理解 new 和 make 的区别是掌握 Go语言的内存模型 的关键一步。它们都用于内存分配,但用途和原理截然不同。本文将深入剖析两者的核心区别、底层内存分配机制,并通过大量实战代码演示其应用场景与性能影响。
一、核心区别概览
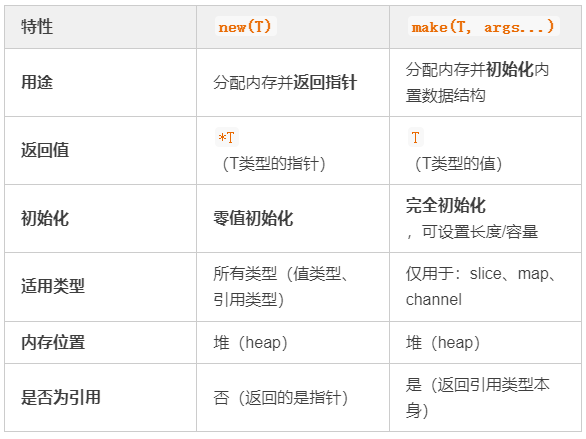
简单来说:
new(T):为类型 T 分配一块内存(填充零值),并返回指向这块内存的指针 *T。它适用于所有类型(值类型和引用类型)。make(T, args…):专门用于初始化 Go 的内置引用类型:slice、map 和 channel。它分配内存并完成数据结构初始化(例如设置 slice 的长度和容量),返回的是已初始化的 T 类型值本身,而非指针。
上方的对比表格清晰地总结了两者在用途、返回值、初始化方式、适用类型和内存位置上的核心差异。
二、new的深度解析
2.1 基本用法与内存分配
new 的主要作用是为变量分配零值内存并返回其指针。
package main
import (
"fmt"
"unsafe"
)
type User struct {
ID int
Name string
Age int
}
func main() {
// 1. new基础类型
pInt := new(int)
*pInt = 42
fmt.Printf("pInt: %p, value: %d, size: %d bytes\n",
pInt, *pInt, unsafe.Sizeof(*pInt))
// 2. new结构体
pUser := new(User)
pUser.ID = 1
pUser.Name = "Alice"
pUser.Age = 25
fmt.Printf("pUser: %p, value: %+v\n", pUser, *pUser)
// 3. 零值验证
pZero := new(int)
fmt.Printf("Zero value: %d\n", *pZero) // 输出: 0
}
new(int) 返回一个指向零值整数(0)的指针。对于结构体,其所有字段也会被初始化为各自的零值。
2.2 内存布局与逃逸分析
Go 编译器通过逃逸分析决定对象分配在栈上还是堆上。返回指针给函数外部引用会导致变量“逃逸”到堆。
package main
import (
"fmt"
"runtime"
"unsafe"
)
// 逃逸分析示例
func escapeToHeap() *[1000]int {
arr := new([1000]int) // 在堆上分配,因为返回指针
for i := range arr {
arr[i] = i
}
return arr
}
func stayInStack() [10]int {
var arr [10]int // 在栈上分配
for i := range arr {
arr[i] = i
}
return arr
}
使用 new 分配的内存,其生命周期由垃圾回收器(GC)管理。
2.3 new与指针运算(谨慎使用)
Go 通常禁止指针运算以确保内存安全,但通过 unsafe 包可以有限度地进行操作,这需要格外小心。
package main
import (
"fmt"
"unsafe"
)
func pointerArithmetic() {
// 分配一个int数组
arr := new([5]int)
// 获取数组首地址
basePtr := uintptr(unsafe.Pointer(&arr[0]))
// 通过指针运算访问元素(不推荐,仅演示)
for i := 0; i < 5; i++ {
// 计算每个元素的地址
elemPtr := (*int)(unsafe.Pointer(basePtr + uintptr(i)*unsafe.Sizeof(int(0))))
*elemPtr = i * 10
}
fmt.Println("Array:", *arr) // 输出: [0 10 20 30 40]
}
三、make的深度解析
3.1 Slice的内存分配与底层数组
make 为 slice 分配底层数组,并设置其长度(len)和容量(cap)。
package main
import (
"fmt"
"reflect"
"unsafe"
)
func sliceMemoryAllocation() {
// 1. make创建slice
s1 := make([]int, 5, 10) // len=5, cap=10
fmt.Printf("s1: len=%d, cap=%d\n", len(s1), cap(s1))
// 2. 查看slice头部结构
sliceHeader := (*reflect.SliceHeader)(unsafe.Pointer(&s1))
fmt.Printf("Slice header - Data: %p, Len: %d, Cap: %d\n",
unsafe.Pointer(sliceHeader.Data), sliceHeader.Len, sliceHeader.Cap)
}
理解 slice 的底层数组共享机制对于避免意外的数据修改至关重要。
func sliceUnderlyingArray() {
// 演示底层数组共享
original := make([]int, 5, 10)
for i := range original {
original[i] = i + 1
}
// 切片共享底层数组
slice1 := original[1:4] // [2,3,4]
slice2 := original[2:5] // [3,4,5]
// 修改会影响所有共享的切片
slice1[0] = 100
fmt.Println("Original:", original) // [1 100 3 4 5 0 0 0 0 0]
fmt.Println("Slice1:", slice1) // [100 3 4]
fmt.Println("Slice2:", slice2) // [3 4 5]
}
3.2 Map的内存分配与哈希表原理
使用 make 创建 map 时可以指定初始容量,这有助于减少后续扩容次数,提升性能。
package main
import (
"fmt"
"time"
)
func mapMemoryAllocation() {
// 1. 创建不同大小的map
smallMap := make(map[string]int, 10) // 预分配容量
largeMap := make(map[string]int, 10000) // 大容量map
// ... 填充数据并分析内存占用
// 3. 哈希冲突演示
conflictMap := make(map[int]string)
start := time.Now()
// 故意制造冲突(所有key都是100的倍数)
for i := 0; i < 100000; i++ {
conflictMap[i*100] = fmt.Sprintf("value%d", i)
}
elapsed := time.Since(start)
fmt.Printf("Time with potential conflicts: %v\n", elapsed)
}
Go 的 map 底层是哈希表,了解其扩容和冲突解决机制有助于编写高效代码。
3.3 Channel的内存分配与并发原理
make 用于创建 channel,可以指定缓冲区大小。无缓冲 channel 用于强同步通信,而有缓冲 channel 则能解耦生产消费速度。
package main
import (
"fmt"
"time"
)
func channelMemoryAndPerformance() {
// 1. 创建不同缓冲大小的channel
unbuffered := make(chan int) // 无缓冲
bufferedSmall := make(chan int, 10) // 小缓冲
bufferedLarge := make(chan int, 1000) // 大缓冲
// 性能测试函数
testChannel := func(ch chan int, name string) {
// ... 生产消费测试逻辑
fmt.Printf("%s: %d messages processed in %v\n", name, count, elapsed)
}
// 运行测试
testChannel(bufferedLarge, "Large Buffered")
testChannel(bufferedSmall, "Small Buffered")
testChannel(unbuffered, "Unbuffered")
}
Channel 是 Go 并发编程 的核心,其缓冲区的设置直接影响程序的并发行为和性能。
四、内存分配原理深入
4.1 Go内存分配器概览
Go 运行时拥有一个高效的内存分配器,它将堆内存划分为不同大小的块,以减少碎片并提升分配速度。new 和 make 最终都会通过这个分配器在堆上请求内存(如果发生逃逸)。
package main
import (
"fmt"
"runtime"
"time"
)
func memoryAllocatorDemo() {
// 展示不同大小内存分配的开销
sizes := []int{8, 16, 32, 64, 128, 256, 512, 1024, 2048}
for _, size := range sizes {
start := time.Now()
// 多次分配
for i := 0; i < 10000; i++ {
slice := make([]byte, size)
_ = slice
}
runtime.GC()
var mem runtime.MemStats
runtime.ReadMemStats(&mem)
elapsed := time.Since(start)
fmt.Printf("Size: %4d bytes | Time: %10v | HeapInuse: %6.2f KB\n",
size, elapsed, float64(mem.HeapInuse)/1024)
}
}
4.2 new和make的底层实现对比
从概念上理解,new 可以看作一个返回指针的零值分配器,而 make 则是由运行时针对特定类型提供的“智能构造函数”。
package main
import "fmt"
// 模拟new的实现原理
func simulatedNew[T any]() *T {
var zero T
return &zero // 注意:这里返回局部变量的地址,在实际Go代码中会逃逸到堆
}
// 模拟make slice的实现原理
func simulatedMakeSlice[T any](len, cap int) []T {
if len < 0 || cap < len {
panic("make slice: invalid arguments")
}
// 实际实现中,这里会调用runtime.makeslice在堆上分配底层数组
// 此处仅为概念演示
return make([]T, len, cap)
}
func compareAllocations() {
fmt.Println("=== 使用 new ===")
p1 := new(int)
fmt.Printf("new(int): type=%T, value=%v\n", p1, *p1)
p2 := new([]int) // 注意:这只是一个指向nil slice的指针
fmt.Printf("new([]int): type=%T, value=%v, is nil? %v\n", p2, *p2, *p2 == nil)
fmt.Println("\n=== 使用 make ===")
s1 := make([]int, 5, 10)
fmt.Printf("make([]int,5,10): len=%d, cap=%d\n", len(s1), cap(s1))
// make(int) // 编译错误: cannot make type int
}
逃逸分析决定了变量最终的位置,无论使用的是 new 还是字面量初始化。
func testEscapeAnalysis() {
fmt.Println("\n=== 逃逸分析 ===")
// 情况1:局部变量,不逃逸(可能分配在栈上)
localVar := 42
fmt.Printf("Local var address: %p (stack likely)\n", &localVar)
// 情况2:返回指针,逃逸到堆
escaped := func() *int {
v := new(int) // 因为返回值被外部引用,v逃逸到堆
*v = 100
return v
}()
fmt.Printf("Escaped var address: %p (heap)\n", escaped)
}
五、实战应用场景
5.1 何时使用new
- 需要显式的零值指针:用于区分字段的“零值”和“未设置”(如在ORM或协议中)。
type Record struct {
ID *int
Name *string
Active *bool
}
record := &Record{
ID: new(int), // 明确指向0
Name: new(string), // 明确指向""
Active: new(bool), // 明确指向false
}
- 避免大结构体复制:当函数需要修改或传递大型结构体时,传递指针比传递值更高效。
type LargeStruct struct { data [1000]int }
process := func(s *LargeStruct) { /* ... */ }
ls := new(LargeStruct) // 分配一个指向大结构体的指针
process(ls)
- 满足接口要求:某些接口方法定义在指针接收者上,此时需要该类型的指针。
var _ sync.Locker = &sync.Mutex{} // sync.Mutex的Lock()方法定义在指针接收者上
5.2 何时使用make
- 预分配Slice容量:已知元素数量时,预分配容量可以避免append操作中多次分配和复制,极大提升性能。
// ✅ 正确方式:预分配
const count = 1000000
goodSlice := make([]int, 0, count) // 一次性分配足够容量
for i := 0; i < count; i++ {
goodSlice = append(goodSlice, i) // 无扩容开销
}
- 初始化Map或Channel:这是
make最主要且必须的用途。未初始化的map(nil map)无法直接赋值,未初始化的channel(nil channel)会导致操作阻塞或panic。
// 必须用make初始化
config := make(map[string]interface{})
taskChan := make(chan string, 100) // 带缓冲的任务队列
- 实现Worker Pool模式:使用带缓冲的channel可以轻松构建并发工作池。
func workerPool(workerCount, jobCount int) {
jobs := make(chan int, jobCount)
results := make(chan int, jobCount)
// ... 启动worker goroutines并分发任务
}
5.3 性能优化实战
理解分配机制有助于性能调优。
package main
import (
"fmt"
"sync"
"time"
)
func memoryOptimization() {
// 1. Slice重用:减少GC压力
var reusable []byte
for i := 0; i < 1000; i++ {
reusable = reusable[:0] // 重置长度,复用底层数组
for j := 0; j < 100; j++ {
reusable = append(reusable, byte(j))
}
}
// 2. 使用sync.Pool缓存和重用大对象
var pool = sync.Pool{
New: func() interface{} {
return make([]byte, 1024) // 创建1KB的切片
},
}
for i := 0; i < 1000; i++ {
obj := pool.Get().([]byte)
// 使用obj...
pool.Put(obj) // 放回池中,供下次重用
}
}
六、常见陷阱与最佳实践
常见陷阱
- 对Slice/Map/Channel使用
new:new([]int) 返回的是一个指向 nil slice 的指针 *[]int,而非一个可用的 slice。你仍需对其解引用并用 make 初始化:*pSlice = make([]int, 5)。直接使用 new 创建这些类型通常不是你想要的做法。
- 尝试对非引用类型使用
make:make 仅用于 slice、map 和 chan。make(int) 会导致编译错误。
- 使用未初始化的Map:
var m map[string]int 声明了一个 nil map,向其赋值 m[“key”]=1 会引发 panic。必须先使用 make 初始化。
- 向nil Channel发送数据:
var ch chan int 是 nil channel。从它接收会永久阻塞,向它发送会直接 panic。
最佳实践
- 明确初始化:即使初始长度为0,也建议显式使用
make 初始化 slice 或 map,使代码意图更清晰。
- 预估容量:对 slice 和 map 使用
make 时,如果能够预估大小,应指定初始容量,减少动态扩容带来的性能损耗。
- 值类型 vs 指针类型:小结构体(小于几个指针大小)传值更高效;大结构体或需要修改原结构体时,使用指针(结合
new 或 &)。
- 及时释放大对象引用:对于不再使用的大 slice 或 map,将其设置为
nil,有助于垃圾回收器更快地回收内存。
总结
关键点回顾:
new(T):
- 返回
*T(指针)
- 零值初始化
- 适用于所有类型
- 在堆上分配内存
make(T, args…):
- 返回
T(值)
- 完全初始化(slice/map/channel)
- 仅适用于三种内置引用类型
- 在堆上分配内存
- 内存分配原则:
- 小对象优先栈分配
- 大对象或逃逸对象堆分配
- Go的GC会自动管理堆内存
- 性能优化建议:
- 预分配slice/map容量
- 重用大对象(sync.Pool)
- 避免不必要的堆分配
- 合理选择值类型/指针类型
掌握 new 和 make 的区别不仅是语法问题,更是理解Go内存模型和进行性能优化的关键。在实际开发中,根据具体场景选择合适的内存分配方式,可以显著提升程序性能与可读性。

 发表于 2026-1-20 13:04:43
|
查看: 158|
回复: 0
发表于 2026-1-20 13:04:43
|
查看: 158|
回复: 0
