
Unicorn 是一个基于 QEMU 的轻量级、多平台、多架构 CPU 模拟器框架。相比于重量级的符号执行框架(如 Angr),Unicorn 虽然没有内置 Z3 约束求解器,但凭借其极致的性能、友好的 API 设计以及强大的 Hook 机制(指令级回调),成为了二进制分析、反混淆和CTF竞赛中的利器。
核心特性
- 多架构支持:全面覆盖 ARM, ARM64 (ARMv8), MIPS, x86 (含 x64), PowerPC, RISC-V, SPARC 等主流架构。
- 极致轻量:基于纯 C 语言实现,无复杂的依赖链,API 设计直观且架构中立。
- 高性能:利用 JIT(Just-In-Time)编译技术,模拟执行速度极快。
- 多语言绑定:除了 C 语言原生接口,官方还提供了 Python, Java, Go, Rust, .NET 等几乎所有主流语言的绑定。
- 跨平台:完美运行于 Windows, Linux, macOS, BSD 等操作系统。
Unicorn 到底是什么?
简单来说,Unicorn 是一款 CPU 模拟器。
但与 VMWare 或 Android 模拟器不同,Unicorn 不负责模拟整个操作系统或完整的硬件环境,它不支持系统调用 (Syscall)。
你需要像操作“裸机”一样:
- 手动申请并映射内存 (Map Memory)。
- 手动写入二进制代码和数据 (Write Data)。
- 设置 CPU 寄存器状态 (Set Registers)。
- 指定起始地址,开始模拟执行 (Emulate)。
应用场景
- 恶意代码分析:截取并模拟执行恶意软件中的解密函数,无需运行整个病毒样本。
- CTF 竞赛:解决复杂的逆向题目,特别是涉及自定义算法或混淆的代码。
- 代码反混淆:模拟执行混淆代码(如 OLLVM),跟踪寄存器变化以还原真实逻辑。
- Shellcode 测试:在安全的环境中快速验证 Shellcode 的功能。
为了避免污染系统的 Python 环境,推荐使用 Conda 进行环境隔离。
创建虚拟环境
# 创建名为 “Unicorn” 的环境,指定 python 版本为 3.9
conda create -n Unicorn python=3.9
激活环境
# 进入虚拟环境
conda activate Unicorn
安装 Unicorn 模块
使用 pip 安装官方的 Python 绑定:
# 安装 unicorn 核心库
pip install unicorn
验证安装
在终端输入 python 进入交互模式,尝试导入:
import unicorn
print(unicorn.__version__)
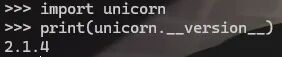
如果无报错且输出了版本号,说明环境搭建成功。
项目配置
打开你的 IDE(如 PyCharm 或 VSCode),创建一个新的 Python 项目。在解释器设置(Interpreter Settings)中,选择 Existing Environment(现有环境),并指向刚刚创建的 Conda 环境路径。

学习 Unicorn 的过程,其实就是学习如何手动扮演操作系统的角色,为 CPU 准备好它运行所需的一切资源。
我们将按照以下顺序攻克 Unicorn 的核心要素:
核心思维模型:模拟执行五步曲
在开始编写 Unicorn 代码之前,我们必须建立一个清晰的思维模型。使用 Unicorn 就像是在扮演一个“手动挡”的操作系统,你必须亲手为 CPU 准备好它运行所需的一切资源。所有的 Unicorn 脚本(无论多么复杂)都逃不出以下 5 个标准步骤:
第一步:初始化 (Initialize)
首先,我们需要引入 Unicorn 库,并实例化一个 Uc 对象。这一步决定了我们要模拟的硬件环境。
- 选择架构:如
UC_ARCH_X86, UC_ARCH_ARM
- 选择模式:如
UC_MODE_32, UC_MODE_64
from unicorn import *
# 加载 x86 和 x86-64 两种架构的常量
from unicorn.x86_const import *
# 初始化一个 X86-64 架构的模拟器实例
# UC_ARCH_X86: 架构
# UC_MODE_64: 64位模式
mu = Uc(UC_ARCH_X86, UC_MODE_64)
第二步:映射内存 (Map Memory)
Unicorn 中的 CPU 只能访问已被映射的内存区域。我们需要像操作系统一样,规划并申请虚拟内存空间。
- API:
mu.mem_map(address, size)
- 注意:
address(基址)和 size(大小)必须是内存页大小(通常为 4KB/0x1000)的整数倍。
# 定义内存布局常量
ADDRESS = 0x400000 # 代码段基址
MEM_SIZE = 2 * 1024 * 1024 # 申请 2MB 内存
STACK_ADDR = 0x0 # 栈内存基址(示例)
STACK_SIZE = 1024 * 1024 # 1MB 栈空间
# 1. 映射代码段内存
mu.mem_map(ADDRESS, MEM_SIZE)
# 2. 映射栈内存
mu.mem_map(STACK_ADDR, STACK_SIZE)
第三步:写入数据 (Write Data)
有了内存空间后,我们需要将机器码(Shellcode)或二进制文件内容写入其中。这相当于加载器(Loader)将程序加载到内存的过程。
- API:
mu.mem_write(address, data)
# 读取本地二进制文件(Shellcode)
with open("./test", "rb") as f:
CODE = f.read()
# 将代码写入到基址 0x400000 处
mu.mem_write(ADDRESS, CODE)
第四步:设置环境 (Setup Context)
在运行前,必须初始化 CPU 的关键寄存器。最重要的是设置指令指针 (RIP/EIP)和 栈指针 (RSP/ESP)。
- API:
mu.reg_write(reg_id, value)
- 宏定义:Unicorn 提供了预定义的常量(如
UC_X86_REG_RSP)来标识寄存器。
# 初始化栈指针 (RSP)
# 注意:栈通常是向下增长的,所以指针应指向栈内存的高地址末端
# 并且通常需要保持对齐(如 8字节或16字节对齐)
mu.reg_write(UC_X86_REG_RSP, STACK_ADDR + STACK_SIZE - 8)
# (可选) 初始化其他通用寄存器,作为函数参数
# mu.reg_write(UC_X86_REG_RAX, 0x1)
第五步:开始执行 (Start Emulation)
一切准备就绪,指定入口点和结束点,按下“启动键”。
- API:
mu.emu_start(begin, end)
begin:模拟执行的起始地址。end:模拟执行的结束地址(运行到此地址前停止)。
# 开始模拟执行
# 从代码基址开始,执行到代码末尾
try:
print(">>> Start emulation...")
mu.emu_start(ADDRESS, ADDRESS + len(CODE))
print(">>> Emulation done.")
except UcError as e:
print(f"ERROR: {e}")
# 执行结束后,可以读取寄存器查看结果
r_rax = mu.reg_read(UC_X86_REG_RAX)
print(f">>> RAX = 0x{r_rax:x}")
初始化与常量体系
在 Unicorn 中,一切的起点都是 Uc 类的实例化。这个步骤决定了你要模拟的“硬件规格”——即 CPU 的架构(Architecture)和运行模式(Mode)。
1. 实例化引擎
要创建一个模拟器实例,我们需要传入两个核心参数:
# 原型:Uc(arch, mode)
mu = Uc(UC_ARCH_X86, UC_MODE_32)
arch (架构):指定 CPU 的指令集架构(如 x86, ARM)。mode (模式):指定 CPU 的运行位数(32/64位)或字节序(大/小端)。
2. 常用架构常量 (Architecture)
Unicorn 支持多种主流架构,以下是逆向分析中最常用的几种:
| 常量名 |
对应架构 |
说明 |
UC_ARCH_X86 |
x86 / x64 |
包含 Intel/AMD 的 16位、32位和 64位架构。 |
UC_ARCH_ARM |
ARM |
经典的 32位 ARM 架构(常见于旧版 Android)。 |
UC_ARCH_ARM64 |
AArch64 |
现代移动设备(Android/iOS)的主流 64位架构。 |
UC_ARCH_MIPS |
MIPS |
常见于路由器、IoT 设备。 |
3. 常用模式常量 (Mode)
模式常量用于进一步细分 CPU 的工作状态。需要注意的是,不同的架构支持的模式不同,且模式可以通过 + 号进行组合。
| 常量名 |
说明 |
适用架构 |
UC_MODE_32 |
32位模式 |
x86, ARM, MIPS 等 |
UC_MODE_64 |
64位模式 |
x86, ARM64, MIPS64 等 |
UC_MODE_THUMB |
Thumb 模式 |
仅限 ARM。用于模拟 16位 Thumb 指令集。 |
UC_MODE_LITTLE_ENDIAN |
小端序 (默认) |
所有架构。数据低位存储在低地址。 |
UC_MODE_BIG_ENDIAN |
大端序 |
MIPS, PowerPC 等。数据高位存储在低地址。 |
4. 实战组合示例
在实际使用中,我们经常需要组合使用这些常量。
场景 A:模拟 PC 上的 32位 Windows 程序
# 标准的 x86 32位环境
mu = Uc(UC_ARCH_X86, UC_MODE_32)
场景 B:模拟 Android 上的 ARM64 代码
# 标准的 ARM64 小端序环境
mu = Uc(UC_ARCH_ARM64, UC_MODE_64)
场景 C:模拟 ARM Thumb 指令
ARM 处理器可以在 ARM 状态(4字节指令)和 Thumb 状态(2字节指令)之间切换。
# 开启 ARM 的 Thumb 模式
mu = Uc(UC_ARCH_ARM, UC_MODE_THUMB)
场景 D:模拟 IoT 设备的 MIPS 大端序程序
某些路由器固件使用大端序 MIPS。
# 组合模式:32位 + 大端序
mu = Uc(UC_ARCH_MIPS, UC_MODE_32 + UC_MODE_BIG_ENDIAN)
内存操作 (Memory API)
Unicorn 模拟器内部没有操作系统的 malloc 或 Heap 管理器。作为“上帝视角”的控制者,你必须手动管理每一页内存的分配、读写和释放。
Unicorn 的内存操作 API 非常精简,核心只有三个:映射(申请)、写入和 读取。
1. 内存映射 (申请内存)
在 CPU 访问任何内存地址之前,该地址必须先被“映射”。访问未映射的内存会导致 UC_ERR_READ_UNMAPPED 或 UC_ERR_WRITE_UNMAPPED 异常。
- API:
uc.mem_map(address, size, perms=UC_PROT_ALL)
address: 起始基址。size: 内存大小。必须是 4KB (0x1000) 的整数倍。perms: (可选) 内存权限,默认可读写执行。
4KB 对齐:
现代操作系统和 CPU 通常以“页(Page)”为单位管理内存,一页通常是 4096 字节 (0x1000)。
如果你尝试申请 0x100 字节,Unicorn 会直接报错。必须向上取整到 0x1000。
# 定义基址和大小
ADDRESS = 0x400000
# 错误写法:SIZE = 1024 (不是 4KB 倍数,会报错)
SIZE = 2 * 1024 * 1024 # 正确:2MB
# 申请 2MB 内存,默认权限 rwx (可读可写可执行)
mu.mem_map(ADDRESS, SIZE)
# 进阶:申请一块“只读”数据区 (UC_PROT_READ)
# 常用于模拟 .rodata 段
DATA_ADDR = 0x800000
mu.mem_map(DATA_ADDR, 0x1000, UC_PROT_READ)
2. 内存写入 (写入数据)
有了内存空间后,我们需要将机器码(Shellcode)或数据填充进去。
- API:
uc.mem_write(address, data)
address: 写入的起始地址。data: 要写入的字节串 (bytes)。
# 机器码:INC EAX (0x40)
machine_code = b"\x40"
# 将机器码写入到刚才申请的代码段基址
mu.mem_write(ADDRESS, machine_code)
# 写入一个字符串到数据段
mu.mem_write(DATA_ADDR, b"Hello Unicorn")
3. 内存读取 (获取结果)
在模拟执行结束后,或者在 Hook 回调中,我们通常需要读取内存中的数据来验证计算结果。
- API:
uc.mem_read(address, size)
- 返回:
bytearray 对象 (可转换为 bytes 或 str)。
# 读取刚才写入的字符串
# 读取 5 个字节 -> b'Hello'
data = mu.mem_read(DATA_ADDR, 5)
print(f"Read from memory: {bytes(data)}")
4. 内存权限常量 (Permissions)
在 mem_map 或 mem_protect 中使用,用于控制内存页的读写执行权限(类似于 Linux 的 mprotect)。
| 常量名 |
权限 |
说明 |
UC_PROT_READ |
可读 (r) |
允许读取数据。 |
UC_PROT_WRITE |
可写 (w) |
允许写入数据。 |
UC_PROT_EXEC |
可执行 (x) |
允许 CPU 在此区域执行指令。 |
UC_PROT_ALL |
rwx |
全权限(默认值)。 |
UC_PROT_NONE |
无权限 |
禁止任何访问。 |
示例:修改内存权限
# 将代码段设为“只读且可执行” (r-x),模拟真实程序的 .text 段属性
# 防止代码在运行中被意外篡改
mu.mem_protect(ADDRESS, SIZE, UC_PROT_READ | UC_PROT_EXEC)
寄存器操作 (Register API)
寄存器是 CPU 的“内部工作台”,几乎所有的运算指令都依赖于它。在 Unicorn 中,我们通过统一的接口来读写不同架构下的数百个寄存器。
核心 API 非常直观:读 (Read)和 写 (Write)。
1. 写寄存器 (初始化环境)
在开始模拟执行之前,通常需要初始化一些关键寄存器:
- 指令指针 (PC/IP):虽然
emu_start 会指定入口,但某些跳转指令可能依赖 PC 的当前状态。
- 栈指针 (SP):这是新手最容易忽略的一步! 如果代码中包含
PUSH/POP、CALL/RET 指令,必须确保栈指针指向一块合法且可写的内存区域。
- 通用寄存器:用于传递函数参数或设置初始状态。
- API:
uc.reg_write(reg_id, value)
# --- 场景:模拟 x86 环境 ---
# 1. 初始化通用寄存器 EAX 为 100
mu.reg_write(UC_X86_REG_EAX, 100)
# 2. 初始化栈指针 ESP
# 栈通常是“向下增长”的,所以我们将 ESP 指向栈底(最高地址)
# 减去 4 或 8 是为了留出一点安全边距或对齐
STACK_ADDR = 0x0
STACK_SIZE = 1024 * 1024
mu.reg_write(UC_X86_REG_ESP, STACK_ADDR + STACK_SIZE - 4)
2. 读寄存器 (获取结果)
模拟执行结束后,或者在 Hook 回调函数中,我们需要读取寄存器的值来检查程序的运行状态或计算结果。
# 读取 EAX 的值,查看计算结果
eax_val = mu.reg_read(UC_X86_REG_EAX)
print(f">>> EAX = 0x{eax_val:x}")
# 在 Hook 中读取当前的指令指针 RIP (查看执行到了哪一行)
rip_val = mu.reg_read(UC_X86_REG_RIP)
3. 常用寄存器常量
Unicorn 为每种架构都定义了海量的寄存器常量。为了方便使用,我们需要导入对应架构的 const 模块。
x86 / x64 架构
from unicorn.x86_const import *
# 通用寄存器
UC_X86_REG_EAX, UC_X86_REG_EBX, UC_X86_REG_ECX ...
UC_X86_REG_RAX, UC_X86_REG_RBX ... (64位)
# 关键指针
UC_X86_REG_EIP / UC_X86_REG_RIP # 指令指针 (PC)
UC_X86_REG_ESP / UC_X86_REG_RSP # 栈指针 (Stack)
UC_X86_REG_EFLAGS # 标志位寄存器
ARM 架构
from unicorn.arm_const import *
# R0 - R15
UC_ARM_REG_R0, UC_ARM_REG_R1 ...
# 关键别名
UC_ARM_REG_PC # Program Counter (R15)
UC_ARM_REG_SP # Stack Pointer (R13)
UC_ARM_REG_LR # Link Register (R14, 保存返回地址)
UC_ARM_REG_CPSR # 状态寄存器
ARM64 架构
from unicorn.arm64_const import *
# X0 - X30
UC_ARM64_REG_X0 ...
# 关键指针
UC_ARM64_REG_PC
UC_ARM64_REG_SP
UC_ARM64_REG_LR # Link Register (X30)
执行控制 (Execution API)
当内存和寄存器都准备就绪后,最后一步就是按下“启动键”,让虚拟 CPU 开始运转。Unicorn 提供了灵活的执行控制接口,允许我们指定运行范围、时间限制甚至指令数量。
1. 开始执行 (Start)
这是 Unicorn 中唯一用于启动 CPU 的 API。调用它是阻塞的,意味着直到模拟结束(或报错),Python 脚本才会继续往下执行。
- API:
uc.emu_start(begin, end, timeout=0, count=0)
参数详解:
begin (int): 起始地址。CPU 将从这里提取第一条指令。end (int): 结束地址。
- 关键规则:Unicorn 的执行范围是 [begin, end),即左闭右开区间。
- 模拟会在 PC (指令指针) 到达
end 地址之前停止。也就是说,位于 end 地址上的指令不会被执行。
- 通常我们将
end 设置为代码段的末尾地址。
timeout (int, 可选): 超时时间(单位:微秒 / microseconds)。
- 用于防止死循环。如果设为
0(默认),则表示无限等待,直到运行到 end 或崩溃。
1000 微秒 = 1 毫秒; 1000000 微秒 = 1 秒。
count (int, 可选): 指令计数。
- 指定要执行的汇编指令条数。
- 如果设为
1,相当于单步调试 (Step Into)。
- 如果设为
0(默认),则不限制数量,直到遇到 end。
ADDRESS = 0x400000 # 代码基址
CODE_LEN = 2 * 1024 * 1024 # 代码长度
# 场景 A: 正常执行所有代码
# 从头跑到尾,没有时间限制
mu.emu_start(ADDRESS, ADDRESS + CODE_LEN)
# 场景 B: 防止死循环 (设置 2秒 超时)
# 如果代码里有 while(1),2秒后会自动抛出 UC_ERR_TIMEOUT 异常
try:
mu.emu_start(ADDRESS, ADDRESS + CODE_LEN, timeout=2 * 1000 * 1000)
except UcError as e:
print(f"Execution stopped: {e}")
# 场景 C: 单步执行 (只跑第一条指令)
# 无论 end 设多大,跑完 1 条指令后立即暂停
mu.emu_start(ADDRESS, ADDRESS + CODE_LEN, count=1)
2. 停止执行 (Stop)
在某些情况下(例如在 Hook 回调函数中检测到了某个特定条件,或者想要实现断点功能),我们需要中途强行停止模拟。
- API:
uc.emu_stop()
- 作用:立即终止当前的
emu_start 过程,控制权返回给 Python 脚本的下一行代码。
注意:emu_stop 通常配合 Hook 使用。
# 这是一个 Hook 回调函数 (后面会详细讲)
def hook_code(uc, address, size, user_data):
print(f">>> Tracing instruction at 0x{address:x}")
# 如果执行到了 0x1000020,强制停止
if address == 0x1000020:
print(">>> Breakpoint hit! Stopping emulation.")
uc.emu_stop()
# 注册 Hook,然后启动
# ...
mu.emu_start(ADDRESS, ADDRESS + CODE_LEN)
print(">>> Emulation finished or stopped by hook.")
初探 Hook 机制 (Hook API)
如果说 emu_start 是让程序跑起来,那么 Hook 就是让程序“透明化”。
Hook 机制是 Unicorn 最强大的特性之一。它允许我们在模拟执行的过程中插入自定义的回调函数(Callback),相当于在 CPU 内部安装了无数个“监控探头”。
通过 Hook,我们可以实现:
- 指令追踪:打印每一条正在执行的汇编指令(Trace)。
- 内存监控:检测程序是否非法读写了内存。
- 断点调试:在特定地址暂停执行。
- 补丁/Fuzz:动态修改寄存器或内存数据。
1. 注册 Hook (安装监控)
- API:
uc.hook_add(hook_type, callback, user_data=None, begin=1, end=0)
hook_type: 监控类型(如指令执行、内存读写、中断等)。callback: 触发时调用的 Python 函数。user_data: (可选) 传递给回调函数的额外数据。begin, end: (可选) 仅监控此地址范围内的事件。默认监控全局。
- API:
uc.hook_del(hook_handle)
2. 常用的 Hook 类型与回调写法
Unicorn 的 Hook 系统非常灵活,以下是三种最基础且最常用的 Hook 类型:
类型 A: 指令级 Hook (UC_HOOK_CODE)
- 作用:每执行一条汇编指令之前,都会触发一次回调。
- 场景:用于打印执行轨迹(Trace)、统计指令覆盖率、或者在特定地址进行 Patch。
- 注意:全局指令 Hook 会显著降低模拟速度,建议配合
begin 和 end 限定范围。
回调函数签名:
def hook_code(uc, address, size, user_data):
"""
uc: Unicorn 引擎实例
address: 当前即将执行的指令地址
size: 当前指令的长度 (字节)
user_data: hook_add 时传入的额外数据 (可以是任意对象)
"""
print(f">>> Tracing instruction at 0x{address:x}, instruction size = {size}")
注册示例:
# 1. 监控所有代码的执行 (全局)
mu.hook_add(UC_HOOK_CODE, hook_code)
# 2. 仅监控特定范围 (例如仅监控某个函数内部)
# begin: 起始地址, end: 结束地址
mu.hook_add(UC_HOOK_CODE, hook_code, begin=0x400000, end=0x400008)
类型 B: 内存级 Hook (UC_HOOK_MEM_*)
- 作用:当 CPU 尝试读取、写入或获取内存指令时触发。
- 常量组合:
UC_HOOK_MEM_READ: 有效内存读取。UC_HOOK_MEM_WRITE: 有效内存写入。UC_HOOK_MEM_UNMAPPED: 访问了未映射(非法)的内存。这是捕获 Crash 的核心手段。
回调函数签名:
def hook_mem_access(uc, access, address, size, value, user_data):
"""
access: 访问类型 (如 UC_MEM_READ, UC_MEM_WRITE, UC_MEM_READ_UNMAPPED)
address: 正在访问的内存地址
size: 读写的数据长度
value: 正在写入的数据值 (仅在 WRITE 类操作时有效,READ 时通常为 0)
"""
if access == UC_MEM_WRITE:
print(f">>> Memory WRITE at 0x{address:x}, size={size}, value=0x{value:x}")
else:
print(f">>> Memory READ at 0x{address:x}, size={size}")
# 对于 UNMAPPED 类型的 Hook:
# 返回 True -> 忽略错误,跳过该指令继续执行 (非常危险,通常用于 Fuzz)
# 返回 False -> 停止模拟,抛出 UcError 异常 (默认行为)
return False
注册示例:
# 同时监控内存读取和写入
mu.hook_add(UC_HOOK_MEM_READ | UC_HOOK_MEM_WRITE, hook_mem_access)
类型 C: 系统调用 Hook (Syscall Handling)
这是 Unicorn 中最容易踩坑的地方。虽然直觉上我们认为系统调用是一种“中断”,但在 Unicorn (基于 QEMU) 的实现中,不同架构和指令触发 Hook 的机制完全不同。
常见误区:
很多人认为 UC_HOOK_INTR 可以捕获所有系统调用。
- 事实:
UC_HOOK_INTR 只能捕获 int 0x80 (x86 软中断)。对于现代 x64 Linux 程序使用的 syscall 指令,它不会触发中断 Hook。
正确姿势:
针对 syscall 指令,我们必须使用 UC_HOOK_INSN(指令特定 Hook),并指定指令 ID 为 UC_X86_INS_SYSCALL。
| 架构 / 指令 |
触发的 Hook 类型 |
说明 |
x86 (32-bit) / int 0x80 |
UC_HOOK_INTR |
属于软中断,走中断回调。 |
x64 (64-bit) / syscall |
UC_HOOK_INSN |
属于特殊指令,需绑定 UC_X86_INS_SYSCALL。 |
1. 针对 x64 syscall 的 Hook 写法
回调函数签名与普通 Hook 不同,它不接收 address 和 size 参数(因为指令已经确定了)。
def hook_syscall(uc, user_data):
"""
针对 syscall 指令的回调
注意:没有 address, size 参数
"""
# 读取系统调用号 (x64 Linux 传参规则)
rax = uc.reg_read(UC_X86_REG_RAX)
print(f"[SYSCALL] Triggered syscall number: {rax}")
# 在这里模拟内核逻辑...
# 注册 Hook
# 参数 6: 必须指定为 UC_X86_INS_SYSCALL
mu.hook_add(UC_HOOK_INSN, hook_syscall, None, 1, 0, UC_X86_INS_SYSCALL)
2. 针对 x86 int 0x80 的 Hook 写法
def hook_intr(uc, intno, user_data):
"""
针对 int 0x80 的回调
intno: 中断号 (通常为 0x80)
"""
if intno == 0x80:
eax = uc.reg_read(UC_X86_REG_EAX)
print(f"[INT 0x80] Triggered syscall number: {eax}")
# 注册 Hook
mu.hook_add(UC_HOOK_INTR, hook_intr)
3. 实战:构建一个综合调试监视器
将上述三种 Hook 结合起来,我们就能得到一个功能完备的“调试监视器”。它可以帮我们实时追踪指令流,并在发生非法内存访问时自动报警。
# 1. 定义指令追踪回调
def trace_inst(uc, address, size, user_data):
# 读取当前的 RIP 寄存器,验证 CPU 状态
# 注意:需要确保已导入 unicorn.x86_const
rip = uc.reg_read(UC_X86_REG_RIP)
print(f"--- IP: 0x{rip:x} | Inst Size: {size} ---")
# 2. 定义异常内存访问回调 (Crash 捕获器)
def hook_mem_invalid(uc, access, address, size, value, user_data):
# 建立映射表,将常量转换为可读字符串
access_type = {
UC_MEM_READ_UNMAPPED: "READ_UNMAPPED",
UC_MEM_WRITE_UNMAPPED: "WRITE_UNMAPPED",
UC_MEM_FETCH_UNMAPPED: "FETCH_UNMAPPED", # 指令预取错误(通常是EIP跑飞了)
}.get(access, "UNKNOWN")
print(f"[CRASH] Invalid Memory {access_type} at 0x{address:x}, size={size}")
# 返回 False:通知 Unicorn 停止模拟,并抛出 Python 异常
# 返回 True:强行忽略错误(不推荐,除非你手动修复了映射)
return False
# 3. 定义中断回调
def hook_intr(uc, intno, user_data):
print(f"[INT] Interrupt {intno} hit!")
# 4. 注册所有 Hook
print(" Installing hooks...")
# 追踪执行流
mu.hook_add(UC_HOOK_CODE, trace_inst)
# 监控非法内存访问 (Crash)
mu.hook_add(UC_HOOK_MEM_UNMAPPED, hook_mem_invalid)
# 监控中断
mu.hook_add(UC_HOOK_INTR, hook_intr)
# 5. 开始执行...
# mu.emu_start(...)
实战:编写一个 x86 模拟器
纸上得来终觉浅。现在,我们将前面的所有知识点串联起来,编写一个完整的 Unicorn 脚本。
我们将从零开始构建一个 x86-32 虚拟环境,并让它执行一条最简单的汇编指令:INC EAX (将 EAX 寄存器的值加 1)。
实验目标
- 构建一个 32位 x86 模拟器。
- 在内存
0x400000 处写入机器码 0x40 (对应汇编 INC EAX)。
- 将寄存器
EAX 的初始值设为 100。
- 执行模拟后,验证
EAX 的值是否变成了 101。
完整代码实现
from unicorn import *
from unicorn.x86_const import *
# ==========================================
# 1. 定义配置常量
# ==========================================
# x86机器码: INC EAX
# 对应的十六进制是 0x40 (在 64位模式下通常表示为 REX 前缀或直接操作)
# 这里为了演示简单,我们使用兼容的机器码
X86_CODE32 = b"\x40" # INC EAX
# 内存布局
ADDRESS = 0x1000000 # 代码段基址
MEM_SIZE = 2 * 1024 * 1024 # 申请 2MB 内存
def test_x86():
print("=== Unicorn x86-64 Demo Start ===")
try:
# ==========================================
# 2. 初始化 (Initialize)
# ==========================================
# 初始化一个 x86 架构、32位 模式的模拟器
mu = Uc(UC_ARCH_X86, UC_MODE_32)
# ==========================================
# 3. 映射内存 (Map Memory)
# ==========================================
# 申请 2MB 内存空间
print(f" Mapping memory at 0x{ADDRESS:x}, size={MEM_SIZE} bytes")
mu.mem_map(ADDRESS, MEM_SIZE)
# ==========================================
# 4. 写入数据 (Write Data)
# ==========================================
# 将机器码写入内存基址
print(f" Writing machine code to 0x{ADDRESS:x}")
mu.mem_write(ADDRESS, X86_CODE32)
# ==========================================
# 5. 设置环境 (Setup Context)
# ==========================================
# 将 EAX 寄存器初始化为 100
print(" Setting EAX = 100")
mu.reg_write(UC_X86_REG_EAX, 100)
# ==========================================
# 6. 开始执行 (Start Emulation)
# ==========================================
# 从 ADDRESS 开始,执行完代码长度后停止
print(" Starting emulation...")
mu.emu_start(ADDRESS, ADDRESS + len(X86_CODE32))
print(" Emulation done.")
# ==========================================
# 7. 验证结果 (Read Register)
# ==========================================
# 读取 EAX 的值
r_eax = mu.reg_read(UC_X86_REG_EAX)
print(f">>> Result: EAX = {r_eax}")
# 逻辑校验
if r_eax == 101:
print(">>> SUCCESS! (100 + 1 = 101)")
else:
print(">>> FAILED!")
except UcError as e:
# 异常处理:捕获 Unicorn 内部错误(如内存未映射、非法指令等)
print(f"ERROR: {e}")
if __name__ == '__main__':
test_x86()
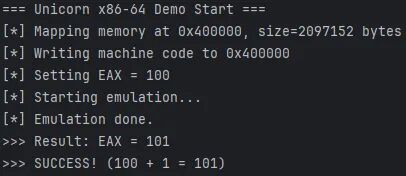
运行结果解析
当你运行这段代码时,终端输出如下内容:
异常处理 (Error Handling)
在代码中我们使用了 try...except UcError 结构。这是编写 Unicorn 脚本的最佳实践。
如果我们在 mem_map 时传入了非 4KB 对齐的大小,或者试图执行未写入指令的内存区域,Unicorn 会抛出 UcError。
常见错误代码:
UC_ERR_READ_UNMAPPED: 读取了未映射的内存。UC_ERR_FETCH_UNMAPPED: 试图执行未映射区域的代码(通常是 EIP 跑飞了)。UC_ERR_INSN_INVALID: 遇到了无法解析的非法指令。
在掌握了 Unicorn 的基础操作后,我们将目光转向更复杂的真实场景。真实的程序不仅仅是简单的加减乘除,它们涉及文件 IO、内存管理、函数调用以及复杂的控制流。
本章节将围绕 “如何模拟一个真实的 ELF/PE 可执行文件” 展开,逐步解决以下核心挑战:
引入三剑客:Unicorn + Capstone + Keystone
在二进制分析的战场上,单打独斗往往力不从心。为了构建一个功能完备的分析环境,我们通常会将 Unicorn 与另外两款神器—— Capstone 和 Keystone 结合使用。
这三者同宗同源(均由同一团队开发),被誉为逆向工程界的“三剑客”:
| 工具 |
角色 |
功能描述 |
核心能力 |
| Unicorn |
大脑 (CPU) |
模拟执行引擎 |
负责跑代码,改变寄存器与内存状态。 |
| Capstone |
眼睛 (Eye) |
反汇编框架 |
将二进制机器码翻译成汇编指令,让我们“看懂”正在执行什么。 |
| Keystone |
双手 (Hand) |
汇编框架 |
将汇编指令编译成机器码,用于动态 Patch 代码或生成 Shellcode。 |
1. Capstone:动态代码解析
在 Unicorn 的 UC_HOOK_CODE 回调中,我们只能拿到当前指令的地址和长度。如果不进行反汇编,我们无法知道具体执行了什么逻辑。
基本用法示例:
from capstone import *
# 1. 初始化反汇编引擎 (x86-32 架构)
cs = Cs(CS_ARCH_X86, CS_MODE_32)
# 2. 在 Hook 回调中使用
def hook_code(uc, address, size, user_data):
# 读取当前指令的机器码
code = uc.mem_read(address, size)
# 反汇编 (返回一个生成器,通常只取第一条)
for insn in cs.disasm(code, address):
print(f"0x{insn.address:x}:\t{insn.mnemonic}\t{insn.op_str}")
# 输出效果:
# 0x400000: mov eax, 1
# 0x400005: inc ebx
2. Keystone:动态修改代码逻辑
有时候我们需要在模拟过程中动态修改程序行为,比如将一条复杂的 CALL 指令替换为 NOP,或者直接注入一段 Shellcode。Keystone 让我们可以直接写汇编,而不用手动拼凑十六进制机器码。
基本用法示例:
from keystone import *
# 1. 初始化汇编引擎 (x86-32 架构)
ks = Ks(KS_ARCH_X86, KS_MODE_32)
# 2. 将汇编代码编译为机器码
# encoding: 机器码列表, count: 语句数量
encoding, count = ks.asm(b"mov rax, 0x1234; inc rax")
# 3. 写入 Unicorn 内存 (Patch)
# 将 Python 的 list 转换为 bytes
machine_code = bytes(encoding)
uc.mem_write(0x400000, machine_code)
这里只做简单了解,具体的学习文章后续更新。
处理外部函数调用 (Hooking & Skipping)
挑战:Unicorn 只是一个裸机 CPU,它没有操作系统内核,也没有加载标准库(libc.so / kernel32.dll)。
当被模拟的程序执行到 call printf 或 call malloc 时,CPU 会跳转到这些函数的地址。但在 Unicorn 的内存中,这些地址通常是未映射的空洞,或者只有符号没有代码。直接执行会导致 Crash。
为了让程序继续跑下去,我们需要手动接管这些“外部调用”。
策略 A:跳过 (Skip) —— “忽略它”
对于那些不影响核心逻辑的函数(如打印日志、Sleep、复杂的系统初始化),我们可以直接跳过。
- 原理:在
CALL 指令处 Hook,强制修改指令指针(RIP/PC),使其跳过 CALL 指令,直接执行下一条。
# 假设 0x401000 处有一条 call printf
def hook_code(uc, address, size, user_data):
if address == 0x401000:
print(" Skipping printf call...")
# 1. 计算下一条指令地址 (当前地址 + 指令长度)
next_inst = address + size
# 2. 强制跳转 (跳过 call)
uc.reg_write(UC_X86_REG_RIP, next_inst)
# 3. 伪造返回值 (假设 printf 返回 0)
uc.reg_write(UC_X86_REG_RAX, 0)
策略 B:高层模拟 (HLE) —— “伪装它”
对于影响程序逻辑的关键函数(如 malloc、strcpy、AES_encrypt),我们不能简单跳过,而是要用 Python 代码来“重写”它们的功能。这被称为 High Level Emulation (HLE)。
- 原理:拦截函数入口,解析参数,用 Python 执行逻辑,将结果写入内存/寄存器,然后执行
RET 返回。
模拟系统调用 (System Calls)
概念:
在现代操作系统中,用户态程序无法直接访问硬件(如读写磁盘、网络通信)。它们必须通过特殊的指令—— SYSCALL (x64) 或 INT 0x80(x86)——陷入内核态,请求操作系统服务。
由于 Unicorn 只是用户态模拟器,遇到这些指令时会停止或报错。我们需要捕获这些信号,并用 Python 代码扮演“操作系统内核”的角色。
1. Hook 技术
Unicorn 提供了专门的 Hook 类型来拦截这些事件:
| 架构 |
指令 |
Hook 类型 |
| x86 (32位) |
INT 0x80 |
UC_HOOK_INTR(中断) |
| x64 (64位) |
SYSCALL |
UC_HOOK_INTR 或 UC_HOOK_SYSCALL(部分绑定支持) |
注意: 通常我们统一使用 UC_HOOK_INTR 来捕获所有类型的中断和系统调用请求,然后根据中断号(intno)进行判断。
2. 实战:模拟 sys_write 与 sys_exit
我们将实现一个迷你 Linux 内核,支持程序打印字符串 (sys_write) 和正常退出 (sys_exit)。
import sys
# Linux x64 系统调用号常量
SYS_WRITE = 1
SYS_EXIT = 60
def hook_syscall(uc, intno, user_data):
# 1. 只有当 intno 为系统调用指令产生的中断时才处理
# 这里的判断逻辑视具体架构而定,但在 x64 下通常无需判断 intno,
# 而是读取 RAX 确认调用号
rax = uc.reg_read(UC_X86_REG_RAX)
# --- 模拟 sys_write (fd, buf, count) ---
if rax == SYS_WRITE:
fd = uc.reg_read(UC_X86_REG_RDI) # 参数1: 文件描述符
buf_ptr = uc.reg_read(UC_X86_REG_RSI) # 参数2: 缓冲区指针
count = uc.reg_read(UC_X86_REG_RDX) # 参数3: 长度
# 从内存读取字符串
data = uc.mem_read(buf_ptr, count)
if fd == 1: # stdout
print(f"[Kernel] sys_write(stdout): {data.decode('utf-8')}", end="")
else:
print(f"[Kernel] sys_write(fd={fd}): {len(data)} bytes")
# 设置返回值 (模拟成功写入了 count 字节)
uc.reg_write(UC_X86_REG_RAX, count)
# --- 模拟 sys_exit (error_code) ---
elif rax == SYS_EXIT:
code = uc.reg_read(UC_X86_REG_RDI)
print(f"\n[Kernel] Program exited with code: {code}")
uc.emu_stop() # 停止模拟
else:
print(f"[Kernel] Unknown syscall number: {rax}")
# 注册 Hook
# 注意:在 Unicorn 中,SYSCALL 指令通常不会自动推进 RIP
# 我们不需要像 CALL 那样手动 pop stack,但有时需要手动 RIP+2 跳过 syscall 指令
# 具体取决于 Unicorn 版本和架构实现
mu.hook_add(UC_HOOK_INTR, hook_syscall)
辅助反混淆 (De-obfuscation)
Unicorn 不仅仅是一个执行器,它更是一个“全知全能”的观察者。通过模拟执行,我们可以拿到静态分析(IDA)无法获取的运行时数据。利用这些数据,我们可以对抗 OLLVM 等现代混淆技术。
OLLVM 控制流平坦化还原 (De-flattening)
痛点:OLLVM 将简单的 if-else 或 while 循环打碎,塞进一个巨大的 switch-case 分发器中(平坦化),导致流程图像一团乱麻。
- 还原思路:
- 找到分发器(Dispatcher)的主干块。
- 模拟执行每个真实块。
- 记录:“执行完块 A 后,状态变量变成了多少?下一个跳到了块 B 吗?”
- 重建关系:直接将块 A 的结尾修改为
JMP Block_B 等,绕过分发器。
1. hxpCTF 2017 - Fibonacci
纸上得来终觉浅,我们通过一个真实的 CTF 题目来实战演练 Unicorn 的使用技巧。本题源自 hxpCTF 2017,名为 Fibonacci。
题目附件: https://eternal.red/assets/files/2017/UE/fibonacci
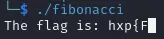
目标: 程序会计算并输出 Flag。我们的任务是让 Unicorn 模拟运行它,并优化执行速度以获取完整 Flag。
当我们运行这个程序的时候,可以注意到这个程序计算和输出Flag非常的慢。Flag的下一个字节计算的越来越慢。
The flag is: hxp{F
初步尝试:模拟运行程序
在拿到二进制文件后,第一步是让它跑起来。我们需要解决内存映射、寄存器初始化以及外部函数调用等问题。
(1) 基础框架搭建
根据前面学习的知识,我们先搭好架子:
- 架构: x86-64
- 内存: 映射代码段和栈段
- 入口: 找到
main 函数的起始 (0x4004E0) 和结束 (0x400582) 地址。
(2) 解决 stdout 报错 (Skipping)
当我们首次运行脚本时,Unicorn 会抛出 UC_ERR_READ_UNMAPPED 错误,提示读取 0x601038 失败。
[MEM READ] 0x601038, size=8
原因分析:
在 IDA 中查看该地址,发现它是 stdout(标准输出流指针)。

程序在 main 函数中调用 setbuf(stdout, NULL) 或 putc(..., stdout) 时,会尝试读取这个指针。由于 Unicorn 没有操作系统环境,.bss 段的这个变量未被 libc 初始化,因此指向了无效区域。
解决方案:
对于这种只影响输出缓冲、不影响核心算法逻辑的代码,直接 Patch (跳过) 即可。我们需要跳过以下地址的指令:
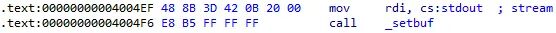
(3) 模拟 printf 和 putc (HLE)
程序使用 printf 输出提示信息,用 putc 逐个输出 Flag 字符。我们需要 Hook 这些地址,用 Python 的 print 替代。
(4) 完整可运行代码
from unicorn import *
from unicorn.x86_const import *
# 1. 初始化
mu = Uc(UC_ARCH_X86, UC_MODE_64)
# 内存布局常量
ADDRESS = 0x400000
MEM_SIZE = 2 * 1024 * 1024
STACK_ADDR = 0x0
STACK_SIZE = 1024 * 1024
# 程序范围
MAIN_START = 0x4004E0
MAIN_END = 0x400582
# 斐波那契函数地址
FIBONACCI_START = 0x400670
# 函数返回指令(RET)所在的地址,可能有多个出口
FIBONACCI_END = [0x4006F1, 0x400709]
# 记忆化搜索容器
fibonacci_dp = {} # 格式: {(arg0, arg1): (rax, rsi_val)}
tmp_dp = [] # 递归调用栈,用于匹配入口和出口
def read_bin(path):
with open(path, 'rb') as f:
return f.read()
def p32(num):
return struct.pack('<I', int(num))
def u32(data):
return struct.unpack('<I', data)[0]
# ==========================================
# 2. 内存与环境初始化
# ==========================================
mu.mem_map(ADDRESS, MEM_SIZE)
mu.mem_map(STACK_ADDR, STACK_SIZE)
# 写入程序
# 请确保路径正确
mu.mem_write(ADDRESS, read_bin(r"E:\Work_Space\fibonacci"))
# 设置 RSP 寄存器 (栈底)
# 注意:栈向下增长,所以设在最高地址
mu.reg_write(UC_X86_REG_RSP, STACK_ADDR + STACK_SIZE - 8)
# ==========================================
# 3. Hook 逻辑实现
# ==========================================
err_skip_addr = [0x4004EF, 0x4004F6, 0x40054F]
put_skip_addr = [0x400560, 0x400575]
def hook_code(uc, address, size, user_data):
# --- [A] 基础模拟部分 ---
# 1. 跳过 stdout 相关的报错地址
if address in err_skip_addr:
mu.reg_write(UC_X86_REG_RIP, address + size)
return
# 2. 模拟 putc 输出 Flag 字符
if address in put_skip_addr:
flag = mu.reg_read(UC_X86_REG_RDI)
print(chr(flag & 0xff), end='', flush=True)
mu.reg_write(UC_X86_REG_RIP, address + size)
return
# 3. 模拟 printf 输出字符串
if address == 0x400502:
str_addr = mu.reg_read(UC_X86_REG_RDI)
data = b""
for i in range(100): # 防止读取过长
c = mu.mem_read(str_addr + i, 1)
if c == b'\x00': break
data += c
print(data.decode(), end='') # 保持格式
mu.reg_write(UC_X86_REG_RIP, address + size)
return
# --- [B] 算法优化部分 (记忆化搜索) ---
# 4. 函数入口 Hook:查表
if address == FIBONACCI_START:
# 根据 System V AMD64 ABI 读取参数
arg0 = mu.reg_read(UC_X86_REG_RDI) # 第一个参数
rsi = mu.reg_read(UC_X86_REG_RSI) # 第二个参数 (指针)
# 读取指针指向的值作为 key 的一部分
arg1 = u32(mu.mem_read(rsi, 4))
if (arg0, arg1) in fibonacci_dp:
# 【命中缓存】直接读取结果,跳过计算
(ret_rax, ret_rsi) = fibonacci_dp[(arg0, arg1)]
# 恢复现场
mu.reg_write(UC_X86_REG_RAX, ret_rax)
mu.mem_write(rsi, p32(ret_rsi))
# 模拟 RET 指令
rsp = mu.reg_read(UC_X86_REG_RSP)
ret_addr = struct.unpack("<Q", mu.mem_read(rsp, 8))[0]
mu.reg_write(UC_X86_REG_RIP, ret_addr)
mu.reg_write(UC_X86_REG_RSP, rsp + 8)
else:
# 【未命中】记录参数,继续执行
tmp_dp.append((arg0, arg1, rsi))
# 5. 函数出口 Hook:记录
if address in FIBONACCI_END:
if tmp_dp:
# 弹出最近一次调用的参数
arg0, arg1, rsi = tmp_dp.pop()
# 获取计算结果
ret_rax = mu.reg_read(UC_X86_REG_RAX)
ret_rsi = u32(mu.mem_read(rsi, 4)) # 某些结果可能通过指针返回
# 存入缓存
fibonacci_dp[(arg0, arg1)] = (ret_rax, ret_rsi)
def hook_mem_invalid(uc, access, address, size, value, user_data):
access_type = {
UC_MEM_READ_UNMAPPED: "READ",
UC_MEM_WRITE_UNMAPPED: "WRITE",
UC_MEM_FETCH_UNMAPPED: "FETCH",
}.get(access, "UNKNOWN")
# 打印内存错误信息
print(f"[MEM {access_type}] 0x{address:x}, size={size}")
return False
# 4. 启动模拟
mu.hook_add(UC_HOOK_CODE, hook_code)
mu.hook_add(UC_HOOK_MEM_UNMAPPED, hook_mem_invalid)
print(">>> Start Emulation...")
try:
mu.emu_start(MAIN_START, MAIN_END)
except UcError as e:
print(f"\n[Error] {e}")
print("\n>>> Done")
运行结果:
>>> Start Emulation...
The flag is:
hxp
程序成功运行并输出了前三个字符 hxp,但随后似乎陷入了卡顿。这是因为程序内部的算法效率极低。
进阶优化:模拟加速 (算法 Hook 优化)
在能够成功运行程序后,我们发现输出 Flag 的速度极慢。通过分析代码可知,该程序使用的是递归方式计算斐波那契数列,时间复杂度为指数级 O(2^n)。如果不进行优化,模拟可能需要数小时甚至数天。
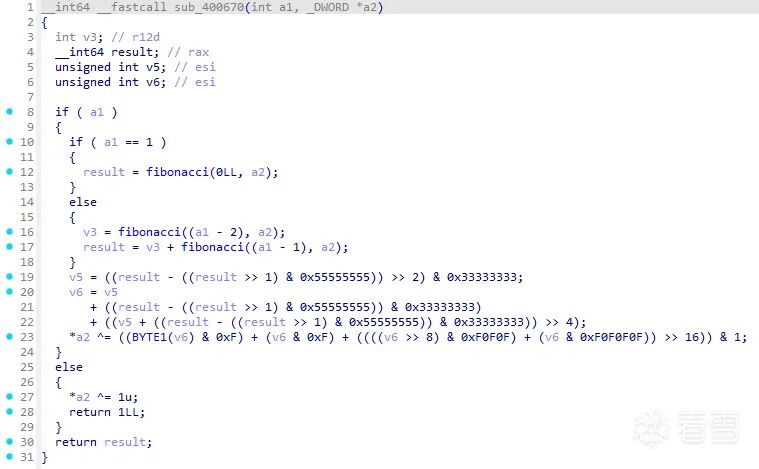
为了解决这个问题,我们采用 Unicorn Hook 实现 记忆化搜索 (Memoization) 算法,以空间换时间。
1. 核心思路
我们需要拦截目标函数 fibonacci 的入口和出口:
建立缓存 (Cache):
使用字典 fibonacci_dp 存储计算结果,映射关系为:{(参数1, 参数2): (返回值RAX, 返回值RSI)}。
处理函数入口 (On Enter):
- 获取当前参数。
- 查表:检查该参数是否已经在
fibonacci_dp 中。
- 命中 (Hit):直接从字典中取出结果,写入寄存器/内存,并跳过函数的执行(修改 RIP),直接返回。
- 未命中 (Miss):将当前参数压入临时栈
tmp_dp,并继续执行函数体。
处理函数出口 (On Leave):
- 当函数执行完毕即将返回时,从
tmp_dp 栈中弹出对应的参数。
- 获取此时的计算结果(RAX/内存)。
- 记录:将
(参数) -> (结果) 存入 fibonacci_dp 字典,供后续调用使用。
2. 完整代码实现
(注:完整的优化代码已在前面的“完整可运行代码”部分集成,此处不再重复列出,核心是 hook_code 函数中标记为 [B] 算法优化部分 的逻辑。)
3. 运行结果
加入记忆化搜索算法后,原本需要数小时的计算过程被瞬间完成:
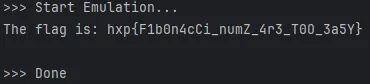
通过 Unicorn,我们在没有修改任何二进制文件的情况下,仅通过 Python 脚本就实现了对目标程序算法的动态热补丁 (Hot Patching) 优化。
参考文章
本文由云栈社区分享,希望这份从基础到实战的 Unicorn 框架指南能帮助你快速上手这一强大的二进制分析工具。
 发表于 2026-1-18 11:27:03
|
查看: 201|
回复: 0
发表于 2026-1-18 11:27:03
|
查看: 201|
回复: 0
