还在为海量监控视频的存储成本头疼吗?每天产生的上百TB数据中,绝大部分画面其实都是静止的。为了那偶尔动态的1%,却要为100%的静态背景反复支付存储和带宽费用,这合理吗?
近期,中国电信人工智能研究院(TeleAI)在arXiv上发布了一项研究成果,论文题为《Enhancing Neural Video Compression of Static Scenes with Positive-Incentive Noise》。这项研究提出了一个新颖的思路:将视频中的动态变化视为“正激励噪声”,用以训练模型深刻记忆静态背景,从而在监控、视频会议等场景中,实现了高达73%的码率节省(BD-rate)。这不仅是一个算法突破,更是“以计算换带宽”产业趋势的精准落地。
静态场景压缩为何成为难题?
要理解这项研究的价值,首先得看看现有技术为何在静态场景上“失灵”。
传统视频编码器(如H.264/HEVC) 依赖于运动估计和补偿。对于动作丰富的视频,它们效率很高。但对于静态场景,每一帧都要重复编码几乎一模一样的背景,无法真正“记住”并重用背景信息,产生了巨大的冗余。
神经视频压缩(NVC)模型 作为AI时代的智能编码器,理论上能更聪明地压缩。但问题在于“训练偏差”。现有的先进NVC模型(如论文中作为基线的SSF模型)大多在动态丰富的通用视频数据集上训练。这让它们擅长处理剧烈运动,却对“几乎不动”的静态场景非常陌生。实验证实,在静态监控视频上,未经调整的NVC模型性能甚至可能不如传统的H.264。
那么,直接用生成式压缩方法行吗?这类方法能生成逼真纹理,但可能“无中生有”,改变真实细节。这在监控、视频会议、医疗影像等真实性至上的场景中是绝对不可接受的。我们需要的是像素级保真的压缩,而非艺术创作。
核心灵感:动态不是负担,而是“教学工具”
TeleAI的研究人员从机器学习领域获得了关键灵感:正激励噪声。这个概念由Xuelong Li教授在2022年系统阐述。与需要被滤除的干扰噪声不同,正激励噪声是一种有结构的、有益的扰动,被主动加入训练中以“磨炼”模型,使其学习更鲁棒、更本质的特征。
灵光在此刻闪现:视频中那些偶尔走过的人、开关的门、摇曳的树叶,不就是现成的、天然的正激励噪声吗?
我们不再将这些动态变化视为需要精确编码传输的核心信号,而是将它们视为一种帮助模型学习的“教学工具”。这些“噪声”激励模型去剥离变化,从而更深刻地理解和记忆那个不变的背景。
这一视角的转换至关重要。它把问题从“如何高效压缩动态”巧妙转变为“如何利用动态来学习静态”。
方法论:两阶段实现“背景先验”学习
基于上述思想,研究人员提出了一套简洁高效的模型微调(Finetuning)方法论,而非设计全新网络。整个过程分为学习和推理两个阶段。
阶段一:学习阶段 —— 让模型“记住这个房间”
假设在一个新会议室部署摄像头。在启用高效压缩前,先进行几天的学习。
- 数据准备:收集该摄像头拍摄的、包含正常活动(人员进出、灯光变化)的视频片段。这些动态即“正激励噪声源”。
- 模型初始化:选择一个预训练好的神经视频压缩模型作为起点。论文选用的是经典的端到端模型——SSF(Scale-Space Flow)。
- 微调训练:使用本地视频数据对SSF模型进行微调,目标仍是标准的率失真优化。
关键在于训练中模型内部发生的变化:模型反复看到同一个背景伴随不同的前景噪声。为了节省码率,它被强烈“激励”去在其网络参数中,构建一个关于该静态背景的强先验知识。这相当于模型“记住了这个房间的样子”,且这份记忆存储在模型权重中,无需通过网络传输。
阶段二:推理阶段 —— “背景在心中,只传变化”
模型学习完毕后,用于该场景的实时压缩。
- 分离:拥有“背景先验”的模型能轻松将新帧分解为“已知背景”和“未知动态”。
- 编码:对“已知背景”,几乎无需发送信息;仅对“未知动态”进行常规编码。
- 解码:接收端拥有同一个微调过的模型(同样记得背景),结合收到的动态码流,即可完美重建帧。
这就像两人拥有共同记忆,只需一句“老地方,有动静”就能传达丰富信息。该方法完美践行了“以计算换带宽”的理念,将学习背景的计算与传输动态的通信解耦。
实验结果:73%的BD-rate节省与视觉质量飞跃
理论需要数据支撑。研究人员自建了大规模静态场景数据集(超过132小时、2K分辨率监控视频)进行验证。
衡量压缩性能的关键指标包括:
- BPP:比特每像素,越低代表码率/文件大小越小。
- PSNR:峰值信噪比,越高代表重建质量越好。
- BD-rate:综合指标,负数表示在相同质量下节省码率。
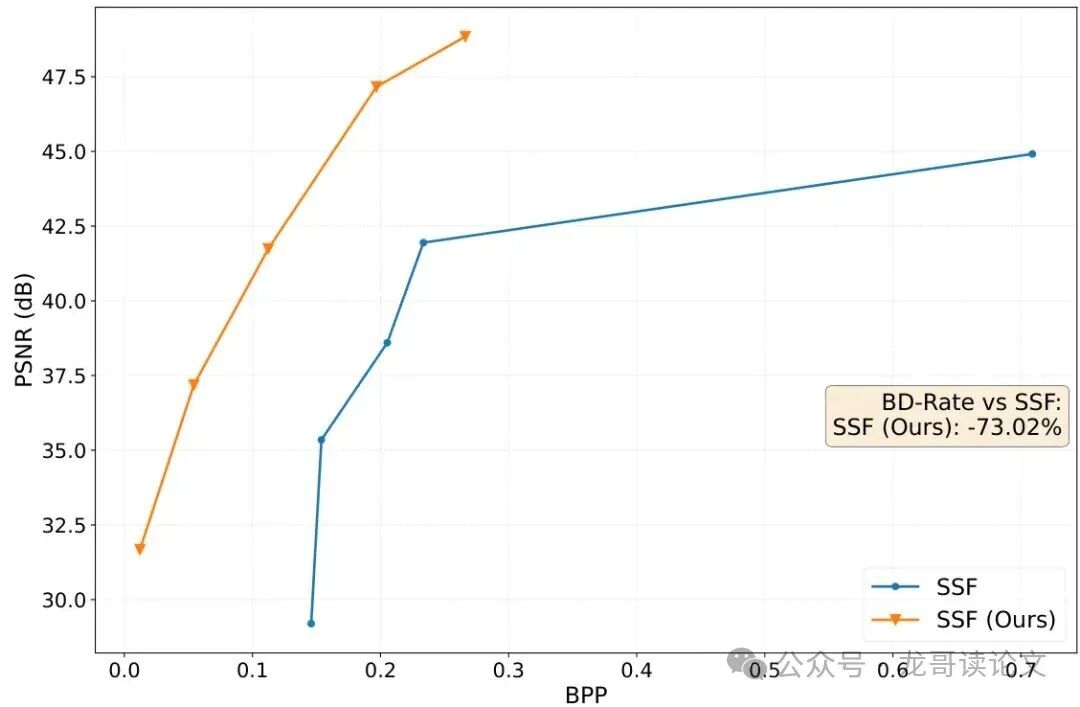
图:微调前后SSF模型的率失真曲线对比。提出的方法实现了73.02%的BD-rate节省。
结论令人震撼:经正激励噪声微调的模型,在所有质量档位上都实现了PSNR提升与BPP降低。最终的BD-rate节省达到了73.0%。这意味着,达到相同画质,新方法只需约原方法1/4的码率。
视觉对比更为直观。下图展示了在相同码率(~0.2 BPP)下,不同方法的重建效果,重点关注灭火器箱上的“FIRE”文字:

图:在相近码率下,H.264、原始SSF及微调后SSF模型的重建帧对比。基于正激励噪声的方法将PSNR从38.70 dB提升至46.27 dB。
- H.264:文字边缘存在模糊和块效应。
- 原始SSF模型:文字区域出现明显彩色条纹伪影,清晰度反而不及H.264,印证了“分布差异导致模型失灵”。
- 微调后SSF模型(本文方法):文字清晰锐利,边缘干净,伪影基本消失,视觉质量显著最优。
应用展望与思考
这项研究的价值超越单一算法,它清晰地展示了一种在AI与网络融合背景下的新资源权衡范式:以(前期的)计算换(长期的)带宽,以(本地的)学习换(总体的)节约。
- 监控存储:在摄像头或边缘服务器上用初期视频进行一次性微调,可换来长期高达73%的存储节约。
- 视频通话/直播:快速学习固定背景后,在网络拥堵时可只传输人脸、手势等细微变化,保障流畅度。
- 车路协同/物联网:路侧单元学习静态道路环境,仅传输车辆、行人等动态信息,减轻通信负担。
这种方法高度契合 “端-边-云”协同计算架构。当然,这仍是初步探索。如何实现快速、轻量的自适应微调以应对背景缓慢变化(如季节更替、室内装修),是未来的有趣挑战。这也引出了一个更深层的问题:在特定垂直场景中,我们是否应该更多地追求这种为特定任务优化的、高性能的专用人工智能模型,而非单一的通用模型?
核心问题解答
-
“正激励噪声”和普通噪声有何区别?
普通噪声(如高斯噪声)是随机、无结构的干扰,目标是被滤除。正激励噪声则是一种有结构的、有益的扰动,被主动引入训练以“磨炼”模型,鼓励其学习更鲁棒的本质特征。本文中,视频里的动态变化就被视作这种有益噪声。
-
BD-rate节省73%有多厉害?
BD-rate是视频编码领域衡量压缩性能增益的标准指标。73%的BD-rate节省意味着,在重建质量完全相同的情况下,新方法所需的码率只有原方法的约27%,或者说节省了超过三分之二的带宽/存储空间。在视频压缩领域,这通常是一个里程碑式的巨大提升。
-
这个方法的主要局限是什么?
其主要局限在于场景特异性。模型学到的背景先验是针对单个场景的,换一个监控点位就需要重新微调,泛化到新场景的能力较弱。因此,它不适用于动态丰富的通用视频,但在封闭、静态的场景中潜力巨大。
论文简评
- 创新性:★★★★☆ 将“正激励噪声”概念创造性引入视频压缩,赋予动态以“有益噪声”的新角色,视角转换巧妙,启发性强。
- 实用性:★★★☆☆ 在固定监控、特定视频会议房间等封闭静态场景有直接产品化潜力,能带来显著的存储/带宽节约。但需解决模型分发、更新等工程问题以实现规模化部署。
- 局限性:★★☆☆☆ “场景特定”特性既是优势也是枷锁,泛化能力弱。未来需研究如何平衡特异性与泛化性,以及实现高效在线自适应学习。
这项来自中国电信TeleAI的研究,为神经网络在垂直场景的应用提供了新思路。它提醒我们,有时候,解决问题的关键不在于更复杂的模型,而在于一个看待问题的全新角度——比如,把噪音变成老师。对于从事视频通信、边缘计算等领域的技术人员而言,这无疑是一个值得深入思考的案例。
主要参考文献
[1] Cheng Yuan, et al. “Enhancing Neural Video Compression of Static Scenes with Positive-Incentive Noise.” arXiv preprint arXiv:2603.06095 (2026).
[2] Xuelong Li. “Positive-incentive noise.” IEEE Transactions on Neural Networks and Learning Systems (2022).
[3] Eirikur Agustsson, et al. “Scale-space flow for end-to-end optimized video compression.” CVPR (2020).
本文基于公开论文进行解读,旨在交流技术思想。更多前沿技术讨论,欢迎访问云栈社区。
 发表于 2026-3-11 01:19:16
|
查看: 215|
回复: 0
发表于 2026-3-11 01:19:16
|
查看: 215|
回复: 0
