1 内存池基本概念与问题背景
在计算机系统中,内存管理对系统性能和稳定性起着决定性作用。传统的动态内存分配方法,如C标准库中的malloc()和free(),虽然使用方便灵活,但在特定场景下存在明显的性能瓶颈和资源利用率问题。理解这些问题的本质,有助于把握内存池技术的核心价值。
1.1 内存分配的性能挑战
每次程序调用malloc()申请内存时,底层内存管理器需要执行复杂操作:查找足够大的空闲内存块、分割内存块、更新内部数据结构等。这些操作的时间复杂度通常不是常数级别,尤其在系统运行时间长、内存分配释放频繁的情况下,内存管理器的内部数据结构会变得复杂,导致查找和分配操作更加耗时。
类比图书馆借书场景:如果每次读者借书时,图书管理员都需要在整个图书馆的所有书架上查找一本书,效率会十分低下。同理,频繁的内存分配和释放会导致性能下降,在实时系统、嵌入式系统或高性能计算等对性能敏感的场景中,这种性能损耗往往是不可接受的。
1.2 内存碎片化的困境
另一个关键问题是内存碎片化。随着内存的不断分配和释放,物理内存中会出现大量小而分散的空闲区块。即使总的空闲内存足够,但当需要分配一块较大的连续内存时,却可能找不到足够的连续空间。内存碎片主要分为两种:
- 外部碎片:分布在已分配内存块之间的零散空闲内存,由于彼此不连续,无法合并用于满足较大的内存请求
- 内部碎片:在已分配的内存块内部,由于对齐或固定块大小等原因而未被实际利用的空间
用停车场比喻:外部碎片就像停车场中分散的空车位,虽然总数不少,但当一辆大货车需要连续多个车位时,这些分散的空位就无法满足需求。而内部碎片则像是车辆停放后与划线边界之间的空隙,虽然存在空间,但无法被其他车辆使用。
1.3 内存池的解决之道
面对上述挑战,内存池(Memory Pool)技术应运而生。其核心思想是预先分配一大块内存,然后由应用程序自行管理这块内存的分配和释放。通过这种方式,内存池技术带来了多重优势:
- 性能提升:通过预先分配和自定义分配策略,极大地减少了每次分配的时间开销,分配操作通常可以在常数时间内完成
- 碎片控制:通过固定大小的分配或精心设计的块大小策略,有效减少内存碎片的产生
- 确定性:对于实时系统,内存池提供了可预测的分配时间,避免了传统内存分配器在最坏情况下表现不佳的问题
- 局部性优势:同一对象的内存块通常位于相邻的内存区域,这有利于缓存局部性,提高访问效率
在Linux内核中,内存池技术有着多层次、多场景的应用。从内核级的genalloc、slab分配器、mempool,到用户态的各种内存池实现,形成了丰富而完善的内存管理生态系统。
2 Linux内核内存池机制详解
Linux内核作为一个复杂且需要高性能的操作系统核心,实现了多种内存池机制,每种机制针对不同的使用场景和需求进行了专门优化。
2.1 genalloc通用内存池
genalloc(通用内存池)是Linux内核中一种灵活且通用的内存池实现,特别适用于管理特定设备上的专用内存或需要特殊对齐要求的内存区域。它的设计目标是提供一个与硬件无关的通用内存管理框架,可以被各种驱动程序或内核子系统使用。
2.1.1 核心数据结构
genalloc的核心数据结构定义在<linux/genalloc.h>中,主要包括以下两个关键结构:
struct gen_pool {
spinlock_t lock; // 保护池的自旋锁
struct list_head chunks; // 内存块链表
int min_alloc_order; // 最小分配阶数
const char *name; // 内存池名称
struct gen_pool_chunk *chunks; // 指向第一个内存块的指针
};
struct gen_pool_chunk {
struct list_head next_chunk; // 链表指针
unsigned long start_addr; // 内存块的起始地址
unsigned long end_addr; // 内存块的结束地址
unsigned long bits[0]; // 位图数组,跟踪分配状态
};
gen_pool结构代表整个内存池,而gen_pool_chunk则表示池中的一个连续内存区域。一个内存池可以由多个chunk组成,这在需要动态扩展池容量时非常有用。
2.1.2 内存池的创建与初始化
创建genalloc内存池的过程涉及几个关键步骤:
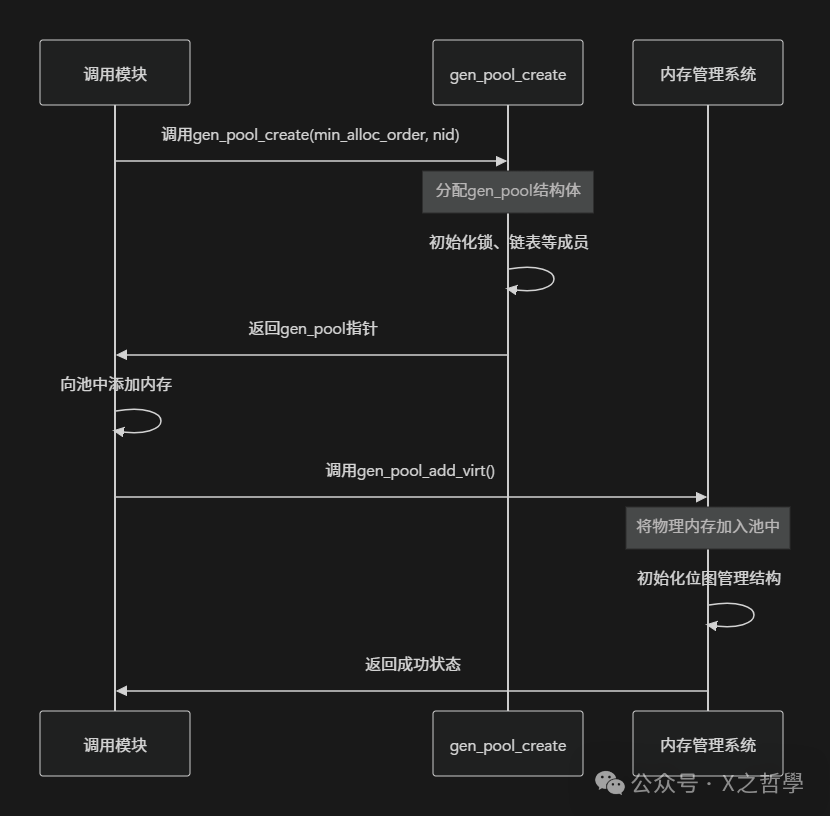
创建内存池后,需要向其中添加实际的内存区域。这通过gen_pool_add_virt()函数完成,该函数将物理内存与虚拟地址关联,并初始化用于跟踪内存分配状态的位图。
2.1.3 分配算法与策略
genalloc提供了多种分配算法,可以通过gen_pool_set_algo()进行设置。每种算法适用于不同的使用场景:
- 首次适应(first-fit):从内存池起始位置查找,选择第一个足够大的空闲块。这是默认算法,简单高效
- 最佳适应(best-fit):查找能够满足请求的最小空闲块,减少内存浪费但增加查找时间
- 固定地址分配:在指定地址进行分配,适用于有严格地址要求的硬件设备
位图管理是genalloc的核心机制之一。系统使用位图来跟踪每个最小分配单元的状态:0表示空闲,1表示已分配。这种设计使得分配和释放操作非常高效,只需要简单的位操作即可完成。
2.2 slab分配器与kmalloc体系
slab分配器是Linux内核中用于管理内核对象内存分配的核心组件,特别针对小对象分配进行了高度优化。它的设计解决了传统内存分配器在频繁分配释放相同大小对象时的性能问题。
2.2.1 三层架构体系
slab分配器采用经典的三层架构,每一层都有特定的职责:
- kmalloc层:提供通用的小块内存分配接口,是内核中最常用的分配API之一
- slab层:管理相同类型对象的缓存,实现了对象复用和内存着色等优化技术
- 页框分配器层:从内核页分配器获取物理页面,作为slab层的基础存储
2.2.2 核心数据结构关系
slab分配器的核心数据结构之间的关系极为复杂,可以通过以下图表直观展示:
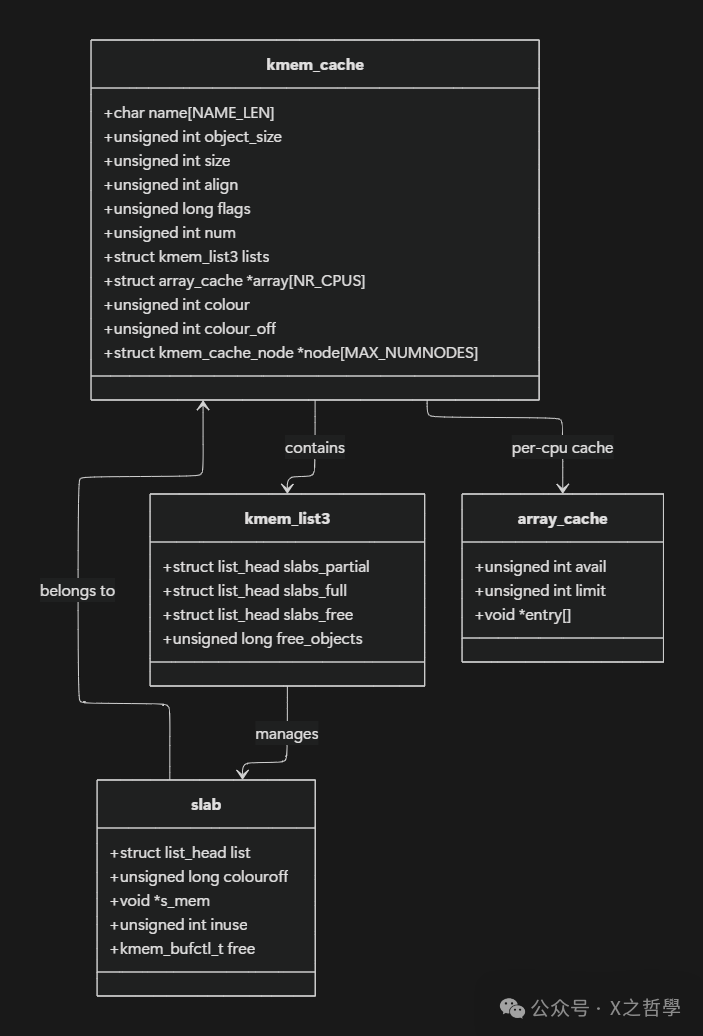
kmem_cache结构是slab分配器的核心,它代表一个特定类型对象的缓存。每个缓存维护三个链表:slabs_partial(部分空闲的slab)、slabs_full(完全分配的slab)和slabs_free(完全空闲的slab)。这种多状态设计使得分配器能够高效地满足分配请求,同时有效地管理内存资源。
2.2.3 性能优化特性
slab分配器包含了多项精心设计的性能优化特性:
- 每CPU缓存(array_cache):为每个CPU核心维护一个对象缓存,减少了锁竞争,提高了分配速度。当需要分配对象时,首先尝试从当前CPU的缓存中获取,避免了跨CPU同步的开销
- 内存着色:通过调整对象在slab内的起始偏移量,使得相同类型的对象在不同slab中具有不同的缓存行对齐,减少CPU缓存冲突
- 对象复用:释放的对象不会被立即返回给系统,而是保留在缓存中,供后续分配重用。这避免了频繁的页面分配和释放操作
- 构造函数和析构函数:每个缓存可以定义可选的构造函数和析构函数,在对象分配时初始化和在释放时清理对象状态
2.2.4 kmalloc的实现机制
kmalloc()是内核中最常用的内存分配函数之一,它实际上构建在slab分配器之上。内核预先创建了一系列不同大小的slab缓存,通常以2的幂次方作为大小(如32、64、128、256字节等)。当调用kmalloc(size, flags)时,系统会向上取整到最接近的标准大小,然后从相应的slab缓存中分配对象。
这种设计的优势在于它将不同大小的分配请求分类到专门的缓存中,既提高了分配效率,又减少了内存碎片。同时,由于相同大小的对象集中在同一个缓存中,也提高了CPU缓存的利用效率。
2.3 mempool紧急内存池
在内核的某些关键路径中,内存分配绝对不能失败。为了应对这种情况,Linux内核提供了mempool(紧急内存池)机制。mempool通过预分配一些内存对象,确保在系统内存紧张时仍能满足关键组件的内存需求。
2.3.1 设计原理与核心数据结构
mempool的核心思想是预先分配一定数量的对象作为应急储备。在正常情况下,分配请求会尝试从底层分配器(如slab或页面分配器)获取内存,如果失败则回退到预分配的对象池中获取。
mempool的主要数据结构如下:
typedef struct mempool_s {
spinlock_t lock; // 保护锁
int min_nr; // 池中保留的最小对象数
int curr_nr; // 当前可用的对象数
void **elements; // 对象指针数组
void *pool_data; // 池的私有数据
mempool_alloc_t *alloc; // 分配函数
mempool_free_t *free; // 释放函数
wait_queue_head_t wait; // 等待队列
} mempool_t;
2.3.2 工作机制
mempool的工作机制体现了"预留后备"的设计思想,其完整工作流程如下图所示:
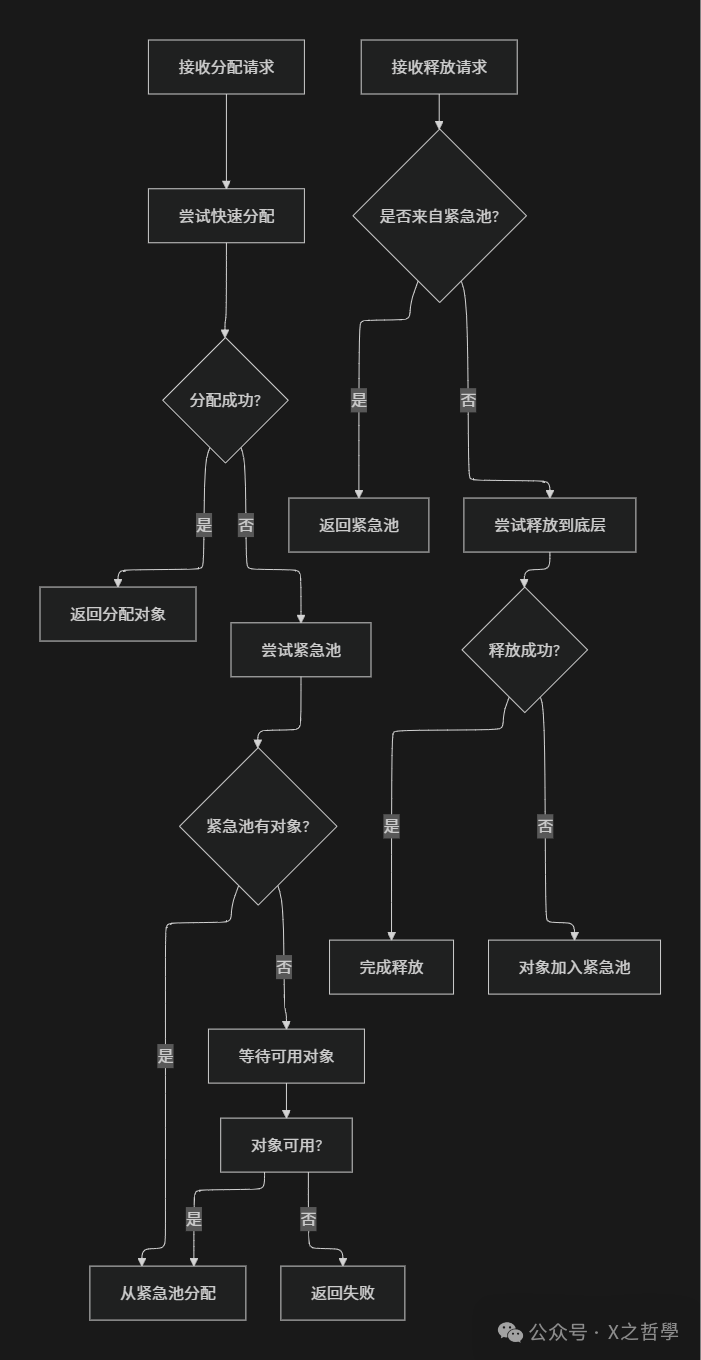
从图中可以看出,mempool在分配时优先尝试底层分配器,只有在常规分配失败时才使用预分配的对象。这种设计既保证了在内存紧张时的可靠性,又避免了在正常情况下过度使用预分配内存造成的浪费。
2.3.3 应用场景与注意事项
mempool主要应用于以下场景:
- 块设备层:确保I/O请求的内存分配在内存紧张时仍能成功,避免I/O路径被阻塞
- 文件系统:关键元数据操作的内存分配
- 设备驱动程序:确保中断处理程序等关键路径的内存需求
然而,使用mempool也需要谨慎,因为它会永久占用一部分内存,即使系统内存紧张时这些内存也无法被回收。因此,内核文档中明确指出:"如果您的驱动程序有任何方法可以应对分配失败,而不危害系统完整性,那么最好不使用mempool。"
3 关键设计模式与核心模型
深入理解Linux内存池的各种实现后,需要从更高层次抽象出它们共同遵循的设计模式和核心模型。这些设计原则不仅适用于内核开发,对于任何需要高性能内存管理的应用场景都具有指导意义。
3.1 内存池的生命周期模型
无论是哪种具体的内存池实现,其生命周期通常都遵循一个统一的模式,包含创建、初始化、分配、释放和销毁等基本阶段。下图展示了这一完整生命周期:
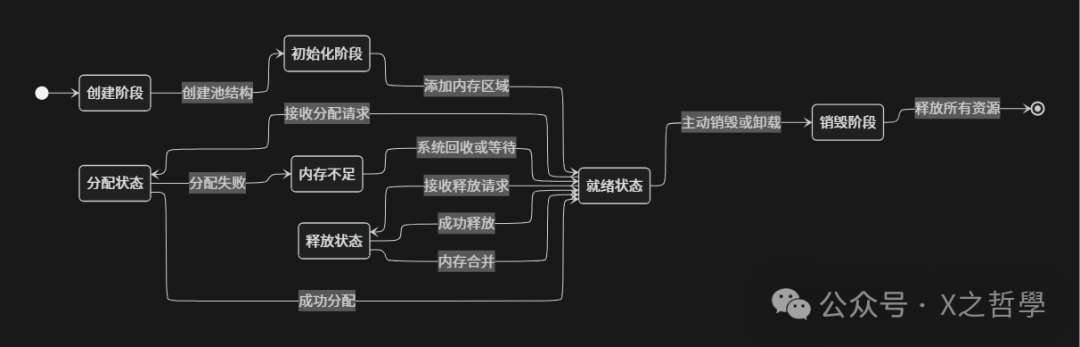
在创建阶段,内存池管理器初始化必要的数据结构,如控制块、链表、位图等,但此时还没有实际的内存可供分配。初始化阶段是向内存池中添加实际内存区域的过程,这些内存可以来自系统页分配器、预留的物理内存或特定的设备内存。就绪状态表示内存池已准备好处理分配和释放请求。当处理分配请求时,系统可能进入分配状态,如果此时没有足够内存满足请求,则进入内存不足状态,根据具体实现可能触发内存回收、等待或直接失败。释放状态处理将内存返回池中的操作,高级实现可能会在此阶段进行内存合并,将相邻的空闲块合并成更大块以减少碎片。最后,销毁阶段负责清理资源,将所有内存返回给系统。
3.2 分配算法比较与分析
不同的内存池实现可能采用不同的分配算法,每种算法各有优劣,适用于不同的场景。下表对比了常见的分配算法特性:
| 算法类型 |
工作原理 |
优点 |
缺点 |
适用场景 |
| 首次适应 |
从内存池起始查找,选择第一个足够大的块 |
简单快速,内存开销小 |
容易产生外部碎片,分配速度随池增大而下降 |
通用场景,内存池大小适中 |
| 最佳适应 |
查找能够满足请求的最小空闲块 |
内存利用率高,减少内部碎片 |
需要遍历整个空闲列表,性能较差 |
内存紧张环境,对象大小差异大 |
| 最坏适应 |
总是分配最大的空闲块 |
减少外部碎片,保留大块连续内存 |
可能无法满足大块请求 |
实时系统,需要避免碎片 |
| 伙伴系统 |
将内存分为2的幂次方块,可以合并相邻空闲块 |
有效减少外部碎片,分配释放高效 |
内部碎片较严重,内存利用率低 |
内核页分配,大块内存管理 |
| 固定大小块 |
预定义一组固定大小的块,请求被向上取整 |
分配极快,无外部碎片 |
内部碎片可能严重,灵活性差 |
对象池,频繁分配释放相似大小对象 |
在实际系统中,这些算法常常结合使用。例如,Linux的slab分配器在高层使用伙伴系统获取大块内存,然后在内部使用固定大小块策略管理对象分配。
3.3 多级内存池架构
现代操作系统通常采用多级内存池架构来平衡性能和通用性。这种架构类似于计算机存储体系中的缓存层次结构,每一级针对不同的访问特性进行优化。
Linux内存管理的多层次架构包括:
- 页分配器(伙伴系统):管理物理页帧,以页为单位(通常4KB),处理大块内存分配请求。这是内存管理的最底层,直接与硬件交互
- slab分配器:构建在页分配器之上,管理内核中小对象的分配,提供对象缓存和复用机制
- 特定子系统缓存:如文件系统inode缓存、目录项缓存等,针对特定对象类型进一步优化
- 用户态内存分配器:如glibc的malloc,管理进程堆内存,通常采用ptmalloc等实现
- 应用程序自定义内存池:针对特定应用场景的高度优化内存管理,如数据库缓冲区、网络服务器连接池等
这种多级架构每一级都屏蔽了下层的细节,同时为上层提供更简化的接口和更好的性能。例如,当slab分配器需要更多内存时,它会向页分配器请求整页内存,然后将这些页面划分为相同大小的对象进行管理。当应用程序调用malloc时,如果请求的内存较大,可能会直接通过mmap系统调用从页分配器获取内存,而小对象则从用户态内存分配器维护的堆中获取。
4 实践应用与调试技巧
理解了内存池的理论知识后,本节将聚焦于实际应用,包括如何在用户态和内核态实现和使用内存池,以及相关的调试和优化技巧。
4.1 用户态内存池实现
虽然Linux内核提供了丰富的内存池机制,但在用户空间应用程序中,有时也需要实现自定义的内存池以满足特定性能需求。下面是一个简化但完整的内存池实现:
4.1.1 基本数据结构定义
#include <stdlib.h>
#include <string.h>
#include <pthread.h>
#define MP_ALIGNMENT 16
#define MP_PAGE_SIZE 4096
#define MP_MAX_ALLOC_FROM_POOL (MP_PAGE_SIZE - 1)
typedef struct mp_large_s {
struct mp_large_s *next;
void *alloc;
} mp_large_t;
typedef struct mp_node_s {
unsigned char *last; // 当前节点的分配游标
unsigned char *end; // 节点结束位置
struct mp_node_s *next; // 下一个节点
size_t failed; // 分配失败次数
} mp_node_t;
typedef struct mp_pool_s {
size_t max; // 大块小块的阈值
mp_node_t *current; // 当前节点
mp_large_t *large; // 大块链表
mp_node_t head[0]; // 小节点头部
} mp_pool_t;
4.1.2 内存池创建与初始化
mp_pool_t *mp_create_pool(size_t size) {
mp_pool_t *p;
int ret = posix_memalign((void**)&p, MP_ALIGNMENT, size + sizeof(mp_pool_t) + sizeof(mp_node_t));
if (ret) {
return NULL;
}
p->max = (size < MP_MAX_ALLOC_FROM_POOL) ? size : MP_MAX_ALLOC_FROM_POOL;
p->current = p->head;
p->large = NULL;
// 初始化第一个节点
p->head->last = (unsigned char *)p + sizeof(mp_pool_t) + sizeof(mp_node_t);
p->head->end = p->head->last + size;
p->head->failed = 0;
p->head->next = NULL;
return p;
}
4.1.3 内存分配实现
内存池中的分配分为小块分配和大块分配两种情况:
// 小块分配
static void *mp_alloc_small(mp_pool_t *pool, size_t size, int align) {
unsigned char *m;
mp_node_t *p = pool->current;
while (p) {
m = align ? mp_align_ptr(p->last, MP_ALIGNMENT) : p->last;
if ((size_t)(p->end - m) >= size) {
p->last = m + size;
return m;
}
p = p->next;
}
return mp_alloc_block(pool, size);
}
// 大块分配
static void *mp_alloc_large(mp_pool_t *pool, size_t size) {
void *p = malloc(size);
if (p == NULL) return NULL;
mp_large_t *large;
// 查找已有大块结构或创建新的
for (large = pool->large; large; large = large->next) {
if (large->alloc == NULL) {
large->alloc = p;
return p;
}
}
// 没有可用的大块结构,需要分配新的
large = mp_alloc_small(pool, sizeof(mp_large_t), 1);
large->alloc = p;
large->next = pool->large;
pool->large = large;
return p;
}
// 统一的分配接口
void *mp_alloc(mp_pool_t *pool, size_t size) {
if (size <= pool->max) {
return mp_alloc_small(pool, size, 1);
}
return mp_alloc_large(pool, size);
}
这个用户态内存池实现展示了内存池的核心概念:通过预分配和大块/小块区分策略,提高了内存分配效率,同时减少了碎片。在实际应用中,可以根据具体需求对此实现进行扩展和优化。
4.2 内核模块中的内存池使用
在内核模块开发中,可以直接使用内核提供的内存池机制。下面示例展示如何在字符设备驱动中使用mempool:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/fs.h>
#include <linux/slab.h>
#include <linux/mempool.h>
#include <linux/blkdev.h>
#define DEVICE_NAME "mempool_example"
#define MINOR_NUMBER 0
#define POOL_SIZE 32
#define OBJECT_SIZE 256
struct example_device {
struct cdev cdev;
mempool_t *pool;
void *objects[POOL_SIZE];
};
static struct example_device *example_dev;
static void *example_alloc(gfp_t gfp_mask, void *pool_data)
{
return kmalloc(OBJECT_SIZE, gfp_mask);
}
static void example_free(void *element, void *pool_data)
{
kfree(element);
}
static int example_open(struct inode *inode, struct file *file)
{
printk(KERN_INFO "Example device opened\n");
return 0;
}
static int example_release(struct inode *inode, struct file *file)
{
printk(KERN_INFO "Example device closed\n");
return 0;
}
static ssize_t example_read(struct file *file, char __user *buf,
size_t count, loff_t *ppos)
{
struct example_device *dev = example_dev;
void *item;
if (count > OBJECT_SIZE)
return -EINVAL;
// 从内存池分配对象
item = mempool_alloc(dev->pool, GFP_KERNEL);
if (!item)
return -ENOMEM;
// 模拟数据操作
memset(item, 0xAB, OBJECT_SIZE);
// 将数据复制到用户空间
if (copy_to_user(buf, item, count)) {
mempool_free(item, dev->pool);
return -EFAULT;
}
mempool_free(item, dev->pool);
return count;
}
static struct file_operations example_fops = {
.owner = THIS_MODULE,
.open = example_open,
.release = example_release,
.read = example_read,
};
static int __init example_init(void)
{
int ret;
dev_t devno;
// 分配设备号
ret = alloc_chrdev_region(&devno, MINOR_NUMBER, 1, DEVICE_NAME);
if (ret < 0) {
printk(KERN_ERR "Failed to allocate device number\n");
return ret;
}
// 分配设备结构
example_dev = kzalloc(sizeof(*example_dev), GFP_KERNEL);
if (!example_dev) {
ret = -ENOMEM;
goto fail_alloc;
}
// 创建内存池
example_dev->pool = mempool_create(POOL_SIZE, example_alloc,
example_free, NULL);
if (!example_dev->pool) {
ret = -ENOMEM;
goto fail_pool;
}
// 初始化字符设备
cdev_init(&example_dev->cdev, &example_fops);
example_dev->cdev.owner = THIS_MODULE;
// 添加字符设备到系统
ret = cdev_add(&example_dev->cdev, devno, 1);
if (ret) {
printk(KERN_ERR "Failed to add character device\n");
goto fail_cdev;
}
printk(KERN_INFO "Example module loaded with mempool\n");
return 0;
fail_cdev:
mempool_destroy(example_dev->pool);
fail_pool:
kfree(example_dev);
fail_alloc:
unregister_chrdev_region(devno, 1);
return ret;
}
static void __exit example_exit(void)
{
dev_t devno = example_dev->cdev.dev;
cdev_del(&example_dev->cdev);
mempool_destroy(example_dev->pool);
kfree(example_dev);
unregister_chrdev_region(devno, 1);
printk(KERN_INFO "Example module unloaded\n");
}
module_init(example_init);
module_exit(example_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Kernel Developer");
这个示例展示了在字符设备驱动中如何使用mempool来确保在内存紧张情况下仍能成功分配对象。通过mempool_create预先分配一定数量的对象,在read操作中使用mempool_alloc和mempool_free来分配和释放这些对象。
4.3 调试工具与技巧
内存池相关问题的调试需要专门的工具和技巧。下面介绍几种常用的调试方法:
4.3.1 Slab信息查看
通过/proc/slabinfo可以查看系统中slab分配器的详细状态:
# 查看所有slab缓存
cat /proc/slabinfo
# 查看特定缓存的信息
grep "kmalloc" /proc/slabinfo
# 使用slabtop实时查看slab使用情况
slabtop
4.3.2 内存泄漏检测
内核提供了kmemleak工具用于检测内核内存泄漏:
# 启用kmemleak
echo scan > /sys/kernel/debug/kmemleak
# 查看检测到的内存泄漏
cat /sys/kernel/debug/kmemleak
4.3.3 内存池状态监控
对于自定义内存池,可以通过添加统计信息来监控其状态:
struct mp_pool_stats {
size_t total_allocated;
size_t current_allocated;
size_t peak_allocated;
size_t allocation_count;
size_t free_count;
size_t failed_count;
};
// 在内存池结构中添加统计字段
typedef struct mp_pool_s {
// ... 其他字段
struct mp_pool_stats stats;
// ...
} mp_pool_t;
// 在分配函数中更新统计
void *mp_alloc_with_stats(mp_pool_t *pool, size_t size) {
void *p = mp_alloc(pool, size);
if (p) {
pool->stats.allocation_count++;
pool->stats.current_allocated += size;
if (pool->stats.current_allocated > pool->stats.peak_allocated) {
pool->stats.peak_allocated = pool->stats.current_allocated;
}
} else {
pool->stats.failed_count++;
}
return p;
}
4.3.4 性能分析
使用perf工具可以分析内存分配的热点和性能瓶颈:
# 记录内存分配相关事件
perf record -e kmem:kmalloc -e kmem:kfree -g ./your_program
# 分析性能数据
perf report
通过这些工具和技巧,开发者可以深入了解内存池的运行状态,及时发现并解决内存泄漏、性能瓶颈等问题。
5 总结与展望
通过对Linux内存池管理的深入分析,可以清晰地看到内存池技术在提高系统性能和可靠性方面的重要价值。从通用的genalloc到专门优化的slab分配器,再到保证可靠性的mempool,Linux内核提供了多层次、多场景的内存池解决方案。
5.1 内存池技术的核心价值
内存池技术的核心价值主要体现在以下几个方面:
- 性能提升:通过预分配和自定义分配策略,大幅减少了内存分配的时间开销,提供了更可预测的性能表现
- 碎片控制:通过固定大小分配、块合并等技术,有效减少了内存碎片,提高了内存利用率
- 可靠性保障:在内存紧张情况下,通过后备机制确保关键路径的内存分配不会失败
- 局部性优化:将相同类型的对象集中存储,提高了CPU缓存命中率,减少了缓存抖动
5.2 实践建议
在实际项目中应用内存池技术时,考虑以下建议:
- 避免过度设计:在性能要求不是特别苛刻的场景,优先使用系统提供的内存分配机制
- 针对性优化:根据应用的特有访问模式设计定制化的内存池,如网络服务器可以考虑连接专用的内存池
- 全面测试:内存池的实现需要经过严格测试,特别是并发安全和边界情况测试
- 监控集成:在生产环境中集成完善的内存监控,及时发现内存泄漏和性能问题
 发表于 2025-11-30 01:10:25
|
查看: 171|
回复: 0
发表于 2025-11-30 01:10:25
|
查看: 171|
回复: 0
