XXL-Job 是国内任务调度领域的标杆项目,其设计兼顾了易用性与功能完整性。然而,在全面拥抱 Nacos 与 Spring Cloud Alibaba 的技术体系中,我们体会到了一丝架构上的摩擦:XXL-Job 拥有独立的注册中心与配置存储,这使其在 Nacos 体系内显得有些冗余。这并非设计缺陷,而是不同架构演进阶段的自然体现。
这促使我们思考:在云原生时代,中间件应该是一个独立的“平台”,还是可以内嵌为微服务架构中的一项“能力”?JobFlow 正是基于后一种理念的探索。
在 Nacos 体系下使用传统调度框架的挑战
当技术栈已选定 Nacos 作为服务发现与配置中心时,再引入一套独立的调度框架,会在架构层面产生一些不可避免的摩擦。
挑战一:两套注册中心导致服务状态割裂
典型的混合架构如下图所示:
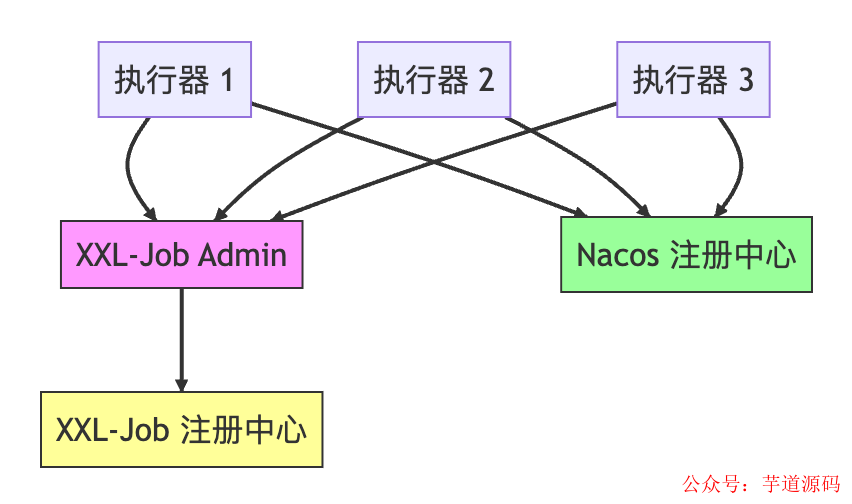
同一个执行器实例需要同时向两套注册中心(XXL-Job 和 Nacos)上报状态。这直接引发了一个核心问题:两个注册中心的服务状态可能不一致。
试想这样一个实际运维场景:你发现某个服务实例内存占用异常,怀疑存在内存泄漏,需要进行 JVM Heap Dump 分析。为了避免分析期间新流量进入,你登录 Nacos 控制台,手动将该实例下线。
- 你的操作:在 Nacos 点击“下线”。
- Nacos:实例状态已更新为“下线” ✓
- 你的预期:没有新请求打到该实例,可以安全执行 Dump。
- 现实情况:XXL-Job 的调度请求可能仍然到达该实例,因为它自身的注册中心仍视该实例为“在线”。
问题根源在于,你在 Nacos 上的运维操作,XXL-Job 的调度中心完全不知情。类似的问题还包括网络抖动导致实例在 Nacos 健康检查中失败,但在 XXL-Job 中仍被视为健康;实例重启后,在 Nacos 重新注册成功,但 XXL-Job 可能还认为它处于离线状态。两套系统各自为政,状态不同步,给日常运维带来了诸多不确定性。
挑战二:可观测性不足,问题排查链路断裂
在传统调度框架中,调度与执行是割裂的:调度器触发任务,执行器接收并执行。一旦任务执行失败或出现异常,排查问题就变得非常繁琐:
调度器触发任务 --> 执行器执行 --> 出现问题
| | |
调度中心日志 执行器日志 问题到底出在哪?
为了定位一次失败的任务执行,你通常需要:
- 登录调度器管理后台,查看调度日志和触发时间。
- 登录对应执行器服务的日志系统,筛选对应时间点的执行日志。
- 依靠时间戳进行人工比对,并祈祷两边的服务器时钟严格同步。
整个过程缺乏贯穿始终的 TraceId,无法形成完整的调用链路视图,排查问题效率低下,严重依赖运维人员的经验。
挑战三:分片机制缺乏强一致性约束
XXL-Job 提供了分片参数,但其分片是“建议式”的。执行器通过 XxlJobHelper.getShardIndex() 和 getShardTotal() 获取分片索引和总分片数,然后自行计算数据范围。
// 执行器端分片处理示例
int shardIndex = XxlJobHelper.getShardIndex(); // 例如:0
int shardTotal = XxlJobHelper.getShardTotal(); // 例如:10
// 然后自己根据模运算计算数据范围
List<Order> orders = orderDao.findByIdMod(shardIndex, shardTotal);
这里存在一个隐患:整个分片过程缺乏分布式锁的保护。在特定场景下(例如执行器实例重启、网络分区),可能出现多个实例同时处理同一份数据的情况,导致数据被重复处理。
核心设计理念:中间件即内嵌的业务能力
面对上述挑战,JobFlow 的设计理念从“重中间件”转向了“轻能力”。传统架构将调度平台视为一个需要独立部署、独立运维的外挂系统。而在云原生理念下,我们更倾向于将其视为一项内嵌的业务能力。
- 传统模式:
业务服务 -> 外挂的独立调度平台 (如 XXL-Job Admin)。
- JobFlow模式:
业务服务 + 作为微服务部署的调度器 (JobFlow Scheduler)。
这意味着调度能力不再是独立的“平台”,而是业务体系的一部分,与业务服务共享同一套技术设施:
- 同样的部署方式:容器化、Kubernetes。
- 同样的监控告警:Prometheus、Grafana。
- 同样的配置管理:Nacos Config。
- 同样的日志收集:ELK 或 Loki。
- 同样的团队维护:由业务研发团队自主掌控。
这种“中间件即业务”的理念带来了显著优势:架构认知统一、基础设施复用、服务状态一致(不会出现 Nacos 下线但调度仍在运行的割裂局面),并且业务团队对调度能力拥有完全的控制权,不依赖外部中间件团队。
具体实现:做减法与做加法
基于这一理念,JobFlow 的具体实现围绕“减法”和“加法”展开。
做减法,去除冗余:
- 摒弃自建的注册中心,统一使用 Nacos 的服务发现机制来获取执行器实例。
- MySQL 仅存储任务定义、执行记录和必要的审计日志,不再承担服务注册信息的存储职责。
做加法,补全能力:
- 内置全链路 TraceId:实现从调度触发到任务执行的全链路追踪。
- 实现真正的分片调度:结合分布式锁,确保分片任务的有状态性与一致性。
- 引入智能重试机制:支持指数退避策略与死信队列。
- 调度器配置云原生化:调度器自身的运行参数(如线程池大小、超时时间)通过 Nacos Config 管理,支持动态调整与多实例共享。
- 无缝复用现有设施:作为标准微服务,天然集成 Actuator、Prometheus 监控、统一告警和日志收集。
- 提供标准的 RESTful API:支持任务的手动触发、状态查询与失败重试。
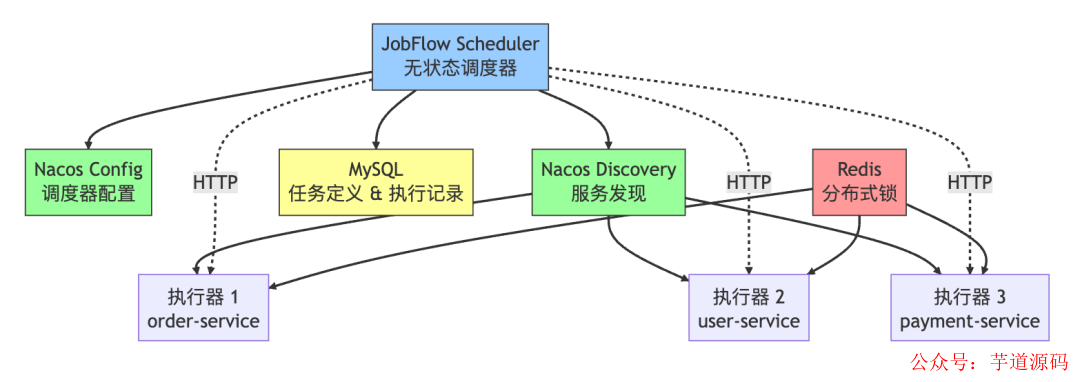
JobFlow 系统架构详解
整体架构
JobFlow 的整体架构非常简洁,核心依赖仅有三个:
- Nacos:作为统一的服务发现与配置中心。
- JobFlow Scheduler:一个轻量级的无状态调度器,可多实例部署。
- MySQL:存储任务定义与执行记录。
关键在于,JobFlow Scheduler 本身就是一个标准的 Spring Boot 微服务。它部署在业务集群中,自动复用已有的 Prometheus、Actuator、告警、日志等所有基础设施,实现了“零额外运维成本”。
任务调用流程
一次完整的任务调度与执行流程如下图所示:
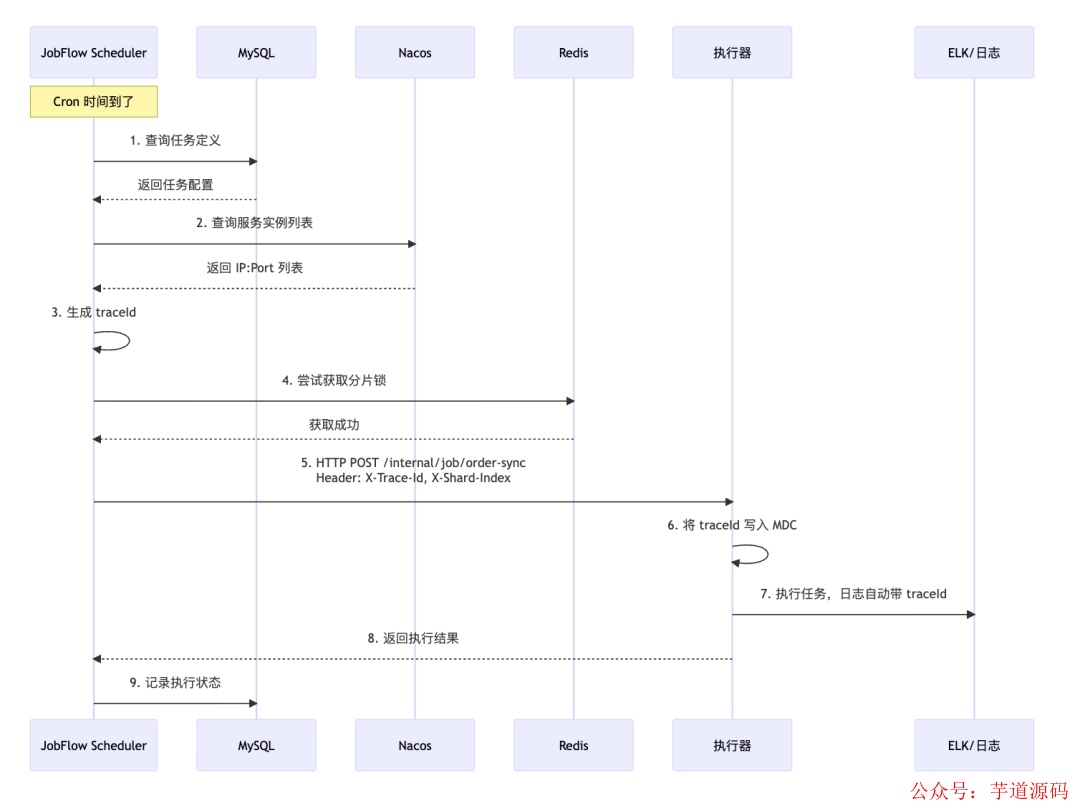
流程的核心在于 TraceId 的传递:
- 调度器在触发任务时生成全局唯一的 TraceId。
- 通过 HTTP Header(如
X-Trace-Id)将 TraceId 传递给执行器实例。
- 执行器将 TraceId 写入日志上下文(MDC)。
- 此后,执行器在处理任务过程中产生的所有日志都会自动携带该 TraceId。
- 在 ELK 等日志系统中,通过搜索这个 TraceId,即可一次性看到从调度触发到业务逻辑执行的完整链路日志,极大提升排查效率。
分片调度机制
JobFlow 的分片是“强约束式”的,调度器会明确计算出每个分片应处理的数据范围(例如 ID 0-333333),并通过分布式锁进行保护。
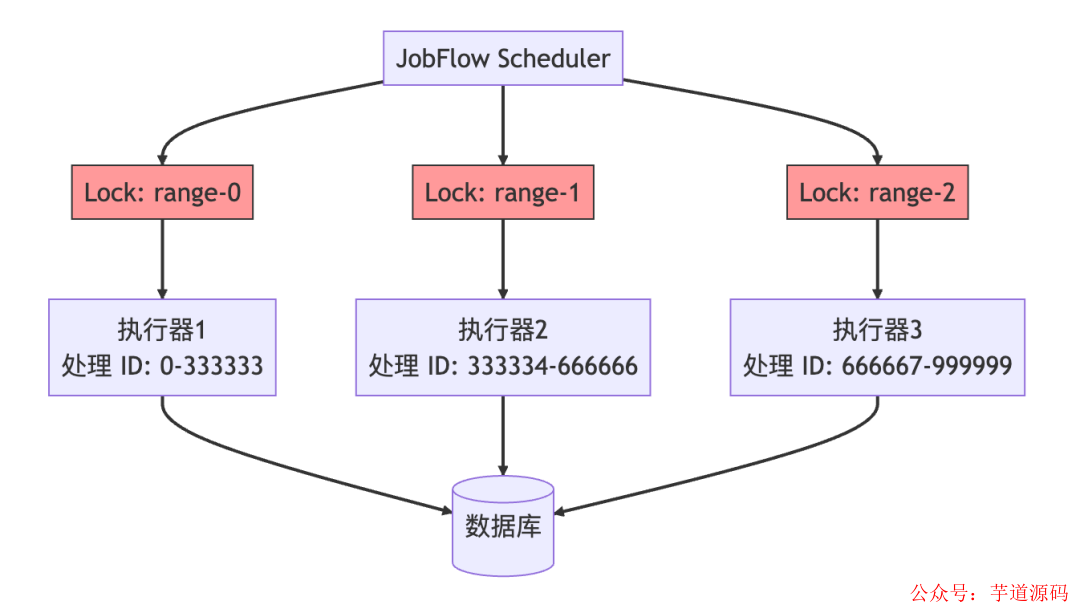
这种方式保证了:
- 数据范围明确:每个执行器实例知道自己该处理哪段确切的数据。
- 互斥性:同一数据范围在同一时刻只会被一个实例处理。
- 可恢复性:即使执行器实例中途宕机,锁释放后,该分片任务可由其他健康实例接管。
关键特性技术实现
特性一:全链路 TraceId
这是提升可观测性的核心。调度器生成 TraceId 并传递给执行器。
调度器端示例:
// JobFlow Scheduler
String traceId = UUID.randomUUID().toString();
HttpHeaders headers = new HttpHeaders();
headers.set("X-Trace-Id", traceId);
headers.set("X-Shard-Index", "0");
headers.set("X-Shard-Total", "10");
// 调用执行器接口
restTemplate.postForEntity(executorUrl, new HttpEntity<>(params, headers), JobResult.class);
执行器端示例:
// 执行器端
@PostMapping("/internal/job/{jobName}")
public JobResult execute(@RequestHeader("X-Trace-Id") String traceId, ...) {
// 将traceId写入日志上下文
MDC.put("traceId", traceId);
try {
log.info("开始执行任务"); // 此日志会自动附带 traceId
// ... 执行业务逻辑
return JobResult.success();
} finally {
MDC.clear();
}
}
特性二:真分片与分布式锁
调度器计算并分配明确的数据范围,执行器在处理前必须先获取对应的分布式锁。
调度器分配分片范围:
// 调度器计算分片范围
int totalRecords = 1000000;
int shardTotal = 10;
int rangeSize = totalRecords / shardTotal;
for (int i = 0; i < shardTotal; i++) {
long startId = i * rangeSize;
long endId = (i + 1) * rangeSize - 1;
// 生成与分片范围绑定的锁Key
String lockKey = String.format("lock:job:order-sync:range:%d-%d", startId, endId);
// 将 startId, endId, lockKey 通过Header传递给执行器
// ... 调用执行器
}
执行器处理带锁的分片任务:
@PostMapping("/internal/job/order-sync")
public JobResult sync(
@RequestHeader("X-Start-Id") Long startId,
@RequestHeader("X-End-Id") Long endId,
@RequestHeader("X-Lock-Key") String lockKey
) {
// 先尝试获取分布式锁(例如使用Redis)
boolean locked = redisLock.tryLock(lockKey, 60, TimeUnit.SECONDS);
if (!locked) {
log.warn("分片范围 {}-{} 已被其他实例锁定", startId, endId);
return JobResult.skip("已有其他实例处理");
}
try {
// 安全地处理 startId 到 endId 之间的数据
List<Order> orders = orderDao.findByIdBetween(startId, endId);
// ... 业务处理
return JobResult.success();
} finally {
redisLock.unlock(lockKey); // 释放锁
}
}
特性三:智能重试与指数退避
任务失败后,采用指数退避策略进行重试,避免雪崩。
# 调度器配置示例
retry:
max: 5
backoff: EXPONENTIAL
initialDelay: 1s
maxDelay: 5m
调度器逻辑:
public void scheduleRetry(JobExecution execution) {
int retryCount = execution.getRetryCount();
if (retryCount >= maxRetry) {
// 超过最大重试次数,进入死信队列等待人工处理
deadLetterQueue.send(execution);
return;
}
// 计算延迟时间:1s, 2s, 4s, 8s, 16s... 但不超过 maxDelay
long delay = Math.min(
initialDelay * (1 << retryCount),
maxDelay
);
// 延迟调度重试
scheduler.schedule(() -> {
retry(execution);
}, delay, TimeUnit.SECONDS);
}
特性四:调度器配置云原生化
JobFlow Scheduler 自身的运行配置完全交由 Nacos Config 管理,享受云原生配置管理的所有好处。
# 存放在 Nacos Config 中的配置:jobflow-scheduler.yaml
jobflow:
scheduler:
thread-pool-size: 20 # 调度线程池大小,支持动态调整
timeout: 300 # 默认任务超时时间(秒)
max-retry: 3 # 默认最大重试次数
executor:
connect-timeout: 5000 # HTTP连接超时
read-timeout: 30000 # HTTP读取超时
redis:
lock-timeout: 60 # 分片锁超时时间(秒)
优势:
- 动态生效:在业务高峰期,可直接在 Nacos 控制台将
thread-pool-size 从 20 调整为 50,无需重启服务。
- 多实例共享:一次配置变更,所有调度器实例同时生效。
- 版本管理与回滚:Nacos 提供完整的配置版本历史,可一键回滚。
特性五:精简的数据库设计
MySQL 中只存储最核心的数据,职责清晰。
-- 1. 任务定义表
CREATE TABLE job_definition (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
job_name VARCHAR(100) UNIQUE, -- 任务名称
service_name VARCHAR(100), -- 执行器服务名(用于从Nacos发现)
handler VARCHAR(100), -- 执行器内处理器路径
cron VARCHAR(100), -- Cron表达式
enabled BOOLEAN DEFAULT TRUE,
created_at TIMESTAMP,
updated_at TIMESTAMP
);
-- 2. 执行记录表
CREATE TABLE job_execution (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
job_name VARCHAR(100) NOT NULL,
trace_id VARCHAR(64) NOT NULL UNIQUE, -- 全链路追踪ID
trigger_time TIMESTAMP NOT NULL,
finish_time TIMESTAMP,
status VARCHAR(20) NOT NULL, -- PENDING/RUNNING/SUCCESS/FAILED/TIMEOUT
retry_count INT DEFAULT 0,
result_message TEXT,
INDEX idx_trace (trace_id),
INDEX idx_job_time (job_name, trigger_time)
);
设计要点:
- 不存服务实例信息:执行器地址通过 Nacos 服务发现实时获取。
- 不存详细日志:业务执行日志通过 TraceId 在 ELK 等日志平台关联查询。
- 不存调度器配置:调度器运行配置在 Nacos Config 中管理。
常见疑问与解答
问题一:Nacos 挂了怎么办?
如果作为注册中心和配置中心的 Nacos 完全不可用,整个微服务体系的通信和配置获取都会受到影响,此时任务调度的可用性并非最高优先级。但 JobFlow 可以做本地缓存降级:调度器缓存最近一次从 Nacos 获取到的健康实例列表,在 Nacos 短暂不可用时,使用缓存列表进行任务调度,保障核心调度功能在有限时间内的连续性。
问题二:数据库写失败导致状态不一致?
采用最终一致性模型。调度器在触发任务时,会先在数据库中插入一条状态为 PENDING 的执行记录。然后异步调用执行器。执行完成后(无论成功或失败),再异步更新数据库中的执行状态。同时,后台会运行一个补偿任务,定期扫描长时间处于 PENDING 状态的记录,通过其 TraceId 去日志系统中查询实际执行结果,并修正数据库状态。即使某次数据库更新失败,依然可以通过 TraceId 在日志中追溯真实情况。
问题三:没有UI管理界面怎么办?
初期可以提供一套完整的 RESTful API 来满足基本运维需求,包括手动触发任务、查询执行历史、根据 TraceId 查看详情、重试失败任务等。配合 Swagger 文档,可以快速上手。在系统稳定后,可以基于这些 API 开发一个轻量级的管理后台。这种“API先行,UI后补”的方式,让核心调度能力得以快速落地。
问题四:如何保证调度器自身的高可用?
JobFlow Scheduler 被设计为无状态服务,可以通过部署多个实例来实现高可用。为了避免多个调度器实例重复触发同一个 Cron 任务,可以采用分布式锁(每任务一把锁)或一致性哈希算法(每个调度器实例固定负责一部分任务)来确保同一时刻只有一个调度器实例触发特定任务。
总结
JobFlow 更多代表了一种架构设计思路的探讨,其核心是 “中间件即业务” 的理念。在云原生背景下,我们倾向于将调度这类能力从独立的“重型平台”解构为内嵌于 微服务体系 的“轻量模块”。
它并非旨在替代功能强大、生态完善的 XXL-Job,而是为那些已经深度使用 Nacos 和 Spring Cloud Alibaba 技术栈、对架构统一性和可观测性有更高要求的团队,提供一种更贴合自身技术体系的备选思路。
其主要优势体现在:
- 架构统一,运维简单:复用 Nacos 体系,无需维护两套注册/配置中心,调度器作为普通微服务部署,无缝复用现有监控、告警、日志设施。
- 可观测性强:内置全链路 TraceId,打通调度与执行日志,问题排查效率高。
- 数据一致性更好:分片调度与分布式锁结合,避免数据重复处理。
技术方案的选型永远取决于具体的业务场景和技术背景。XXL-Job 在通用性、开箱即用和社区生态上具有巨大优势。JobFlow 的思路则更适合技术栈定型、追求基础设施融合与自主掌控力的团队。这场讨论的价值,不在于孰优孰劣,而在于通过不同视角的碰撞,深化我们对分布式调度这一技术领域理解。
探索更多 Spring Boot 应用架构与 云原生 实践,欢迎访问 云栈社区 进行交流与学习。
 发表于 2026-1-20 14:55:44
|
查看: 161|
回复: 0
发表于 2026-1-20 14:55:44
|
查看: 161|
回复: 0
