AI 编码工具的发展速度快得让人应接不暇。从早期 GitHub Copilot 的代码补全,到如今 Claude Code、Cursor、Comate IDE 等能够自主完成复杂编程任务,AI 已不再是简单的「智能补全工具」。它能够理解你的代码库、执行终端命令、甚至协助调试问题,正在演变为真正的“编码伙伴”。
在团队中推广这类工具时,我发现一个有趣的现象:大家虽然都在用,却很少有人真正理解其工作原理。有人觉得它“很神奇”,有人吐槽它“经常出错”,还有人担心“会不会把代码搞乱”。这些困惑的背后,其实都指向同一个核心问题——我们对这位“伙伴”还不够了解。
就像你不会盲目信任一个新同事一样,要与 AI 编码伙伴高效协作,你必须清楚它的工作方式、能力边界以及如何进行有效“沟通”。基于对多个开源项目的源码研究与实践经验,我将在本文系统性拆解 Coding Agent 的工作原理,旨在帮助开发者在深入了解后,能与 AI 伙伴更好地协作,提出更高效的问题并获得有效结果。
01 背景:从固定工作流到智能体
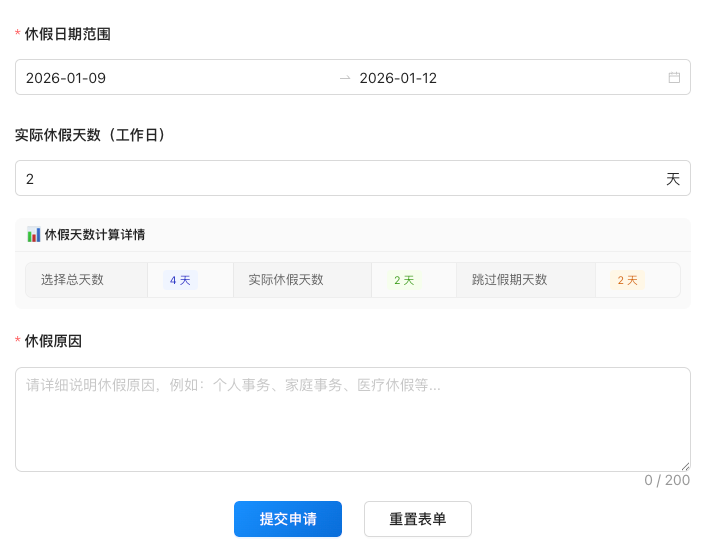
让我们从一个实际例子开始:申请休假。
如果你的需求非常简单:“一键申请明天的休假”。这个需求可以简化为一个固定的工作流:
- 打开网页。
- 填写起始时间。
- 填写结束时间。
- 填写休假原因。
- 提交表单。
整个过程没有任何模糊的输入,通过程序化脚本即可完成,这是最原始的工作流形态。
如果需求变得模糊一些:“申请后天开始3天休假”。这个需求没有明确的起止时间,需要从语义上进行分析:
- 起始时间:后天。
- 休假时长:3天。
- 转换日期:计算出具体日期范围。
- 执行申请:提交表单。
这是一个在工作流中使用大模型提取部分参数的典型案例,是模型与工作流的结合。
如果需求更加模糊:“国庆后休假连上下个周末”。这样的需求几乎没有任何直接确定日期的信息,同时由于年份、休假安排等动态因素,大模型不具备直接提取参数的能力。将它进一步分解,需要一个动态决策、逐步分析的过程:
- 知道当前年份。
- 知道对应年份的国庆休假和调休安排。
- 知道国庆后第一天是星期几。
- 将国庆后第一天到下个周末设为休假日期。
- 额外补充调休的日期。
- 填写并提交表单。
可以看到,其中1-5步都是用来最终确定休假日期的,且需要外部信息输入,单独的大模型无法直接完成。这是一个典型的Agent流程,通过大模型的智能与工具访问外部信息相结合来实现用户需求。
02 核心概念:什么是Agent与Coding Agent
2.1 什么是Agent
简单来说,Agent是以大模型为核心,为满足用户的需求,使用一个或多个工具,自动进行多轮模型推理,最终得到结果的工作机制。
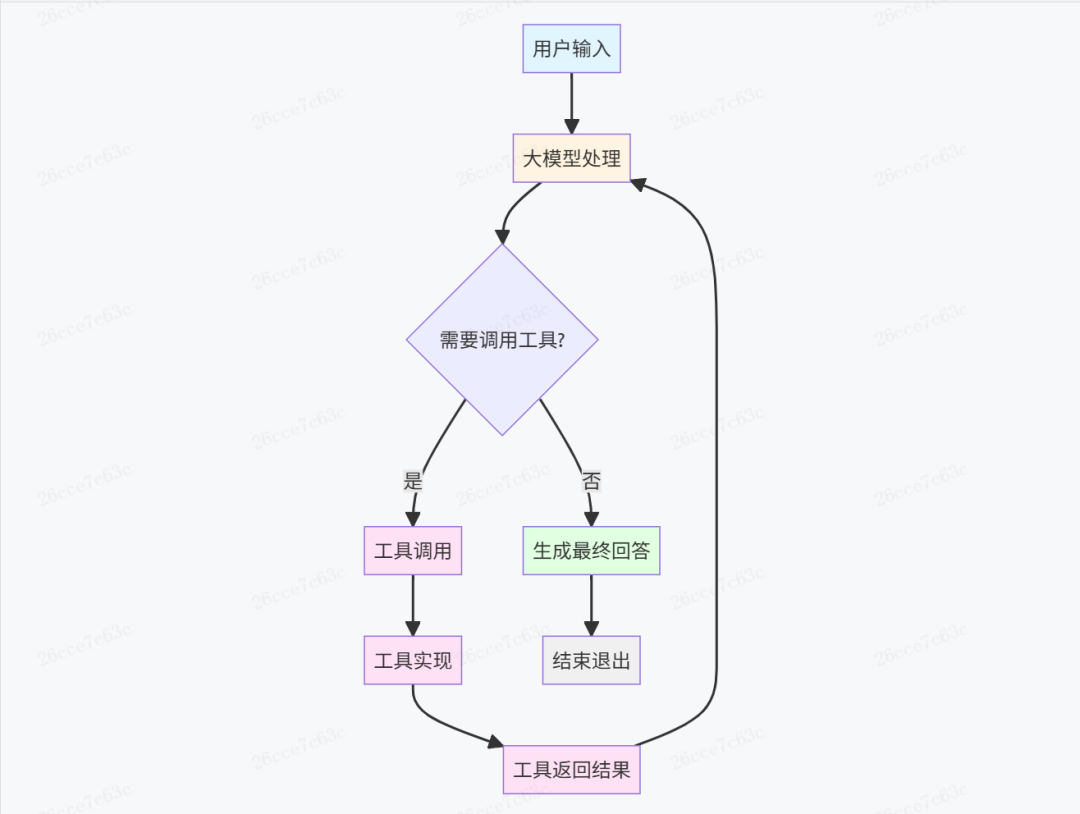
2.2 什么是Coding Agent
在Agent基本定义的基础上,通过提示词、上下文、工具等元素强化“编码”这一目的,所制作的特化Agent即为Coding Agent。
Coding Agent的最大特征是在工具的选取上,它模拟工程师进行代码编写的环境,提供一套完整的编码能力,包括:
- 阅读和查询代码:
- 读取文件,对应
cat 命令。
- 查看目录结构,对应
tree 命令。
- 通配符查找,对应
ls 命令(如 **/*.test.ts 、 src/components/**/use*.ts )。
- 正则查找,对应
grep 命令(如 function print\(.+\) 可以找函数定义)。
- LSP(Language Server Protocol),用于提供查找定义、查找引用、检查代码错误等能力。
- 编写或修改代码:
- 执行或交互命令:
- 执行终端命令。
- 查看终端命令
stdout 输出。
- 向终端命令
stdin 输入内容。
除此之外,Coding Agent通常还具备一些为强化效果而设定的工具,表现为与Agent自身或外部环境进行交互,例如常见的TODO、MCP、Subagent等。
03 内部组成:拆解Coding Agent的三大支柱
3.1 上下文结构
一个Coding Agent在调用大模型时,其输入(上下文)是一个精心组织的结构。
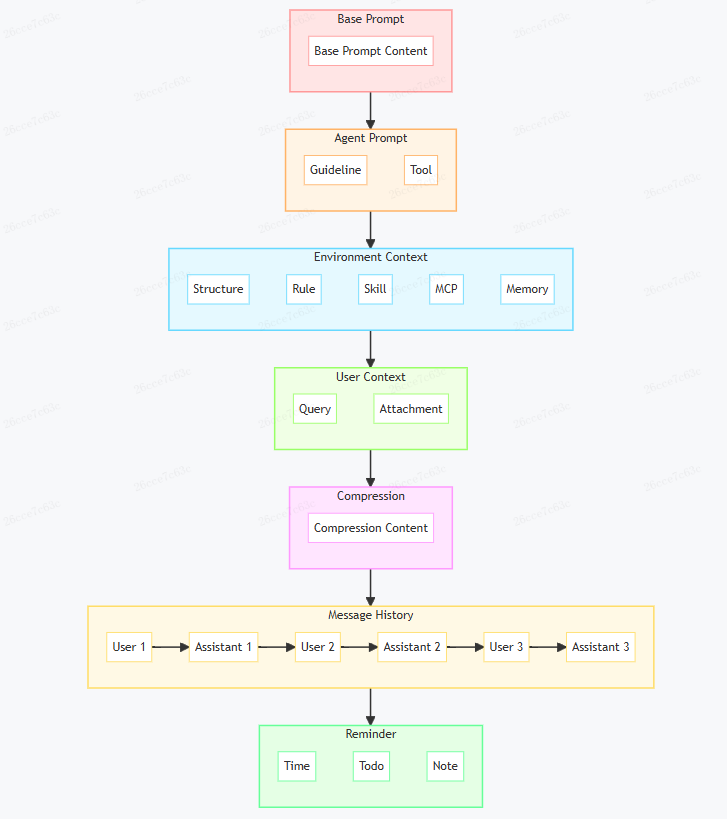
3.2 身份定义
Agent首先会将模型定义成一个具体的身份。例如,你可能会看到这样的系统提示词开头:“You are a Senior Front-End Developer and an Expert in React, Next.js, JavaScript, TypeScript...”。
在身份基础上,再附加工作的目标和步骤拆解。以Cline项目为例,其系统提示词中包含了清晰的目标和行动准则(Guideline),例如分析任务、设定目标、顺序执行、使用工具前思考等。
有些Coding Agent支持在多种模式(或称智能体)间切换,例如Cursor的Edit、Ask、Plan模式,RooCode的Architect、Orchestrator模式。选择不同模式时,会产生不同的目标要求和行为准则,即不同的Guideline。因此,系统提示词中的身份部分,通常会分成不变的Base Prompt和可变的Agent Prompt两部分来管理,实际开始任务时再拼装起来。
3.3 工具调用
工具是Agent的核心组成部分。没有工具,就无法称之为Agent。要让Agent使用工具,必须提供两部分信息:1. 有哪些工具可用及其作用;2. 如何指定使用一个工具。
在开发中,一个工具通常被视作一个函数,由以下几部分定义:
- 名称。
- 参数结构。
- 输出结构。
实际调用模型时,“输出结构”往往不需要提供给模型,但会在实现中预先定义好。“名称”和“参数结构”会组合成一个结构化定义,通常所有工具只接收1个参数(对象类型),并用JSON Schema表示参数结构。
一个典型的工具定义(读取文件):
{
"name": "read",
"description": "Read the contents of a file. Optionally specify line range to read only a portion of the file.",
"parameters": {
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "The file path to read from"
},
"lineStart": {
"type": "integer",
"description": "The starting line number (1-indexed). If not specified, reads from the beginning of the file."
},
"lineEnd": {
"type": "integer",
"description": "The ending line number (1-indexed). If not specified, reads to the end of the file."
}
},
"required": ["path"]
}
}
这可以简单理解为对应的TypeScript接口:
interface ReadToolParameter {
path: string;
lineStart?: number;
lineEnd?: number;
}
async function read(parameters: ReadToolParameter) {
// 工具实现
}
关于“如何指定使用工具”,业界通常有两种主流做法。
第一种(Function Calling格式),以Claude Code、Cursor等为典型:
- 调用大模型时,通过
tools 字段传递所有工具定义。
- 模型返回的消息中包含
tool_calls 字段,每个对象代表一个工具调用,有唯一的 id。
- 工具执行结果,以一条
role: 'tool' 的消息返回,其中 tool_call_id 与调用的 id 对应, content 是工具结果(不同模型厂商实现略有差异)。
第二种(自定义文本格式),以Cline、RooCode为典型,使用XML等自定义文本格式来表示工具调用。例如,Cline中读取一个文件:
<read_file>
<path>src/index.ts</path>
</read_file>
只要模型返回的消息中出现此结构,就会被解析为工具调用。结果以普通的 role: 'user' 消息返回,包含实际内容和一些提示信息。
3.4 环境感知
Coding Agent能在一个代码库上执行任务,除了通过工具遍历、检索代码外,另一个关键因素是Agent实现会在调用模型时主动提供一部分与项目相关的信息。
其中最有用的信息之一是代码库的目录结构树。这部分信息通常符合以下特征:
- 尽可能保留层级结构,使用换行和缩进表达。
- 遵循
.gitignore 等项目配置,被忽略的文件不会显示。
- 当内容过多时,有裁剪策略,但同时尽可能多地保留信息。
以Cursor为例,这部分内容大致如下:
<project_layout>
Below is a snapshot of the current workspace‘s file structure at the start of the conversation. This snapshot will NOT update during the conversation. It skips over .gitignore patterns.
codex-cursor/
- AGENTS.md
- CHANGELOG.md
- cliff.toml
- codex-cli/
- bin/
- codex.js
- rg
- Dockerfile
- package-lock.json
- package.json
- scripts/
- build_container.sh
- build_npm_package.py
- init_firewall.sh
- [+4 files (1 *.js, 1 *.md, 1 *.py, ...) & 0 dirs]
- codex-rs/
- ansi-escape/
- Cargo.toml
- README.md
- src/
- lib.rs
</project_layout>
当内容数量超过阈值时,会采用广度优先的保留策略(尽可能保留上层目录结构),对被隐藏的文件或子目录,会以 [+4 files (1 *.js, 1 *.md, 1 *.py, ...) & 0 dirs] 的形式保留文件类型和数量信息。
除了目录结构,还有一系列默认需要模型感知的信息,通常分为两大类:
- 系统信息:
- 操作系统(Windows、macOS、Linux,具体版本)。
- 命令行语言(Shell、Powershell、ZSH)。
- 常见终端命令是否已安装(
python3 、 node 、 jq 、 awk 等,包含具体版本)。
- 代码库目录的绝对路径。
- 为Agent扩展能力的信息:
- Rule(自动激活的部分)。
- Skill(摘要描述部分)。
- MCP(需要的Server和Tool列表)。
- Memory(通常是全量)。
需要注意的是,环境信息一般不出现在系统提示词中,而是和用户提问的消息放置在一起。
3.5 动手实现一个最小化Coding Agent
在理解了身份定义、工具调用、环境感知这三大基础组成后,简单地使用大模型API,进行自动化的工具调用解析、执行和发起新一轮模型调用,就可以实现一个最小化的Coding Agent。
你可以尝试用以下提示词,使用现有的Coding Agent产品(如Cursor、Claude Code),让它为你编写一个实现,并亲自调试,以直观感受Coding Agent的基础逻辑:
我希望基于大模型实现一个Coding Agent,以下是我的具体要求:
1. 使用Claude作为模型服务商,使用环境变量管理我的API Key。
2. 默认使用Claude Sonnet 4.5模型。
3. 使用Anthropic's Client SDK调用模型。
4. 不需要支持流式输出。
5. 使用TypeScript编写。
以下是Agent提供的工具:
1. read({path: string}):读取一个文件的内容
2. list({directory: string}):列出一个目录下的一层内容,其中目录以`/`结尾
3. write({path: string, content: string}):向文件写入内容
4. edit({path: string, search: string, replace: string}):提供文件中的一块内容
以下是交互要求:
1. 通过NodeJS CLI调用,支持`query`和`model`两个参数,可以使用`yargs`解析参数。
2. 在System消息中,简短地说明Coding Agent的角色定义、目标和行为准则等。
3. 在第一条User消息中,向模型提供当前的操作系统、Shell语言、当前目录绝对路径信息,同时包含跟随`query`参数的内容,组织成一条模型易于理解的消息。
4. 对每一次模型的工具调用,在控制台打印工具名称和标识性参数,其中标识性参数为`path`或`directory`,根据工具不同来决定。
5. 如果模型未调用工具,则将文本打印到控制台。
请在当前目录下建立一个`package.json`,并开始实现全部的功能。
04 优质上下文工程:生产环境的关键技术
4.1 成本控制
大模型调用成本高昂。以Claude API定价为例:
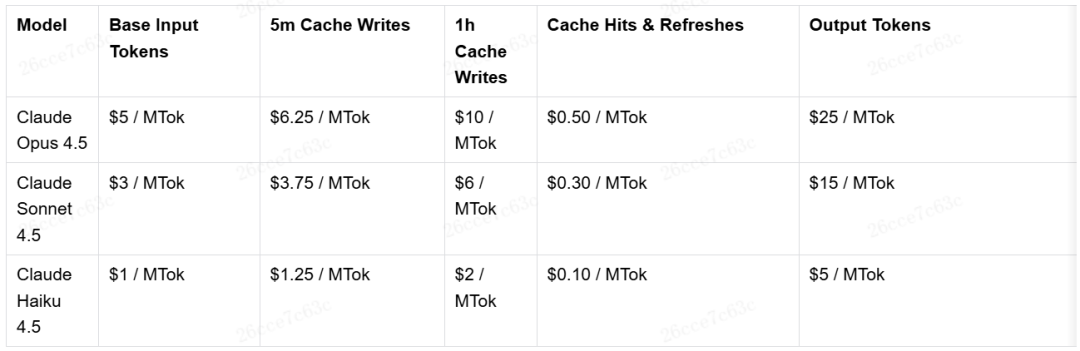
我们可以观察到:
- 输出令牌的价格约是输入的5倍。
- 缓存写入(Cache Writes)比正常输入(Base Input)贵约1.25倍。
- 缓存命中(Cache Hits)的价格非常便宜,仅为正常输入的1/10。
这意味着,一个良好利用缓存的Agent实现,其成本会比不用缓存降低8-10倍。因此,所有Coding Agent都会细致地梳理内容结构,最大化利用缓存。
在大模型API中,缓存通常以“块”为单位控制,例如系统提示词中不变的部分、可变部分、工具定义、每一条消息等。观察Claude关于缓存控制的文档可以发现,一旦各种参数发生变动,缓存会大量失效,导致成本急剧上升。
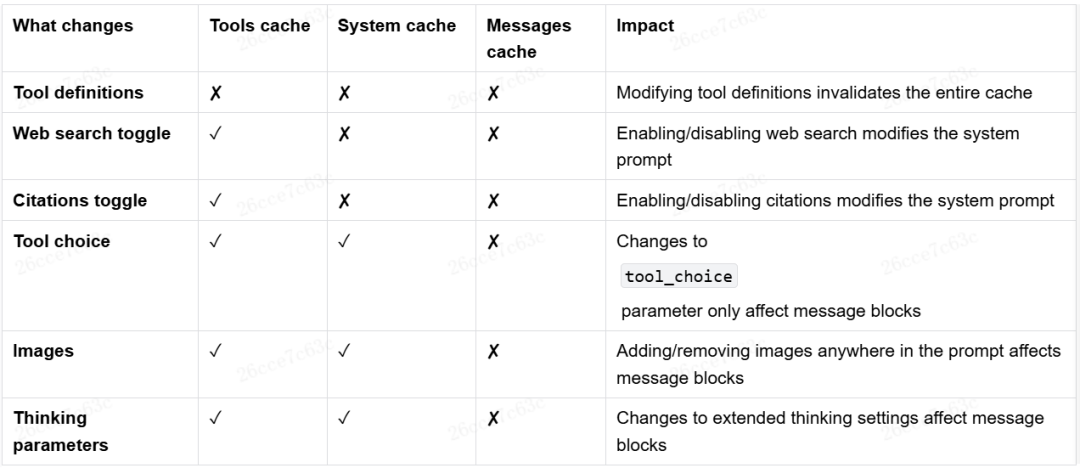
因此,在Coding Agent实现中,通常会从一开始就确定所有参数,整个任务期间不做任何变更。一些经典实例如下:
- 一次任务不会一部分消息开思考模式,一部分不开,因为思考参数会让全部的消息缓存失效。
- 切换不同模式时,虽然能使用的工具可能不同,但只是在消息中增加说明,而不会真的改变
tools 字段。
此外,Coding Agent会尽可能保持历史消息内容完全不变,以最大化消息缓存命中率。随意修改历史消息(如删除已读取的文件内容),看似减少了长度,实则破坏了缓存结构,可能导致成本成倍增加。
总而言之,缓存是至关重要的因素。Coding Agent的策略优化通常以确保缓存有效为前提,仅在非常必要的情况下才破坏缓存。
4.2 空间管理
Coding Agent会进行多轮交互,不断读入文件、命令输出等信息,上下文长度会变得非常大,而大模型通常只有128K左右的上下文限制。因此,如何将大量内容“适配”到有限长度中,是一个巨大挑战。
控制上下文长度的第一种方式是“裁剪”,即在上下文中删除没用的信息。考虑一个场景:模型读取了一个文件,然后连续修改了其中两行。如果每次修改后都返回完整的文件内容,一个1000行的文件经过1读2改,就会产生3000行的空间占用。
一种优化方式是,在这种连续的读-改场景下,只保留最后一条消息中的全文内容,中间步骤使用 unidiff 等形式保留编辑差异信息。这样可以最大程度降低空间占用,同时保留模型的推理逻辑。
但裁剪不能用于非连续的消息中。随意使用裁剪逻辑很可能破坏消息缓存结构,导致模型调用输入无法通过缓存处理,从而数倍增加调用成本。
即便进行了裁剪,随着更多内容进入上下文,最终空间还是会被占满。此时,Coding Agent通常会使用“压缩”技术,即通过模型将前文摘要成少量文字,同时保留关键的推理链路。
压缩通常在上下文使用率达到90%时触发,目标是将其压缩至10%的长度,腾出80%的空间供后续推理。压缩本身是一个由模型完成的任务,需要提供高质量的压缩要求。一个典型实现是Claude Code的“八段式摘要”法:
const COMPRESSION_SECTIONS = [
"1. Primary Request and Intent", // 主要请求和意图
"2. Key Technical Concepts", // 关键技术概念
"3. Files and Code Sections", // 文件和代码段
"4. Errors and fixes", // 错误和修复
"5. Problem Solving", // 问题解决
"6. All user messages", // 所有用户消息
"7. Pending Tasks", // 待处理任务
"8. Current Work" // 当前工作
];
通过将信息压缩成这8部分,能最大限度地保留工作目标、进度和待办事项。
4.3 独立上下文(Subagent)
在实践中,一个任务很少真的需要用完128K上下文,但体验上却常常感觉“上下文不够用”。这种差异主要源于两类情况:
- 为满足任务需要收集大量信息,但收集过程中引入了无效或错误内容。
- 复杂任务被分解为多个小任务,各自占用部分上下文,总和超出限制。
例如,任务“修改Webpack配置,让产出的JS文件大小平均”。假设项目中有6个 webpack.config.ts,目标配置在一个 optimization.ts 文件中。Agent可能需要:读取6个无用的配置文件 -> 读取10个被导入的模块 -> 找到目标文件 -> 反复修改并编译8次。其中大量步骤(读取无关文件、多次编译)都对最终目标无效,却可能占用超过150K上下文,迫使任务中途进行压缩。
为解决此问题,当前多数Coding Agent引入了“Subagent”概念。Subagent是一种类似子进程的,在独立的上下文空间中运行,与主任务仅进行必要信息交换的工作机制。
在上述案例中,使用Subagent可以将过程重构:
- 启动Subagent A:目标“找到Webpack文件拆分的代码”。完成查找后返回总结。
- 启动Subagent B:目标“修改配置,执行构建,返回不平均的文件”。完成一次优化尝试。
- 启动Subagent C:目标“分析构建统计,进一步优化配置,再次构建”。
- 循环启动更多Subagent,直到结果满意。
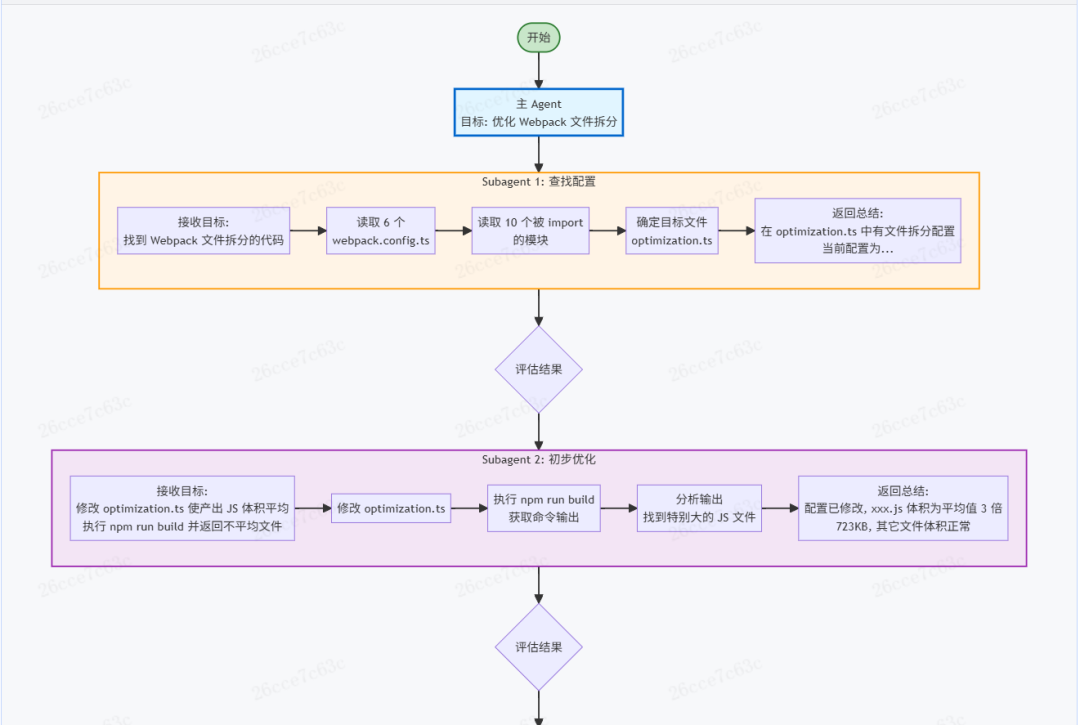
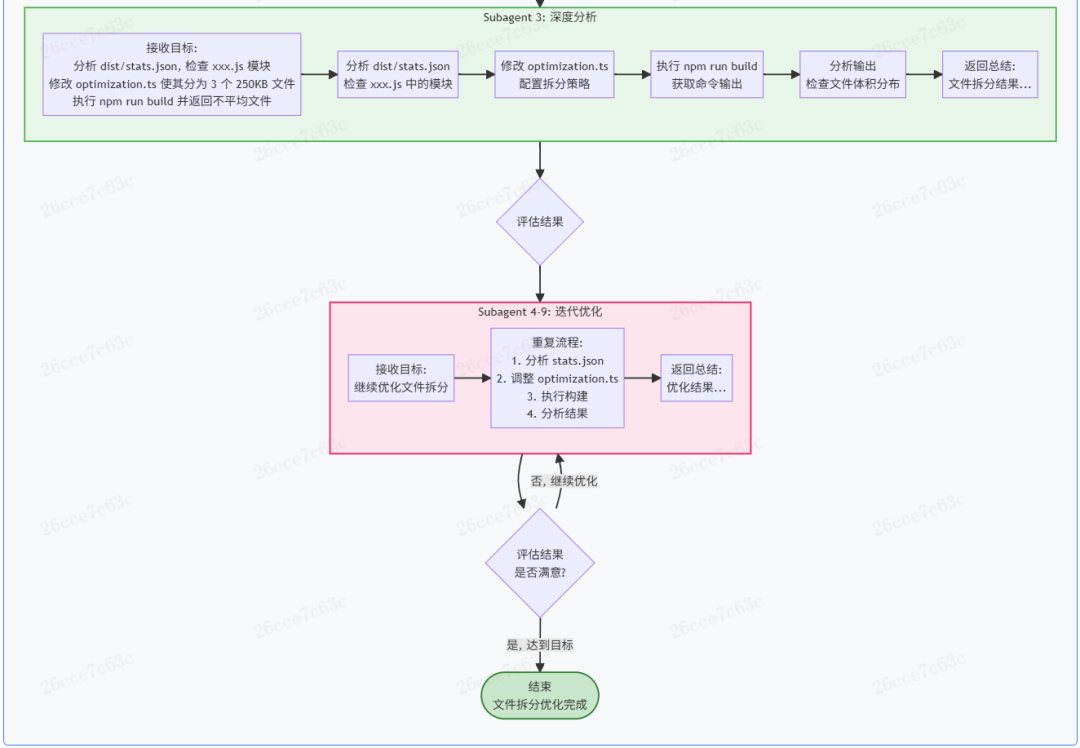
在这种模式下,主Agent实际上是在“指挥”Subagent做事,自身上下文占用很少。每个Subagent仅“专注”于一个小目标,也不需要太多上下文。通过这种不断开辟新上下文空间的方式,最终完成复杂任务。
4.4 注意力优化
在使用Coding Agent时,你可能会遇到这种情况:Agent做到一半忘了自己要做什么,草草结束或开始随机行为。这可能是由于裁剪、压缩导致信息丢失,但更多是因为简单的用户需求被大量代码、命令输出等推理过程淹没,权重弱化到不再被大模型“注意”到。
因此,Coding Agent的一个重要任务是在长时间运作中随时调整大模型的注意力,使其始终聚焦于最终目标。当前产品通常通过两个概念实现。
第一是 TODO。许多产品中,Agent会将任务分解为步骤,形成一个待办列表并始终显示。这个列表并不是给用户看的,而是给模型看的。
在实际实现中,每次调用模型时,会在最后一条消息(通常是工具调用结果)上增加一个“Reminder”区域。该区域始终出现在消息最后,在模型注意力中优先级更高,且绝对不会因其它因素而消失。
Reminder中可以放置多种内容:
- TODO及进度:让模型时刻理解目标、进展和待办。
<reminders>
- Planned todos:
- [x] Explore for code related to "print" function
- [x] Add "flush" parameter to function
- [ ] Refactor all "print" function calls to reflect the new parameter
</reminders>
- 工具子集:当切换模式导致可用工具减少时,为避免破坏缓存,仅在Reminder中说明部分工具不可用,由模型遵循约束。
<!-- 切换至Ask模式 -->
<reminders>
- You can ONLY use these tools from now on:
- read
- list
- grep
- bash
</reminders>
- 行为指示:当模型陷入不合理循环时(如重复相同工具调用),在Reminder中增加提示,帮助其调整。
- 状态提示:例如激活某个Skill时,提示“当前正在使用X Skill”,让模型更专注。
需注意,Reminder仅在最后一条消息中出现,当有新消息时,旧消息上的Reminder会被移除。因此,Reminder永远无法命中缓存,其内容长度需要严格控制,以避免成本过高。
4.5 冲突管控
随着Coding Agent能力的增强,任务时间变长,编辑文件增多,用户也习惯在Agent工作时并行编码,甚至并发多个Agent任务。这种“协同”模式下,可能会出现“自己修正了Agent生成的代码,之后Agent又把代码改回去”的问题。
基本原因是Agent并不知道你改动过代码。假设Agent读取并编辑了一个文件,在模型的上下文中,该文件内容已被更新。如果你之后手动修改了该文件,模型后续的编辑仍会基于它记忆中的旧内容进行,造成冲突。
解决文件编辑冲突的常见方法:
- 加锁法(主流):Agent读取/编辑文件时,记录文件内容快照。当再次编辑该文件时,读取实际内容并与快照比对。若不同,则拒绝编辑,并要求Agent重新读取文件(更新快照)后再编辑。实现细节较重。
- 推送法:监听所有被Agent操作过的文件的变更。当文件变更时,在下一次模型调用的Reminder区域追加变更通知,让模型“实时”感知变化,直到文件被再次读取。这种方式能让模型更早感知变化,但推送信息可能过多,影响成本和推理速度。
- 隔离法:使用Git Worktree方案,让不同Agent任务在文件系统上隔离(独立Git分支),互不干扰。任务完成后,用户检查并合并变更。这种方法让Agent根本不需要考虑冲突,但系统资源占用高,且有合并冲突风险。
除了文件编辑,还有其他冲突类型,例如终端命令抢占(用户在输入命令时Agent执行了另一个命令)。这类冲突相对容易解决,通常让每个Agent任务独占自己的终端即可。
4.6 持久记忆
我们知道,模型本身是无状态的。每次Agent执行任务,对于项目或用户的偏好,都像是从头开始。这相当于历史经验无法积累。虽然可以通过Rule等方式持久化“经验”,但需要用户主动介入,成本较高。
因此,许多Coding Agent产品都在探索“记忆”能力,目标是让Agent用得越多越好用。记忆的真正难点在于:1. 如何触发记录;2. 如何消费使用;3. 什么内容值得作为记忆。
触发记忆的常见做法:
- 工具型:定义
update_memory 工具,将记忆作为字符串数组进行增删改,由模型在任务中实时决定调用。但模型通常不太主动使用这类工具。
- 总结型:每次对话结束后,将全部内容发送给模型,由其提取记忆并补充到存储中。但容易过度提取,将不必要的信息持久化。
- 存储型:不进行任何整理,将所有任务的原始过程全部存储为记忆,只在消费环节做精细处理。
消费记忆的常见做法:
- 始终附带:将记忆文件内容附带在每次模型请求中。这会加重模型认知负担,占用大量上下文空间,且很多记忆可能与当前任务无关。
- 渐进检索:不主动附带记忆,而是将其以文件系统形式存放,Agent可通过
read、 list、 grep 等工具检索。配合“存储型”触发,能让全量历史任务成为可检索的记忆。但这要求模型有很强的认知,能在正确时刻检索相关记忆。然而,模型往往根本不知道记忆里有什么,进而无法知道何时应该检索,导致几乎不触发。
定义记忆是当下最棘手的问题之一。错误或不必要的记忆可能导致任务效果下降。通常,记忆分为两大方向:
- 事实型:如“使用4个空格缩进”、“不要使用
any 类型”。这些是客观、无情感的事实。
- 画像型:如“用户更喜欢简短的任务总结”。这是对单个用户主观特征的描述。
在Coding Agent中,往往更倾向于记忆“事实型”内容。同时,业界也在探索模型底层的记忆能力,未来或许Agent实现不再需要关注记忆逻辑,模型自身将具备持久化记忆能力。
05 能力扩展:Rule、MCP与Skill
在实际应用中,还需要一些机制让Agent更好地适应特定项目、团队和个人习惯。当前主流的Coding Agent产品提供了Rule、MCP、Skill三种扩展能力,它们各有侧重。
5.1 Rule
当面对业务仓库中大量领域特定知识(非模型已有知识)时,这些需要凭借经验或阅读大量代码才能总结出的内容,适合放入Rule中,作为静态的、不频繁改动的内容,长期存在于环境上下文(Environment Context)中被缓存。
好的Rule应当足够精简、可操作且范围明确。人看不懂或描述不清的规则,模型肯定无法遵守。
- 将Rule控制在500行以内。
- 将较大的规则拆分为多个可组合的规则,按需激活。例如,可以为“API调用与错误处理”创建独立的Rule文件,并在索引Rule中写明激活条件(如“当编码涉及API调用时,必须阅读此规则”)。
- 提供具体示例或参考文件。
- 避免模糊的、交互式的指导。
- 告知模型正确的构建、测试命令,引导其验证改动。
5.2 MCP
MCP(Model Context Protocol) 是Anthropic提出的一种标准化工具扩展协议,它允许开发者以统一的方式为Coding Agent添加新能力。
与Rule的“声明式约束”不同,MCP是一种实时工具调用协议,通过连接MCP Server来扩展Agent能做的事情。一个典型场景是集成外部服务,例如连接GitHub MCP Server,让Agent能直接创建Issue、查询PR状态等。
{
"mcpServers": {
"github": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-github"],
"env": {
"GITHUB_PERSONAL_ACCESS_TOKEN": "<your-github-token>"
}
}
}
}
MCP的优势是实现门槛低。一个MCP Server本质是一个标准输入输出的程序,通过JSON-RPC协议与Agent通信。模型只需按照固定协议调用,无需关心其内部实现。
5.3 Skill
5.3.1 什么是Skill
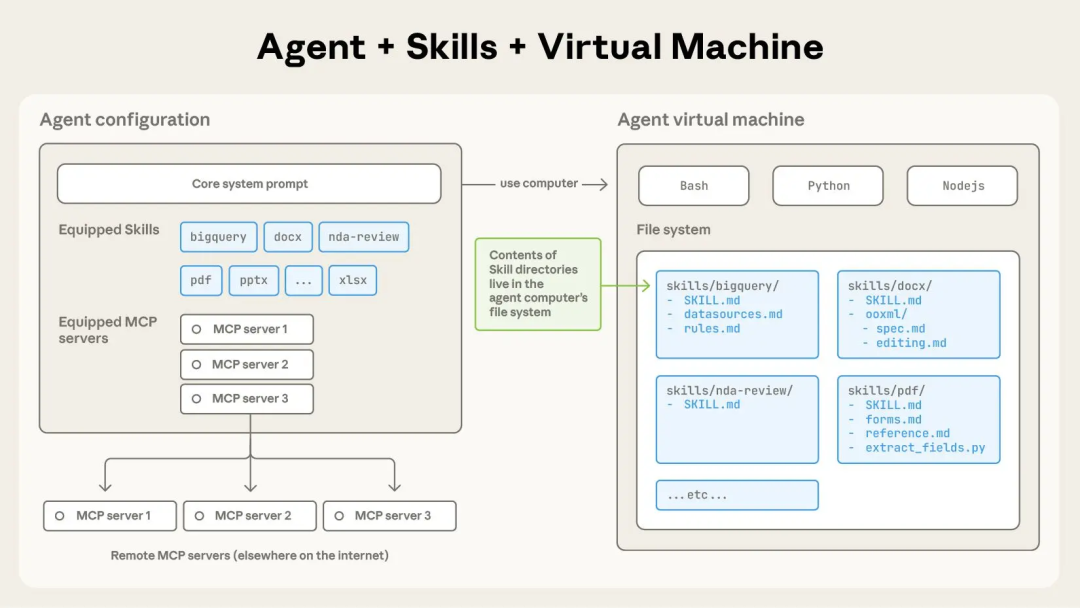
随着任务复杂度增加,我们需要更具可组合性、可扩展性的方法,为Agent配备特定领域的专业知识。Skill 作为一种为Agent扩展能力的标准应运而生。
Skill将指令、脚本和资源打包成一个文件夹,形成专业领域的知识包。Agent初始化时会获取可用Skill列表,并在需要时动态加载以执行特定任务。Skill是渐进式触发的,其 SKILL.md 文件中的 name 和 description 是关键,这些描述会始终存在于Agent的环境上下文中,模型据此决定是否触发该Skill。你也可以在Prompt中明确指定“使用xxx Skill完成任务”。
5.3.2 Skill和代码执行
大模型在许多任务上表现出色,但许多操作需要通过“编写代码 -> 执行代码”的方式来完成,以获得更高效、确定和可靠的结果。生成式模型常通过生成可执行代码来验证或计算结果。
在Skill中,代码既可以作为可执行工具,也可以作为文档。Skill应该明确告知模型,是应该直接运行某个脚本,还是应该将其作为参考信息读入上下文。
5.3.3 如何创建Skill
每个Skill由一个必需的 SKILL.md 文件和可选的bundle资源组成。Skill应只包含完成任务所需的信息。
skill-name/
├── SKILL.md (必需)
│ ├── YAML frontmatter 元数据 (必需)
│ │ ├── name: (必需)
│ │ ├── description: (必需,帮助模型理解何时使用该skill)
│ │ └── compatibility: (可选)
│ └── Markdown 说明 (必需)
└── bundle的资源 (可选)
├── scripts/ - 可执行代码 (Python/Bash/等)
├── references/ - 需要时加载到上下文的文档
└── assets/ - 用于输出的文件 (模板、图标、字体等)
例如,将项目从LESS迁移到PostCSS涉及一系列复杂步骤(安装依赖、配置、分析变量、替换mixin、转换语法等)。这可以通过清晰的流程描述和配套脚本实现,封装成一个 less-to-postcss Skill。
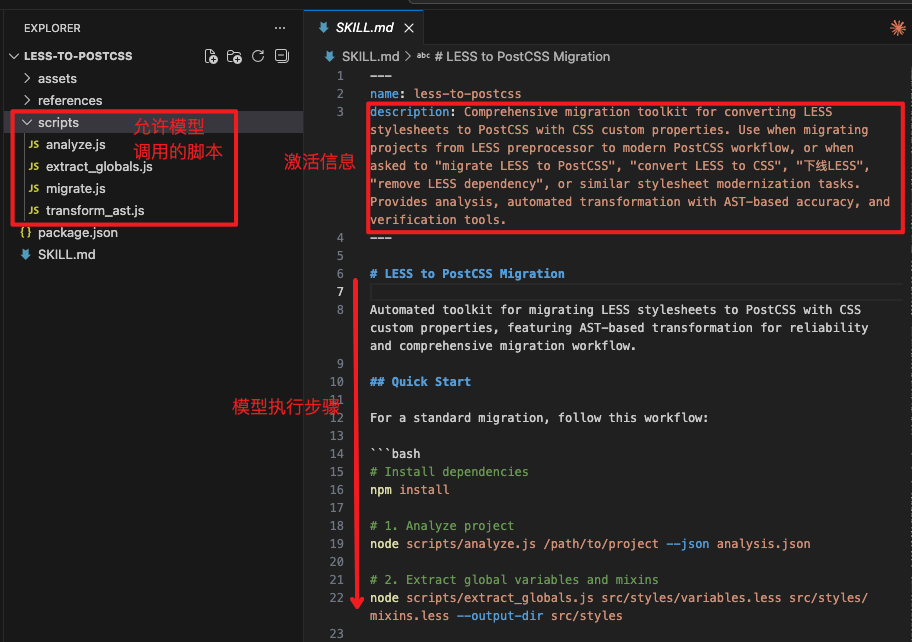
5.3.4 Skill的使用与选择
任何人都可以创建Skill,也可以让Agent来编写Skill,这赋予了很高的自由度。但这也意味着恶意Skill可能引入漏洞,因此务必仅从可信来源安装,并在使用前彻底审核。
Skill并非用于替代MCP,而是与之互补。Skill擅长在本地通过执行 code 完成复杂、确定的流程;而MCP Server则适合处理需要查询用户私有数据、动态数据或外部服务的场景。两者结合可以完成更复杂的流程。
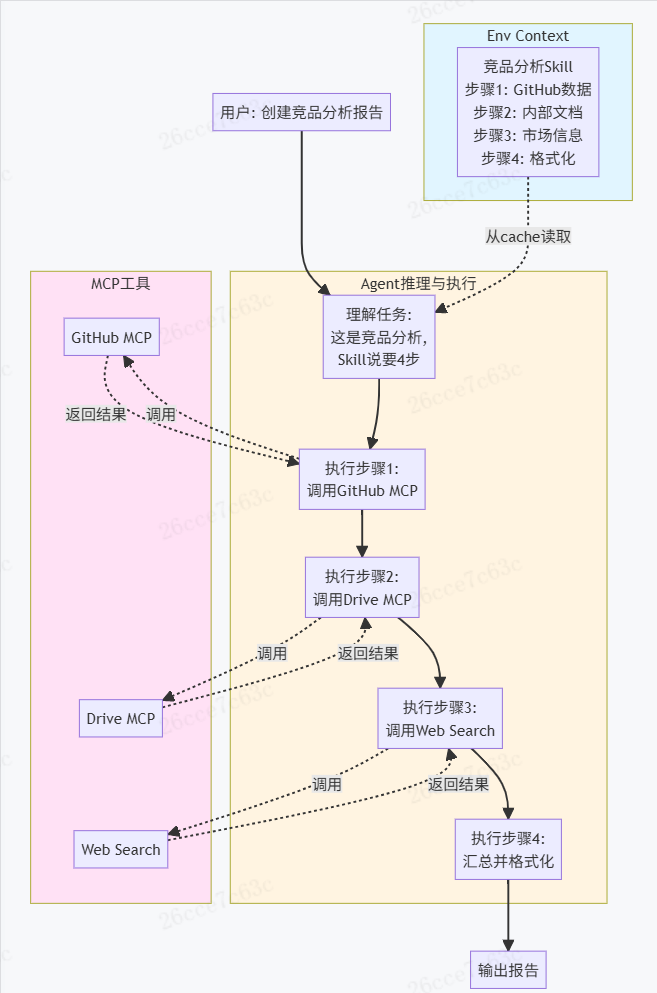
结语
深入理解Coding Agent的内部工作机制,能帮助开发者摆脱将其视为“黑箱”或“魔法”的认知,转而以更理性、协作的方式与之共事。从核心的身份定义、工具调用、环境感知,到生产环境必须考虑的缓存、压缩、冲突管控,再到通过Rule、MCP、Skill进行能力扩展,每一层设计都旨在让这位AI编码伙伴变得更可靠、更高效。
随着人工智能和Agent技术的持续演进,Coding Agent的能力边界必将进一步拓展。掌握其原理,不仅能让你更好地利用现有工具提效,也能为未来理解和应用更先进的AI编码技术打下坚实基础。希望这篇深度解析能为你与AI编码伙伴的协作开启新的篇章。欢迎在云栈社区与更多开发者交流你的实践与见解。
 发表于 2026-1-20 03:59:48
|
查看: 203|
回复: 0
发表于 2026-1-20 03:59:48
|
查看: 203|
回复: 0
