
你的 Mac 桌面,很可能蕴藏着一股未被充分释放的 AI 算力。
苹果 M4 芯片内置的神经网络引擎(ANE)在官方定位中,被严格限制在推理场景,其底层硬件访问权限近乎完全封闭。然而,近期一项开源项目打破了这一局面。
开发者巧妙地借助 Claude Opus 等工具,对 Apple Silicon 的底层驱动进行了逆向工程。成果令人惊讶:他们不仅在这块被定义为“纯推理”的芯片上,成功运行了一个拥有 1.1 亿参数的 Transformer 模型的完整训练流程,更测得了一组颠覆认知的性能数据。
实测显示,在优化后的流水线上,单步训练耗时仅需 9.3 毫秒。而其能效比更是达到了惊人的 6.6 TFLOPS/W——这意味着,执行单次浮点运算的能效,据估算可达英伟达 A100 GPU 的 80 倍。
01. 绕过CoreML:直通底层硬件
通常情况下,开发者通过 CoreML 框架来调用 ANE。但 CoreML 会在模型执行前,插入超过 30 层的黑盒抽象与优化过程(Espresso/E5RT),这无疑增加了延迟和不确定性。
为了直接触及硬件,开发者采用了动态链接器信息分析(dyld_info)与 Objective-C 方法交换等技术,成功拦截并揭示了底层的调用链。最终,苹果的私有框架 AppleNeuralEngine.framework 及其核心入口 _ANEClient 浮出水面。
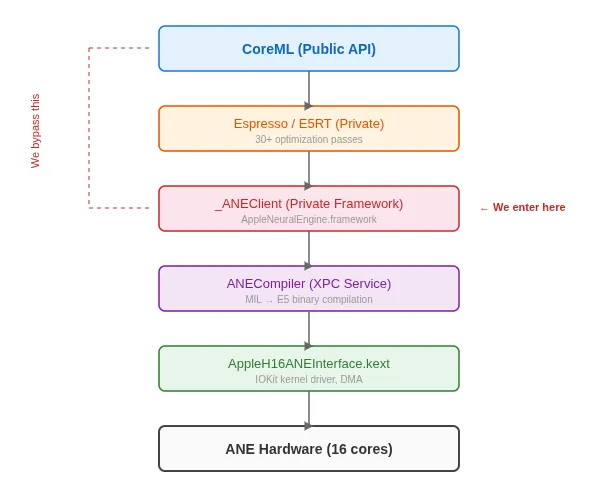
被还原的 ANE 完整软件栈,跳过 CoreML 直接调用私有框架
追踪进一步发现,CoreML 提交给 ANE 的并非 ONNX 等常见格式,而是一种名为 MIL(Model Intermediate Language)的中间语言。这种中间语言随后会被 ANE 编译器编译为专有的 E5 二进制格式。
program(1.3) [buildInfo = dict<string, string>({"coremltools-version", "9.0"})] {
func main<ios18>(
tensor<fp16, [1, 1024, 1, 1024]> x,
tensor<fp16, [1, 1024, 1, 1024]> w
) {
bool tx = const()[val = bool(false)];
bool ty = const()[val = bool(false)];
tensor<fp16, [1, 1024, 1, 1024]> out = matmul(transpose_x = tx, transpose_y = ty, x = x, y = w);
} -> (out);
}
MIL 中间语言代码示例
在训练场景下,模型权重需要频繁更新。如果沿用常规的文件路径,每次权重变动都会触发一次从 MIL 到 E5 的编译,并且必然涉及磁盘 I/O,这种延迟在训练中是无法接受的。
为此,开发者挖掘出了私有 API _ANEInMemoryModelDescriptor。利用该接口,可以直接在内存中完成 MIL 字节流的编译与加载,彻底绕开了文件系统带来的性能瓶颈。
02. M4 ANE架构与性能极限
获得直接调用权限后,一系列纯净的基准测试揭示了 M4 ANE 的真实硬件特性。
对比数据清晰地表明,对于小规模算子(如矩阵乘法),通过 CoreML 调用会带来 2 到 4 倍的性能惩罚(主要由延迟开销导致)。只有绕过抽象层,直接与硬件对话,才能释放其全部潜力。
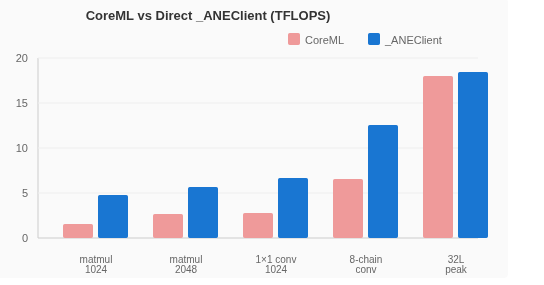
相同算子在 CoreML 与直接调用下的性能对比
测试发现,当矩阵乘法的工作集(约24MB)能够完全驻留在片上缓存(SRAM)时,ANE 可以达到 5.7 TFLOPS 的峰值算力。一旦工作集增大至约96MB,开始向 DRAM 溢出,性能便会骤降30%。
这种平滑的性能下降曲线暗示,ANE 采用了类似多级缓存(Cache)的架构,而非简单的固定大小便笺内存(Scratchpad)。由此反推,其片上缓存容量大约为 32MB。

矩阵乘法吞吐量与工作集大小关系图,清晰展现了突破 32MB SRAM 容量后的性能断崖
苹果官方宣称 M4 ANE 的算力为 38 TOPS。但实测显示,其 FP16 与 INT8 数据类型的性能完全相同。这说明硬件原生仅执行 FP16 计算,所谓的 INT8 支持只是在数据加载时进行反量化,以节省内存带宽。因此,其真实的物理算力极限应为 19.0 TFLOPS (FP16)。
此外,ANE 专为深层、复杂的计算图设计。对于单次计算操作,其算力利用率仅为 30% 左右;而当计算图链接了 16 到 64 个操作时,利用率才能达到 94% 的峰值。同时,其硬件支持高达 127 的队列深度,专为高吞吐的流式计算而生。
在峰值负载下,ANE 的整体功耗仅为 2.8W,从而实现了 6.6 TFLOPS/W 的超高能效比。

M4 ANE 与其他处理器的能效比对比
在空闲状态,硬件会瞬间切断电源,实现功耗的绝对归零。
在彻底弄清硬件特性后,团队将目标转向了一个实际的 AI 模型:拥有 1.1 亿参数的 Stories110M Transformer。
单层 Transformer 被拆解为 6 个 ANE 核心 Kernel,整个 12 层模型单次编译就需要构建多达 72 个 Kernel。
然而,要让这块为“推理”而生的芯片跑通“训练”所需的反向传播,必须跨越三个系统级的深坑:
1. 固化权重与 119 次编译死局
在 macOS 26.3(M5芯片)上的深入测试证实,ANE 在编译时会将权重数据“写死”在编译结果中,且其执行频率对系统的 QoS 调度完全免疫。
这意味着训练中每次权重更新,理论上都需要触发一次重编译。但 ANE 编译器存在底层资源泄漏问题,单个进程大约编译 119 次后就会崩溃。
项目代码引入了一个底层的系统级 Hack:在累积 10 步梯度更新后,强制保存检查点(checkpoint),然后通过 exec() 系统调用自我重启进程,在物理层面实现训练的连续性。
// Check compile budget
if (g_compile_count + TOTAL_WEIGHT_KERNELS > MAX_COMPILES) {
for (int L=0; L<NLAYERS; L++) { free_layer_kernels(&kern[L]); free_kern(sdpaBwd2[L]); }
double wall = tb_ms(mach_absolute_time() - t_wall_start);
save_checkpoint(CKPT_PATH, step, total_steps, lr, last_loss, ...);
printf("[exec() restart step %d, %d compiles, loss=%.4f]\n", step, g_compile_count, last_loss);
fflush(stdout);
execl(argv[0], argv[0], "--resume", NULL); // <--- 强行自我覆盖重启进程的核心
perror("execl"); return 1;
}
2. 重构异构计算流水线
苹果原生提供的 SDPA(缩放点积注意力)硬件算子不支持因果掩码(causal mask),这是训练自回归模型所必需的。
为此,代码被迫将注意力机制的计算拆解,在 CPU 与 ANE 之间进行极限接力:先在 ANE 上并发计算 $Q \times K^T$,将结果传回 CPU 处理因果掩码和 Softmax,然后再送回 ANE 完成与 $V$ 的乘法。
3. 极致压榨异构算力
为了消除不必要的数据转置开销,CPU 侧的内存布局被重构,以完美对齐 ANE 硬件偏好的“通道优先”(Channel-first)格式。
同时,利用苹果的 vDSP 加速框架重写了 RMSNorm 算子,实现了约 10 倍的加速。还通过“前向抽头”技术,直接暴露注意力分数等中间隐藏状态,避免了在反向传播时的重复计算。
最终,权重梯度更新被推入 GCD(Grand Central Dispatch)后台异步队列,与 ANE 的前向计算实现流水线重叠。经过一系列极致优化,单步训练时间被压缩至 107 毫秒。

终端训练 Dashboard 展示
04. 结语
基于对 ANE 底层机制的深刻掌握,这项研究也为 M4 平台的大语言模型推理指出了最佳调度策略:异构协同。
具体而言,可以将大规模批处理的“预填充”(prefill)阶段交给高吞吐的 ANE 处理,而将延迟敏感的“单 Token 解码”(decode)阶段交给几乎没有调度开销的 CPU SME 模块。
这项工程实践证明,Apple Silicon 在终端侧的巨大能力潜力,此前很大程度上受限于其封闭的软件生态。一旦底层的硬件访问权限被打开,其真实的硬件实力才得以彻底释放。
完整的研究代码与基准测试脚本已在 GitHub 开源社区发布,为后续的探索者提供了宝贵的参考。
想要深入了解 AI 模型训练优化、硬件底层奥秘的开发者,欢迎在 云栈社区 的 人工智能 和 开源实战 板块进行更深度的交流与探讨。
参考文献
[1] Inside the M4 Apple Neural Engine, Part 1: Reverse Engineering. https://maderix.substack.com/p/inside-the-m4-apple-neural-engine
[2] Inside the M4 Apple Neural Engine, Part 2: ANE Benchmarks. https://maderix.substack.com/p/inside-the-m4-apple-neural-engine-615
[3] GitHub. https://github.com/maderix/ANE
 发表于 2026-3-4 06:34:55
|
查看: 293|
回复: 0
发表于 2026-3-4 06:34:55
|
查看: 293|
回复: 0
