1 RCU简介与背景
在Linux内核的并发编程领域中,读-拷贝-更新(Read-Copy-Update, RCU) 是一种高效的同步机制,它通过独特的思路解决了读写锁在读取密集型场景下的性能瓶颈。RCU由Paul E. McKenney在Linux内核中实现并推广,如今已成为内核核心基础设施的关键组成部分。与传统基于锁的同步机制不同,RCU允许读取器和写入器在无锁情况下并发执行,实现了读取路径完全无锁,这在多核系统中带来显著的性能提升。
从本质上看,RCU适用于读多写少场景的同步需求,通过"拷贝-更新-替换"的逻辑链实现数据的高效并发访问。举个现实例子:假设图书馆要更新常用参考书。传统方式是闭门装修(加锁),这会阻止所有读者。而RCU的做法是先准备修订版(创建副本),在合适时机原子替换旧书(原子指针更新)。这样,替换前到达的读者继续读旧版,之后到达的读者自动获得新版,双方互不阻塞。
RCU的适用场景特点包括:(1)数据结构主要通过指针访问;(2)读取操作远多于更新操作;(3)读取端代码无法容忍锁开销;(4)更新操作相对不频繁。在Linux内核中,RCU广泛应用于保护进程描述符表、虚拟文件系统(VFS)层、网络协议栈等数据结构。
从宏观视角看,RCU代表了同步原语设计哲学的转变:从对抗性互斥到协作式分离。传统锁机制基于互斥原则,读取者和写入者相互竞争导致扩展性受限。RCU采用分离策略,通过巧妙的内存管理方案,使读取者和写入者大部分时间并行工作,这种设计在多核系统和大数据量处理中表现优异,尤其在现代服务器和云计算环境中价值凸显。
2 RCU核心原理剖析
2.1 基本概念与生活化比喻
RCU的核心思想可概括为"读时直接读, 写时拷贝改"。以家庭公告板为例:当需要更新日程时,不会阻止他人查看,而是先将当前内容抄到新纸上修改,在无人注意的瞬间替换公告板。替换后不立即销毁旧纸,而是等待确保所有可能看旧板的人看完后才丢弃。
在这个比喻中,"替换瞬间" 对应RCU的发布(Publishing) 操作,"等待确保" 对应宽限期(Grace Period),而"丢弃旧纸" 则对应回收(Reclamation)。这三个概念构成RCU的核心三角。
从技术视角看,RCU保护的数据通常通过指针访问。读取者通过指针访问数据;更新者先创建数据副本并修改,然后使用原子操作将指针更新指向新数据,最后在适当时机回收旧数据。关键点在于确定何时安全回收旧数据——即所有可能访问旧数据的读取者都已完成访问时。
2.2 读取端原理解析
读取端操作是RCU中最简单且最高效的部分。在Linux内核中,典型RCU读取端代码如下:
rcu_read_lock();
/* 读取受保护的数据 */
data = rcu_dereference(global_pointer);
/* 使用数据 */
rcu_read_unlock();
这里的rcu_read_lock()和rcu_read_unlock()并不执行实际加锁解锁操作。在非抢占式内核中,它们可能是空操作。其主要作用是告诉编译器不要重排指令,并在可抢占内核中标记临界区开始和结束。
rcu_dereference()是一个关键宏,确保在Alpha等弱内存顺序处理器上读取操作按预期顺序进行。它可以看作是内存屏障的封装,保证指针读取在获取实际数据前发生。
读取端的关键特性在于零开销——无原子操作、无内存屏障(大多数架构上)、无锁争用。这使得RCU读取路径极其高效,即使在高并发读取场景下性能也能保持稳定。
2.3 更新端与宽限期机制
更新端操作相对复杂,涉及三个关键步骤:复制、更新和发布。典型更新操作如下:
/* 1. 创建新副本 */
struct data *new_data = kmalloc(sizeof(*new_data), GFP_KERNEL);
*new_data = *old_data;
new_data->field = new_value;
/* 2. 原子替换:发布新指针 */
rcu_assign_pointer(global_pointer, new_data);
/* 3. 同步等待宽限期结束 */
synchronize_rcu();
/* 4. 回收旧数据 */
kfree(old_data);
其中,rcu_assign_pointer()确保在新指针对读取者可见前,新数据已完全初始化。它包含写内存屏障,防止编译器和CPU的重排优化。
宽限期是RCU中最精妙的概念。一个宽限期指从更新开始到所有可能存在对旧数据引用的读取者都退出的时间段。宽限期结束后,更新者可安全回收旧数据。
Linux内核通过上下文切换、用户模式执行和空闲循环作为读取端临界区退出的标志。当CPU经历这些状态之一后,内核认为该CPU上所有RCU读取端临界区都已完成。
以下图表展示RCU更新过程中宽限期的概念:
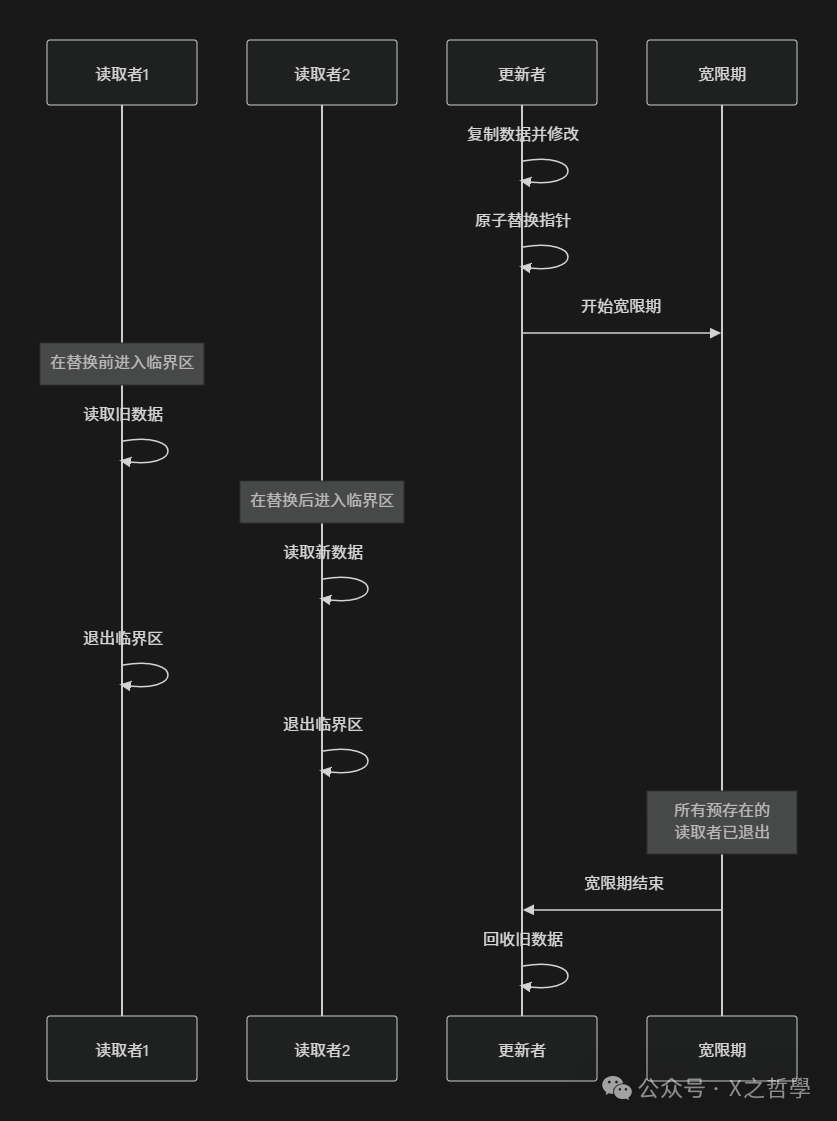
2.4 内存屏障与顺序一致性
RCU的实现严重依赖内存屏障来保证多核环境下的顺序一致性。内存屏障类似于代码中的"栅栏",防止编译器和CPU为优化而重排指令。
在读取端,rcu_dereference()包含读内存屏障,确保在获取指针后的操作不会重排到指针获取前。在更新端,rcu_assign_pointer()包含写内存屏障,确保在更新指针前的所有存储操作对其他CPU可见前,指针更新本身不会对其他CPU可见。
这种顺序保证对RCU的正确性至关重要。考虑数据发布场景:更新者必须先初始化新数据,然后发布指针。若无内存屏障,CPU或编译器可能重排这两步,导致读取者看到未完全初始化的数据。
3 RCU代码框架与数据结构
3.1 核心数据结构关系图
RCU的实现涉及多个核心数据结构,它们协作管理宽限期检测和回调处理。以下是主要数据结构及其关系概览:
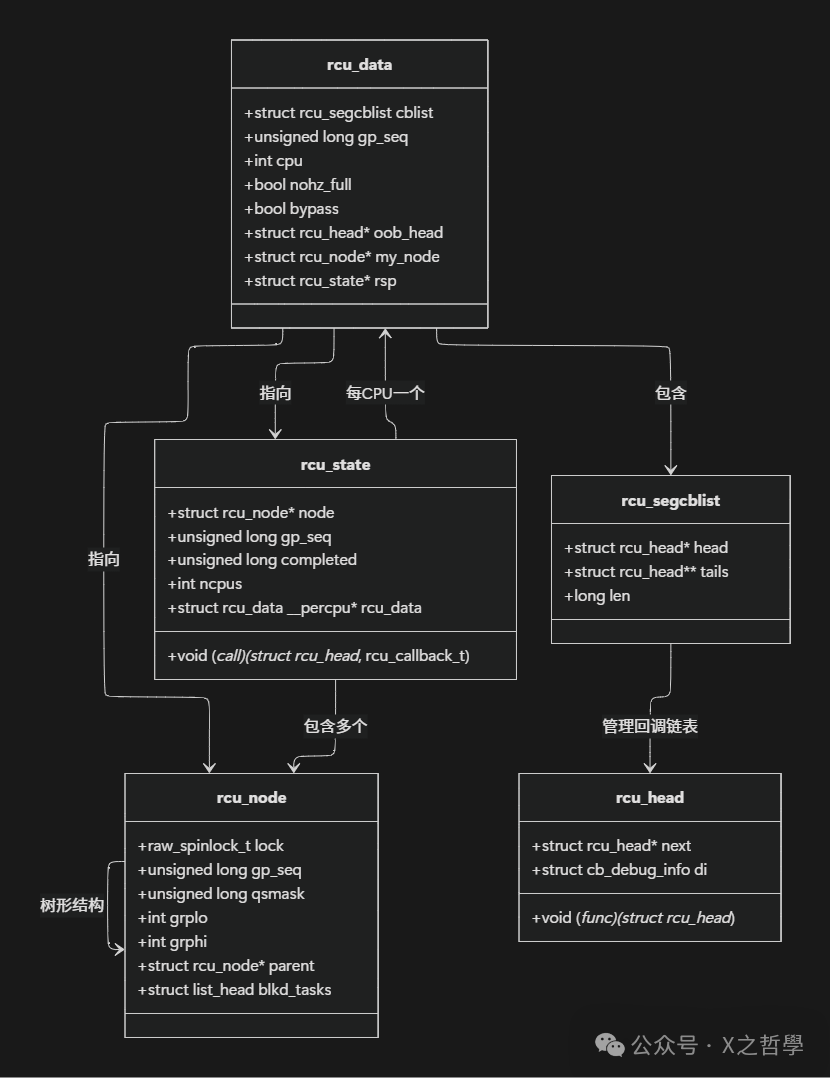
3.2 rcu_state结构
rcu_state结构是RCU的全局状态管理器,每个RCU变种(如rcu_sched、rcu_bh、rcu_preempt)都有独立实例。主要字段包括:
- • node:指向RCU节点树的根节点,用于分层宽限期检测
- • gp_seq:当前宽限期序列号,用于跟踪宽限期进度
- • completed:已完成的宽限期序列号
- • ncpus:跟踪的CPU数量
- • rcu_data:每CPU数据指针数组
- • call:回调调用函数指针
该结构通过gp_seq字段管理宽限期推进,序列号在每次新宽限期开始时递增。
3.3 rcu_node层次树
为应对现代多核系统(尤其是NUMA系统)的扩展性挑战,Linux RCU引入分层树结构管理宽限期状态。rcu_node结构构成树的节点:
struct rcu_node {
raw_spinlock_t lock;
unsigned long gp_seq;
unsigned long qsmask;
int grplo;
int grphi;
struct rcu_node *parent;
struct list_head blkd_tasks;
};
树结构设计使宽限期检测分层进行:叶子节点收集各自管理CPU的状态,中间节点合并子节点状态,最终根节点判断整个系统状态。这种设计减少锁竞争,提高扩展性。
qsmask字段是位图,跟踪该节点管理的CPU中哪些未经历当前宽限期。当所有位清除时,表示该节点管理所有CPU都已经历宽限期。
3.4 每CPU数据rcu_data
rcu_data结构是每CPU变量,每个CPU有自己实例,包含该CPU的RCU状态:
struct rcu_data {
struct rcu_segcblist cblist;
unsigned long gp_seq;
int cpu;
bool nohz_full;
bool bypass;
struct rcu_head *oob_head;
struct rcu_node *my_node;
struct rcu_state *rsp;
};
关键字段cblist是分段回调链表,将回调按宽限期分段管理。这种分段管理使RCU能同时处理多个不同阶段回调,提高效率。
3.5 回调管理rcu_segcblist
rcu_segcblist结构管理待处理RCU回调:
struct rcu_segcblist {
struct rcu_head *head;
struct rcu_head **tails;
long len;
};
它使用四个段(segments)分类回调:
- • 已准备好:可立即调用的回调
- • 等待当前宽限期:等待当前宽限期结束的回调
- • 等待下一个宽限期:等待下一个宽限期的回调
- • 离线:CPU离线时暂存的回调
这种分段管理使回调处理更高效,尤其在宽限期交替时。
4 RCU核心模型剖析
4.1 状态机与宽限期推进
RCU核心是精细状态机,管理宽限期开始、推进和结束。以下图表展示RCU宽限期的完整状态流程:
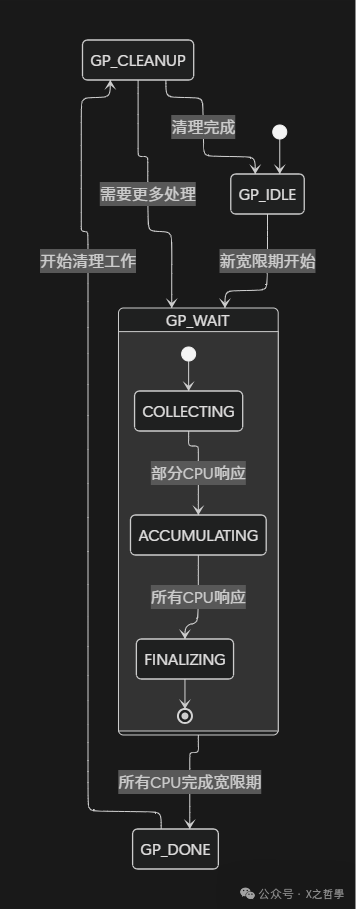
宽限期推进由以下关键步骤组成:
- 开始阶段:当需要新宽限期时,RCU递增gp_seq,初始化相关状态,并唤醒RCU内核线程
- 收集阶段:RCU通过每CPU的rcu_data结构收集CPU状态。每个CPU通过rcu_report_qs_rnp报告已经历宽限期
- 完成阶段:当所有CPU都报告后,宽限期正式结束,相关回调可安全调用
- 回调调用阶段:宽限期结束后,RCU调用所有等待该宽限期的回调函数,完成旧数据释放
4.2 混合树形结合机制
RCU使用混合树形结构结合每CPU变量高效管理宽限期。这种设计是现代RCU扩展到数千CPU的关键。
在树形结构中,每个rcu_node管理一组CPU。当CPU报告宽限期经历时,先更新对应叶子节点。叶子节点收集所有管理CPU的报告后,向上报告给父节点。这种分层报告机制大大减少根节点竞争。
同时,RCU使用每CPU变量存储大部分状态信息,使每个CPU在报告宽限期经历时主要操作自己数据,仅在必要时获取节点锁。这进一步减少锁竞争。
4.3 回调处理与内存回收
回调处理是RCU内存回收核心。当调用synchronize_rcu()或call_rcu()时,RCU不会立即执行清理,而是将清理操作延迟到宽限期结束后。
call_rcu()函数是RCU异步处理基础:
void call_rcu(struct rcu_head *head, rcu_callback_t func)
{
__call_rcu(head, func, rcu_state_p, -1, 0);
}
该函数将回调结构rcu_head添加到当前CPU的rcu_data回调链表中。回调链表中元素会在宽限期结束后被批量处理。
为调试RCU回调处理,Linux内核引入CONFIG_RCU_TRACE_CB选项,可跟踪每个回调的排队、刷新和调用过程。启用该选项时,rcu_head结构包含调试信息:
struct cb_debug_info {
u16 cb_queue_jiff;
u16 first_bp_jiff;
u16 cb_flush_jiff;
enum cb_debug_flags flags:16;
};
4.4 可抢占RCU与实时性改进
为满足实时系统需求,Linux内核引入可抢占RCU(Preemptible RCU)。在传统RCU中,读取端临界区不允许被抢占,这在实时系统中可能导致延迟不确定性。
可抢占RCU通过以下改进提供更好实时性:
- • 允许在RCU读取端临界区中被抢占
- • 使用特殊链表blkd_tasks跟踪被阻塞任务
- • 当任务被抢占时,将其添加到阻塞任务列表,在任务恢复时从列表移除
这种机制确保即使读取端任务被抢占,宽限期仍能正确推进,不会无限期等待被抢占任务。
4.5 无回调CPU和离线处理
现代节能技术如nohz模式允许CPU在空闲时完全关闭时钟中断,这给RCU带来挑战,因为RCU依赖时钟中断检测宽限期。
为解决这个问题,RCU引入无回调CPU(Callback-Free CPUs)处理。当CPU进入nohz模式时,它会先报告宽限期状态,确保在关闭中断期间不会阻止宽限期推进。
同样,当CPU离线时,RCU需特殊处理确保离线CPU不会阻止宽限期进展。RCU通过rcu_report_dead()函数处理CPU离线事件,将离线CPU从宽限期检测中移除。
5 RCU工具命令与调试手段
5.1 调试配置选项
Linux内核提供丰富RCU调试选项,这些选项可在内核配置中启用:
| 配置选项 |
功能描述 |
对性能影响 |
CONFIG_PROVE_RCU |
检查RCU使用正确性 |
中等 |
CONFIG_RCU_TORTURE_TEST |
RCU压力测试 |
仅测试时 |
CONFIG_RCU_TRACE_CB |
跟踪回调生命周期 |
轻微 |
CONFIG_RCU_CPU_STALL_TIMEOUT |
检测RCU停滞 |
可忽略 |
CONFIG_DEBUG_CREDENTIALS |
凭证RCU调试 |
中等 |
其中,CONFIG_PROVE_RCU是重要调试选项,它使用Lockdep框架验证RCU API正确使用。启用该选项时,内核会跟踪RCU读取端临界区状态,并检测可能误用,如在临界区内阻塞或违反锁顺序等。
5.2 运行时监控与调试
在运行时,可通过sysfs和debugfs文件系统监控RCU状态:
常用监控命令:
# 查看RCU宽限期状态
cat /sys/kernel/debug/rcu/rcu_preempt/gp_seq
# 查看RCU回调统计
cat /sys/kernel/debug/rcu/rcu_preempt/rcu_callback
# 查看每CPU RCU状态
cat /sys/kernel/debug/rcu/rcu_preempt/rcudata
# 检测RCU停滞信息
dmesg | grep "RCU stall"
RCU停滞检测是重要调试功能。当RCU宽限期超过预设时间(默认21秒)时,内核会打印警告信息,包括停滞CPU和回溯信息,帮助开发者定位问题。
5.3 性能测试与压力测试
RCU提供专门压力测试模块rcutorture,用于验证RCU实现正确性和健壮性:
# 加载rcutorture模块
modprobe rcutorture
# 查看测试状态
cat /sys/kernel/debug/rcutorture/rcu_torture_stats
# 卸载模块
rmmod rcutorture
rcutorture测试会创建多个内核线程,执行各种RCU操作组合,包括读取端临界区、更新操作、回调处理等,同时模拟各种异常情况,如内存压力、CPU热插拔等。
5.4 内核跟踪与事件
对于深度调试,Linux内核提供RCU相关跟踪事件:
# 启用RCU回调跟踪
echo 1 > /sys/kernel/debug/tracing/events/rcu/enable
# 查看跟踪结果
cat /sys/kernel/debug/tracing/trace
RCU跟踪事件包括:
- • rcu_invoke_callback:回调调用事件
- • rcu_batch_start:回调批量处理开始
- • rcu_torture_read:rcutorture读取事件
这些事件帮助开发者理解RCU内部行为,诊断性能问题和正确性问题。
6 RCU简单实例与实践
6.1 内核模块示例
为完整展示RCU使用方法,我们创建简单内核模块,演示RCU保护下的数据结构读写:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/rcupdate.h>
#include <linux/slab.h>
#include <linux/kthread.h>
#include <linux/delay.h>
struct data {
int value;
char name[32];
struct rcu_head rcu;
};
static struct data *global_data;
static struct task_struct *reader_thread;
static struct task_struct *writer_thread;
static int reader_function(void *data)
{
struct data *d;
while (!kthread_should_stop()) {
rcu_read_lock();
d = rcu_dereference(global_data);
printk(KERN_INFO "Reader: value=%d, name=%s\n", d->value, d->name);
rcu_read_unlock();
msleep(1000);
}
return 0;
}
static void data_reclaim(struct rcu_head *rcu)
{
struct data *d = container_of(rcu, struct data, rcu);
printk(KERN_INFO "Reclaiming data: %s\n", d->name);
kfree(d);
}
static int writer_function(void *data)
{
struct data *new_data, *old_data;
int counter = 0;
while (!kthread_should_stop()) {
/* 创建新数据 */
new_data = kmalloc(sizeof(*new_data), GFP_KERNEL);
new_data->value = counter++;
snprintf(new_data->name, sizeof(new_data->name), "Data-%d", new_data->value);
/* 原子替换 */
old_data = global_data;
rcu_assign_pointer(global_data, new_data);
/* 异步回收旧数据 */
call_rcu(&old_data->rcu, data_reclaim);
msleep(5000);
}
return 0;
}
static int __init rcu_test_init(void)
{
/* 初始化全局数据 */
global_data = kmalloc(sizeof(*global_data), GFP_KERNEL);
global_data->value = 0;
strcpy(global_data->name, "Initial");
/* 创建读写线程 */
reader_thread = kthread_run(reader_function, NULL, "rcu-reader");
writer_thread = kthread_run(writer_function, NULL, "rcu-writer");
printk(KERN_INFO "RCU test module loaded\n");
return 0;
}
static void __exit rcu_test_exit(void)
{
kthread_stop(reader_thread);
kthread_stop(writer_thread);
/* 清理数据 */
synchronize_rcu();
kfree(global_data);
printk(KERN_INFO "RCU test module unloaded\n");
}
module_init(rcu_test_init);
module_exit(rcu_test_exit);
MODULE_LICENSE("GPL");
6.2 示例代码分析
这个示例模块展示RCU典型使用模式:
- 数据结构设计:struct data包含rcu_head字段,这是RCU回调所必需
- 读取端保护:在reader_function中,使用rcu_read_lock()和rcu_read_unlock()划定临界区,在临界区内使用rcu_dereference()安全获取指针
- 更新端操作:在writer_function中,先创建新数据副本并修改,然后使用rcu_assign_pointer()原子替换全局指针,最后使用call_rcu()注册回收函数
- 内存回收:data_reclaim函数通过container_of宏从rcu_head指针获取完整数据结构,然后释放内存
6.3 编译与测试
编译该模块需要Linux内核头文件,Makefile内容如下:
obj-m += rcu_test.o
KDIR := /lib/modules/$(shell uname -r)/build
all:
make -C $(KDIR) M=$(PWD) modules
clean:
make -C $(KDIR) M=$(PWD) clean
加载模块后,可通过dmesg观察输出,会看到读取者定期打印数据,写入者每5秒更新一次数据,而旧数据在宽限期结束后被回收。
6.4 实际应用注意事项
在实际内核开发中使用RCU时,需注意以下几点:
- 防止阻塞:RCU读取端临界区内不能阻塞,也不能调用可能阻塞的函数
- 内存屏障使用:正确使用rcu_dereference()和rcu_assign_pointer()确保内存可见性
- 宽限期理解:synchronize_rcu()等待的是所有预存在的读取者,而不是所有读取者
- 调试支持:在开发阶段启用CONFIG_PROVE_RCU等调试选项,及早发现RCU使用错误
7 总结
优势:
- • 读取端零开销:读取路径无锁、无原子操作、无内存屏障(大多数架构上)
- • 卓越的可扩展性:读取性能随CPU数量线性扩展
- • 避免死锁:读取端不会导致死锁,简化软件设计
- • 实时性:读取端不会被阻塞,适合实时系统
局限性:
- • 写入端开销大:写入需要内存分配、复制和同步等待
- • 内存使用:存在暂时性内存重复占用
- • 复杂性:实现机制复杂,理解和使用门槛高
- • 适用场景有限:主要适用于读多写少的指针型数据结构
Linux RCU是一种精妙的并发同步机制,代表同步原语设计思想的进化:从对抗到协作,从互斥到分离。它通过读取端无锁化、写入端延迟回收和宽限期检测三大核心技术,在高并发读取场景下提供卓越性能。
 发表于 2025-11-30 01:04:29
|
查看: 184|
回复: 0
发表于 2025-11-30 01:04:29
|
查看: 184|
回复: 0
