前言
去年负责一个老旧订单系统的容器化改造,这个系统运行了近8年,代码量超过50万行,日订单峰值达到200万笔。改造过程中踩了不少坑,也积累了一些经验。这篇文章不谈理论,只聊实战中遇到的问题和解决方案。
从传统虚拟机迁移到K8s,不是简单的“docker build + kubectl apply”,背后涉及架构改造、状态管理、网络重构、监控体系升级等一系列工程问题。很多团队在这个过程中要么操之过急导致生产故障,要么畏手畏脚拖了一两年还没完成。
本文会结合实际案例,分享容器化改造的完整路径,包括前期评估、技术选型、分阶段迁移、风险控制等关键环节。
目录
- 传统系统的典型痛点
- 容器化改造的整体策略
- 迁移路径的三种模式
- 技术难点与实战解决方案
- 生产环境的平滑切换
一、传统系统的典型痛点
1.1 环境不一致带来的噩梦
“开发环境正常,测试环境有问题,生产环境又是另一种状态”——这是传统部署模式最常见的问题。某次大促前一天,测试通过的版本上线后出现了依赖库版本冲突,定位问题花了3个小时,回滚又花了1个小时。
传统虚拟机模式下,每台机器的环境都可能存在细微差异:
- CentOS版本不统一,有7.6也有7.9
- JDK版本混乱,同一个应用在不同机器上用的可能是1.8.0_181或1.8.0_291
- 系统配置参数(ulimit、内核参数)经常被手动修改过
- 依赖的第三方组件版本不一致
这些问题在小规模场景下还能靠人工管控,但当服务器数量超过100台,应用数量超过50个时,环境管理就成了灾难。
1.2 资源利用率低下
传统部署模式下,为了应对峰值流量,通常会预留大量冗余资源。实际测算下来,大部分虚拟机的CPU利用率常年在15%-25%之间,内存利用率也只有30%左右。
更糟糕的是扩容速度慢。每次大促前,运维团队需要提前两周申请资源、配置环境、部署应用,整个流程下来至少需要一周时间。而活动结束后,这些机器又要保留很长时间才能下线。
1.3 发布效率拖累业务
传统发布流程复杂且耗时:
- 打包构建:10-15分钟
- 上传制品到跳板机:5分钟
- 逐台部署:每台3-5分钟,20台机器就是60-100分钟
- 重启服务:每台2-3分钟
- 验证健康检查:10分钟
一次完整的发布流程下来,至少需要1.5-2小时。如果发现问题需要回滚,又要再来一遍。
这种发布效率直接拖累了业务迭代速度。产品经理提的需求,开发完成后要等一周才能排上发布窗口,错过了很多市场机会。
二、容器化改造的整体策略
2.1 不要激进,分阶段推进
见过太多团队想一口气把所有系统都容器化,结果搞得团队焦头烂额,最后不得不回滚。容器化改造是个系统工程,需要分阶段、有计划地推进。
我们采用的策略是“试点-扩散-全面铺开”三步走:
第一阶段(1-2个月):选择无状态服务试点
选择2-3个无状态的Web服务作为试点,这类服务改造成本最低,风险最可控。通过试点验证技术方案、积累经验、培养团队能力。
第二阶段(3-6个月):扩散到核心业务
将试点经验推广到核心业务系统,重点解决有状态服务、数据库连接池、会话保持等复杂问题。这个阶段会遇到各种挑战,需要投入足够的时间打磨方案。
第三阶段(6-12个月):全面铺开
建立标准化的容器化改造流程和工具链,批量推进剩余系统的迁移。到这个阶段,团队已经有足够的经验和工具支撑,改造效率会大幅提升。
2.2 架构演进路径
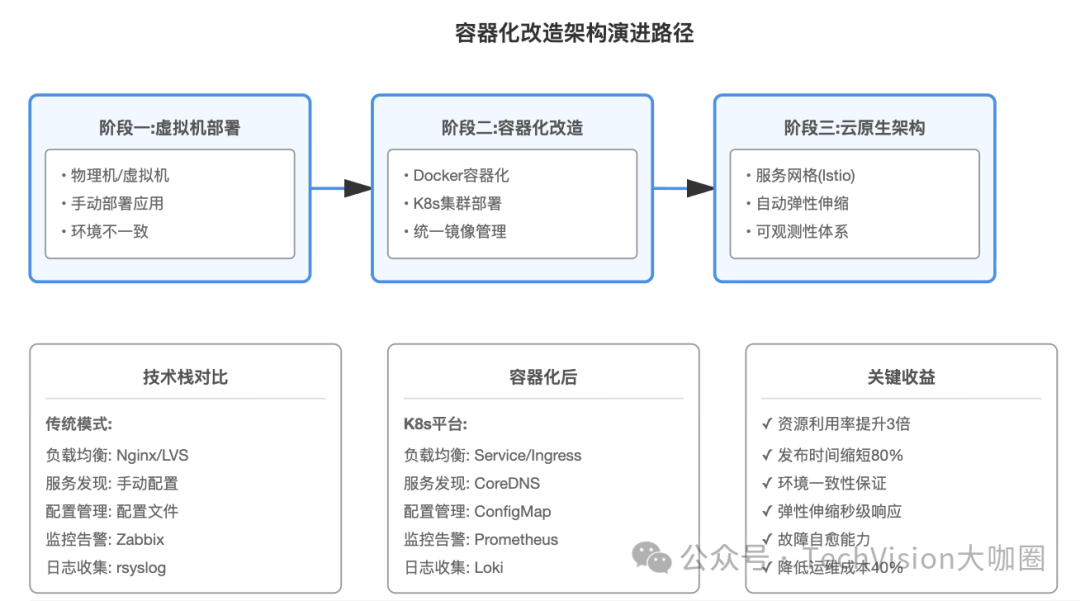
2.3 技术选型要点
容器运行时:选择containerd而不是Docker,性能更好,资源占用更低。K8s从1.24版本开始已经移除了对dockershim的支持,使用containerd是主流趋势。
网络插件:根据实际场景选择。如果是云环境,用云厂商提供的VPC-CNI性能最好;自建机房可以考虑Calico或Cilium。我们最终选择了Cilium,支持eBPF加速,网络性能损耗控制在5%以内。
存储方案:无状态服务用emptyDir或hostPath就够了;有状态服务需要持久化存储,可以选择Ceph RBD或云厂商的块存储。注意做好存储性能测试,IOPS和延迟对数据库类应用影响很大。
Ingress控制器:Nginx Ingress是最成熟的方案,但Traefik和Envoy也值得考虑。Traefik的动态配置能力很强,Envoy的性能更好。我们用的是Nginx Ingress,主要是团队对Nginx比较熟悉,出问题好排查。
服务网格:不要一开始就上Istio,太重了。等容器化稳定后再考虑。如果真要用,Linkerd比Istio轻量很多,适合中小规模场景。
三、迁移路径的三种模式
3.1 重构式迁移(推荐)
这是最彻底也是收益最大的方式。把应用代码按照云原生最佳实践重新梳理,拆分单体应用为微服务,改造成完全无状态架构。
适用场景:代码质量较差、技术债务严重、需要长期维护的核心系统。
改造重点:
- 去除对本地文件系统的依赖,文件存储改用对象存储
- 去除服务器级别的缓存,统一使用Redis等分布式缓存
- 配置外部化,全部通过环境变量或配置中心获取
- 日志统一输出到stdout/stderr,不落盘
- 健康检查接口标准化
实际案例:我们的订单服务原本有一个定时任务,每天凌晨把订单数据导出到本地CSV文件,然后通过FTP传给财务系统。容器化改造时,我们把这个逻辑改成了:
- 定时任务改用CronJob
- 数据导出改为直接写到S3对象存储
- 财务系统改为从S3读取数据
改造后的系统完全无状态,可以随意销毁和重建容器,不用担心数据丢失。
3.2 重新打包式迁移(快速方案)
如果应用代码改动成本太高,可以采用“最小改动”策略,只做容器化封装,不改架构。
改造步骤:
- 编写Dockerfile,把应用和依赖环境打包成镜像
- 把配置文件通过ConfigMap挂载
- 把日志目录挂载为hostPath或持久化卷
- 编写K8s部署文件
这种方式改造快,但保留了很多传统架构的问题。比如日志还是落盘,配置还是文件形式,健康检查可能不完善。
适用场景:临时方案、遗留系统、计划淘汰的老系统。
3.3 平台封装式迁移(不推荐)
有些团队为了快速完成容器化,会开发一个自动化平台,把传统部署流程包装成容器化部署。表面上容器化了,实际上还是老一套。
这种方式的问题是:
- 没有真正发挥容器化的优势
- 维护两套部署体系,成本更高
- 迁移完成后还要二次改造
除非有特殊原因(如政策要求必须容器化),否则不建议这么做。
四、技术难点与实战解决方案
4.1 会话保持问题
传统应用很多依赖Session粘滞,容器化后Pod会频繁重建,Session粘滞失效导致用户登录态丢失。
解决方案:
方案一是改用JWT或Redis存储Session。这是最彻底的方案,但需要改代码。我们的做法是在Nginx Ingress上配置基于Cookie的会话保持:
nginx.ingress.kubernetes.io/affinity: "cookie"
nginx.ingress.kubernetes.io/session-cookie-name: "route"
nginx.ingress.kubernetes.io/session-cookie-expires: "3600"
nginx.ingress.kubernetes.io/session-cookie-max-age: "3600"
方案二是使用源IP哈希。在Service上配置 sessionAffinity: ClientIP ,但这种方式在有反向代理的场景下可能失效。
4.2 配置管理迁移
传统应用的配置文件有几十个,分散在不同目录,还有环境变量、启动参数等。容器化后如何管理这些配置?
我们的实践是分层管理:
第一层:镜像内固化配置
不会变的基础配置直接打入镜像,比如JVM参数、日志配置模板等。
第二层:ConfigMap管理通用配置
应用配置文件、数据库连接串等通过ConfigMap管理,挂载到容器内。
第三层:Secret管理敏感信息
密码、证书等敏感信息用Secret存储,运行时通过环境变量注入。
第四层:配置中心管理动态配置
需要热更新的业务配置接入Apollo或Nacos配置中心。
4.3 存储迁移策略
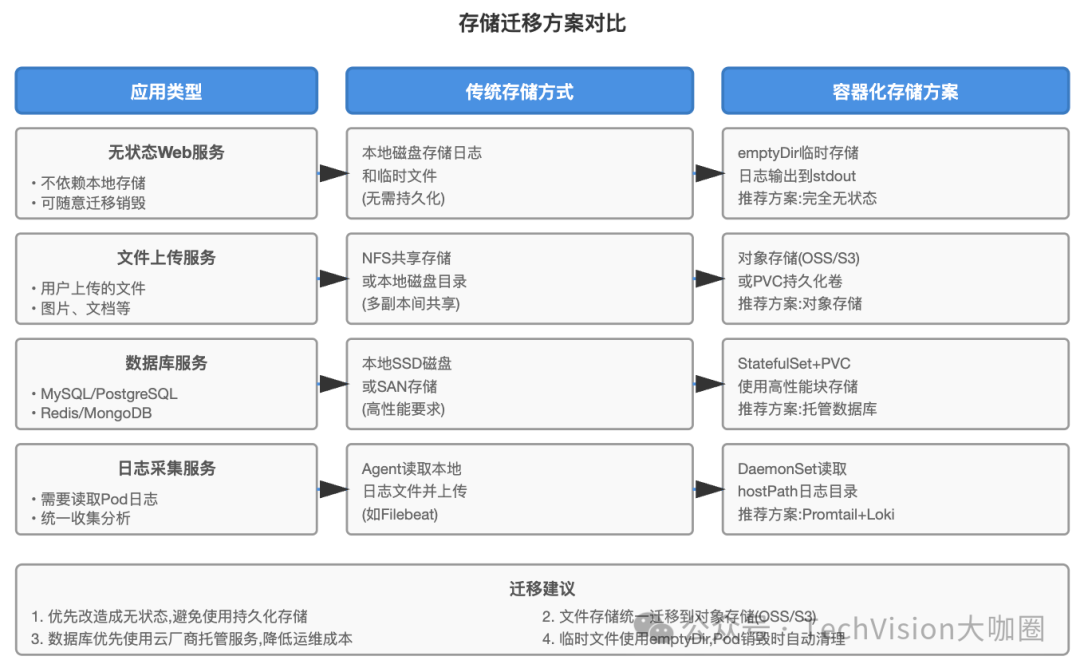
有个血泪教训:某次我们把一个报表服务容器化,没有做存储迁移,直接用hostPath挂载了生成的Excel文件。结果Pod迁移到其他节点后,找不到之前生成的文件,导致用户下载失败。后来改成直接上传到OSS,问题才解决。
4.4 网络访问控制
传统环境下,我们通过防火墙规则和安全组控制服务间访问。容器化后,IP是动态分配的,原有的网络策略失效。
K8s的NetworkPolicy可以解决这个问题,但很多团队没用起来。我们的实践是:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: order-service-policy
spec:
podSelector:
matchLabels:
app: order-service
policyTypes:
- Ingress
ingress:
- from:
- podSelector:
matchLabels:
app: api-gateway
ports:
- protocol: TCP
port: 8080
这个策略限制只有api-gateway可以访问order-service的8080端口,其他服务访问会被拒绝。
4.5 监控体系重构
传统监控系统(如Zabbix)是基于主机的,容器化后需要切换到基于容器和服务的监控。
我们采用的方案是:
- 基础设施监控:Node Exporter + Prometheus,监控节点CPU、内存、磁盘等
- 容器监控:cAdvisor + Prometheus,监控容器资源使用情况
- 应用监控:业务指标通过Prometheus客户端暴露,如QPS、响应时间、错误率
- 日志监控:Promtail + Loki,替代ELK,更轻量
- 链路追踪:Jaeger,定位跨服务调用问题
有个坑要注意:Prometheus默认只保留15天数据,长期数据要接入Thanos或Victoria Metrics做远程存储。
五、生产环境的平滑切换
5.1 灰度发布策略
不要直接全量切换,风险太大。我们的灰度策略是:
第一步:新建K8s集群,部署新版本,只接入1%流量
第二步:观察24小时,监控指标、错误日志、用户反馈
第三步:逐步放量到5% → 10% → 30% → 50%
第四步:确认无问题后,全量切换
每次放量后都要观察至少2小时,发现问题立即回滚。我们用Nginx的split_clients模块实现流量灰度:
split_clients "${remote_addr}" $backend {
1% k8s_backend;
* traditional_backend;
}
5.2 双环境并行
在灰度期间,传统环境和容器环境同时运行,做好快速切换准备。
关键配置:
- DNS配置两套A记录,权重可调
- 数据库使用主从同步,两边共享数据
- Redis使用同一个集群,避免数据不一致
- 消息队列共用,确保消息不丢失
双环境并行会增加成本,但这是平滑迁移的必要代价。我们并行运行了2个月,确认容器环境完全稳定后才下线传统环境。
5.3 回滚预案
一定要准备回滚预案,包括:
- 流量切换预案(DNS切换、Nginx配置切换)
- 数据回滚预案(数据库回滚脚本)
- 配置回滚预案(保留老配置)
- 应急联系人和值班安排
我们经历过一次凌晨回滚。容器环境上线后,发现数据库连接池配置不当,导致连接数暴增。DBA通过DNS快速切回传统环境,整个过程只用了5分钟。这要感谢提前准备的回滚预案。
5.4 关键数据对比
在灰度期间,要对比两个环境的关键数据:
- 订单量、交易额是否一致
- 接口响应时间对比
- 错误率对比
- 资源使用情况对比
我们写了脚本自动拉取两边的数据做对比,每小时生成一份报告发到告警群。发现异常立即介入排查。
六、总结
容器化改造是个系统工程,不是简单的技术替换。整个过程中,有几点体会:
技术层面:不要追求一步到位,先解决核心问题,再逐步完善。很多特性(如服务网格、混沌工程)可以等系统稳定后再引入。
流程层面:建立标准化的改造流程和检查清单,让团队其他成员也能独立完成改造。我们后期的改造效率能提升3倍,就是靠流程标准化。
团队层面:容器化不只是运维的事,需要开发、测试、DBA共同参与。前期多投入时间培训,后期会省很多麻烦。
风险控制:宁可慢一点,也不要急于求成。每个阶段充分验证,确保万无一失再推进。我们整个改造周期拉了10个月,但没出过一次生产故障。
最后说一句,容器化不是目的,是手段。最终目标是提升研发效能,降低运维成本,支撑业务快速发展。不要为了容器化而容器化。如果你对相关技术的进一步探讨感兴趣,也可以到专业的云栈社区与更多开发者交流实战经验。
 发表于 2026-1-19 20:15:35
|
查看: 214|
回复: 0
发表于 2026-1-19 20:15:35
|
查看: 214|
回复: 0
