引言: 为什么需要Workqueue?
想象一下你正在经营一家繁忙的餐厅。当顾客点单时,你有两种处理方式:一是让厨师立即停下手头工作来处理新订单(中断处理),二是把订单写在纸条上放在队列中,让厨师按顺序处理(工作队列)。显然,后者更合理,因为它不会打断厨师当前的工作。Linux内核中的workqueue正是基于类似的设计哲学。
它不仅仅是简单的队列,更是Linux内核异步任务处理机制的基石,深刻影响着系统的响应性、吞吐量和能效。想深入了解系统层面的并发设计,可以到我们的 后端 & 架构 板块探索更多知识。
一、Workqueue设计思想全景图
1.1 异步执行的必要性
在内核开发中,我们经常面临这样的困境:某些操作(如磁盘I/O、网络包处理)需要较长时间完成,但如果直接在中断上下文或某些关键路径中执行,会阻塞整个系统。workqueue的诞生就是为了解决这个矛盾。
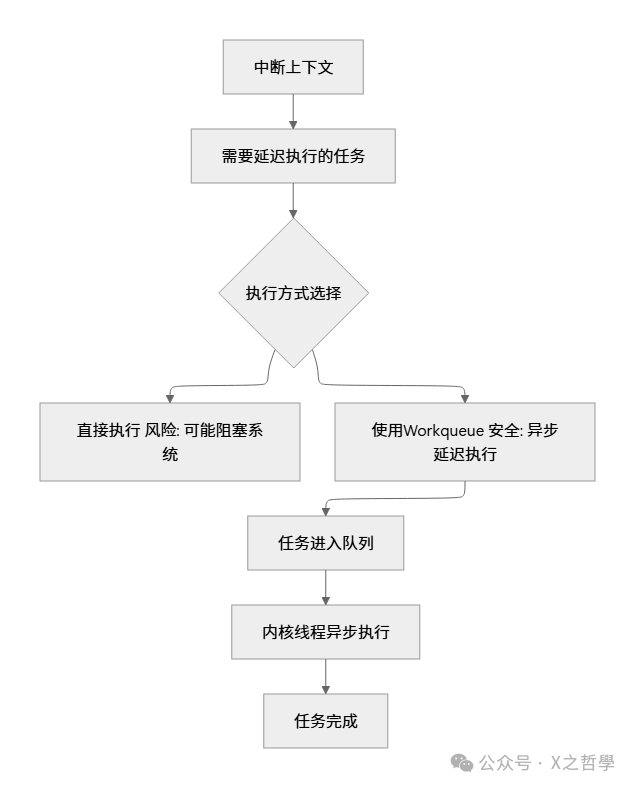
1.2 演进历程: 从原始队列到并发管理工作队列
让我们回顾一下workqueue的演进历程:
| 时期 |
实现方式 |
优点 |
缺点 |
| 2.6.20之前 |
单队列系统 |
简单易用 |
无法有效利用多核,易导致死锁 |
| 2.6.20-3.8 |
并发管理工作队列 (cmwq) |
自动负载均衡,更好的并发性 |
配置复杂,调试困难 |
| 3.9+ |
现代workqueue API |
更清晰的抽象,更好的性能控制 |
学习曲线较陡 |
二、核心概念深度解析
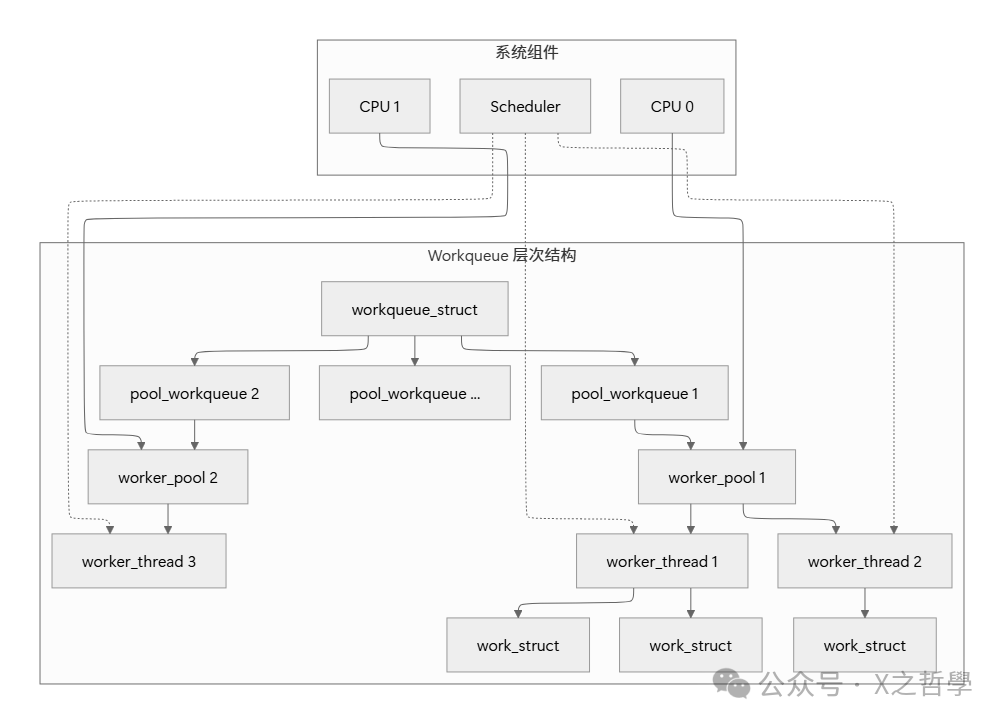
2.1 核心数据结构解剖
看看workqueue的内部构造。就像餐厅的后厨有不同区域一样,workqueue也有专门的工作者线程处理不同类型的任务。
/* 核心数据结构定义 */
struct work_struct {
atomic_long_t data; // 工作标志和指针
struct list_head entry; // 链表节点
work_func_t func; // 工作处理函数
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
struct workqueue_struct {
struct list_head pwqs; /* 所有pool_workqueue的列表 */
struct list_head list; /* 全局workqueue列表节点 */
struct pool_workqueue __percpu *cpu_pwqs; /* 每CPU pwq */
struct pool_workqueue __rcu *numa_pwqs[]; /* NUMA节点pwq */
const char *name; /* workqueue名称 */
unsigned int flags; /* WQ_* flags */
int nice; /* 工作者线程优先级 */
/* 并发管理相关 */
unsigned int max_active; /* 最大活跃工作数 */
int saved_max_active; /* 保存的最大活跃数 */
};
struct worker_pool {
spinlock_t lock; /* 保护池的锁 */
int cpu; /* 绑定的CPU,-1表示未绑定 */
int node; /* NUMA节点 */
int id; /* 池ID */
unsigned int flags; /* 池标志 */
struct list_head worklist; /* 待处理工作列表 */
int nr_workers; /* 工作者数量 */
/* 工作者管理 */
struct list_head idle_list; /* 空闲工作者列表 */
struct timer_list idle_timer; /* 空闲超时定时器 */
};
理解这些底层数据结构,是掌握C语言和 系统编程 的关键。
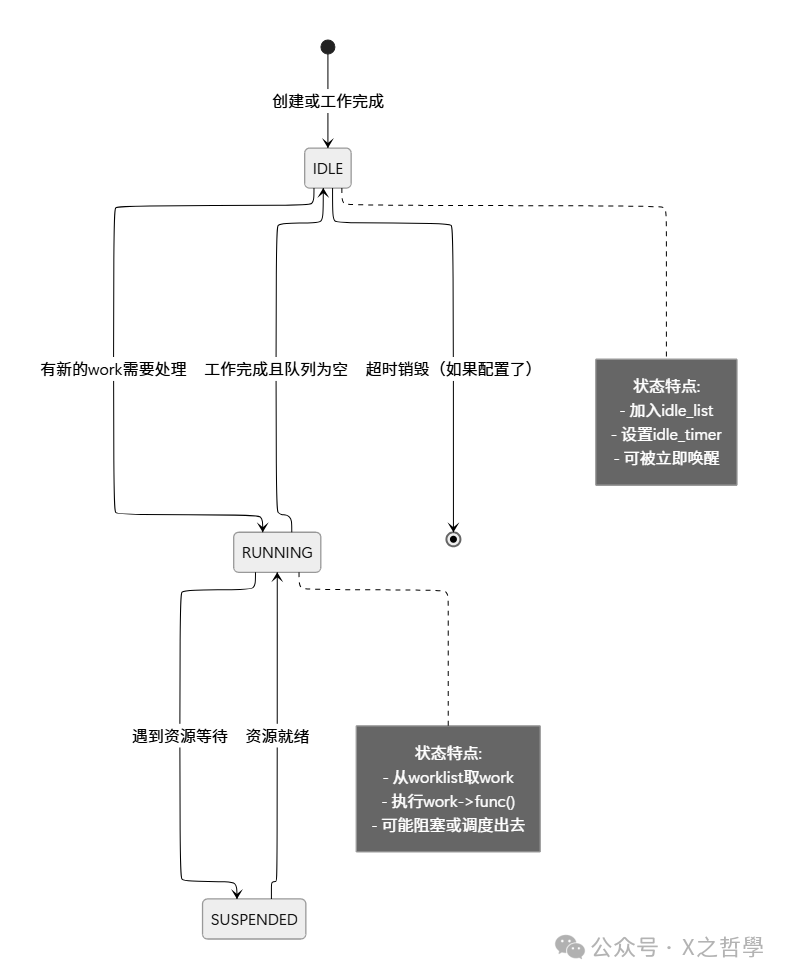
2.2 工作者线程(Worker Thread)的生命周期
工作者线程就像是厨房里的厨师,它们有明确的状态转换:
2.3 关键机制详解
2.3.1 负载均衡机制
想象一下餐厅里有多个厨师,有些忙得不可开交,有些却闲着。workqueue的负载均衡机制就像一个聪明的领班,会把订单从忙碌的厨师那里转移给空闲的厨师。
/* 简化的负载均衡逻辑 */
static void wq_watchdog_timer_fn(struct timer_list *unused)
{
struct worker_pool *pool;
/* 遍历所有worker池 */
for_each_worker_pool(pool, cpu) {
unsigned long nr_running = 0;
struct worker *worker;
/* 统计运行中的工作者 */
list_for_each_entry(worker, &pool->idle_list, entry)
nr_running++;
/* 如果负载不均衡,触发重新平衡 */
if (nr_running > pool->nr_workers / 2) {
wake_up_worker(pool);
}
}
}
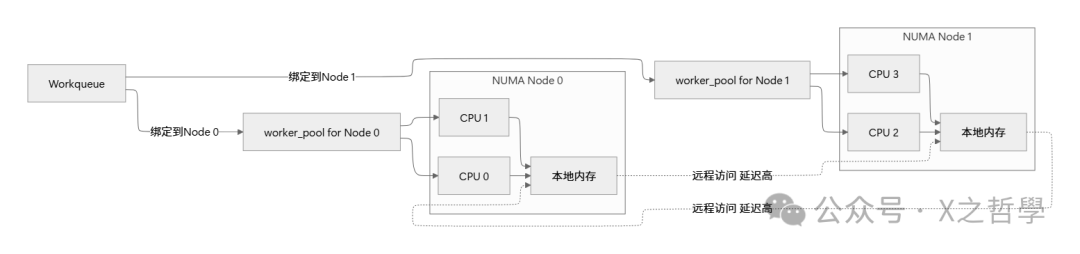
2.3.2 CPU亲和性与NUMA优化
在多核系统中,workqueue需要智能地处理CPU亲和性和NUMA内存访问。这就像是安排厨师工作时,要考虑他们离食材储藏室的距离。
三、Workqueue类型与使用模式
3.1 Workqueue分类对比
| 类型 |
创建方式 |
特点 |
适用场景 |
| 系统workqueue |
系统预创建 |
全局共享,无需自行创建 |
通用异步任务 |
| 专用workqueue |
alloc_workqueue() |
可定制属性,独立工作者线程 |
特殊需求任务 |
| 绑定型workqueue |
alloc_ordered_workqueue() |
严格顺序执行 |
需要顺序保证的任务 |
| 高优先级workqueue |
WQ_HIGHPRI标志 |
高优先级线程执行 |
实时性要求高的任务 |
3.2 使用模式示例
通过一个实际的网络驱动程序例子来说明如何正确使用workqueue:
#include <linux/workqueue.h>
#include <linux/slab.h>
/* 自定义数据结构,包含work_struct */
struct net_device_context {
struct net_device *dev;
struct work_struct tx_work;
struct work_struct rx_work;
struct sk_buff_head tx_queue;
struct sk_buff_head rx_queue;
struct workqueue_struct *wq;
};
/* 发送处理函数 */
static void process_tx_work(struct work_struct *work)
{
struct net_device_context *ctx =
container_of(work, struct net_device_context, tx_work);
struct sk_buff *skb;
/* 处理所有待发送的数据包 */
while ((skb = skb_dequeue(&ctx->tx_queue)) != NULL) {
if (netif_queue_stopped(ctx->dev))
netif_wake_queue(ctx->dev);
/* 实际的发送逻辑 */
if (ctx->dev->netdev_ops->ndo_start_xmit(skb, ctx->dev) != NETDEV_TX_OK) {
skb_queue_head(&ctx->tx_queue, skb);
schedule_delayed_work(&ctx->tx_work, msecs_to_jiffies(10));
break;
}
}
}
/* 接收处理函数 */
static void process_rx_work(struct work_struct *work)
{
struct net_device_context *ctx =
container_of(work, struct net_device_context, rx_work);
struct sk_buff *skb;
while ((skb = skb_dequeue(&ctx->rx_queue)) != NULL) {
/* 协议栈处理 */
netif_receive_skb(skb);
}
}
/* 初始化函数 */
static int netdev_init(struct net_device *dev)
{
struct net_device_context *ctx;
ctx = kzalloc(sizeof(*ctx), GFP_KERNEL);
if (!ctx)
return -ENOMEM;
ctx->dev = dev;
/* 创建专用的workqueue,名称带设备名便于调试 */
ctx->wq = alloc_workqueue("netdev-%s",
WQ_MEM_RECLAIM | WQ_HIGHPRI | WQ_CPU_INTENSIVE,
0, dev->name);
if (!ctx->wq) {
kfree(ctx);
return -ENOMEM;
}
/* 初始化work_struct */
INIT_WORK(&ctx->tx_work, process_tx_work);
INIT_WORK(&ctx->rx_work, process_rx_work);
/* 初始化skb队列 */
skb_queue_head_init(&ctx->tx_queue);
skb_queue_head_init(&ctx->rx_queue);
dev->priv = ctx;
return 0;
}
/* 数据包接收中断处理 */
irqreturn_t netdev_interrupt(int irq, void *dev_id)
{
struct net_device *dev = dev_id;
struct net_device_context *ctx = dev->priv;
struct sk_buff *skb;
/* 从硬件读取数据包 */
while ((skb = read_packet_from_hw(dev)) != NULL) {
/* 放入接收队列 */
skb_queue_tail(&ctx->rx_queue, skb);
}
/* 调度work处理接收队列,不阻塞中断上下文 */
queue_work(ctx->wq, &ctx->rx_work);
return IRQ_HANDLED;
}
这个例子展示了在 网络/系统 编程中如何优雅地处理异步IO。
四、并发管理工作队列(CMWQ)深度剖析
4.1 CMWQ架构总览
CMWQ是workqueue现代化的重要里程碑。用餐厅的比喻来解释:想象一个大型餐厅有多个厨房(worker pools),每个厨房有多个厨师(worker threads)。订单(work)可以根据类型送到不同的厨房,而厨房领班(CMWQ调度器)会动态调整厨师的数量和分配。
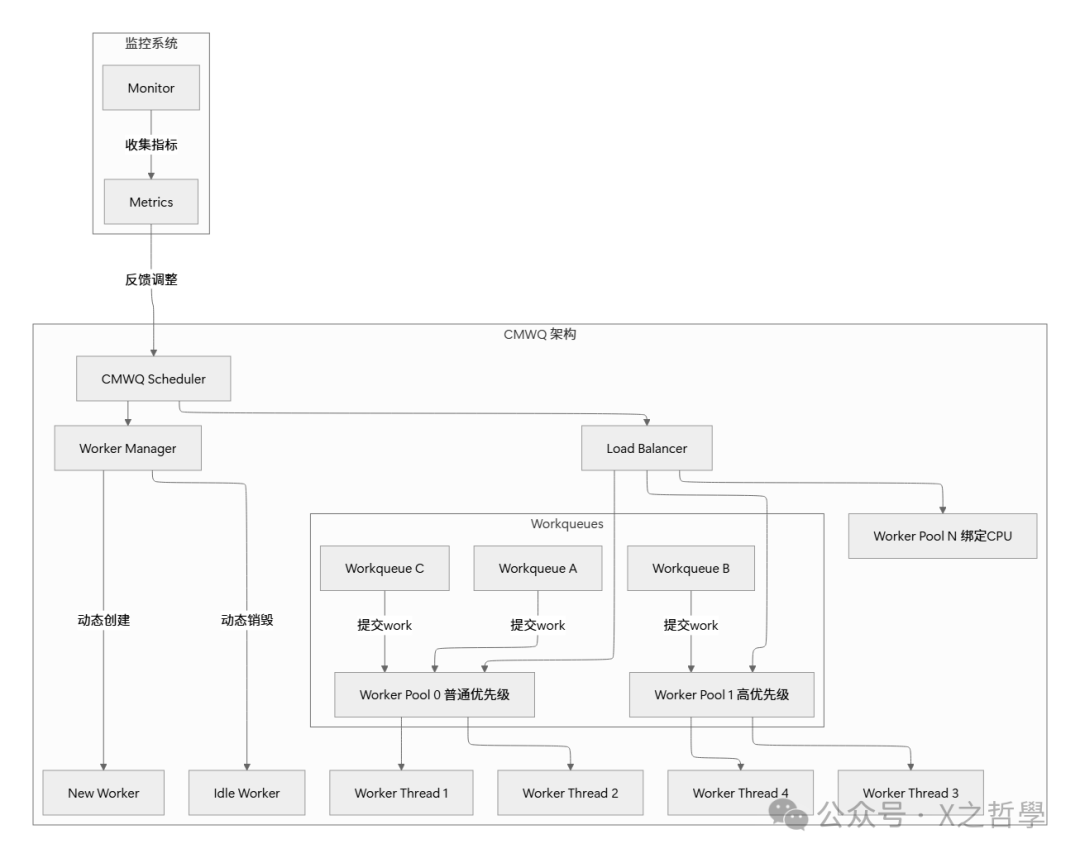
4.2 动态工作者管理算法
CMWQ最精妙的部分是它的动态工作者管理。详细解释这个算法:
/* 简化的动态工作者管理逻辑 */
static struct worker *create_worker(struct worker_pool *pool)
{
struct worker *worker;
worker = kzalloc(sizeof(*worker), GFP_KERNEL);
if (!worker)
return NULL;
/* 创建内核线程 */
worker->task = kthread_create_on_node(worker_thread, worker,
pool->node, "kworker/%s",
pool->name);
if (IS_ERR(worker->task)) {
kfree(worker);
return NULL;
}
/* 设置CPU亲和性 */
if (pool->cpu >= 0)
kthread_bind_mask(worker->task, cpumask_of(pool->cpu));
/* 加入池的管理列表 */
list_add_tail(&worker->entry, &pool->workers);
pool->nr_workers++;
/* 如果池中有待处理工作,立即唤醒工作者 */
if (!list_empty(&pool->worklist))
wake_up_process(worker->task);
return worker;
}
/* 工作者线程主函数 */
static int worker_thread(void *__worker)
{
struct worker *worker = __worker;
struct worker_pool *pool = worker->pool;
/* 设置线程属性 */
set_user_nice(current, pool->attrs->nice);
/* 主循环 */
while (!kthread_should_stop()) {
struct work_struct *work;
/* 尝试获取工作 */
work = get_first_work(pool);
if (!work) {
/* 没有工作,进入空闲状态 */
schedule();
continue;
}
/* 执行工作 */
pool->worker_working(worker);
work->func(work);
pool->worker_idle(worker);
/* 检查是否需要创建更多工作者 */
if (need_more_workers(pool))
wake_up_worker_manager(pool);
}
return 0;
}
4.3 负载均衡算法细节
CMWQ的负载均衡算法相当智能,它会考虑多个因素:
| 因素 |
权重 |
说明 |
| 队列长度 |
高 |
待处理work数量 |
| 工作者空闲率 |
中 |
空闲工作者比例 |
| CPU使用率 |
中 |
目标CPU的负载 |
| NUMA距离 |
低 |
内存访问延迟 |
| 缓存热度 |
低 |
缓存局部性 |
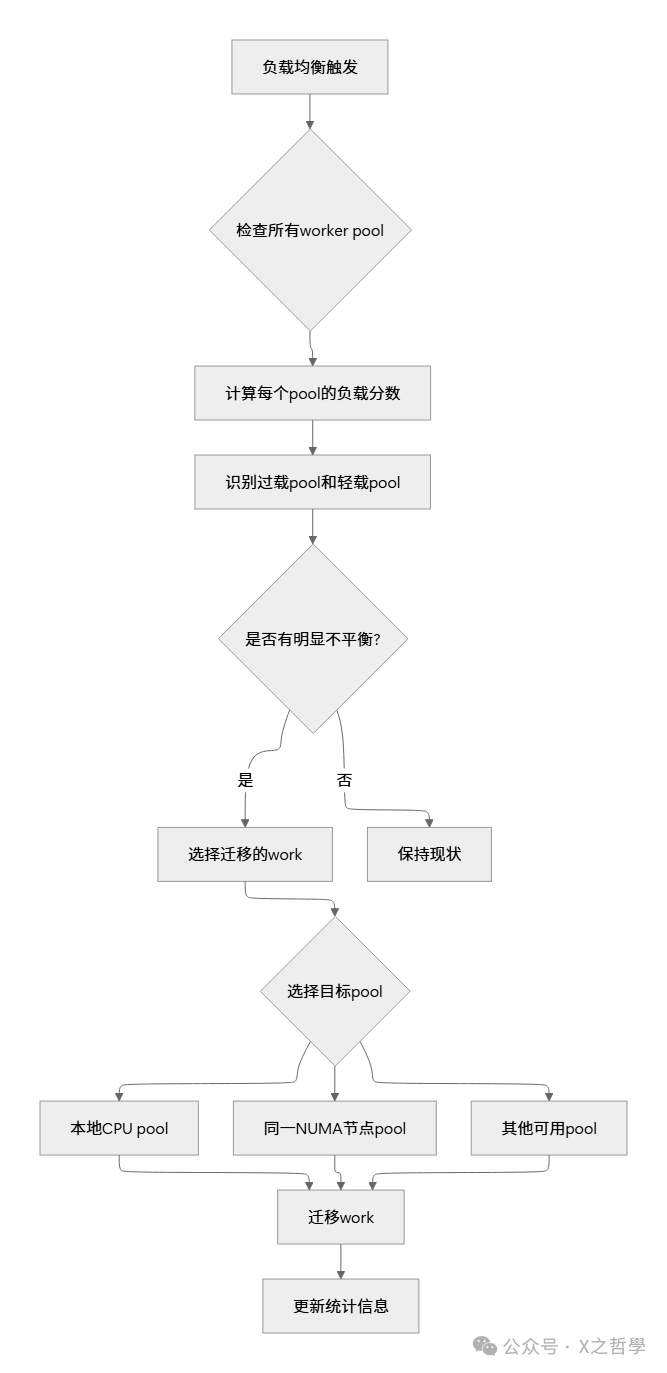
五、高级特性与最佳实践
5.1 延迟工作(Delayed Work)
有时候,我们不仅需要异步执行,还需要延迟执行。这就像是餐厅的预约服务。
/* 延迟work使用示例 */
struct delayed_work dwork;
/* 初始化延迟work */
INIT_DELAYED_WORK(&dwork, my_delayed_function);
/* 调度3秒后执行 */
schedule_delayed_work(&dwork, 3 * HZ);
/* 如果需要更精确的时间控制 */
schedule_delayed_work_on(cpu, &dwork, jiffies + msecs_to_jiffies(100));
/* 取消尚未执行的延迟work */
cancel_delayed_work_sync(&dwork);
5.2 Workqueue属性配置
正确配置workqueue属性对性能至关重要:
/* workqueue属性配置示例 */
struct workqueue_attrs attrs;
/* 初始化属性 */
init_workqueue_attrs(&attrs);
/* 设置属性 */
attrs.nice = -5; /* 较高优先级 */
attrs.cpumask = cpu_online_mask; /* 所有在线CPU */
attrs.no_numa = false; /* 启用NUMA感知 */
/* 应用属性到workqueue */
apply_workqueue_attrs(wq, &attrs);
| 属性 |
推荐值 |
说明 |
| nice值 |
-20到19 |
负值优先级更高 |
| cpumask |
根据负载调整 |
控制哪些CPU可执行 |
| max_active |
1到512 |
控制并发度 |
| flags |
WQ_MEM_RECLAIM等 |
特殊行为控制 |
5.3 内存回收安全(WQ_MEM_RECLAIM)
在内存压力大的情况下,workqueue需要特别小心。WQ_MEM_RECLAIM标志确保即使在内存回收时,关键工作也能继续执行。

六、调试与性能分析
6.1 常用调试工具
# 查看系统中所有workqueue的状态
$ cat /sys/kernel/debug/workqueues
# 输出示例:
# name max_active idle/busy total mayday rescuer
# events 0 0/0 0 0 0
# events_highpri 0 0/0 0 0 0
# events_long 0 0/0 0 0 0
# events_unbound 256 0/9 9 0 0
# 使用ftrace跟踪workqueue事件
$ echo 1 > /sys/kernel/debug/tracing/events/workqueue/enable
$ cat /sys/kernel/debug/tracing/trace_pipe
# 使用perf分析workqueue性能
$ perf record -e workqueue:workqueue_execute_start -a sleep 10
$ perf report
6.2 常见问题诊断
| 问题现象 |
可能原因 |
诊断方法 |
解决方案 |
| 系统响应慢 |
workqueue占用过多CPU |
perf top查看热点 |
调整nice值,减少并发 |
| 内存泄漏 |
work结构体未正确释放 |
kmemleak检查 |
确保cancel_work_sync |
| 死锁 |
工作函数中获取锁不当 |
lockdep检查 |
避免在work中获取可能被其他上下文持有的锁 |
| 延迟过大 |
工作者线程优先级低 |
trace-cmd记录调度事件 |
使用WQ_HIGHPRI标志 |
6.3 性能优化建议
-
合理选择workqueue类型:
- 对延迟敏感的任务使用专用workqueue
- 对顺序有要求的任务使用ordered workqueue
- 通用任务使用系统workqueue
-
优化工作函数:
/* 不好的实践 */
static void bad_work_func(struct work_struct *work)
{
/* 长时间操作阻塞了其他work */
msleep(1000);
/* 持有锁时间过长 */
spin_lock(&long_lock);
/* 复杂计算 */
complex_calculation();
}
/* 好的实践 */
static void good_work_func(struct work_struct *work)
{
/* 将长时间操作分割 */
if (need_more_time()) {
schedule_delayed_work(&dwork, 0);
return;
}
/* 快速完成关键部分 */
quick_operation();
}
-
监控指标:
/proc/sys/kernel/workqueue 中的统计信息- 使用
wq_monitor.py 脚本监控workqueue状态
- 定期检查
dmesg 中的workqueue警告
七、实战案例: 实现一个简单的异步日志系统
通过一个完整的例子来巩固所学知识。我们将实现一个异步日志系统,避免日志写入阻塞主业务逻辑。
#include <linux/module.h>
#include <linux/workqueue.h>
#include <linux/slab.h>
#include <linux/printk.h>
#include <linux/string.h>
#define MAX_LOG_ENTRIES 1000
#define LOG_ENTRY_SIZE 256
struct log_entry {
char message[LOG_ENTRY_SIZE];
struct list_head list;
};
struct async_logger {
struct workqueue_struct *wq;
struct work_struct flush_work;
struct delayed_work periodic_flush;
spinlock_t lock;
struct list_head log_list;
int entry_count;
};
static struct async_logger *logger;
/* 初始化日志系统 */
int init_async_logger(void)
{
logger = kzalloc(sizeof(*logger), GFP_KERNEL);
if (!logger)
return -ENOMEM;
/* 创建专用的workqueue,启用内存回收和NUMA优化 */
logger->wq = alloc_workqueue("async_logger",
WQ_MEM_RECLAIM | WQ_UNBOUND | WQ_FREEZABLE,
0);
if (!logger->wq) {
kfree(logger);
return -ENOMEM;
}
/* 初始化工作 */
INIT_WORK(&logger->flush_work, flush_logs);
INIT_DELAYED_WORK(&logger->periodic_flush, periodic_flush_func);
/* 初始化链表和锁 */
INIT_LIST_HEAD(&logger->log_list);
spin_lock_init(&logger->lock);
logger->entry_count = 0;
/* 启动定期刷新 */
schedule_delayed_work(&logger->periodic_flush, 5 * HZ);
return 0;
}
/* 记录日志(非阻塞) */
void async_log(const char *fmt, ...)
{
struct log_entry *entry;
va_list args;
/* 分配日志条目 */
entry = kmalloc(sizeof(*entry), GFP_ATOMIC);
if (!entry)
return; /* 内存不足时静默失败 */
/* 格式化消息 */
va_start(args, fmt);
vsnprintf(entry->message, LOG_ENTRY_SIZE, fmt, args);
va_end(args);
/* 添加到链表 */
spin_lock(&logger->lock);
if (logger->entry_count >= MAX_LOG_ENTRIES) {
/* 队列满,丢弃最旧的条目 */
struct log_entry *old = list_first_entry(&logger->log_list,
struct log_entry, list);
list_del(&old->list);
kfree(old);
logger->entry_count--;
}
list_add_tail(&entry->list, &logger->log_list);
logger->entry_count++;
/* 如果积累了大量日志,立即触发刷新 */
if (logger->entry_count > 100) {
queue_work(logger->wq, &logger->flush_work);
}
spin_unlock(&logger->lock);
}
/* 刷新日志到磁盘 */
static void flush_logs(struct work_struct *work)
{
struct log_entry *entry, *tmp;
LIST_HEAD(local_list);
/* 将日志条目移动到本地列表,减少锁持有时间 */
spin_lock(&logger->lock);
list_splice_init(&logger->log_list, &local_list);
logger->entry_count = 0;
spin_unlock(&logger->lock);
/* 处理所有日志条目 */
list_for_each_entry_safe(entry, tmp, &local_list, list) {
/* 这里实际应该写入磁盘,示例中打印到内核日志 */
printk(KERN_INFO "LOG: %s\n", entry->message);
list_del(&entry->list);
kfree(entry);
}
}
/* 定期刷新,即使日志不多也确保写入 */
static void periodic_flush_func(struct work_struct *work)
{
/* 触发刷新 */
queue_work(logger->wq, &logger->flush_work);
/* 重新调度自己 */
schedule_delayed_work(&logger->periodic_flush, 5 * HZ);
}
/* 清理函数 */
void cleanup_async_logger(void)
{
/* 取消所有待处理的工作 */
cancel_work_sync(&logger->flush_work);
cancel_delayed_work_sync(&logger->periodic_flush);
/* 刷新剩余日志 */
flush_logs(&logger->flush_work);
/* 销毁workqueue */
destroy_workqueue(logger->wq);
/* 释放内存 */
kfree(logger);
}
这个例子展示了workqueue的最佳实践:
- 使用专用workqueue避免影响系统其他部分
- 合理使用锁保护共享数据
- 实现批量处理提高效率
- 添加定期处理确保数据不会永远积压
八、未来展望
8.1 实时性增强
/* 未来可能引入的API */
/* 设置work的截止时间 */
int work_set_deadline(struct work_struct *work, ktime_t deadline);
/* 优先级继承机制 */
void work_inherit_priority(struct work_struct *work, int priority);
8.2 更智能的调度
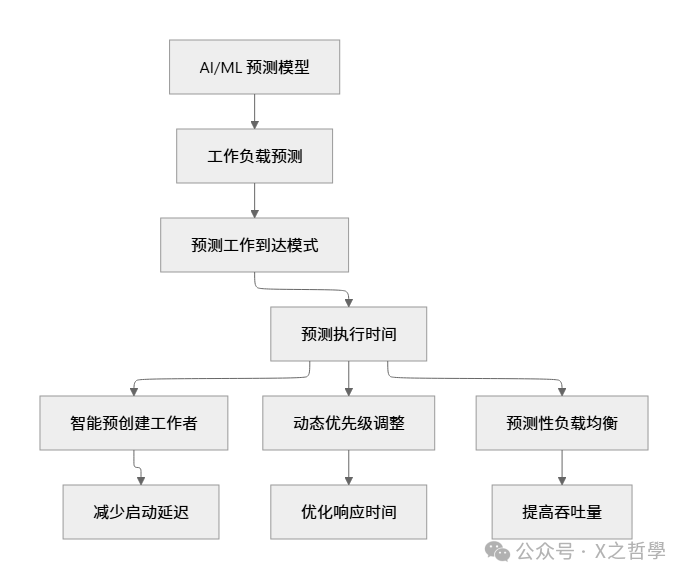
8.3 容器化支持增强
随着容器技术的普及,workqueue需要更好地支持cgroups和namespace:
- 每个cgroup可以有独立的worker pool
- 支持cgroup级别的资源限制
- 更好的容器间隔离
总结
通过本文的深入探讨,我们全面理解了Linux workqueue的工作原理、设计思想和最佳实践。最后用一张总览图来总结workqueue的核心概念:
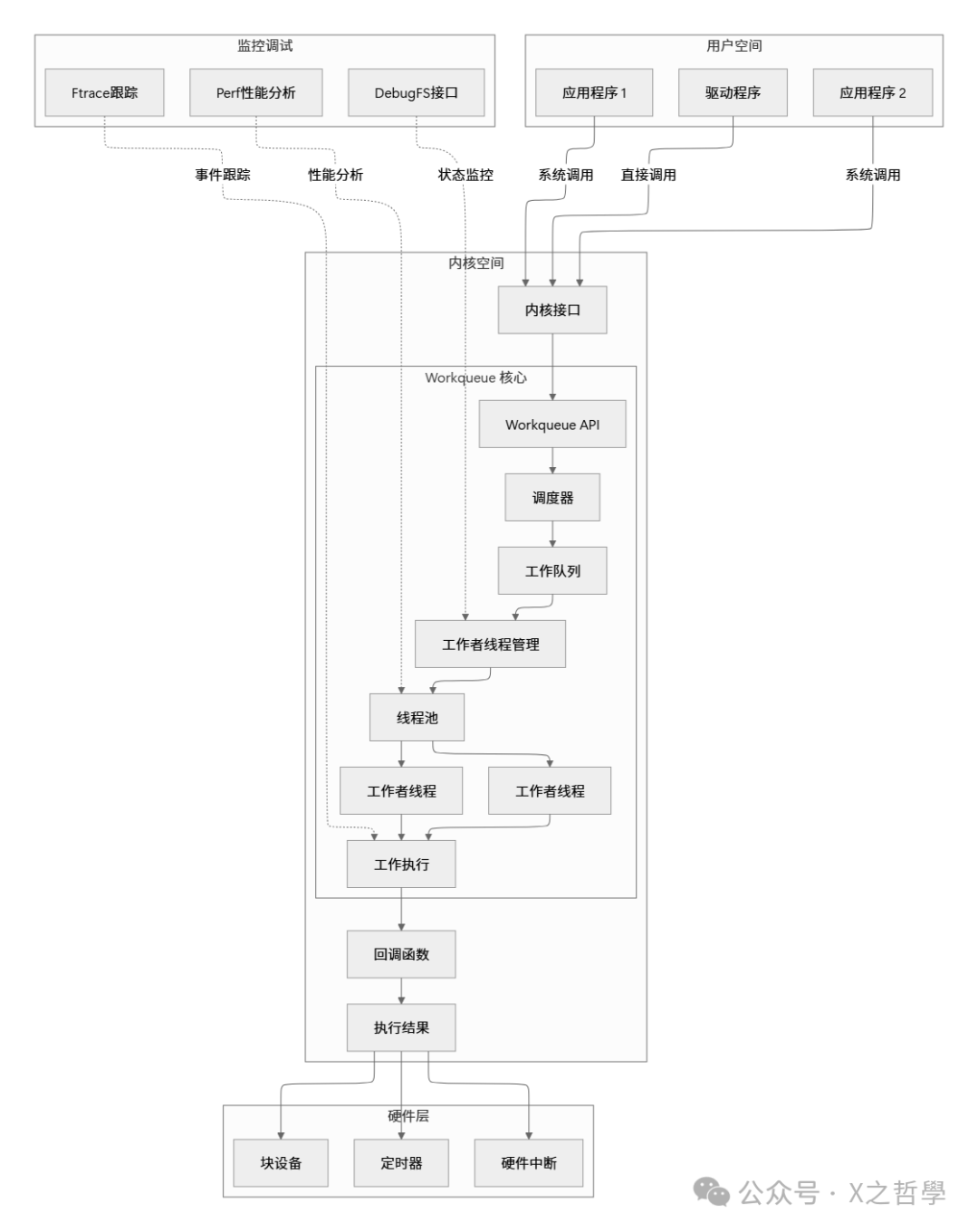
核心要点回顾:
- 设计哲学: Workqueue将紧急的中断处理转换为可管理的异步任务,提高系统整体稳定性和响应性
- 核心机制:
- 工作者线程池动态管理
- 智能负载均衡
- NUMA感知的调度
- 内存回收安全机制
- 最佳实践:
- 为不同类型任务选择合适的workqueue类型
- 合理设置并发度和优先级
- 避免在工作函数中长时间阻塞
- 正确管理work的生命周期
- 调试技巧:
- 利用debugfs和tracepoint
- 监控worker pool状态
- 分析工作执行延迟
workqueue作为Linux内核的核心基础设施,其设计体现了Linux哲学的精髓:简单、灵活、高效。理解和掌握workqueue,不仅能写出更好的内核代码,也能深入理解操作系统异步任务处理的精髓。记住,好的workqueue使用就像好的餐厅管理——正确的任务分配给正确的人(线程),在正确的时间(调度时机),以正确的方式(优先级和并发度)完成。
希望这篇深度剖析能帮助你更好地驾驭Linux内核的并发世界。如果你对更多底层技术或系统编程感兴趣,欢迎到 云栈社区 交流探讨。
 发表于 2026-1-18 03:22:22
|
查看: 151|
回复: 0
发表于 2026-1-18 03:22:22
|
查看: 151|
回复: 0
