说起GUI Agent,最尴尬的时刻往往不是简单的误操作,而是它执行了一连串看似合理的动作后,将你带回任务的起点——仿佛在重复上演数字版的《土拨鼠之日》。
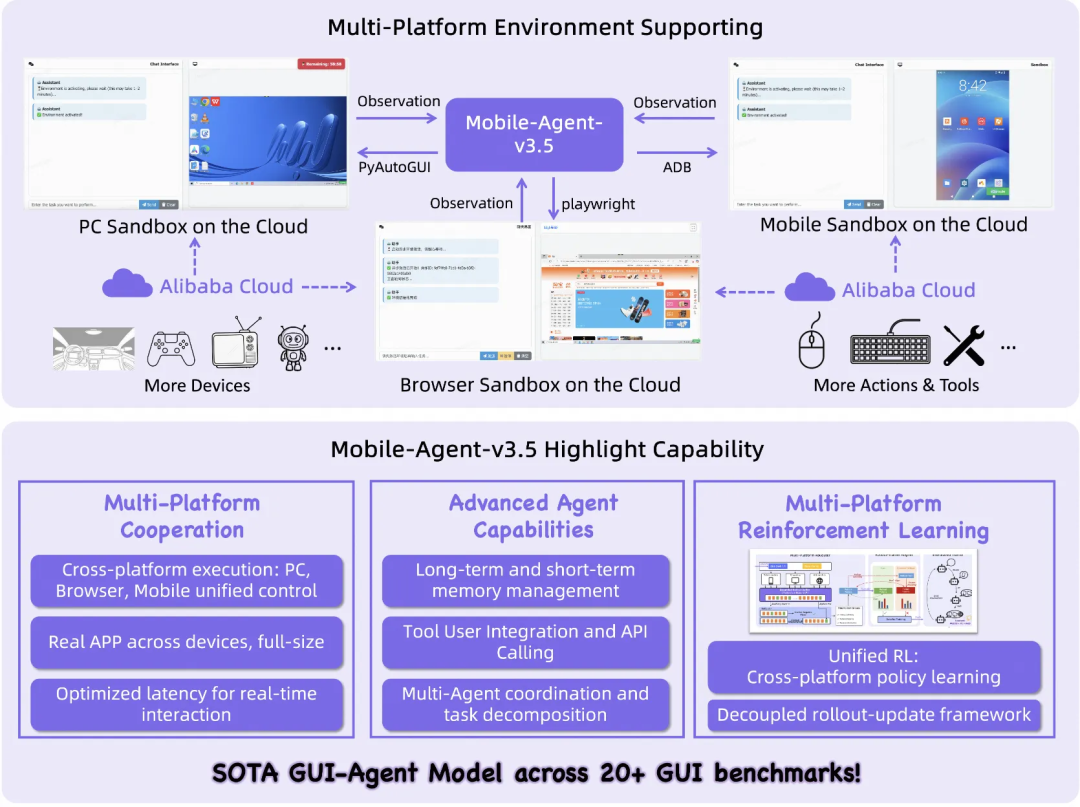
为了解决这个核心痛点,阿里通义实验室正式开源了Mobile-Agent-v3.5框架,并发布了新一代多平台GUI Agent基座模型家族 GUI-Owl-1.5。这套模型旨在实现桌面(PC)、移动端(Mobile)和浏览器(Browser)的跨平台统一自动化操作,提供了从2B、4B、8B、32B到235B的多种参数量规格,并包含面向快速执行的Instruct版本和具备深度思考能力的Thinking版本。
项目已在GitHub开源:
https://github.com/X-PLUG/MobileAgent
论文标题:
MOBILE-AGENT-v3.5: MULTI-PLATFORM FUNDAMENTAL GUI AGENTS
论文链接:
https://arxiv.org/abs/2510.19325
直面真实场景的三大挑战
现有许多GUI Agent在演示中表现流畅,但在复杂的真实环境中常常捉襟见肘。主要挑战集中在三个方面:
数据采集困难:长任务轨迹的人工标注成本极高,且真实环境中的验证码(CAPTCHA)、反爬机制、网络异常等问题频发,导致高质量数据获取艰难。
多平台冲突:手机、桌面和网页的应用在界面布局、交互逻辑和动作空间上存在显著差异。将这些异构平台的数据简单混合训练,容易导致模型学习目标冲突,效果相互抵消。
能力要求全面:真实的自动化任务远不止于“点击按钮”。它通常需要模型具备工具调用(Tool Calling)、记忆管理、知识查询甚至多智能体(Multi-Agent)协同等高级能力,才能完成端到端的工作流。
GUI-Owl-1.5的目标正是将智能体从“会执行原子操作”升级为“能可靠完成复杂任务”。它不仅要在高分辨率、多窗口的专业软件界面上精准定位,还要具备记事、反思、调用工具等综合能力,并在多端训练中保持稳定高效。
模型家族:快速执行与深度思考的组合拳
GUI-Owl-1.5并非单一的“巨无霸”模型,而是一个覆盖不同场景需求的模型家族。
- Instruct版本:包含2B、4B、8B、32B规格。该版本不输出中间思考链,直接生成可执行动作,主打低延迟和高效率,非常适合在资源受限的边缘设备上部署,满足实时交互的需求。
- Thinking版本:包含8B、32B、235B规格。该版本具备更强的规划、推理和反思能力,通过生成详细的思考链来应对复杂、多步的长周期任务。
这种设计天然支持“端云协作”的实用范式:轻量级的Instruct模型部署在终端,负责高频、快速的界面操作,保证响应速度和用户隐私;强大的Thinking模型部署在云端,负责复杂的任务分解、规划与事后复盘。这种组合让整个系统更像一个可落地的产品方案,而非单一的演示原型。
执行机制:从GUI操作到工具调用的多面手
GUI-Owl-1.5将GUI任务建模为一个多轮决策循环:观察(Observation)- 思考/执行(Action)- 再观察的迭代过程。
其输出采用两段式设计:
- Action Conclusion:用自然语言简要描述当前步骤要达成的目标。
- Structured Tool Call:输出结构化的、可执行的具体指令,例如点击(Click)、输入(Type)、滚动(Scroll)、拖拽(Drag)等。更重要的是,它支持调用外部工具和Model Context Protocol(MCP)接口。
这意味着,该模型不仅能遵循UI流程进行操作,还能在必要时跳出界面,主动调用外部API或工具来补全任务闭环,例如查询数据库、验证结果、写入日志或与其它系统进行协作。
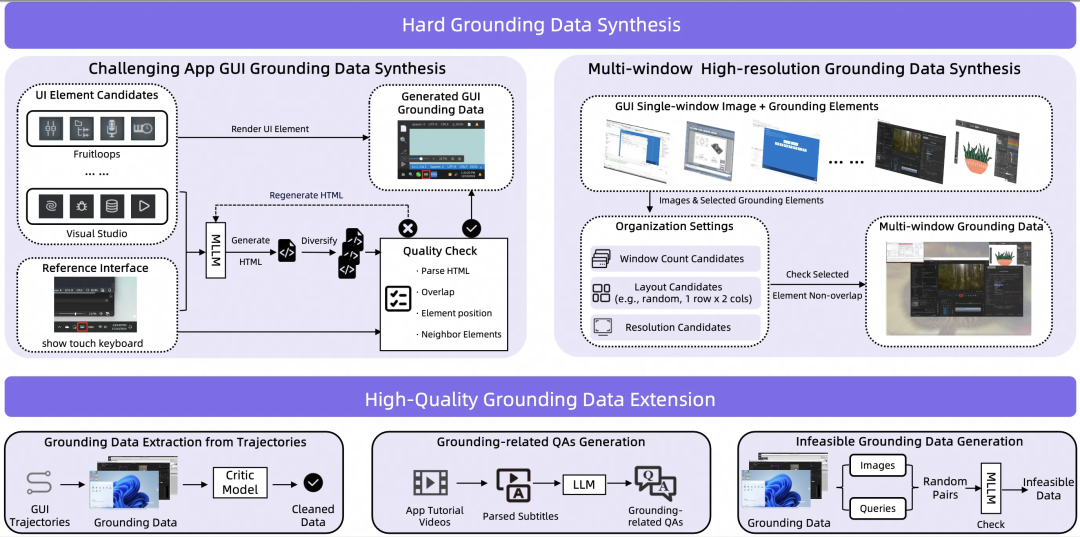
数据合成体系:攻克复杂界面的精准定位难题
要让模型在4K高分辨率屏幕、堆叠的多窗口以及专业软件(如Visual Studio)的复杂界面中准确识别和定位目标元素,高质量的数据至关重要。
为此,团队构建了一套针对GUI场景的Grounding(元素定位)数据增强体系,重点解决分辨率高、元素密集、窗口遮挡和专业界面晦涩等痛点。该体系包含两条主线:
1. 高难度场景合成
- 挑战性应用合成:针对复杂或专业软件,基于参考界面和UI元素标注,利用多模态大模型(MLLM)生成逼真的软件截图,并通过严格的质量检查(如元素重叠、位置合理性校验)迭代优化,确保数据的可信度。
- 多窗口高分辨率合成:将单窗口截图与标注好的元素,结合随机的窗口数量、布局(如1行×2列)和分辨率组合,生成多窗口场景数据。过程中会检查确保目标元素在不同窗口布局下不被遮挡。
2. 规模化数据扩展
- 从轨迹中挖掘:从真实或仿真的操作轨迹中自动提取
grounding数据对(图像-元素),并使用批评者(Critic)模型过滤低质量样本。
- 生成相关问答:从应用教程视频的字幕或知识库中,提炼生成与界面元素定位相关的问答(QA)数据。
- 生成负样本:专门合成“不可行”的
grounding负样本(例如要求点击一个不存在的按钮),训练模型在找不到目标时能够正确判断并停止,而不是胡乱点击。
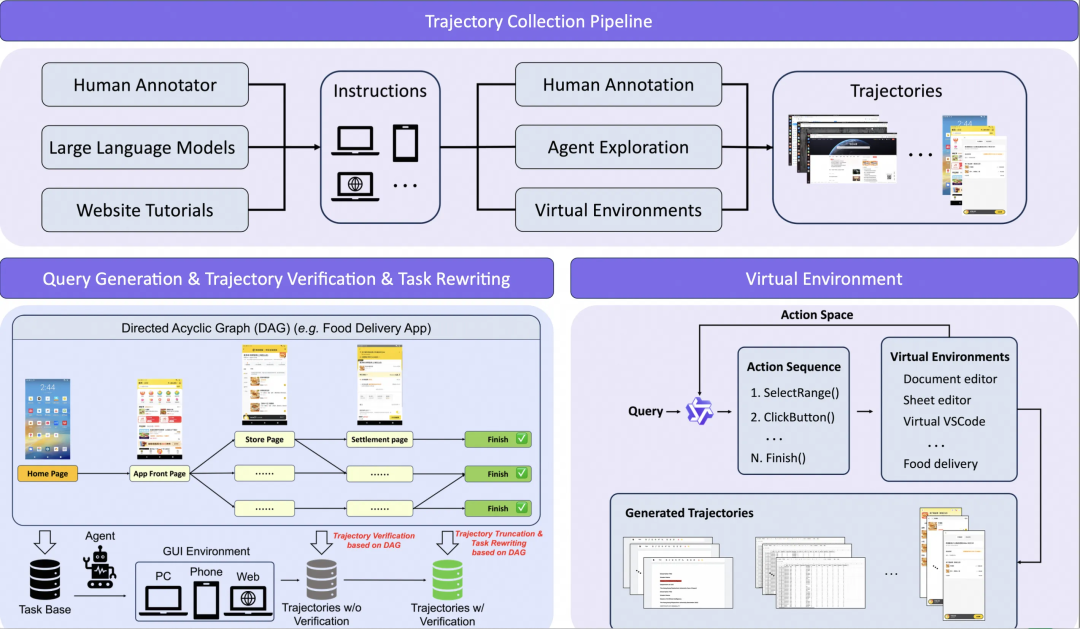
长轨迹生成:用DAG取代随机探索
为了保证长程、多步骤任务轨迹的质量和逻辑性,团队引入了有向无环图(DAG) 来组织任务流程。图中的节点代表子任务,边代表子任务间的可达关系。
具体流程如下:
- 在预先定义好的DAG上采样一条任务路径,并生成相应的自然语言指令,以覆盖真实的高频工作流。
- 在真实设备或云端沙箱环境中自动执行(Rollout)该任务。
- 每个子任务都设有检查点(Checkpoint)谓词来判断是否成功完成。成功则收录轨迹;失败则截断至最后一个正确的检查点,并将剩余未完成部分交给修复流程处理,从而确保用于训练的监督信号是干净、准确的。
- 对于极其困难的案例,则辅以少量的人工示范进行补充。
此外,为了应对真实网页环境中的验证码、反爬机制导致轨迹中断的问题,团队还构建了Web-Rendering虚拟环境。在这个可控环境中,可以精确获取子任务完成信号,并能通过脚本或RPA工具低成本、大批量地生成高质量的原子操作轨迹(如文档编辑、表格处理等)。
能力增强:赋予智能体助理级的“思考力”
仅仅模仿人类的下一步点击动作,很容易将智能体训练成只有“手速”没有“脑力”的操作员。为了让其真正像助理一样工作,团队从三个维度进行了能力增强:
1. 注入GUI领域知识
从软件官方文档、社区教程、技术论坛和问答平台爬取相关信息,经过清洗和重写,构建为问答对或视觉问答数据。这让模型获得了“软件常识”,知道特定功能通常位于哪里,常见的操作路径是什么,以及如何将用户的自然语言描述映射到具体的界面操作。
2. 学习状态变化预测
从成功的操作轨迹中构造“动作-状态转移”描述数据:给定当前屏幕截图和执行的动作,让模型学习预测下一屏幕会发生什么变化(如弹出对话框、文本更新、焦点转移等)。这赋予了模型在行动前预判结果的能力,是其进行规划的基础。
3. 统一思维链合成
将轨迹的每一步都增强为结构化的推理过程,包括:
- 观察:提取与当前任务相关的屏幕关键信息。
- 记忆:决定需要将哪些信息写入长期或短期记忆。
- 反思:判断动作结果是否符合预期,如果不符合则进行纠错推理。
- 进度更新:明确当前任务的整体进展。
- 工具推理:在需要时,给出选择调用特定工具或MCP接口的理由。
这种统一的Thought-Synthesis流程显著提升了模型处理长程任务的稳定性和可靠性。
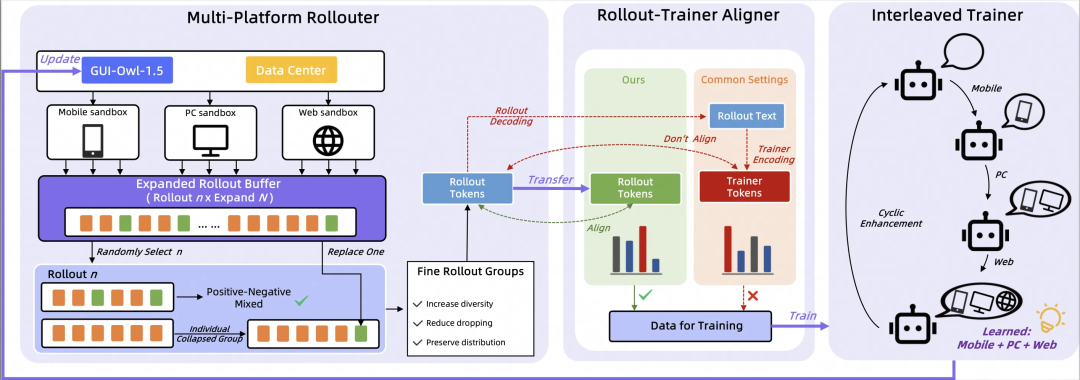
MRPO算法:解决多平台强化学习的“内耗”问题
在多平台统一的强化学习训练中,很容易出现两个问题:一是不同平台(移动、桌面、网页)的梯度更新方向相互冲突,导致训练震荡;二是在分组强化学习(如GRPO)中,同一组内的样本成功率要么全高要么全低,导致训练信号失效或方差过大。
为此,团队提出了 MRPO(Multi-platform Reinforcement Policy Optimization) 算法,其核心设计包括:
- 设备条件化统一策略:使用一个统一的策略模型处理所有平台,但通过显式地输入设备类型作为条件信号,让模型自适应地学习不同平台的交互模式差异。
- 在线滚动缓冲区:首先进行多轮
on-policy采样以扩充缓冲区,再进行分组。如果某小组样本同质化严重(全正或全负),则从缓冲池中随机替换一条样本,以增加组内多样性,同时保持on-policy特性。
- Token-ID传输对齐:在环境端执行模型推理后,不仅返回动作文本,还将对应的
token ID序列一并返回给训练器。这样,训练器可以使用完全相同的离散token序列计算对数概率,避免了因环境端与训练端分词器(Tokenizer)细微差异导致的KL散度或策略梯度估计偏差。
- 交替多平台优化:采用按平台轮换训练的方式,依次在移动、桌面、网页数据上进行优化,减少同步更新带来的“梯度拉扯”,有助于稳定收敛并保持良好的跨平台泛化能力。
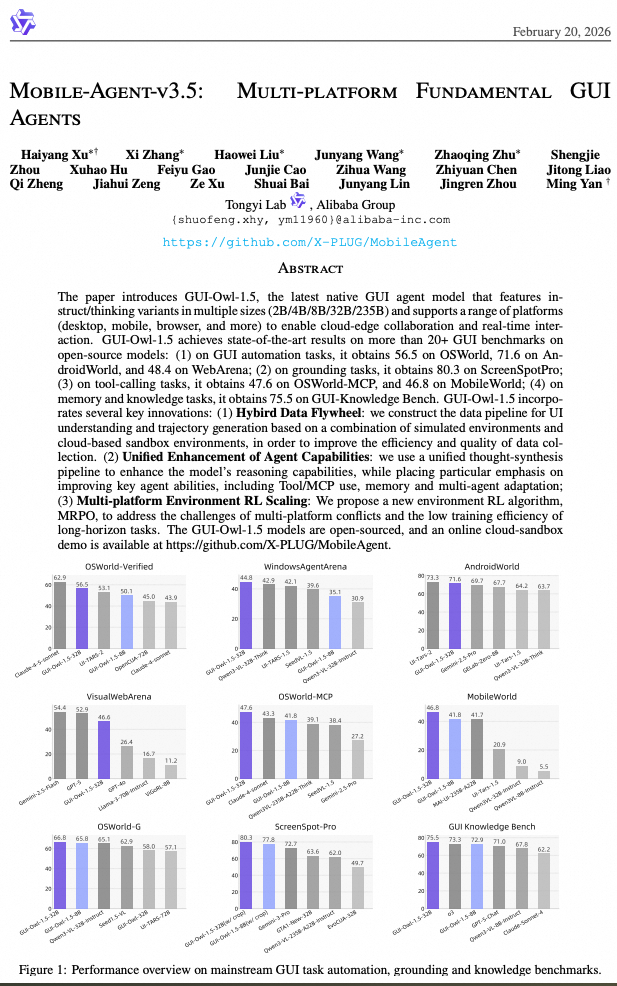
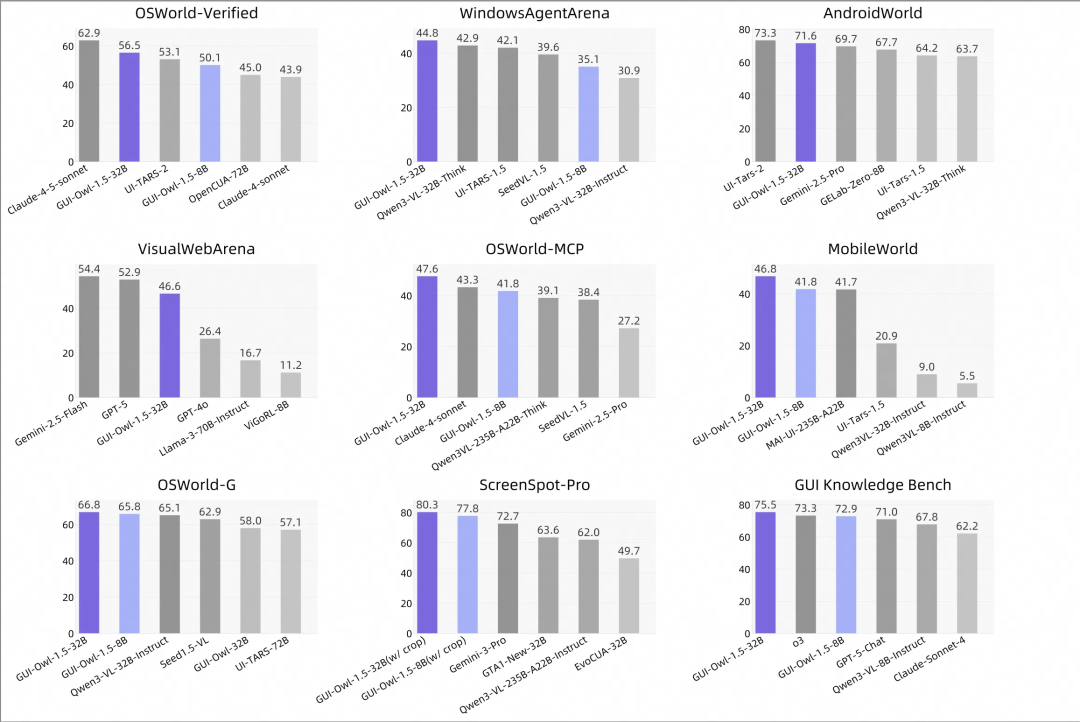
性能表现:在20+基准测试中达到开源SOTA
GUI-Owl-1.5在GUI自动化、元素定位、工具调用、知识与记忆四大方向上,覆盖了超过20个主流基准测试,并取得了领先的开源模型成绩。部分代表性结果如下:
端到端自动化
- OSWorld-Verified: 56.5 (32B-Instruct)
- AndroidWorld: 71.6 (8B-Thinking)
- WebArena: 48.4 (32B-Thinking)
- VisualWebArena: 46.6 (32B-Thinking)
工具/MCP调用
- OSWorld-MCP: 47.6 (32B-Instruct)
- MobileWorld: 46.8 (32B-Instruct)
高分辨率元素定位
- ScreenSpot-Pro: 72.9 (不使用裁剪)
- ScreenSpot-Pro: 80.3 (使用两阶段裁剪优化)
知识与记忆
- GUI Knowledge Bench: 75.5 (32B)
- MemGUI-Bench (Easy): 27.1 (在原生模型对比中显著领先)
总结与展望
如果你正在研究或开发面向计算机(Computer Use)、移动设备(Mobile Use)或浏览器(Browser Use)的自动化智能体,需要实现跨平台的统一控制,希望将GUI操作与工具调用、MCP协议结合以编排复杂工作流,或者正在寻找“轻量终端模型+强大云端模型”的协同部署方案,那么GUI-Owl-1.5模型家族及其Mobile-Agent-v3.5框架提供了一个值得深入评估的基座选择。
保证一个智能体永远不出错是极其困难的,毕竟人类操作员也会失误。但该团队的核心目标在于:让智能体在出错时能够自主察觉,并在察觉后能够有效纠正,从而避免将用户的宝贵时间浪费在无意义的循环操作上。这标志着GUI Agent正从“看起来聪明”的演示阶段,迈向“真正可用”的工程化阶段。对该开源项目感兴趣的研究者与开发者,可以访问其GitHub仓库获取模型、代码并参与社区建设。
 发表于 2026-3-4 06:38:57
|
查看: 228|
回复: 0
发表于 2026-3-4 06:38:57
|
查看: 228|
回复: 0
