国内开发者若直接按照 NVIDIA Triton 推理服务器的官方指南进行编译,往往会因网络问题遭遇各种依赖下载失败的错误。其核心构建脚本 build.py 长达三千余行,初次接触难免令人望而却步。本文将详细拆解 build.py 的工作流程,并结合 CMake 与 Dockerfile 的构建逻辑,提供一套清晰的编译裁剪方案,帮助你像搭积木一样,灵活组装属于自己的 Triton Server 版本。
Triton Server 项目组成
早期的 Triton 是一个单一仓库,TensorRT 后端也默认包含在主仓中。如今,项目已演进为高度模块化的结构,TensorRT 后端被拆分出来,并支持众多其他推理后端,用户可以根据需求自定义后端组合。
当前 Triton 生态包含约 35 个仓库,主要分为以下几类:
核心组件 (5个)
- server: Triton 服务的外层框架,包含 HTTP/GRPC 请求处理、服务内存分配等功能。
- core: Triton 的主框架,负责请求调度、后端管理、模型生命周期管理等核心逻辑。
- common: 通用工具库,例如日志模块。
- backend: 后端框架代码,定义了后端通用接口和基类,自定义后端需继承此类。
- third_party: 项目所依赖的第三方库汇总,主要在 CMake 构建时引入。
后端集合 (16个)
- tensorrt_backend: TensorRT 推理后端。
- pytorch_backend: LibTorch (PyTorch C++) 推理后端。
- python_backend: Python 后端,包含 Python 存根并启动 Python 运行时环境。
- ... 以及其他如 ONNX Runtime、OpenVINO 等后端。
工具类 (6个)
- model_navigator: 简化将 PyTorch、TensorFlow、ONNX 模型转换为 TensorRT 格式的流程。
- pytriton: 简化在 Python 环境中使用 Triton 的流程。
- model_analyzer: CLI 工具,为部署在 Triton 上的模型寻找最优配置。
- perf_analyzer: CLI 工具,对 Triton 上的模型进行性能分析。
- triton_cli: 类似
trtexec 的 CLI 工具(目前为 Beta 版本)。
其他 (8个)
- local_cache / redis_cache: 本地与 Redis 缓存组件,用于加速推理过程。
- checksum_repository_agent: 在加载模型仓库前进行必要校验,提前暴露问题。
Triton Server 编译过程解析
Triton Server 的编译入口是 build.py。其核心过程是根据传入的参数,选择性地编译上述仓库,最终生成 Docker 镜像(或本地二进制文件)。构建流程的本质是对多个组件的协同编译。
build.py:编译的总调度器
build.py 的主要作用是将用户输入的参数(如所需后端、功能开关等)转换为具体的 CMake 指令,并组织构建环境。它会生成构建镜像和运行镜像,在构建镜像中执行编译,最后将产物复制到运行镜像中,形成最终的 tritonserver 镜像。
一个典型的构建命令如下:
python3 ../build.py \
-v \
--backend=identity \
--enable-logging \
--enable-stats \
--enable-metrics \
--enable-cpu-metrics \
--endpoint=http \
--endpoint=grpc \
--dryrun # 可选,开启后只生成脚本而不执行,需手动运行 docker_build
构建流程总览
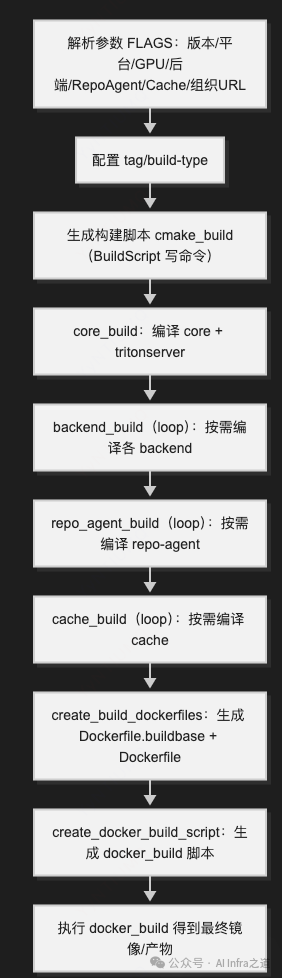
编译产物说明
如果采用容器化构建,通常会生成以下 5 个关键文件;若采用非容器化构建,则主要生成 cmake_build 脚本。
- docker_build: 容器构建的入口脚本,负责启动
Dockerfile.buildbase 镜像并在其中执行 cmake_build,最终汇总产物并生成运行镜像。在网络通畅的情况下,直接执行此脚本即可得到可运行的 Docker 镜像。
- cmake_build: 核心编译脚本,内含所有组件的 CMake 构建命令,将依赖下载和代码编译步骤整合在一起,运用了 CMake 的一些高级特性。
- Dockerfile.buildbase: 用于执行
cmake_build 的基础构建镜像。
- Dockerfile.cibase: 持续集成(CI)相关的基础镜像。
- Dockerfile: 最终的运行镜像定义文件,将编译好的产物打包进去。
cmake_build 是编译的主体,它会调用各个仓库的 CMakeLists.txt,下载依赖、应用配置选项,执行 make && make install,并将所有模块的编译产物汇总到统一目录(默认是 /tmp/tritonbuild/tritonserver/build)。其逻辑主要分为三部分:
- 编译核心库与可执行文件:包括
server、core、common、backend、third_party 仓库。
- 编译各推理后端:如 ONNX Runtime、PyTorch、TensorRT 等后端,每个后端对应独立的 CMake 指令。
- 收集 CI 制品。
若启用了 repoagent,脚本中还会包含相应的代理编译代码。在编译目标时,CMake 会首先尝试下载其依赖,若此时无法访问外部网络,则会导致失败。理解整个构建链条,特别是 CMake 如何管理依赖,是进行离线或定制化编译的关键。对于想深入理解大型项目构建过程的开发者,可以参考 云栈社区 上关于 CMake 和编译器原理 的讨论。
Dockerfile:将编译产物封装为镜像
此文件由 build.py 生成,其本身不负责编译 Triton,而是将上一步 cmake_build 产生的构建产物(位于 build/install 目录)复制到一个干净的运行时基础镜像(如 Ubuntu)中,补齐运行时依赖库,并设置好启动入口和版本信息。
像搭积木一样:裁剪与离线编译方案
分析完上述流程,我们可以得出结论:编译的核心在于 cmake_build。只要它成功运行,Triton Server 的构建就基本完成了。以下是针对常见问题的解决方案。
网络依赖问题
- 使用代理:为构建环境配置 HTTP/HTTPS 代理(如 Clash)是最直接有效的方法。
- 内网镜像仓库:将所需的 35 个仓库手动下载并上传到内网的 GitLab 或 Gitee。然后修改
build.py 中的仓库地址,或通过 --github-organization 参数指定你的内网仓库前缀,这样 CMake 就会从内网拉取代码。
- 手动补全子模块:如果部分第三方库(如 gRPC)的子模块下载失败,可以手动介入。进入 CMake 生成的临时构建目录,手动克隆缺失的仓库并初始化子模块。
# 示例:在构建容器内手动补全 gRPC 的 googletest 子模块
cd /tmp/tritonbuild/tritonserver/build/_deps/repo-third-party-build/grpc-repo/src/grpc
git submodule init
git submodule update
# 输出示例:Submodule path 'third_party/googletest': checked out 'c9ccac7cb7345901884aabf5d1a786cfa6e2f397'
后端组件化编译
在编译 ONNX Runtime、PyTorch 等通用后端时,Triton 会在这些后端的官方库之上增加一个适配层(Adapter)。官方构建方式可能会在 Docker 中再次拉取或编译这些后端库。
我们可以将这部分工作提前:
- 在宿主机上预先编译或下载好所需后端的头文件和库文件。
- 通过
build.py 的 --extra-backend-cmake-arg 参数,将路径直接传递给 CMake,使其跳过内部的下载和编译步骤。
例如,为 ONNX Runtime 后端指定预编译的依赖:
--extra-backend-cmake-arg="onnxruntime:TRITON_ONNXRUNTIME_INCLUDE_PATHS:PATH=/opt/onnxruntime/include;/opt/onnxruntime/include/onnxruntime/core/providers/openvino" \
--extra-backend-cmake-arg="onnxruntime:TRITON_ONNXRUNTIME_LIB_PATHS:PATH=/opt/onnxruntime/lib;/opt/intel/openvino_2025.4.0/runtime/lib/intel64" \
具体操作示例:
- 编译 ONNX Runtime Backend:从官方渠道下载与 Triton 版本匹配的 ONNX Runtime 预编译库,提取头文件和库文件。通过上述参数传递给构建系统,编译出
libtritonserver_onnxruntime.so。之后用 ldd 检查该动态库的依赖是否齐全,缺少的依赖从预编译库中补充即可。
- 编译 PyTorch Backend:方法类似,关键在于准备好对应版本的 LibTorch 头文件和库文件。
通过这种方式,我们实现了后端依赖的“组件化”。解决了网络和依赖问题后,你就可以像搭积木一样,只选择需要的后端和功能,定制出最精简的 Triton Server 镜像。这种高度定制化的构建方式,与 云原生 理念中按需组合、轻量部署的原则是相通的。
总结
build.py 是统一入口和调度器,它将用户配置转化为具体的 cmake_build 和 docker_build 脚本,真正的编译工作在 cmake_build 中完成。- 国内构建的核心挑战在于依赖获取:最佳实践是使用网络代理;次选方案是将所有仓库镜像到内网,并通过
--github-organization 切换源;在极端情况下,可进入 third_party 等目录手动补全子模块。
- 裁剪与定制的关键在于“后端组件化”:利用
--extra-backend-cmake-arg 参数提前提供后端依赖的头文件和库路径,可以绕过官方构建中对这些后端的二次拉取或编译,从而实现按需拼装最小可用的 Triton Server 镜像,显著提升构建效率和成功率。
 发表于 2026-1-20 11:16:42
|
查看: 235|
回复: 0
发表于 2026-1-20 11:16:42
|
查看: 235|
回复: 0
