在人工智能和机器学习领域,通用矩阵乘法(GEMM) 已成为支撑大模型训练与推理的核心计算操作。无论是GPT-4这样的万亿参数模型,还是科学计算中的大规模线性代数问题,其高效执行都依赖于海量的GEMM运算。GPU凭借强大的并行计算能力和专用矩阵核心,是加速GEMM的关键硬件。
然而,在GPU上实现高性能的GEMM内核极具挑战。开发者不仅要深刻理解GPU复杂的内存层次结构,还需精心设计数据流,确保计算单元能持续获得数据,避免因供给不足导致性能瓶颈。
更棘手的是,一个高效的内核只是开始——构建完整的GEMM库还需要在运行时为千变万化的矩阵形状(M, N, K)自动选择最优的内核配置,包括分块大小、循环展开策略等。
传统的解决方案依赖于自动调优:通过编译并实际运行大量候选配置,从中选出最快的。这种方法虽能逼近最优性能,却需要付出巨大的时间与计算资源代价,且调优结果难以跨硬件平台迁移。

今天我们将深入解读由AMD团队发布的论文《tritonBLAS: Triton-based Analytical Approach for GEMM Kernel Parameter Selection》。它提出了一项突破性工作:完全摒弃运行时自动调优,转而通过一个轻量、确定性的分析模型,直接“计算”出接近最优的GEMM内核参数。
这项研究基于流行的GPU编程框架Triton实现,旨在为生产环境中的高性能计算与机器学习负载提供一个零调优开销、即开即用的高性能GEMM解决方案。关于GPU性能优化的更多深度讨论,可以访问智能 & 数据 & 云板块。
一、 背景与挑战:为何我们需要摆脱自动调优?
1. GEMM:从算法到硬件的映射艺术
广义矩阵乘法定义为: C = A × B,其中 A ∈ R^{M×K}, B ∈ R^{K×N}, C ∈ R^{M×N}。其最朴素的实现是一个三层嵌套循环。
在GPU上实现高性能GEMM的关键在于层次化分块。核心思想是:将庞大的输出矩阵C分解为多个小块(Tile),并利用GPU的多级存储和并行计算单元协同处理。
典型的“输出固定”数据流如以下算法所示:将M和N维度在计算单元间进行空间上的并行划分,而将K维度在时间上顺序累加。

分块参数的选择是一场精密的权衡游戏:
- 并行性:分块越小,产生的输出块越多,越能充分利用GPU上大量的计算单元。
- 局部性:分块越大,每个数据块在被换出缓存前能被重用的次数越多,减少了昂贵的内存访问。
例如,对于矩阵大小 M=N=4096,若选择分块尺寸 MT=NT=256,将产生 16x16=256 个输出块,正好可以映射到一个拥有256个计算单元(CU)的GPU上,实现完全并行。若选择 MT=NT=4096 的分块,则只产生1个输出块,整个计算将落在一个CU上,造成巨大的计算资源闲置。
2. 自动调优的“阿喀琉斯之踵”
以Triton为代表的现代GPU编程框架,通过高级语言抽象简化了内核开发,但其高性能严重依赖自动调优系统。用户需要预先定义一个候选配置空间,当内核首次被某个问题形状调用时,框架会编译并逐一运行所有候选配置以测量耗时,最后选择最快的。
这种方法的弊端显而易见:
- 高昂的开销:编译和基准测试耗时与候选配置数量、问题规模成正比。对于动态形状或实时应用,此开销不可接受。
- 搜索空间限制:性能严重依赖于用户定义的配置空间是否完备。穷举搜索在面对海量可能的矩阵形状时不具备可扩展性。
- 可移植性差:在一款显卡上调优出的最优配置,在另一款上可能表现平平甚至糟糕。
二、 tritonBLAS的核心创新:用分析模型取代“试错”
tritonBLAS的雄心在于:不运行任何候选内核,仅通过一个分析模型,直接预测出给定问题在目标硬件上的近似最优配置。其核心是一个分层性能模型,它将GEMM操作分解,并量化评估硬件架构与算法结构之间的相互作用。
1. 设计目标:清晰而务实
- 接近最优性能:对广泛矩阵形状达到近似最优。
- 零调优:无需运行时搜索。
- 轻量快速:选择配置的额外开销微乎其微。
- 确定性:相同输入总是产生相同选择,确保可复现性。
- 架构可移植:仅依赖可测量的硬件参数,通过微基准测试校准即可适配新硬件。
2. 方法论基石:层次化分块建模
tritonBLAS性能模型的起点是精确刻画GPU的层次化分块结构。如下表所示,对于AMD MI300X GPU,分块层次自底向上包括:指令/矩阵核心、寄存器/SIMD、共享内存/计算单元(CU)、L2缓存/加速器芯片组(XCD)以及全局内存/设备。
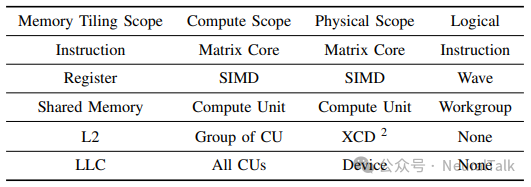
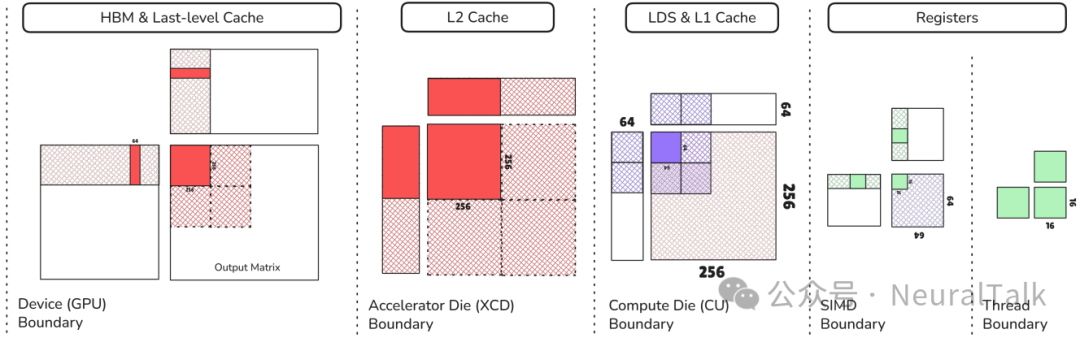
这个层次结构是理解并行性与局部性之源。下层分块旨在最大化数据复用(局部性),而上层分块旨在将工作负载映射到更多的计算资源上(并行性)。
三、 深入模型:如何量化并行性与局部性?
1. 量化并行性:从矩阵核心到芯片满载
tritonBLAS从三个层面量化并行性对性能的影响:
- a) 矩阵核心级并行:这是由GPU硬件决定的固定吞吐量。例如,一个MFMA指令可能在固定周期内完成一个小矩阵乘。这是一个已知的硬件常数。
- b) 计算单元内部并行:一个工作组分块需要被一个CU内的多个SIMD协作完成。其计算延迟可以通过将工作组分块尺寸分解为多个MFMA指令来估算。

- c) 计算单元间并行(占用率):这是决定性能的关键。tritonBLAS将M和N维度的输出块在GPU的各个CU之间进行分配。占用率取决于输出块总数与GPU CU总数之比。
一个重要洞察是“波次量化”问题:由于输出块总数不一定能被CU总数整除,最后一波可能只有部分CU在工作,造成计算资源利用不足。tritonBLAS通过算法精确计算最后一波的活跃CU数,从而更准确地建模整体占用率。
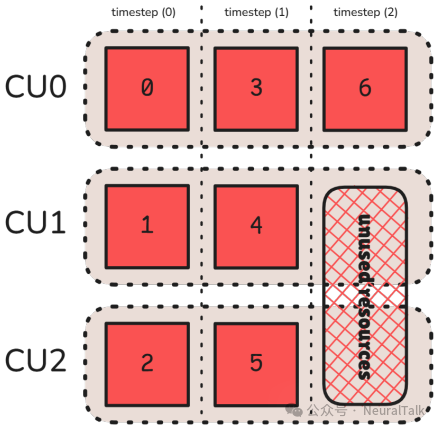
上图是跨时间步的占用率示意图,可以看出只有最后一个时间步是“未满载”的。

2. 量化局部性:软件管理与硬件缓存的共舞
局部性分为两类:
- 软件管理局部性:通过显式使用共享内存,程序员可以精确控制数据在SIMD内和SIMD间的复用。
- 硬件管理局部性:由GPU的L1/L2缓存透明管理,其行为需要被预测。
缓存行为预测是模型的精髓。tritonBLAS首先根据共享同一缓存的CU数量,枚举所有可能的长方形缓存分块形状。通常,最接近正方形的形状能最大化缓存内数据的重用。


随后,估算缓存命中率。其基本思想是:高层缓存以底层分块为单位进行交互。通过计算未缓存读取与总读取的比率,得到命中率。模型还会将每一步的工作集大小与缓存有效容量对比,若超出则按比例降低预测命中率,从而捕捉容量限制效应。
3. 权衡的艺术:并行性 vs. 局部性
最优分块并非单纯追求最高并行性或最强局部性,而是寻找两者之间的最佳平衡点,使单次迭代(K维度一步)的延迟最小。由于软件流水线的存在,单次迭代的最终延迟是计算延迟和内存延迟的较大值。
tritonBLAS将可能遇到的瓶颈归纳为几类:
| 瓶颈类别 |
核心描述 |
解决方案 |
| 加载/存储指令发射率瓶颈 |
加载/存储单元的占用率不足,无法提供足够的带宽以支撑计算需求 |
提高加载/存储单元的占用率,确保数据传输能力与计算需求匹配 |
| 软件管理内存带宽瓶颈 |
已充分利用共享内存实现数据复用,但计算性能受限于从共享内存加载数据的带宽 |
增大寄存器分块尺寸,最大化从软件管理内存(如共享内存)加载数据的复用率 |
| 缓存带宽瓶颈 |
硬件管理的缓存(如L2、LLC)因带宽有限,成为限制计算性能的瓶颈 |
提高软件管理内存(如共享内存)中的数据复用率,减少对硬件缓存带宽的依赖 |
| 计算单元占用不足瓶颈 |
已占用的计算单元(CU)中矩阵指令利用率较高,但整体计算单元占用数量不足,无法达到最大吞吐量 |
展开K维度循环或调整分块尺寸,提高计算单元的整体占用率 |
| 最大并行计算瓶颈 |
所有计算单元均被占用,且因软件流水线无内存瓶颈,矩阵指令利用率处于较高水平,已达到硬件最大可实现性能 |
无需进一步优化,此状态下已实现最优性能 |
这些目标常常相互冲突:例如,为了提高并行性而缩小分块,却可能损害缓存局部性。tritonBLAS的分析模型正是通过第一性原理,估算不同分块选择下的计算与内存延迟,来导航这个复杂的权衡空间。理解这类性能权衡背后的计算机科学原理至关重要。
四、 从模型到实践:如何计算GEMM总延迟?
tritonBLAS将上述所有量化指标整合为一个最终的性能评估指标:预测的GEMM总延迟。这个过程分为三步:
- 计算单次迭代延迟:结合各级缓存的命中率和带宽,计算完成一次K维度分块计算所需的内存延迟,并与计算延迟取最大值,得到流水线迭代延迟。
- 计算单个输出块延迟:一个输出块的计算包含流水线“序章”(加载数据)、“主循环”(多次迭代)和“尾声”(写回结果)。
- 计算整个GEMM延迟:根据输出块总数、CU总数和每个输出块的延迟,计算出整个GEMM运算的预测总延迟。
这个预测的总延迟就是tritonBLAS为不同分块配置进行排名的“分数”。模型会为给定问题评估所有合法的分块配置,选择预测延迟最小的那个。整个过程完全基于分析和计算,无需运行任何内核代码。



五、 性能评估:模型真的有效吗?
在AMD Instinct MI300X GPU上对tritonBLAS进行了全面评估。
1. 选择准确率:媲美穷举搜索
在15万个随机矩阵形状的测试集上,tritonBLAS的选择效率达到了94.7%。这意味着,其自动选择的配置能达到穷举搜索能找到的最优配置性能的94.7%。
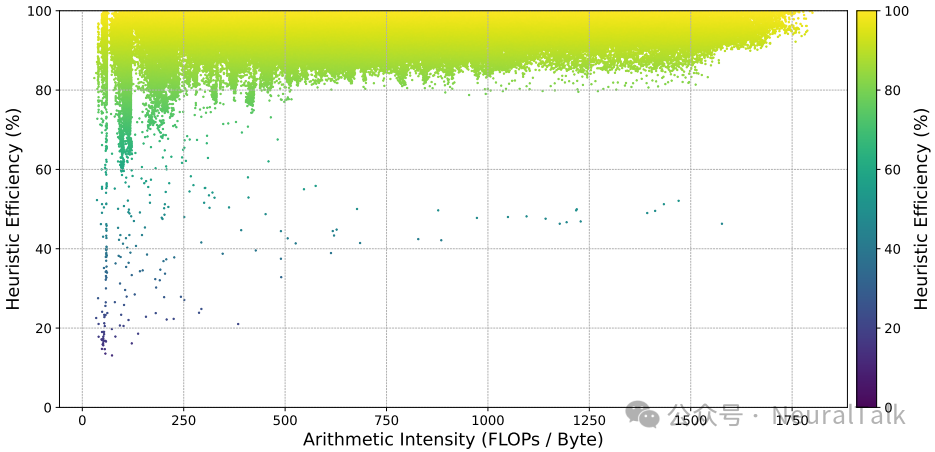
上图是tritonBLAS相对于Triton穷举自动调优的效率散点图。大多数点密集分布在顶部,表明在广泛算术强度范围内都有高效率。
2. 选择开销:数量级的飞跃
这是tritonBLAS最显著的优势。传统自动调优的选择时间随问题规模激增,而tritonBLAS的选择时间稳定在50-80微秒,快了5到6个数量级。
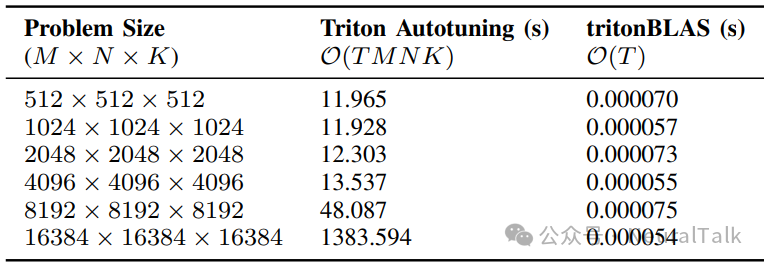
上表是对比数据。以问题规模 16384×16384×16384 为例,Triton自动调优耗时约23分钟,而tritonBLAS仅需0.000054秒。
3. 绝对性能:匹敌厂商优化库
与PyTorch调用的高度优化的厂商GEMM库相比,tritonBLAS的平均性能仅低约3%。在一些关键的大模型典型矩阵尺寸上,tritonBLAS甚至能取得最高1.1倍的加速,平均性能差距在13.9%以内,表现极具竞争力。
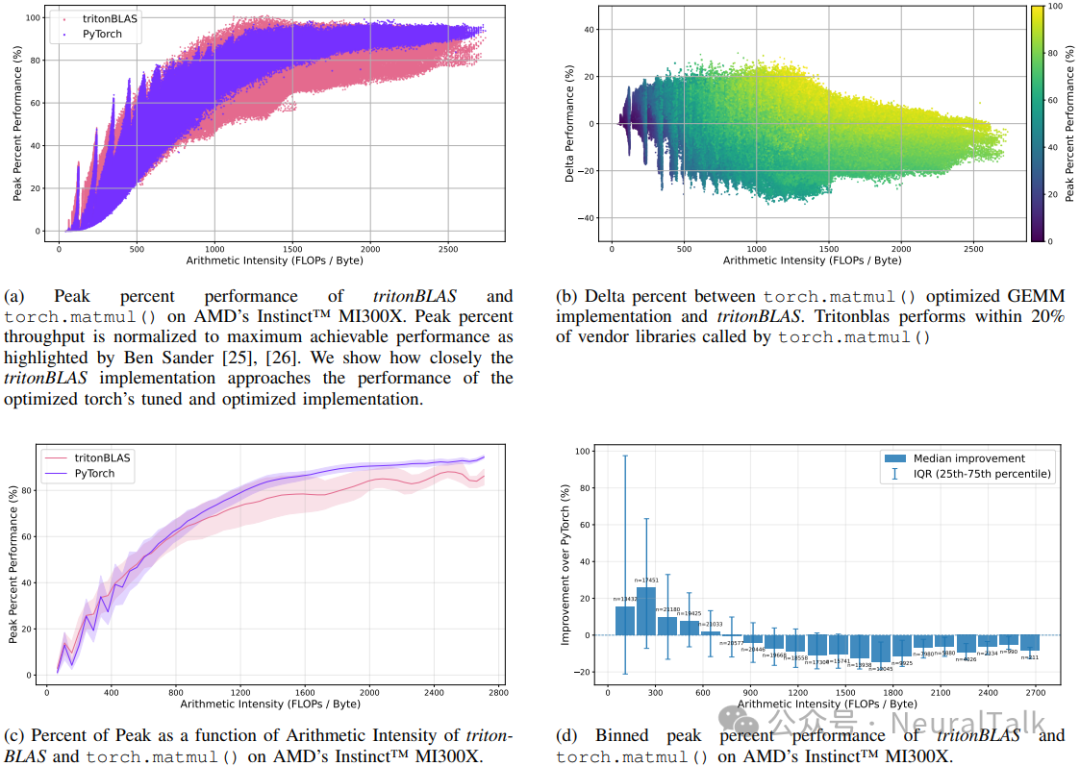
进一步分析上图:
- 图4a:对比了tritonBLAS与PyTorch底层优化库的性能。tritonBLAS通过Stream-K技术优化GPU占用率,平均性能表现出色。部分差距源于Triton框架自身的限制。
- 图4b:量化了性能差异,tritonBLAS处于厂商库性能的20%范围内,在无自动调优开销下极具竞争力。
- 图4c & 4d:展示了不同算术强度下的性能表现,验证了分析模型对不同瓶颈场景的适配能力,性能稳定。
4. 架构可移植性:验证成功
模型的参数仅包含可测量的硬件参数。作者将同一套模型应用于下一代MI350X GPU,仅更新参数就获得了与MI300X一致的趋势表现,验证了其良好的跨架构移植能力。

六、 相关工作:站在巨人的肩膀上
tritonBLAS并非首个尝试用分析模型优化GEMM的工作,但其在GPU和Triton语境下的系统化实现独具特色:
- CUTLASS/cuBLAS:使用基于经验的启发式规则,但规则闭源且与特定硬件深度耦合。
- TVM/Ansor:结合分析模型与学习修正项,但仍依赖数据驱动拟合。
- DeLTA:提出感知局部性的屋顶线模型用于分析预定义内核性能。
tritonBLAS的独特之处在于,它将完整的、基于第一性原理的分析模型深度集成到Triton JIT编译流程中,实现了从建模、选择到代码生成的全栈式、零调优解决方案。
七、 总结与展望
tritonBLAS展示了一条通向高效GPU计算的新路径:用严谨的分析和建模代替昂贵的“试错”。它通过一个层次化性能模型,精确量化了GPU上GEMM操作的并行性、局部性及其复杂权衡,从而能够在微秒级时间内为任意矩阵形状确定接近最优的内核配置。
这项工作的意义深远:
- 极大降低部署门槛:消除了生产环境中令人望而却步的调优开销。
- 提升开发效率:为开发者提供了强大的分析工具,快速评估算法和硬件设计的影响。
- 推动性能可移植性:基于硬件参数的模型使其能够更平滑地跨不同GPU进行迁移。
当然,tritonBLAS目前聚焦于单GPU上的标准GEMM。其框架未来有望扩展到多GPU分布式计算、更复杂的类GEMM算子以及更广泛的张量计算领域。
在追求算力极致的时代,tritonBLAS代表了一种思维的转变:从“盲目搜索”到“精准计算”。它证明,通过深刻理解硬件与算法的内在规律,我们完全可以用“数学”算出高效的代码。对于关注前沿优化技术和算法实现的开发者而言,这无疑是一个值得深入探究的方向。欢迎在云栈社区交流更多技术见解。
 发表于 2026-1-18 06:58:37
|
查看: 173|
回复: 0
发表于 2026-1-18 06:58:37
|
查看: 173|
回复: 0
