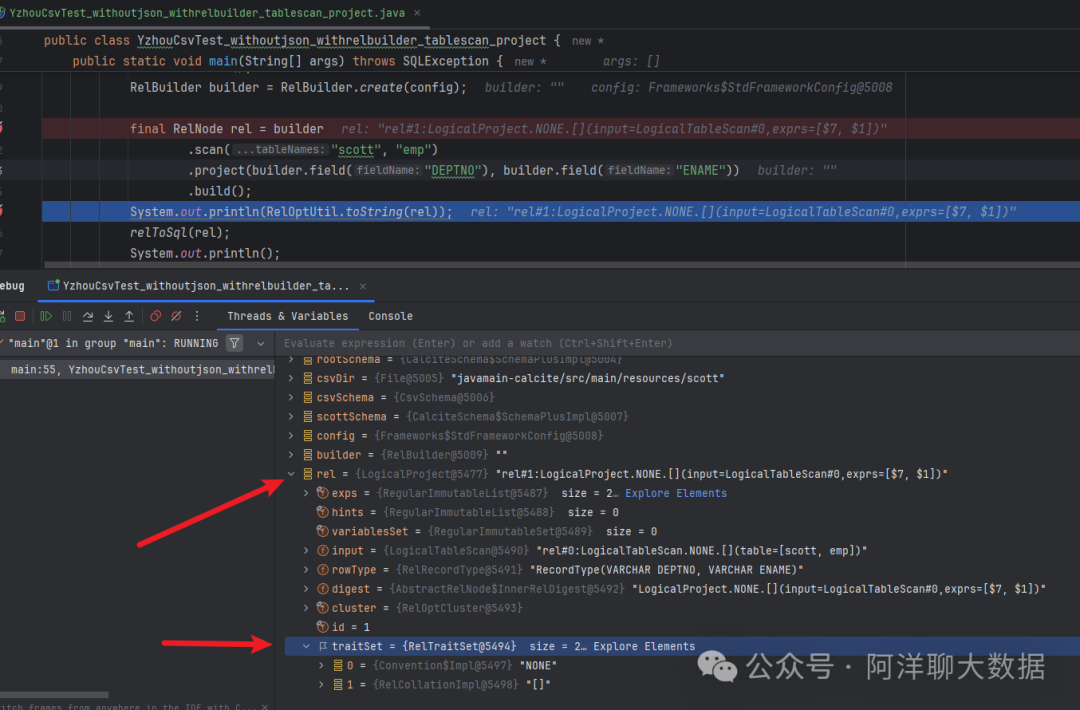
在关系代数中,Project 对应投影操作,用于选择特定的列。在示例 YzhouCsvTest_withoutjson_withrelbuilder_tablescan_project 中,我们在 scan 后调用了 project() 方法。
示例代码:YzhouCsvTest_withoutjson_withrelbuilder_tablescan_project.java
public class YzhouCsvTest_withoutjson_withrelbuilder_tablescan_project {
public static void main(String[] args) throws SQLException {
// ... 初始化连接和Schema的代码与上文相同,此处省略 ...
RelBuilder builder = RelBuilder.create(config);
final RelNode rel = builder
.scan("scott", "emp")
.project(builder.field("DEPTNO"), builder.field("ENAME"))
.build();
System.out.println(RelOptUtil.toString(rel));
relToSql(rel);
System.out.println();
// ... 执行查询和打印结果的代码与上文相同,此处省略 ...
}
// ... print 和 relToSql 方法定义与上文相同 ...
}
输出结果:
LogicalProject(DEPTNO=[$7], ENAME=[$1])
LogicalTableScan(table=[[scott, emp]])
=== Generated SQL ===
SELECT "DEPTNO", "ENAME"
FROM "scott"."emp"
20, SMITH
30, ALLEN
30, WARD
20, JONES
30, MARTIN
... 省略部分数据
关键点:
- 输出表达式
LogicalProject(DEPTNO=[$7], ENAME=[$1]) 呈现了树形结构,$7 和 $1 分别代表输入行中 DEPTNO 和 ENAME 字段的序号(从0开始)。
project() 方法的参数类型是 RexNode,这是Calcite中代表标量表达式的核心类。
添加 Filter 和 Aggregate(过滤与聚合)
现在,我们构建一个更复杂的查询:SELECT deptno, count(*) AS c, sum(sal) AS s FROM emp GROUP BY deptno HAVING count(*) > 2。需要注意的是,原始CSV中字段默认为字符串类型,为了进行 SUM 计算,我们需要在Schema定义中显式将 SAL 字段类型设置为 int。
示例代码:YzhouCsvTest_withoutjson_withrelbuilder_tablescan_project_filter_aggregate.java
public class YzhouCsvTest_withoutjson_withrelbuilder_tablescan_project_filter_aggregate {
public static void main(String[] args) throws SQLException {
// ... 初始化部分需指向包含字段类型定义的 scott_fieldtype 目录 ...
File csvDir = new File("javamain-calcite\\src\\main\\resources\\scott_fieldtype");
// ... 其余初始化代码与上文类似 ...
RelBuilder builder = RelBuilder.create(config);
final RelNode rel = builder
.scan("scott", "emp")
.aggregate(builder.groupKey("DEPTNO"),
builder.count(false, "C"),
builder.sum(false, "S", builder.field("SAL")))
.filter(
builder.call(SqlStdOperatorTable.GREATER_THAN,
builder.field("C"),
builder.literal(2)))
.build();
System.out.println(RelOptUtil.toString(rel));
relToSql(rel);
// ... 执行和打印代码 ...
}
}
输出结果:
LogicalFilter(condition=[>($1, 2)])
LogicalAggregate(group=[{7}], C=[COUNT()], S=[SUM($5)])
LogicalTableScan(table=[[scott, emp]])
=== Generated SQL ===
SELECT "DEPTNO", COUNT(*) AS "C", SUM("SAL") AS "S"
FROM "scott"."emp"
GROUP BY "DEPTNO"
HAVING COUNT(*) > 2
30, 6, 9400
20, 5, 10875
10, 3, 8750
理解 Push 和 Pop:构建器的栈机制
RelBuilder 内部使用一个栈来存储每一步生成的关系表达式,并将其作为输入传递给下一步。大多数时候,你只需要使用 build() 方法来获取栈顶的表达式(即树的根节点)。但当表达式嵌套过深时,可以使用 push() 和 pop() 来显式管理栈。
栈机制示例:
观察上面 filter() 方法的调用顺序:builder.call(SqlStdOperatorTable.GREATER_THAN, builder.field("C"), builder.literal(2))。参数顺序(操作符、左操作数、右操作数)类似于波兰表达式(前缀表达式)的求值逻辑。RelBuilder 正是利用栈来暂存中间表达式(如 COUNT() 的结果 C),然后将其作为 GREATER_THAN 操作的输入。
为了更直观地理解栈在表达式求值中的作用,可以对比 波兰表达式与逆波兰表达式 的算法。这类表达式无需括号即可无歧义地表示运算顺序,其求值过程天然依赖于栈结构。这正是 RelBuilder 所描述的“存储每一步生成的关系表达式,并将其作为输入传递给下一步”的核心思想。
Bushy Join 示例
以下示例演示了如何使用栈机制构建一个多表连接(bushy join)。我们先分别构建两个子连接,再将它们连接起来。
测试数据准备: 在 scott_join 目录下准备 consumers.csv, line_items.csv, orders.csv, products.csv 文件。
示例代码:YzhouCsvTest_withoutjson_withrelbuilder_tablescan_project_bushyjoin.java
public class YzhouCsvTest_withoutjson_withrelbuilder_tablescan_project_bushyjoin {
public static void main(String[] args) throws SQLException {
// ... 初始化连接和Schema,指向 scott_join 目录 ...
RelBuilder builder = RelBuilder.create(config);
// 构建左子树:consumers JOIN orders ON order_id
final RelNode left = builder
.scan("scott","consumers")
.scan("scott","orders")
.join(JoinRelType.INNER, "order_id")
.build();
// 构建右子树:line_items JOIN products ON product_id
final RelNode right = builder
.scan("scott","line_items")
.scan("scott","products")
.join(JoinRelType.INNER, "product_id")
.build();
// 将左右子树压入栈,并进行连接
final RelNode rel = builder
.push(left)
.push(right)
.join(JoinRelType.INNER, "order_id")
.build();
System.out.println(RelOptUtil.toString(rel));
relToSql(rel);
// ... 执行和打印代码 ...
}
}
输出结果:
LogicalJoin(condition=[=($4, $9)], joinType=[inner])
LogicalJoin(condition=[=($4, $5)], joinType=[inner])
LogicalTableScan(table=[[scott, consumers]])
LogicalTableScan(table=[[scott, orders]])
LogicalJoin(condition=[=($2, $5)], joinType=[inner])
LogicalTableScan(table=[[scott, line_items]])
LogicalTableScan(table=[[scott, products]])
=== Generated SQL ===
SELECT *
FROM "scott"."consumers"
INNER JOIN "scott"."orders" ON "consumers"."order_id" = "orders"."order_id"
INNER JOIN ("scott"."line_items" INNER JOIN "scott"."products" ON "line_items"."product_id" = "products"."product_id") ON "consumers"."order_id" = "line_items"."order_id"
... (查询结果数据)
切换 Convention(执行约定)
Convention 是 RelNode 的物理特征之一,它描述了关系表达式将以何种方式执行。默认情况下,RelBuilder 创建的 RelNode 其 Convention 为 NONE,表示这是一个逻辑表达式,尚未绑定具体的执行引擎。
Calcite 内置了多种 Convention,例如:
ENUMERABLE: 在内存中迭代执行(生成Java代码)。JDBC: 下推到数据库执行。BINDABLE: 解释执行。
通过 adoptConvention() 方法,我们可以切换表达式树的执行约定。下面的示例将排序操作转换为 Enumerable 约定执行。
示例代码:YzhouCsvTest_withoutjson_withrelbuilder_tablescan_convention.java
public class YzhouCsvTest_withoutjson_withrelbuilder_tablescan_convention {
public static void main(String[] args) throws SQLException {
// ... 初始化代码 ...
RelBuilder builder = RelBuilder.create(config);
final RelNode rel = builder
.scan("scott", "emp")
.project(builder.field("ENAME"), builder.field("SAL"))
.adoptConvention(EnumerableConvention.INSTANCE)
.sort(builder.field("SAL"))
.build();
System.out.println(RelOptUtil.toString(rel));
relToSql(rel);
// ... 执行和打印代码 ...
}
}
输出结果:
EnumerableSort(sort0=[$1], dir0=[ASC])
LogicalProject(ENAME=[$1], SAL=[$5])
LogicalTableScan(table=[[scott, emp]])
=== Generated SQL ===
SELECT "ENAME", "SAL"
FROM "scott"."emp"
ORDER BY "SAL"
ADAMS, 1100
WARD, 1250
MARTIN, 1250
MILLER, 1300
TURNER, 1500
ALLEN, 1600
CLARK, 2450
BLAKE, 2850
JONES, 2975
SCOTT, 3000
FORD, 3000
KING, 5000
SMITH, 800
JAMES, 950
Convention 的重要性:
在Calcite的 VolcanoPlanner 优化器中,Convention 是进行代价优化和规则匹配的关键属性。优化器会根据 Convention 将等价的表达式分组,并选择代价最低的物理实现。理解 Convention 是深入Calcite优化器原理的基础。
字段名与序号引用
在构建关系表达式时,可以通过字段名或序号(从0开始)来引用字段。运算符保证其输出字段的顺序。字段名在表达式内部是唯一的,如果发生冲突,Calcite会自动重命名(例如 DEPTNO 和 DEPTNO_1)。
一些方法提供了对字段名的控制:
project() 允许使用 alias(expr, fieldName) 包装表达式来建议字段名。values(String[] fieldNames, Object... values) 直接接受字段名数组。
当构建涉及多个输入的关系表达式(如Join)时,需要指定输入来源。例如,关联 EMP(8个字段)和 DEPT(3个字段),内部会形成一个11个字段的组合行。左侧输入的字段偏移从0开始,右侧从8开始。引用方式如下:
builder.field(2, 0, "SAL"): 表示在两个输入中,第0个输入(左侧)的名为“SAL”的字段。builder.field(2, 1, 1): 表示在两个输入中,第1个输入(右侧)的第1个字段(即 DNAME)。
掌握按序号引用字段的能力,在表达式经过多次重写规则变换后尤为可靠。
总结
通过本文的实践,我们从 TableScan 到复杂 Join,逐步掌握了使用 Apache Calcite RelBuilder 构建关系代数表达式的方法。关键在于理解:
RelNode 即关系代数表达式,是查询优化与执行的基石。RelBuilder 的栈机制是其构建表达式树的核心。Convention 定义了表达式的物理执行方式,是连接逻辑与物理计划的桥梁。- 灵活运用字段名和序号引用,能构建出精确而强大的查询。
RelBuilder 不仅是一个API,更是一扇深入理解SQL引擎内部运作的窗口。希望这些示例能帮助你在实际项目中更自如地使用Calcite进行查询构建与优化。
想了解更多关于数据库原理、关系代数与算法的深度内容,欢迎访问 云栈社区 与更多开发者交流探讨。
 发表于 2026-1-18 01:55:30
|
查看: 325|
回复: 0
发表于 2026-1-18 01:55:30
|
查看: 325|
回复: 0
