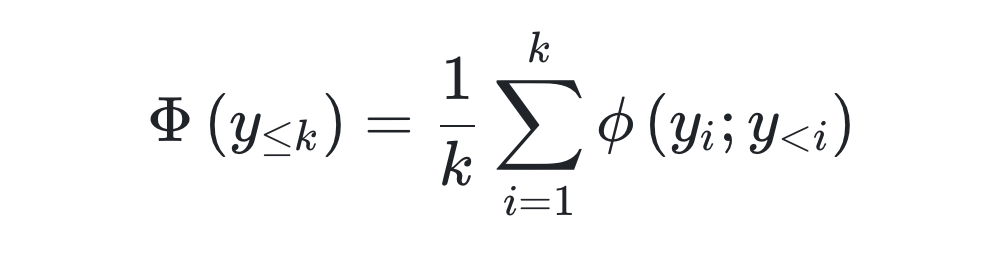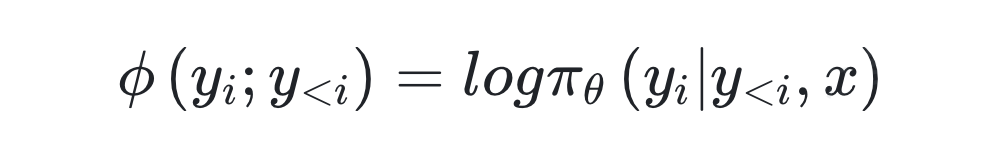大模型其实“心里有数”,天生具备高效推理的潜能,只是被我们习以为常的采样方法掩盖了。最近,北航与字节跳动的研究团队发表了一项研究,系统地揭示并激活了大模型的这项隐藏天赋。

论文标题:
Does Your Reasoning Model Implicitly Know When to Stop Thinking?
研究团队:
北航+字节跳动联合研究
论文地址:
https://arxiv.org/abs/2602.08354
项目主页:
https://hzx122.github.io/sage-rl/
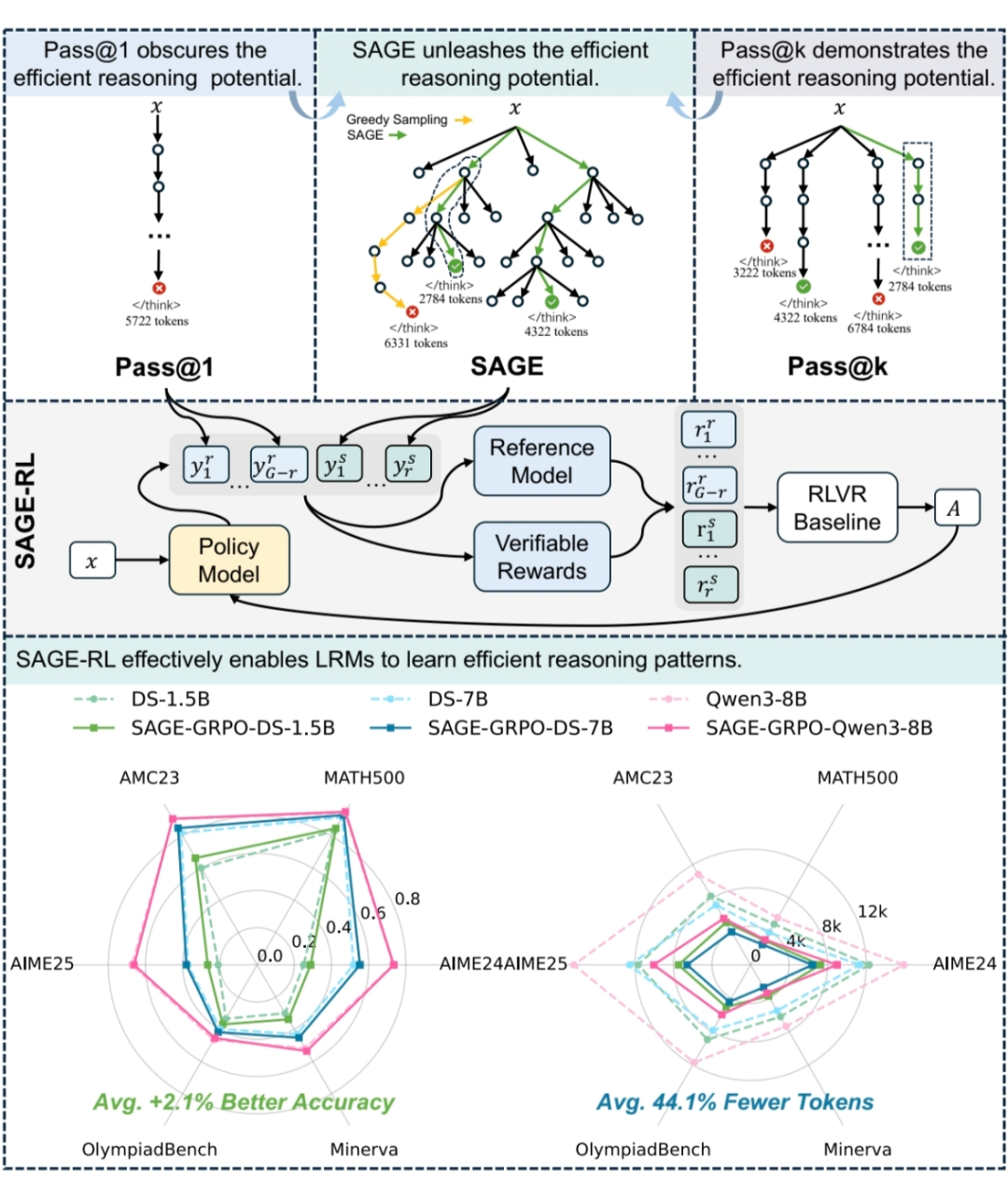
核心发现:被采样范式掩盖的“在合适时机终止思考”天赋
这项研究最核心的突破,是首次系统性证明了大推理模型天生具备判断推理终止时机的能力——它们能精准识别“已得出正确答案”的节点。然而,这种能力却被 pass@1 等主流采样范式所掩盖,导致推理过程充斥着大量冗余步骤。
这一发现并非偶然,而是通过五层递进的实验验证得出的核心结论,每一层都揭示了模型高效推理潜能的真实性与普遍性。
1. 悖论拆解:长推理链≠高正确率,冗余反而拖垮性能
长期以来,行业有一个默认认知:“更长的思维链(CoT)能带来更优推理结果”。但实验数据从定量角度揭示了这一认知的谬误。
多项独立研究验证了长度与正确率的脱钩关系:
- Balachandran 等人(2025)观察到,在 AIME 2025 数据集上,DeepSeek-R1 生成的回复长度接近 Claude 3.7 Sonnet 的 5 倍,却仅实现了相近的正确率。
- Hassid 等人(2025)在 AIME 和 HMMT 数据集上发现,QwQ-32B 的最短回复比随机采样回复少用 31% 的 token,正确率反而高出 2 个百分点。
- Shrivastava 等人(2025)则指出,在 AIME 2025 数据集上,72% 的问题中,更长的回复比更短的回复错误率更高。
这些发现共同表明,一旦思维链长度超过某个必要阈值,单纯增加长度并不会带来推理能力的提升,反而会因冗余步骤引入逻辑混乱,降低最终答案的可靠性。当前 CoT 输出中包含的大量无关 token 和重复验证步骤,不仅无助于正确性,还会大幅降低推理效率。
2. 关键证据:模型对“高效路径”的天然置信度偏好
通过对模型内部生成机制的解析,研究证实累积置信度(Φ)是模型判断推理有效性的核心信号。
核心公式定义
其中,π_θ(y_i | y_<i, x) 是模型在给定查询 x 和前缀序列 y_<i 下生成第 i 个 token y_i 的概率。
3. 范式缺陷:现有采样策略扼杀了模型的“自主终止”能力
尽管模型天生具备识别高效路径的能力,但当前主流的采样范式(尤其是 pass@1)存在致命缺陷,导致这一能力被完全掩盖。
首次正确步骤占比(RFCS):用于量化模型的高效推理能力,定义为正确答案首次出现的步骤索引与推理总步骤数的比值:

实验显示,在 pass@1 范式下,超过 50% 的样本在得出正确答案后,仍会生成数百个 token 的重复验证步骤。更关键的是,这一问题无法通过扩大模型规模来解决。
pass@k 范式虽能通过多轮采样发现少量“短且优”的有效推理链,但这些链被淹没在大量冗余样本中,需要额外计算成本筛选,无法直接应用于实时推理场景,本质上仍是对模型高效推理潜力的浪费。
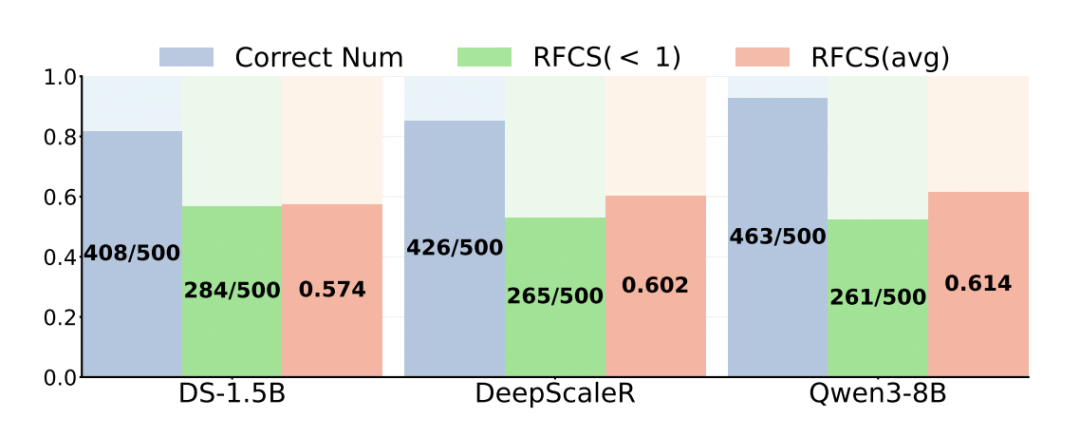
不同大推理模型在 MATH500 数据集上的首次正确步骤比(RFCS)统计结果
4. 模型对高效链的终止决策高度自信
模型对高置信度推理链的终止决策具有极高的鲁棒性,这一特征通过终止容忍度(TR)敏感性分析得到了验证。
终止容忍度(TR):表示模型对思考结束 token </think> 排名的容忍程度。当终止 token 的排名在 top-h 范围内时,模型会接受该终止决策;否则,会丢弃该候选序列。
实验显示,基于 Φ值 的终止决策不受外部参数干扰,是模型内在能力的体现。
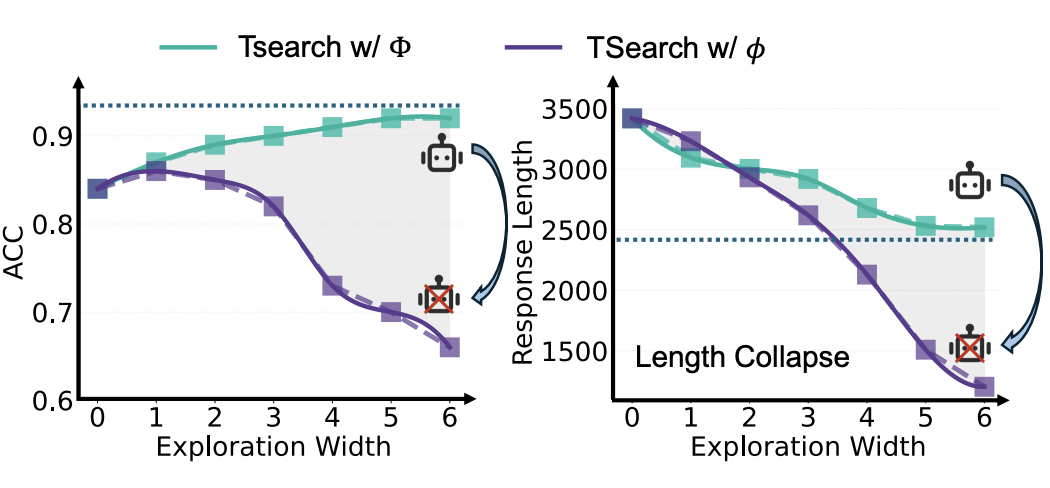
随着探索宽度增加,TSearch 不同变体的性能对比
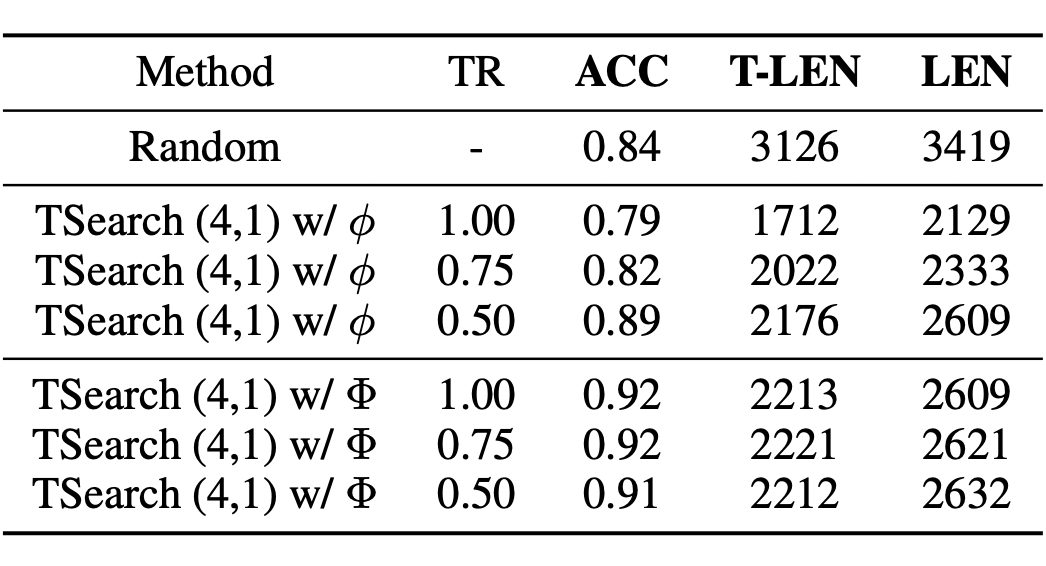
不同 TR 下 TSearch 变体的性能对比
进一步分析发现,随着探索宽度增加,TSearch w/Φ 识别出的终止 token </think> 在候选 token 集中的排名始终稳定在第 1 位,表明模型对高效推理链的终止决策高度自信。
而 TSearch w/φ 中终止 token 的排名随探索宽度增加逐渐上升,显示模型对冗余链的终止决策充满不确定性。
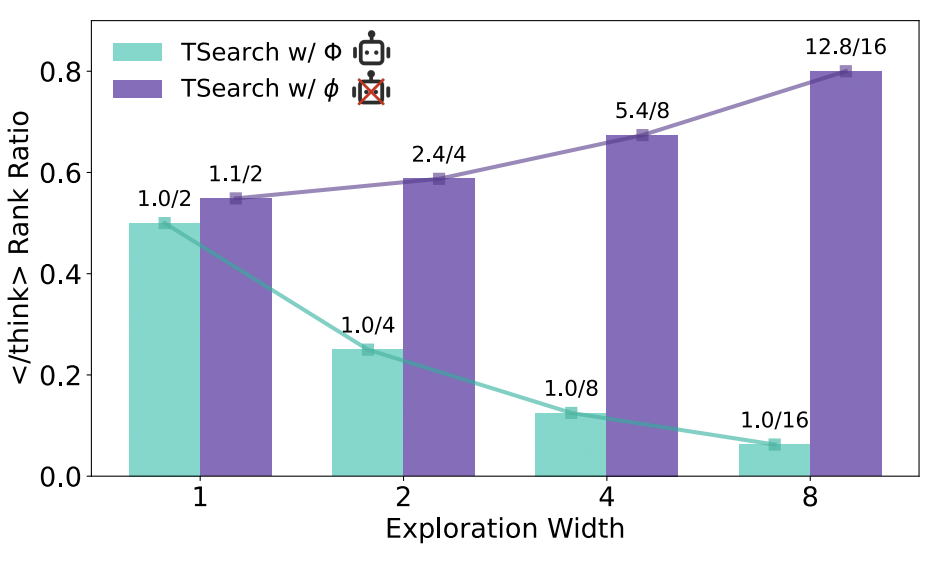
思考终止符出现在候选集 T 中时的平均排名比率
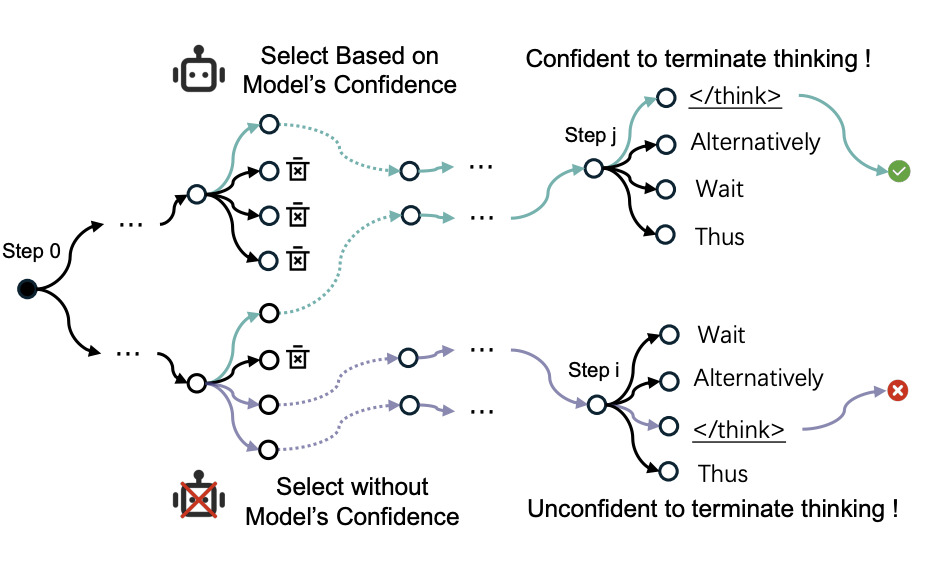
当根据模型在每个扩展步骤的置信度保留推理分支时,模型能够以高置信度完成推理
5. 收敛验证:探索空间扩大时,模型的高效推理能力更显著
研究进一步发现,当给予模型足够的探索空间时,其“自主终止”能力会呈现明显的收敛趋势。
在充足的 token 预算下,采用 TSearch (m, 1) w/Φ 作为采样策略,随着探索宽度 m 的增加,模型的 pass@1 持续提升,同时响应长度持续缩短,两者均逐渐收敛至最优值。这一趋势证明模型的高效推理能力是稳定且可被充分激活的。
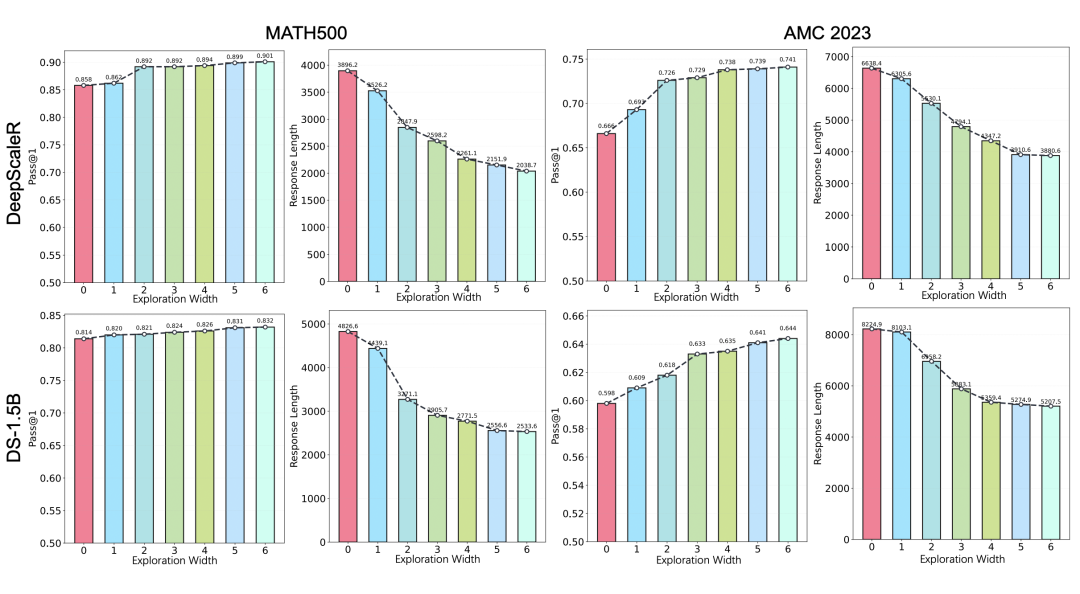
在所有设置下,pass@1 和响应长度均随探索宽度(EW)收敛
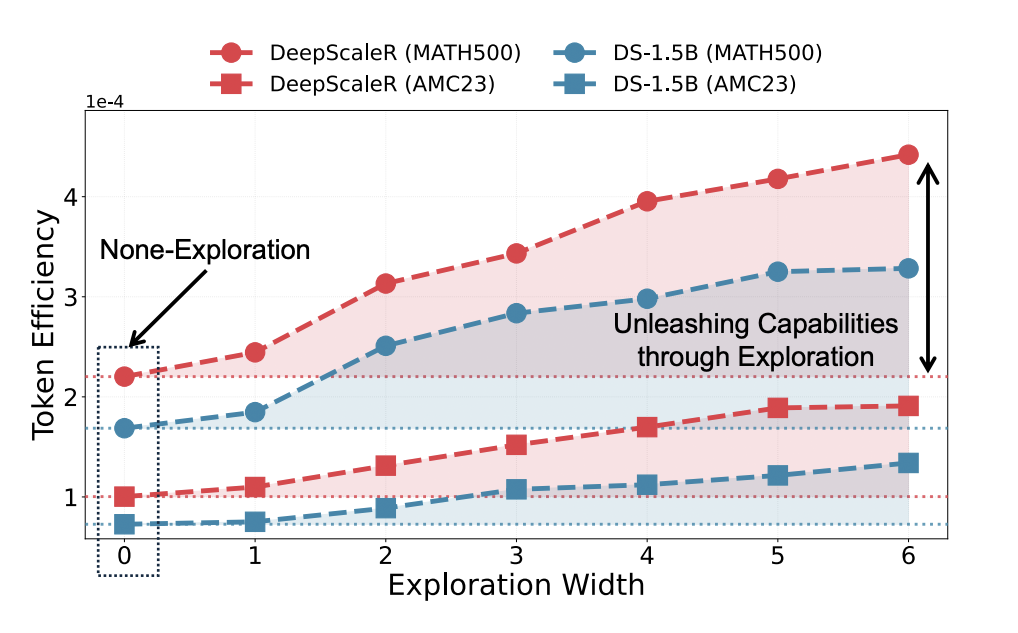
不同探索宽度下 token 效率(pass@1/LEN)对比
方法概述:释放高效推理潜能的极简方案(SAGE & SAGE-RL)
基于上述核心发现,研究提出了一个轻量化的解决方案,无需修改模型结构,核心目标是“解锁”模型天生的高效推理能力。
2.1 SAGE:自感知引导的高效推理
SAGE 的设计完全围绕“尊重模型自主判断”展开,基于 TSearch w/Φ 优化而来。
关键设计
-
累积置信度(Φ)计算:
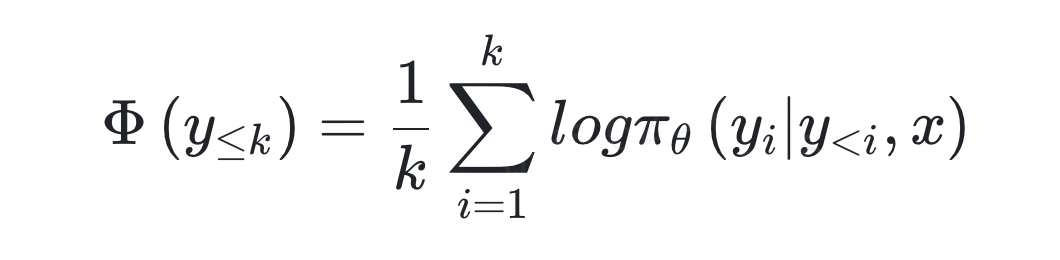
-
步阶式推理链探索:按“推理步骤”扩展候选链,而非逐 token 盲目生成。在第 i 步,每个候选序列通过采样 2m 个推理步骤进行扩展:
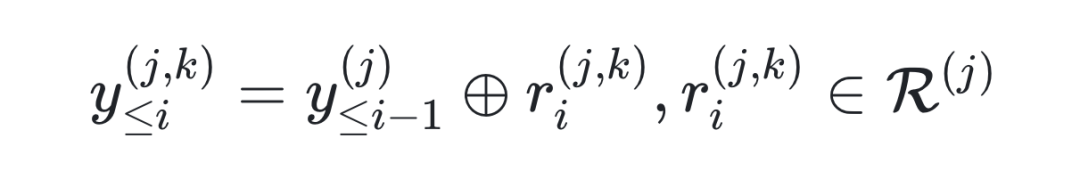
其中,R^{(j)} 是基于查询 x 和前缀 y_{≤i-1}^{(j)} 随机采样的 2m 个推理步骤的集合。
-
置信度驱动推理终止:无需手动设置 TR 参数,当候选序列的推理步骤以终止 token </think> 结束时,直接将其加入完成集,因为高置信度推理链必然伴随自信的终止决策。
-
生成最终回答:生成 r 条推理链后,基于查询和推理链贪婪解码出最终答案。
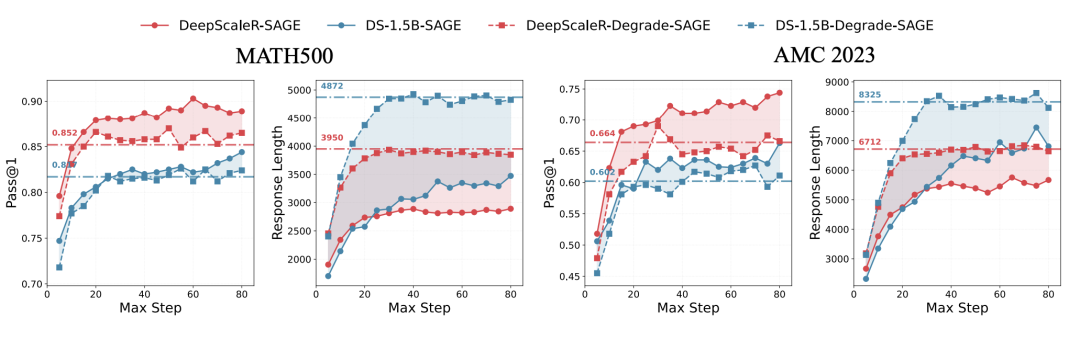
2.2 SAGE-RL:高效推理模式迁移
为了让模型在标准的 pass@1 推理中也能持续保持高效,研究将 SAGE 融入了强化学习框架(RLVR),仅需修改 rollout 阶段,用高效样本引导模型固化“自主终止”的习惯,无需改动现有 RL 框架,部署成本极低。
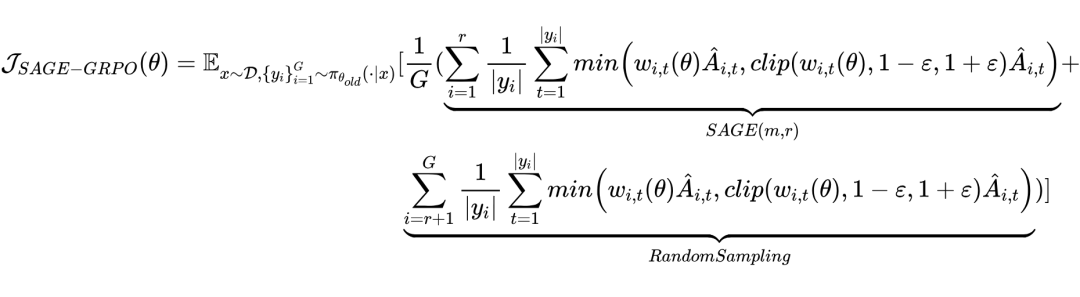
核心公式(基于 GRPO/GSPO 扩展)
-
SAGE-GRPO 目标函数:
-
SAGE-GSPO 目标函数:
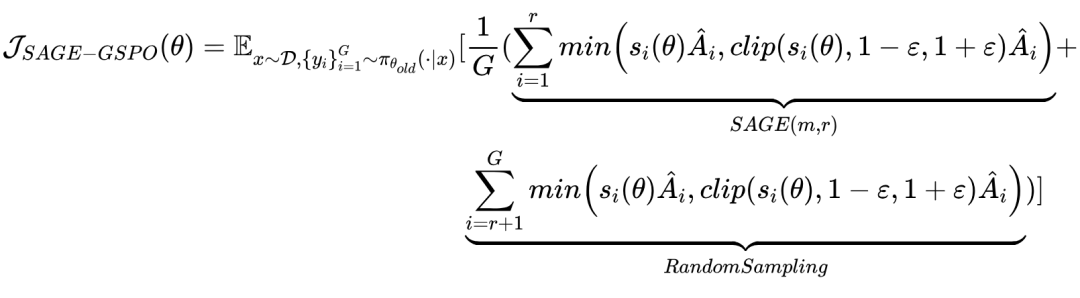
其中,G 为每组生成的回复数,r 为 SAGE 采样的高效推理链数,w_{i,t} 为 token 级重要性权重,s_i 为序列级重要性权重,Â_{i,t} 和 Â_i 为优势函数。
实验:核心发现的全方位佐证
所有实验均围绕“验证模型天生具备高效推理潜能”展开,覆盖了 6 个具有挑战性的数学推理数据集,四种基座模型和 GRPO、GSPO 两种基于组的强化学习算法,验证了核心发现的普适性。
佐证一:SAGE-RL固化效果显著
SAGE-RL 微调后,各个模型的 RFCS 平均值显著提升,同时准确率也有了显著提高。这表明模型已成功将 SAGE 的高效推理模式迁移到了标准的 pass@1 推理中。
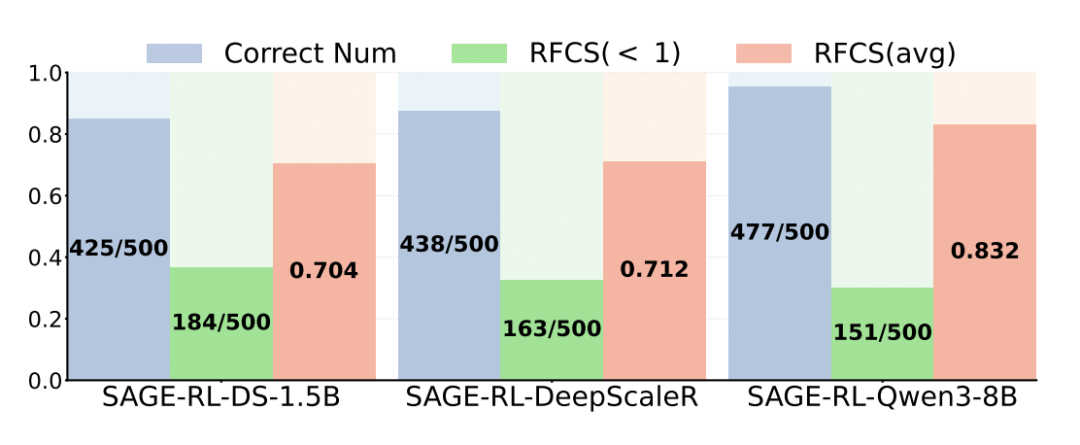
SAGE-RL 训练后的模型在 MATH500 数据集上的首次正确步骤比(RFCS)统计结果
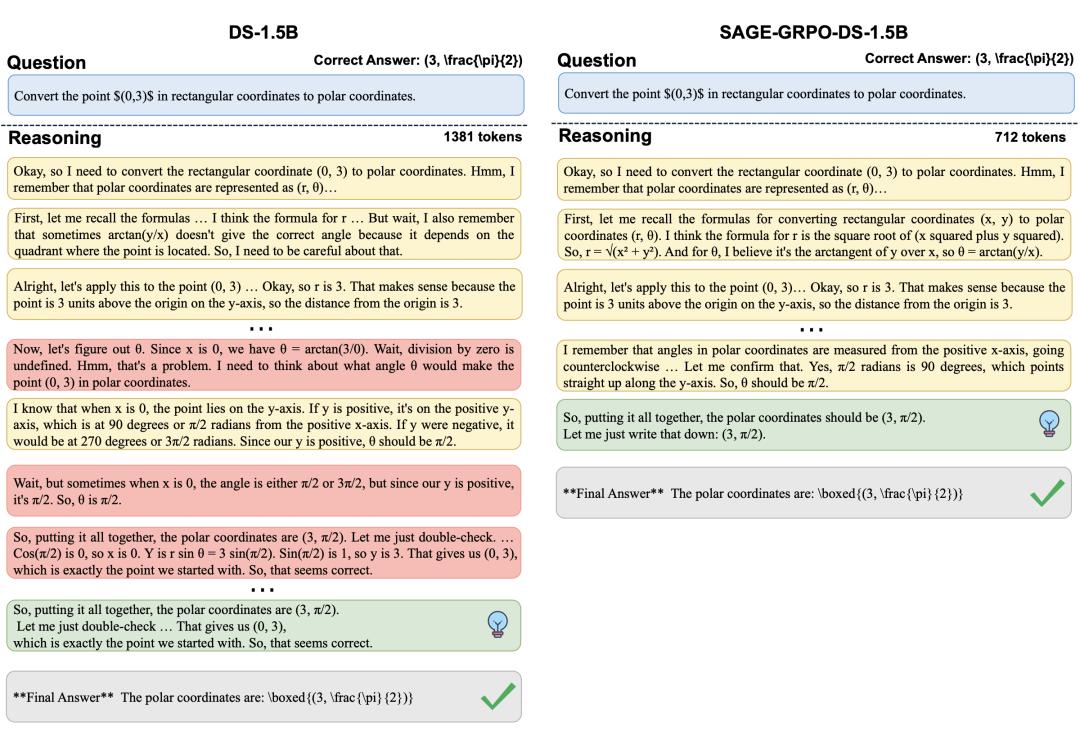
案例1:SAGE-GRPO-DS-1.5B 在显著缩短推理步骤的同时得出正确答案
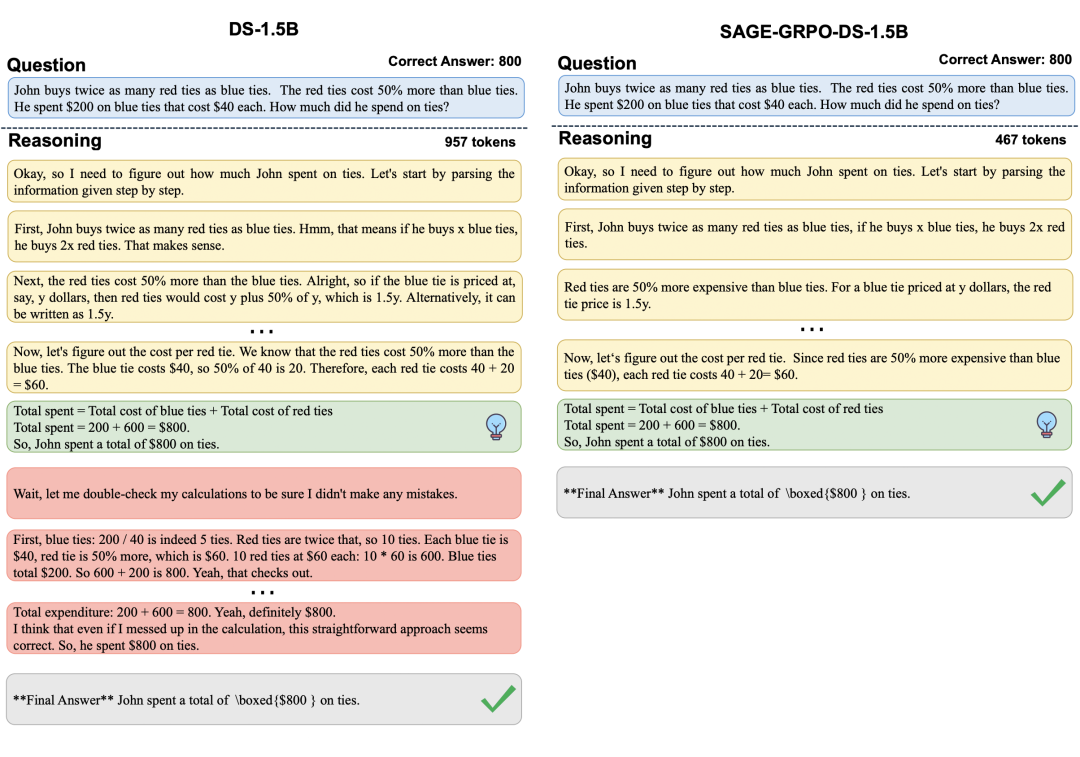
案例2:SAGE-GRPO-DS-1.5B 的推理更加简洁直接
佐证二:全维度性能领先
SAGE-RL 在所有数据集上实现了正确率、简洁度、token 效率的全面领先:平均正确率提升 2.1%,平均 token 数减少 44.1%,token 效率(Pass@1/LEN)均为最优或次优。
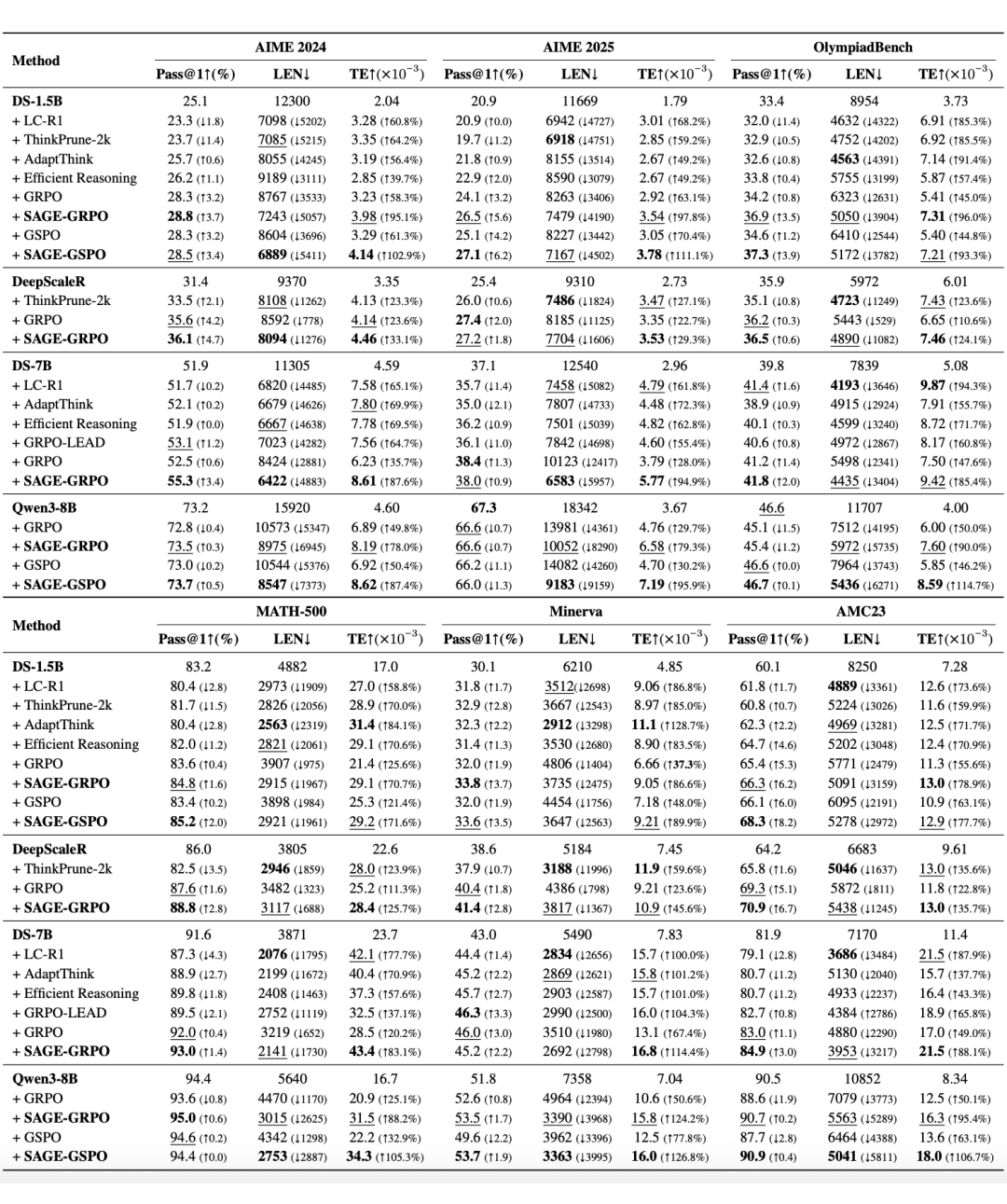
六个基准数据集和四个基础模型在使用不同方法前后的 pass@1 准确率、响应长度(LEN)和 token 效率(TE)结果。
- 精度提升更快:Pass@1 指标上升速度更快,且收敛至更高数值。
- 长度持续缩减:回复长度在整个训练过程中不断下降,没有平台期。
- 熵值降低更显著:策略对高效推理链的置信度更高。
- KL 散度更高:策略从原始分布偏移,习得了 SAGE 的高效推理模式。
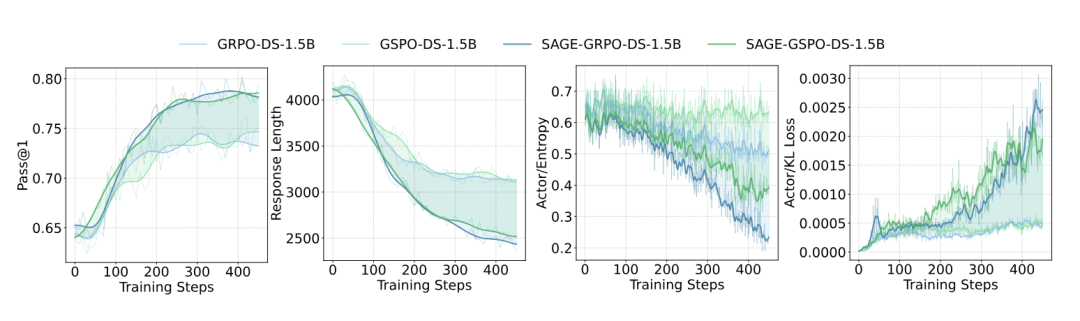
RLVR 和 SAGE-RL 的训练动态对比
佐证三:超参数与复杂度分析
- 超参数敏感性:当每组的采样轨迹数
r 从 1 增加到 2 时,模型性能提升有限。但当探索宽度 m 从 1 增加到 2 时,模型在性能和效率上均实现了显著提升。有限的 m 会导致 SAGE-RL 的优化行为趋近于标准 GRPO,这证实了探索宽度在激活模型高效推理能力方面的关键作用。在不同的超参数组合中,SAGE (2,2)-GRPO 展现出最优的综合性能。

DS-1.5B 模型在 SAGE-GRPO 不同参数设置下的实验结果对比。其中 SAGE (m, r) 表示探索宽度为 m,最终保留 r 条不同的轨迹。
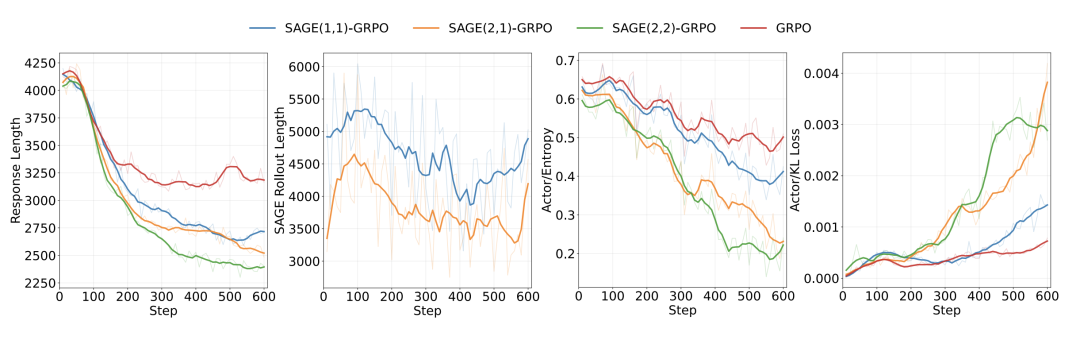
不同超参数组合下 SAGE-GRPO 的训练动态对比
- 时间复杂度:SAGE 基于 vLLM 实现,当
m ≤ 2 时耗时增长平缓,当 m > 2 时,推理时间的增长速度会加快。因此,研究主要将探索宽度 m 设为 2,这是推理时间慢增长区域与快增长区域的转折点,能够在效率与性能之间实现良好平衡。SAGE-RL 微调后的模型在标准 pass@1 推理中,平均延迟降低了 28.7%,多数场景降幅超 40%。
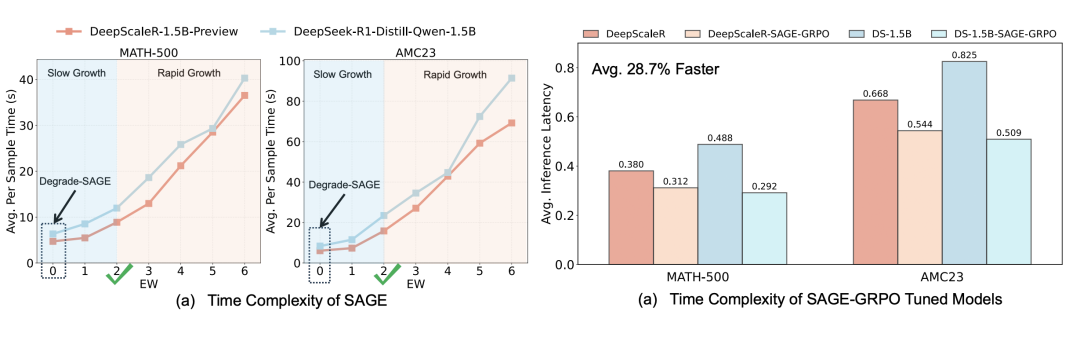
结论
- 大推理模型的高效推理潜力是与生俱来的,只是被现有采样范式掩盖。
- 累积置信度(Φ)是模型自主终止能力的核心信号,能精准识别“短且优”的推理路径。
- 轻量化的 SAGE 与 SAGE-RL 能有效解锁并固化这一天赋,且适用于各类推理模型,具有极强的普适性。
- 研究重塑了对大模型推理行为的认知——与其教模型如何高效推理,不如让模型释放内在的高效推理潜能。
应用价值
基于核心发现诞生的解决方案,可直接应用于实时推理、低资源部署、高难度数学/逻辑推理等核心场景,在大幅降低推理耗时、计算成本的同时,提升推理正确率,有望真正推动大推理模型从“实验室”走向“工业化”。
代码获取:请联系 huang_zx@buaa.edu.cn
这项研究为优化大模型的推理效率提供了一个全新的视角,即相信并利用模型自身的能力。对强化学习和模型高效推理感兴趣的朋友,可以在云栈社区的人工智能和开源实战板块找到更多相关的技术讨论与源码分析。
 发表于 2026-4-15 01:36:25
|
查看: 173|
回复: 0
发表于 2026-4-15 01:36:25
|
查看: 173|
回复: 0