近期有诸多传闻称,DeepSeek将在春节前发布新一代模型。结合DeepSeek过去几年的研究路线,本文尝试对DeepSeek-V4的模型架构进行预测。首先回顾其研发路径,探讨模型的Scale逻辑,进而推测新架构可能的技术方向。关于注意力机制,DSA、mHC与Engram的组合已是明牌,但本文更想尝试理解其背后的设计理论与核心Know-How。
1. 稀疏是整个主旋律
纵观DeepSeek从诞生至今的技术演进,一条清晰的脉络是针对不同模型组件的稀疏化处理。其背后的逻辑非常朴素:由于内存墙的存在,计算可以相对容易地Scale,而访存则非常困难。我们先来回顾一下整个发展脉络。
1.1 MoE
模型的稀疏化之路始于MoE,通过精细化的专家(Fine-Grained Expert)处理实现。详细的演进可以参考相关文章《详细谈谈DeepSeek MoE相关的技术发展》。
- DeepSeek-V1 MoE:引入了Fine-Grained Expert,并放置了一个独立的共享专家(Shared Expert)。利用辅助损失函数实现了专家的负载均衡与设备的负载均衡。V1模型包含64个路由专家和2个共享专家,topk=6。
- DeepSeek-V2 MoE:将路由专家总数增加到了160个,共享专家保持2个,topk=6。相对于V1,增加了设备限制路由(Device-Limit Routing)和通信负载均衡的辅助损失,并引入了一些Token丢弃策略。
- DeepSeek-V3 MoE:路由专家数量扩展到256个,共享专家减为1个,topk=8。引入了专家分组和无需辅助损失函数的负载均衡机制,取消了Device-Limit Routing和Token丢弃策略。同时,开发了新的DeepEP通信范式,配合冗余专家(Redundancy Expert)和EPLB完成负载均衡。
至此,针对前馈神经网络(FFN)的稀疏化MoE处理告一段落。
1.2 Attention
那么,下一个Scale的目标自然就落到了Attention上。Attention的计算复杂度为 O(n²d)。随着现代大模型推理任务对上下文长度的要求越来越高,构造稀疏注意力(Sparse Attention)便成为首要考虑。这不仅是计算复杂度的优化,也因为密集注意力存在“概率稀释”问题:即使模型对某个选项有较高的置信度,在经过Softmax归一化后,其最终概率也会被稀释,导致整个概率分布更平坦。
在文章《谈谈DeepSeek Native Sparse Attention》中已有分析,其核心思想是朴素的:能否构建一个函数将键值对(KV)映射到一个低维空间?更早的MLA(Multi-head Latent Attention)便是通过压缩KV来降低访存带宽。随后,NSA进一步优化了这一思路。
在此之前,业内已有多种稀疏注意力方案,例如基于哈希、随机或池化的方法,总带着些传统机器学习中特征工程的味道。DeepSeek在NSA论文中评价道,这些方案要么包含不可训练的组件,要么在反向传播阶段效率低下。
而DeepSeek的NSA方案则非常直接:
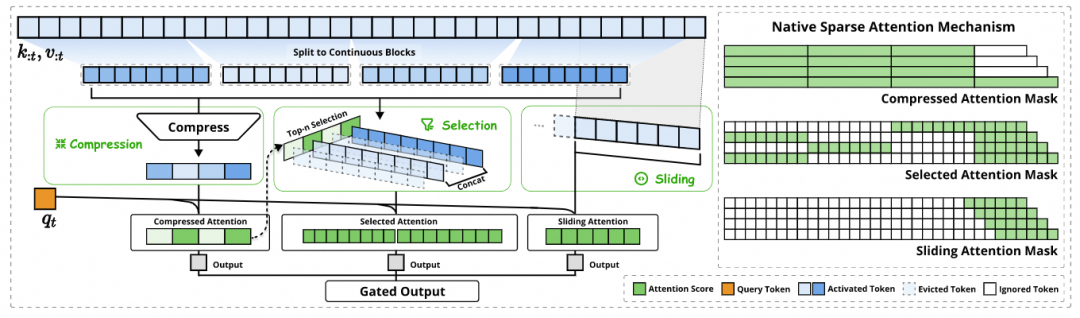
- 压缩(Compression):部分尽量获得全部输入的一个摘要。
- 滑动(Sliding)窗口:获得最近上下文关注的注意力焦点。
- 根据top-n选择(Selection):巧妙地将压缩过程中损失的重要细粒度信息补了回来。
此后,DSA出现并应用于DeepSeek-V3.2。相对于NSA,DSA做了大量简化:将块选择(block selection)改为词元级别的选择(token wise selection),并用一个小规模的索引器(indexer)计算top-2048个词元。通过继续预训练的方式,先在完整MLA上预热索引器,再利用KL散度将索引器输出与主注意力分布对齐。
这其实也是处理稀疏注意力的一种常见手段。去年愚人节的一篇文章《谈谈一个新的MoA模型架构DeepSick-4.1T》也玩笑式地提到了通过自KL散度来衡量稀疏注意力效果,以对齐完整注意力分布。
当然,工业界在此路径上存在分歧,例如Qwen和Kimi选择了线性注意力(Linear Attention)。
2. 预测一下DeepSeek-V4的模型架构
其实,最近的mHC和Engram论文已经透露出一些端倪。在此之前,我们不妨先假装没读过这些论文,尝试猜测背后的逻辑。进一步Scale该如何处理?简单地为MoE堆砌更多参数吗?在Engram论文之前,这种观点确实存在。但专家数量过多后,训练中会出现更多“死亡专家”,通信压力也会剧增。因此,通过MoE进行Scale的收益将越来越难获得。
那么,目标自然又盯回了Attention。此外,DeepSeek似乎有一种“Tick-Tock”的节奏:V1引入MoE后,V2修改Attention构建了MLA,V3又改进了MoE。似乎到了V4,又该轮到修改Attention了。
预计整个Attention的结构将基于 DSA + mHC + Engram 构建。
稀疏注意力在某种意义上解决了计算复杂度 O(n²d) 中与 n 相关的问题。但我们很自然地会想:如何在不增加计算复杂度的情况下进行Scale?例如扩大 d(维度)。一个直觉的想法是,构建一个旁路网络结构,在一个高维空间进行稀疏处理后再降维,但不扩展Attention自身的维度。这个想法在2024年读DeepMind的TransNAR论文时就曾出现。
正如那篇文章最后谈到的,我们期望有一个旁路的稀疏运算,甚至可以卸载(Offload)到CPU,然后通过跨越多层旁路注入的方式。结合起来,便是mHC与Engram。从微观角度看,N-gram本身也是一个稀疏的图。
实际上,Seed团队最早做出了一版HC,但同时也有过度编码(Over-Encoding)的问题,在工程落地的细节上,特别是训练稳定性和效率方面,存在许多未妥善处理的问题。
2.1 谈谈mHC
[mHC的一些详细分析可以参考相关文章。其实mHC中的“流形约束”一词有些夸大其词了,本质上我更愿意称其为双随机矩阵约束HC。但我想,DeepSeek可能是想说明流形约束的方法或范式可以应用于其他地方。例如,考虑一个由 n 个参数定义的分布族,所有这些分布构成一个 n 维几何空间,形成一个“统计流形”。对于流形上的两个点,其测地线距离、曲率或Fisher信息度量相关的约束,可能会应用到其他地方,例如在RL后训练阶段做一些离策略(Off-policy)处理以提升训练速度。
回到mHC上,基于Sinkhorn-Knopp迭代算法的处理非常巧妙,但也很难想到。一些做图模型相关的同学可能对SK算法更熟悉。在LLM领域,除了早期的Sink Attention以及去年的一篇《Scaled-Dot-Product Attention as One-Sided Entropic Optimal Transport》,真的很难有人会想到从Birkhoff多面体的性质来如此优雅地处理HC的训练稳定性问题。
2.2 谈谈Engram
详细介绍可参考相关文章。 其本质是解决早期如DeepMind的Mixture-of-Depths和Mixture-of-Recursions等工作中发现的问题:标准Transformer模型在计算资源分配上效率低下。传统Transformer对序列中的每个词元都施加相同的计算量,而MoD让模型学会动态、有选择地将计算资源分配给序列中最重要的词元。
然而,递归注意力虽然在模型参数不变的情况下等效地增加了模型深度,但Engram对于一些计算量需求偏低的Token任务做了更巧妙的处理。它通过将N-gram嵌入到上下文中,以更轻量级的方式增加了复杂词元的注意力运算预算。
另一方面,Engram做得非常巧妙的一点是,其多头哈希操作仅有 O(n) 复杂度,卸载到CPU的处理对推理也非常友好。同时,将N-gram嵌入到原始上下文时使用的门控机制巧妙地利用了注意力机制本身:
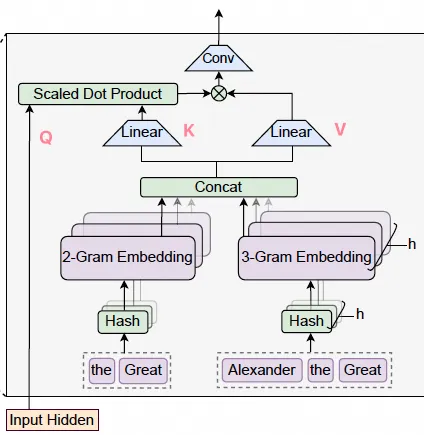
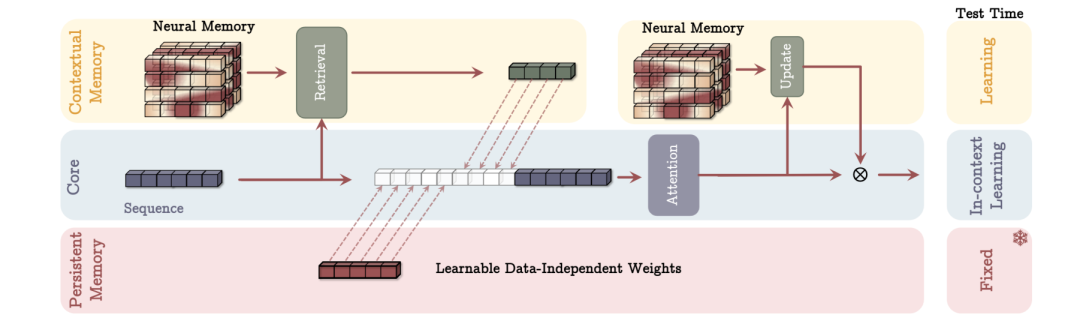
当然,目前的Engram还是一个比较静态的记忆模块,不知未来是否会演进到类似Google提出的“测试时学习”相关范式:
3. 对DeepSeek-V4模型做一个整体的预测
3.1 Attention
从当前公开的资料来看,基于 DSA + mHC + Engram 构建Attention模块基本上算是明牌了。
3.2 MoE
MoE的结构估计在这一代模型中不会有太大变化,更多的Scale可能从Engram的视角去实现。
3.3 模型的参数
从Engram的论文来看,假设总参数能够适配小规模的8卡服务器(例如H20/H200)平台,那么Attention + MoE的参数量应该可以Scale到约1.5T。这主要受限于GPU显存容量和算力约束。按照激活参数量估计,会达到约70B,这也是一个推理速度较快的模型范围。
然后是Engram的参数规模。考虑到CPU内存容量,其规模应该可以Scale到1T左右。也就是说,累计模型参数规模大约可以做到2T ~ 2.5T。
大致计算如下:模型的隐藏层维度(Hidden_size)可能会进一步扩展到12K到16K。因为有DSA处理,维度的增加对算力消耗是可控的。然后配合mHC(假设n=4)应该会带来很大的性能提升。
模型的层数应该还是在60层左右,层数过长可能会影响训练效率。
另一方面,其实在DeepSeek-V3推出时,我就曾设想是否能推出一个相对小的模型。例如,主干模型在120B附近,Engram约100B规模,整体模型规模在200B~300B左右。这样的模型对国产卡推理,或NV一些相对合规的卡、小规模的单机至4机部署非常友好。实际上,这个规模的模型对于很多ToC业务已经足够,也能承载大量的服务请求。真的很期待DeepSeek能发布一些小尺寸模型。
3.4 关于RL后训练
从去年的进展看,DeepSeek公开的强化学习相关工作不多,主要是GRM。
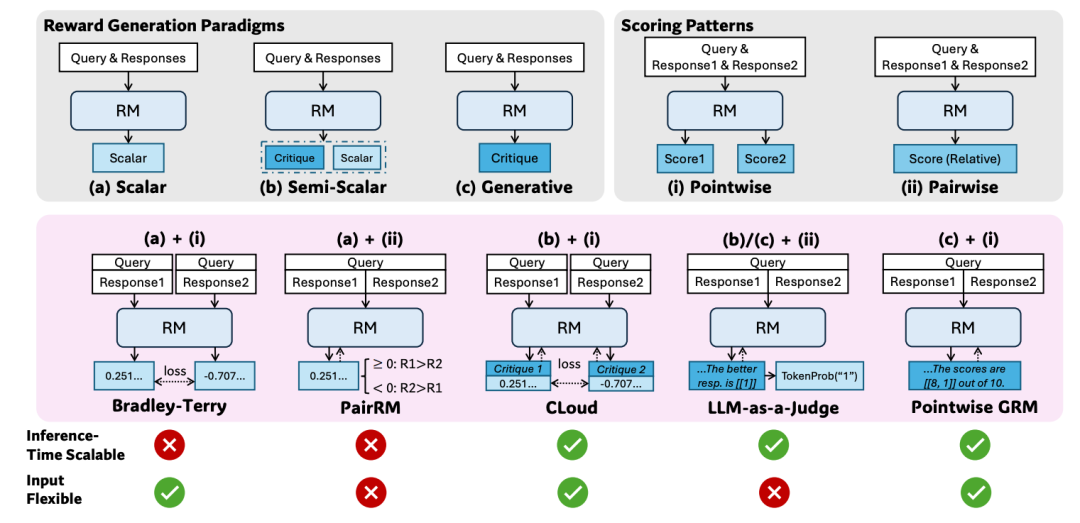
在通用的奖励模型设计上,GRM采用了让模型自己生成多维度打分评价体系的原则,并根据这些生成的原则来产生评论,再基于评论给出最终的点对点打分。这样的奖励模型设计巧妙地提高了模型本身的泛化能力。
另一方面,今年年初刷新DeepSeek-R1论文时,披露了一些训练时就采用的“训推对齐”方法R3。
其实,我非常期待DeepSeek能从流形约束的视角去处理一些强化学习相关的问题。特别地,当前很大程度上为了训练稳定性和效果,还是以同策略居多。如果我们不追求完全的训推对齐,而是采用一些流形约束的方法构建高质量的离策略数据,应该是一个非常 promising 的路径。
对前沿技术架构的推测总是充满挑战与乐趣,欢迎在云栈社区继续交流探讨。
 发表于 2026-1-19 13:46:01
|
查看: 291|
回复: 0
发表于 2026-1-19 13:46:01
|
查看: 291|
回复: 0
