
我们在Kubernetes平台上使用Vector收集日志已有多年,并将其成功部署于众多客户的生产环境,体验非常出色。因此,我希望能将这些实践经验分享给更广泛的社区,让更多K8s运维人员了解它的潜力,并考虑将其引入自己的技术栈。
本文将首先简要梳理在Kubernetes中可以收集哪些类型的日志信息,接着探讨Vector的核心架构及其优势,最后分享我们遇到过的真实生产案例与经验教训。
Kubernetes中的日志
首先,我们来看看Kubernetes环境下的日志来源。虽然K8s的核心任务是调度和运行容器,但必须明确,这些容器通常遵循类似Heroku的“十二要素应用”原则进行开发。那么,它们是如何在K8s中产生日志的?除了应用,还有哪些日志生产者?日志又存放在哪里?
1. 应用(Pods)日志
在K8s中运行的应用程序通常将其日志写入标准输出(stdout)或标准错误(stderr)。随后,容器运行时会收集这些日志并将其存储在一个特定目录中,通常是 /var/log/pods。这个路径是可配置的,可以根据实际需求进行调整。
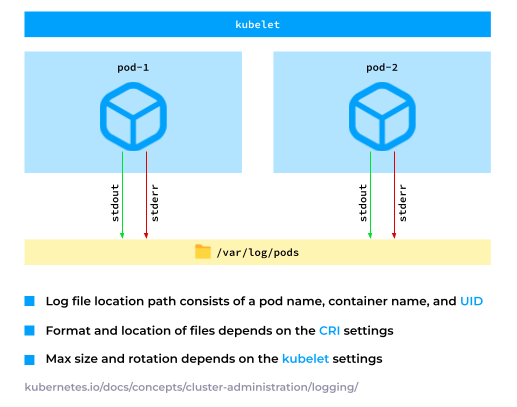
2. 节点服务日志
此外,Kubernetes节点上还存在一些在容器外运行的系统服务,例如 containerd 和 kubelet。
牢记这些服务并从系统日志(syslog)中收集相关消息至关重要,例如SSH认证日志。
另外,某些情况下容器也会将日志写入特定的文件路径。例如,kube-apiserver 通常会写入审计日志。因此,也需要从对应节点收集这些文件日志。
3. Events(事件)
Kubernetes事件是日志收集的另一个重要维度。它们具有独特的结构,因为事件仅存在于etcd中,所以收集它们必须向Kubernetes API发起请求。
由于事件的 reason 字段(参见下方示例)可以标识事件类型,而 count 字段则作为计数器随事件发生次数递增,因此事件可以被视为一种指标。
同时,事件也可以作为追踪信息收集,它们拥有 firstTimestamp 和 lastTimestamp 字段,便于创建展示集群中所有事件的综合性甘特图。
最后,事件提供了人类可读的 message 字段,这使其也能作为日志被收集。
apiVersion: v1
kind: Event
count: 1
metadata:
name: standard-worker-1.178264e1185b006f
namespace: default
reason: RegisteredNode
firstTimestamp: '2023-09-06T19:08:47Z'
lastTimestamp: '2023-09-06T19:08:47Z'
involvedObject:
apiVersion: v1
kind: Node
name: standard-worker-1
uid: 50fb55c5-d97e-4851-85c6-187465154db6
message: 'Registered Node standard-worker-1 in Controller'
本质上,Kubernetes中可以收集Pod日志、节点服务日志和事件。但本文将主要聚焦于Pod日志和节点服务日志,因为事件收集需要额外软件来抓取Kubernetes API,这超出了本次讨论的范围。
什么是Vector
现在,让我们深入了解Vector。
Vector的独特特性(以及我们为什么使用它)
根据官网定义,Vector是一个“用于构建可观测性管道的轻量级、超快速工具”。但作为Vector的深度用户,我想结合我们的实际用例,重新强调一下其核心特性:
Vector是一个开源、高效的日志收集管道构建工具。
这个定义对我们而言有何重要意义?
- 开源是必须的,这使我们能够在其基础上构建可靠、长久的解决方案,并放心地推荐给他人。
- 另一个关键因素是Vector的高效。如果一个工具轻量但无法处理海量数据,则无法满足需求;反之,如果一个工具超快但资源消耗巨大,也不适合作为日志收集器。因此,效率至关重要。
- 值得一提的是,Vector收集其他类型数据(如指标、追踪)的能力对我们当前场景并非重点,因为我们仅聚焦于日志。
Vector的一个卓越特性是其供应商中立性。尽管隶属于Datadog,但Vector可以无缝集成众多其他供应商的解决方案,包括Splunk、Grafana Cloud和Elasticsearch Cloud。这种灵活性确保了单一的软件解决方案能够跨越多云或多供应商环境使用。
Vector带来的另一个显著好处是,你无需为了性能而将Go应用重写为Rust——因为Vector本身就是用Rust编写的。
此外,它被设计为高性能。这是如何做到的?Vector拥有一个CI系统,会对每个提交的Pull Request运行基准测试。维护者会严格评估新功能对Vector性能的影响。如果出现性能回退,贡献者会被要求及时修复,因为性能始终是Vector团队的核心优先事项。
最后,Vector是一个高度灵活的构建模块,具体我们稍后会详细展开。
Vector的架构
作为一个数据处理工具,Vector从各种来源收集数据。它通过主动抓取或充当HTTP服务器来接收其他工具发送的数据。
Vector擅长转换日志条目,能够修改、丢弃或将多条消息聚合为一条。(不要被下方架构图中显示的转换器数量所迷惑——它实际提供的功能远不止这些。)
完成转换后,Vector处理消息并将它们发送到存储系统或消息队列。
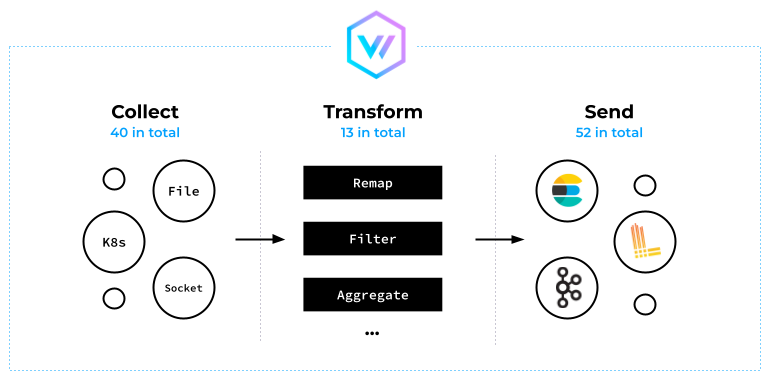
Vector架构概览:收集日志、转换日志、发送日志
Vector集成了一种强大的转换语言,称为Vector Remap Language,支持无限可能的转换操作。
Vector Remap Language示例
让我们快速了解一下VRL,先从日志过滤开始。在下面的代码片段中,我们使用VRL表达式来确保severity字段不等于"info":
[[transforms.filter_severity]]
type = "filter"
inputs = ["logs"]
condition = '.severity != "info"'
当Vector收集Pod日志时,它会使用额外的Pod元数据(如Pod名称、IP和标签)来丰富日志行。然而,Pod标签中可能包含一些仅供Kubernetes控制器使用的标签,对人类用户价值不大。为了获得最佳的存储性能,我们建议删除这些标签:
[[transforms.sanitize_kubernetes_labels]]
type = "remap"
inputs = ["logs"]
source = '''
if exists(.pod_labels."controller-revision-hash") {
del(.pod_labels."controller-revision-hash")
}
if exists(.pod_labels."pod-template-hash") {
del(.pod_labels."pod-template-hash")
}
'''
下面是如何将多行日志合并为单行的示例:
[[transforms.backslash_multiline]]
type = "reduce"
inputs = ["logs"]
group_by = ["file", "stream"]
merge_strategies."message" = "concat_newline"
ends_when = '''
matched, err = match(.message, r'[^\\]$');
if err != null {
false;
} else {
matched;
}
'''
在这种情况下,merge_strategies字段向message字段添加换行符。此外,ends_when部分使用VRL表达式检查一行是否以反斜杠结尾(类似于Bash中多行命令的连接方式)。
日志收集拓扑
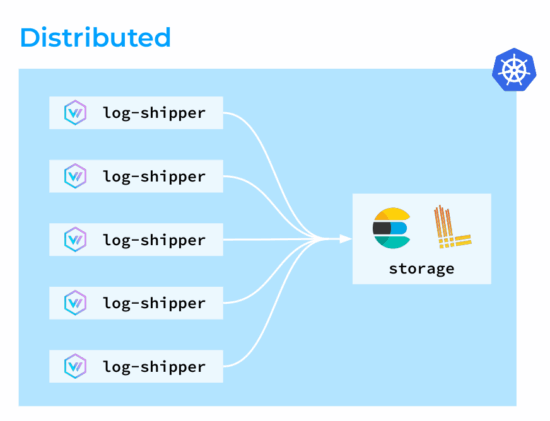
接下来,我们探讨几种与Vector配合使用的不同日志收集拓扑。第一种是分布式拓扑,其中Vector代理以DaemonSet形式部署在Kubernetes集群的所有节点上。这些代理收集、转换日志,并直接将其发送到存储后端。
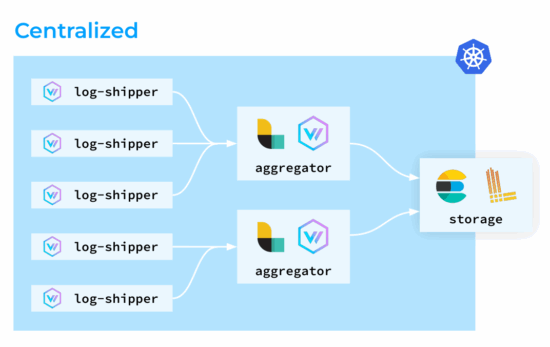
第二种是集中式拓扑。在这种拓扑中,Vector代理同样在所有节点上运行,但它们不执行复杂的转换;相反,由专门的聚合器来处理这些任务。这种设置的优势在于负载更可预测。你可以为聚合器部署专用节点,并根据需要轻松扩展,从而优化集群工作节点上Vector代理的资源消耗。
第三种拓扑是基于流的方法。在这种方法中,Kubernetes Pod的日志被尽快“转移”出节点。日志被直接摄取到存储中,如果是Elasticsearch,它会解析日志行并调整索引,这可能是一个资源密集型过程。但如果使用Kafka,消息则被简单地视为字符串处理。因此,我们可以轻松地从Kafka中取回日志,进行后续的存储和分析,这为构建高性能的云原生/IaaS可观测性平台提供了灵活的选择。
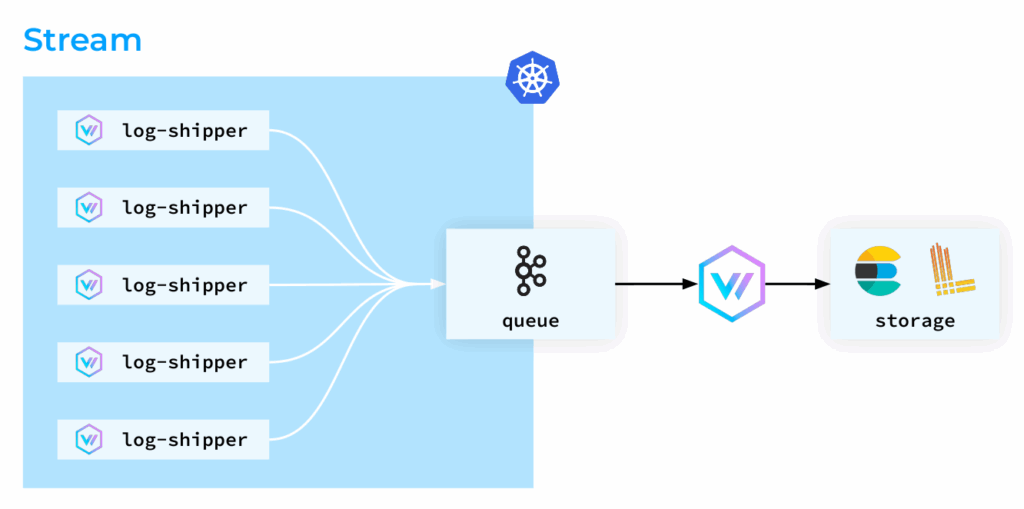
请注意,本文将不涵盖Vector作为聚合器的拓扑,而仅聚焦于其作为集群节点上日志收集代理的角色。
Kubernetes中的Vector部署
在Kubernetes中,Vector会以何种形态呈现?让我们看看下面的Pod设计:
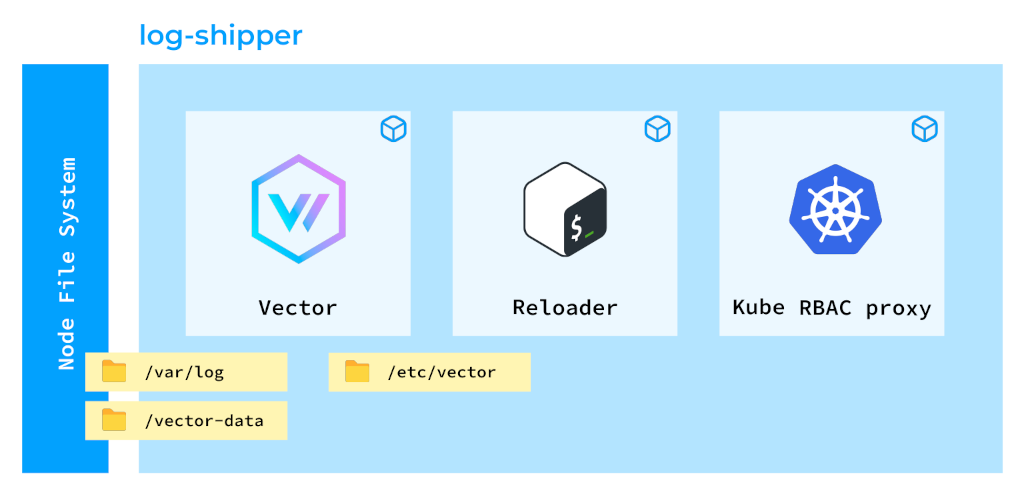
将Vector部署为DaemonSet后的Kubernetes容器
这样的设计初看可能有些复杂,但各有其因。这个Pod中包含三个容器:
- 第一个容器运行Vector本身,其主要职责就是收集日志。
- 第二个容器称为Reloader,它使得我们平台上的用户能够创建自己的日志收集和摄取管道。我们有一个特殊的Operator,用于接收用户定义的规则并为Vector生成配置映射。Reloader容器验证该配置映射,并相应地重新加载Vector。
- 第三个容器Kube RBAC proxy扮演着重要角色,因为Vector会暴露关于其所收集日志行的各种指标。由于这些信息可能很敏感,因此必须通过适当的授权进行保护。
Vector被部署为DaemonSet(参见下方清单),因为我们必须确保在Kubernetes集群的所有节点上都运行其代理。
为了有效收集日志,我们需要将额外的目录挂载到Vector容器中:
/var/log目录,因为如前所述,所有Pod的日志都存储在那里。- 此外,我们需要为Vector挂载一个持久卷,用于存储检查点。每次Vector发送一条日志行后,它都会写入一个检查点,以避免重复发送相同日志到存储。
- 另外,我们挂载
localtime以便日志时间戳与节点时区保持一致。
apiVersion: apps/v1
kind: DaemonSet
volumes:
- name: var-log
hostPath:
path: /var/log/
- name: vector-data-dir
hostPath:
path: /mnt/vector-data
- name: localtime
hostPath:
path: /etc/localtime
volumeMounts:
- name: var-log
mountPath: /var/log/
readOnly: true
terminationGracePeriodSeconds: 120
shareProcessNamespace: true
关于此清单,还有几点需要注意:
- 挂载
/var/log目录时,务必启用readOnly模式。这项预防措施可以防止对日志文件进行未经授权的修改。
- 我们设置了较长的终止宽限期(120秒),以确保Vector在重启前有足够时间完成所有正在进行的任务。
- 共享进程命名空间对于使Reloader能够向Vector发送重启信号至关重要。
以上便是我们在Kubernetes中部署Vector的基本设置。接下来,让我们进入最有趣的部分——实际生产用例。以下并非假设场景,而是我们在值班期间遇到的真实故障。
实际生产用例与故障排查
案例 #1:设备空间不足
某一天,所有Pod都因磁盘空间不足而被节点驱逐。经过调查,我们发现Vector竟然保留了已被删除的文件。那么,为什么会发生这种情况?
- Vector监控
/var/log/pods目录中的文件。
- 当应用程序积极写入日志时,文件大小可能超过预设的10MB限制,达到20、30、40、50MB甚至更多。
- 在某个时刻,kubelet会轮转日志文件,将其截断回10MB。
- 然而,就在同一时刻,Vector正尝试将大量积压的日志发送到Loki。不幸的是,Loki可能无法立即处理如此巨量的数据!
- Vector作为一个负责任的软件,仍然试图将所有日志发送到存储后端。
但应用程序不会等待这些内部操作完成——它们会继续运行并产生新日志。这导致Vector试图保留所有日志文件(包括已被轮转的旧文件),随着kubelet不断轮转,节点上的可用磁盘空间最终被耗尽。
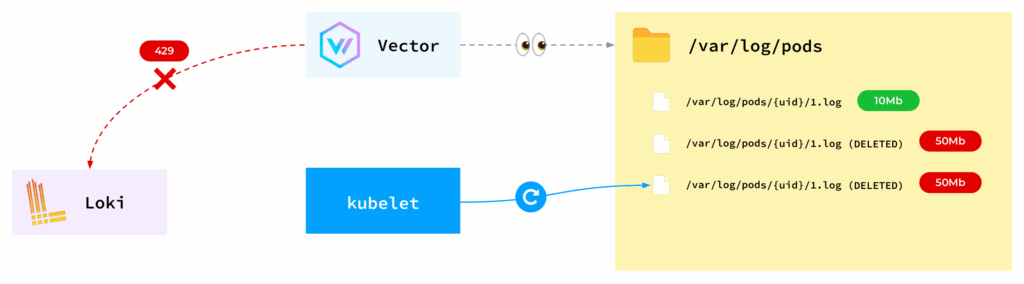
那么,如何解决这个问题呢?
- 首先,可以从调整缓冲区设置入手。默认情况下,如果Vector无法将日志发送到存储,它会将所有日志存储在内存中。默认缓冲区容量仅为1000条消息,这是相当低的。你可以将其扩展到10000。
- 或者,将行为从“阻塞”改为丢弃新日志也可能有帮助。使用
drop_newest行为,Vector会简单地丢弃其缓冲区无法容纳的任何新日志。
- 另一个选择是使用磁盘缓冲区而非内存缓冲区。缺点是Vector会在I/O操作上花费更多时间。在决定此方案前,你需要权衡其对运维/DevOps/SRE关注的系统性能的影响。
消除此问题的经验法则是考虑采用流拓扑。通过允许日志尽快离开节点,可以显著降低因监控问题导致生产应用程序中断的风险。毕竟,我们不希望因为日志收集的瓶颈而影响核心业务,对吧?
最后,如果你足够勇敢,可以使用sysctl调整进程的最大打开文件数限制。但是,我们并不推荐这种方法。
案例 #2:Prometheus “爆炸”
Vector在节点上运行并执行多项任务。它收集Pod日志,同时还暴露指标,例如收集的日志行数和遇到的错误数。这得益于Vector出色的可观测性特性。
然而,许多指标携带了特定的file标签,这可能导致高基数问题,而Prometheus难以消化。因为当Pod重启时,Vector开始为新Pod暴露指标,同时仍可能保留旧Pod的指标(file标签不同)。这种行为是其Prometheus Exporter工作方式(按设计)的结果。不幸的是,在多次Pod重启后,这种情况导致Prometheus负载激增,最终“爆炸”。
为了解决这个问题,我们应用了指标标签规则,移除了有问题的file标签。这暂时解决了Prometheus的问题——它恢复了正常运行。
然而,一段时间后,Vector自身遇到了问题。事实是,Vector消耗了越来越多的内存来存储所有这些带高基数标签的指标,导致了内存泄漏。为了纠正这一点,我们启用了Vector的全局选项expire_metric_secs:
- 如果你将其设置为60秒,Vector将检查是否仍在从这些文件收集数据。
- 如果没有,它将停止为这些文件导出指标。
虽然这个解决方案很有效,但它也影响了其他一些指标,例如Vector组件错误总数。如下图所示,最初记录了数个错误,但在触发指标过期后,数据序列出现了缺口。
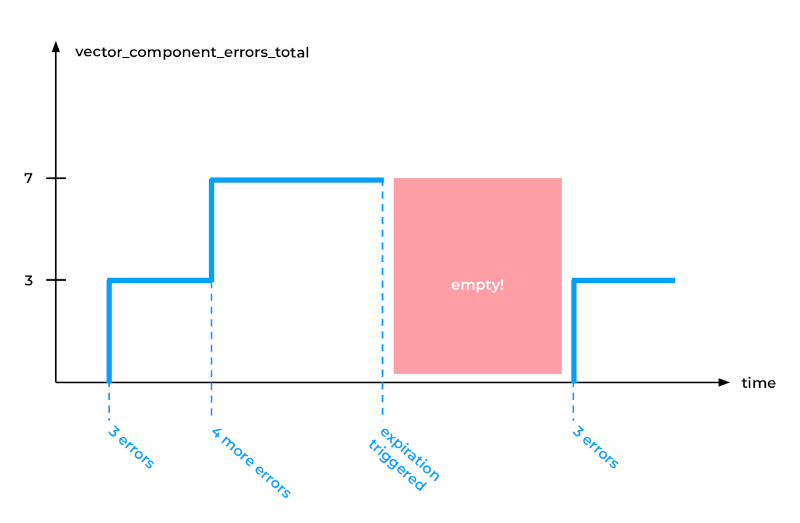
不幸的是,Prometheus,特别是PromQL中的rate函数(及类似函数),难以处理数据序列中的这种缺口。Prometheus期望指标在整个查询时间范围内持续存在。
为了解决这个限制,我们最终修改了Vector的源代码,直接从相关指标中完全移除了file标签——只需在几个关键位置删除对"file"的引用即可。这个变通方法成功地一劳永逸地解决了问题。
案例 #3:Kubernetes控制平面故障
某一天,我们注意到当多个Vector实例同时重启时,Kubernetes控制平面容易发生故障。通过分析监控仪表板,我们将问题根源锁定在过高的内存使用率,主要是etcd的内存消耗激增。
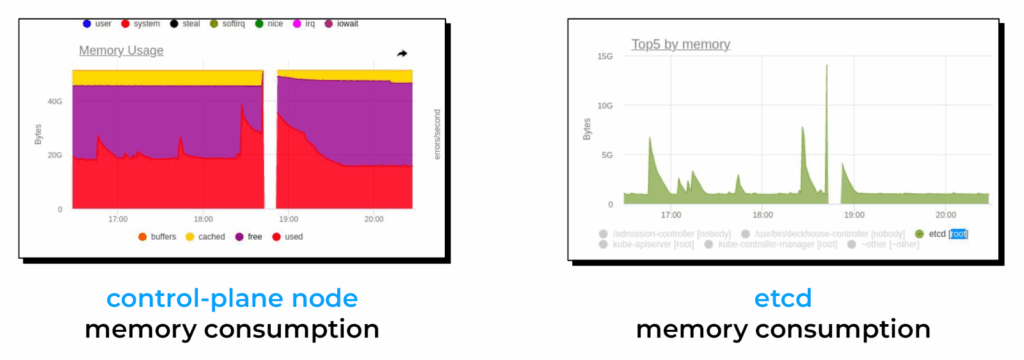
为了更好地理解根本原因,我们需要先深入探究Kubernetes API的内部工作机制。
当Vector实例启动时,它会向Kubernetes API发起LIST请求,以获取Pod元数据并填充其本地缓存。如前所述,Vector依赖这些元数据来丰富日志条目。
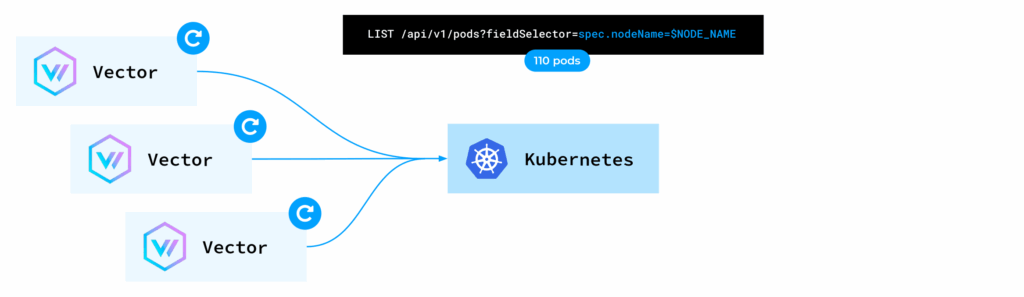
因此,每个Vector实例都会请求Kubernetes API提供其所在节点上所有Pod的元数据。但是,对于每一个这样的请求,Kubernetes API默认都会直接从etcd读取数据。
etcd是一个键值数据库。键由资源的kind、namespace和name组成。对于涉及节点上110个Pod的每个请求,Kubernetes API都会访问etcd并检索所有Pod的完整数据。这导致了kube-apiserver和etcd的内存使用量急剧上升,最终可能致使它们崩溃。
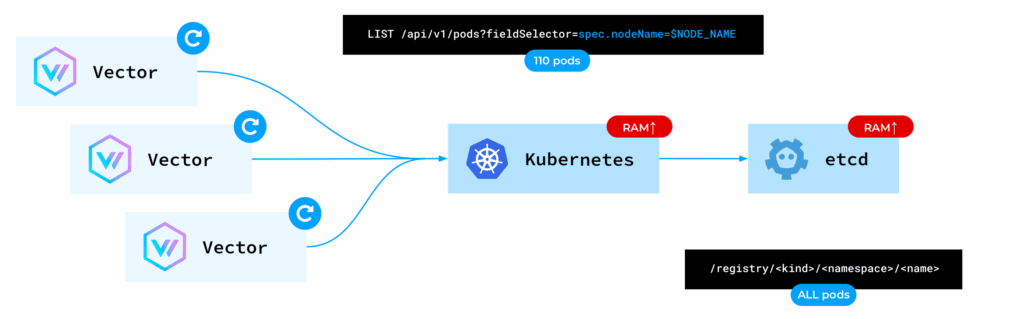
这个问题有两种潜在的解决方案。首先,我们可以采用缓存读取方式。在这种方式下,我们指示API Server从其现有的缓存中读取数据,而不是每次都访问etcd。虽然在某些极端情况下可能导致读取到稍微过时的数据,但对于日志收集和运维 & 测试这类监控工具来说,通常是可接受的。遗憾的是,当时Kubernetes的Rust客户端库并未提供此功能。因此,我们向Vector项目提交了一个Pull Request,增加了use_apiserver_cache=true选项。
第二个解决方案涉及利用Kubernetes优先级与公平性API的特性。你可以定义一个请求队列:
apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: PriorityLevelConfiguration
metadata:
name: limit-list-custom
spec:
type: Limited
limited:
assuredConcurrencyShares: 5
limitResponse:
queuing:
handSize: 4
queueLengthLimit: 50
queues: 16
type: Queue
并将其与Vector使用的特定服务账户关联:
apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: FlowSchema
metadata:
name: limit-list-custom
spec:
priorityLevelConfiguration:
name: limit-list-custom
distinguisherMethod:
type: ByUser
rules:
- resourceRules:
- apiGroups: [""]
clusterScope: true
namespaces: ["*"]
resources: ["pods"]
verbs: ["list", "get"]
subjects:
- kind: ServiceAccount
serviceAccount:
name: ***
namespace: ***
这样的配置允许你限制并发LIST请求的数量,有效“削峰填谷”,从而最小化其对控制平面的冲击。
最后,你还可以考虑使用kubelet API(通过请求/pods端点)来获取Pod元数据,而不是依赖Kubernetes API。但这需要修改Vector的代码来实现,目前并非开箱即用的功能。
结论
Vector以其灵活性、多功能性以及对广泛日志摄取和传输选项的支持,非常适合平台工程的需求。我个人极力推荐Vector,并鼓励你充分挖掘其潜力。
希望这篇融合了架构解析与实战排障的经验分享,能为你规划或优化自己的K8s日志收集方案带来启发。如果你在实践中遇到其他独特挑战,欢迎到云栈社区交流讨论。
 发表于 2026-1-20 16:45:04
|
查看: 267|
回复: 0
发表于 2026-1-20 16:45:04
|
查看: 267|
回复: 0
