目录
一、背景介绍
二、数据比对关键挑战与目标
1.关键挑战一:如何更快地完成全文数据比对
2.关键挑战二:如何精准定位异常数据
3.比数核心目标
三、解决方案实现原理
1.快速完成全文数据比对方法
2.精准定位异常数据实现方法
四、比数平台功能介绍
1.数据比对基本流程
2.任务生成:三种比对模式
3.前置校验:提前发现问题
4.破解比数瓶颈:资源分配与任务调度优化
五、比数平台收益分享
六、未来演进方向
七、结语
一、背景介绍
得物经过10年发展,计算任务已超10万+,数据总量超过200+PB。为了优化成本结构,公司启动了计算引擎和存储资源从云平台到自建平台的迁移工作。具体来说,计算引擎从云平台Spark迁移到自建Apache Spark集群,存储则从ODPS迁移至OSS。
在这次大规模迁移过程中,最核心的诉求是什么?答案是确保迁移前后数据的绝对一致性。面对超10万计算任务,如果依靠人工逐一比对数据,无异于天方夜谭。因此,一个自动化、高效的大数据比对平台——Galaxy(比数平台)应运而生,旨在解决这一核心痛点。
二、数据比对关键挑战与目标
在平台建设之初,我们面临两大核心挑战。
1.关键挑战一:如何更快地完成全文数据比对
现状痛点:
在平台上线前,迁移同学需要手动编写SQL(例如JOIN两张表)来识别不一致的数据,然后逐条记录、逐个字段进行肉眼比对。这种方式在任务量少时勉强可行,但当任务规模达到成千上万级别时,完全无法实现并发和快速分析。
核心问题:
- 效率瓶颈:每天需要完成数千任务的比对,累计待迁移任务超过10万+,涉及的表数量更是高达数十万张。
- 扩展性不足:传统的人工比对方式从根本上无法满足大规模、高并发的数据处理需求。探索如何构建一个高效的 大数据 比对引擎,成为首要课题。
2.关键挑战二:如何精准定位异常数据
现状痛点:
即使在识别出存在不一致数据后,分析人员也需要通过肉眼观察来定位具体问题,这极易导致视觉疲劳和分析效率急剧下降。
核心问题:
- 分析困难:一旦比对不通过,人员需要投入大量时间人工分析失败原因。
- 复杂度高:面对数据量大、加工逻辑复杂的场景,尤其是包含大JSON对象时,肉眼几乎无法有效分辨差异。
- 耗时严重:根据统计,在比对不通过的情况下,单次任务的平均人工分析时间高达1.67小时。
3.比数核心目标
基于以上挑战,Galaxy比数平台确立了以下核心目标:
- 高并发处理能力:支持每天数千任务的快速比对,能够从容应对10万+待迁移任务和数十万张表的庞大规模。
- 自动化比对机制:实现从任务提交到结果分析的全自动化流程,最大限度减少人工干预,提升整体效率。
- 智能差异定位:提供精准的差异定位能力,能自动识别并高亮显示不一致的字段和具体数值。
- 可视化分析界面:构建用户友好的可视化平台,支持对复杂数据结构(如大JSON)的格式化展示和差异比对。
- 性能优化:将用户从识别差异到定位根因的单次分析耗时,从小时级大幅缩短至分钟级别。
- 可扩展架构:设计灵活、可水平扩展的 系统架构 ,能够伴随业务增长而平滑扩容。
三、解决方案实现原理
为了达成上述目标,我们深入研究了数据比对的底层逻辑,并设计了一套组合方案。
1.快速完成全文数据比对方法
比数方法调研
我们首先对多种数据比对方法进行了性能调研。设定场景为:待比对的两张表数据大小均为300GB,可用计算资源为1000 CPU核心。


经过综合评估,Galaxy平台最终采用了上述第二种(Union后分组)和第三种(哈希值聚合)相结合的策略进行数据比对。
先Union再分组数据一致性校验原理
假设我们需要比对表a和表b。
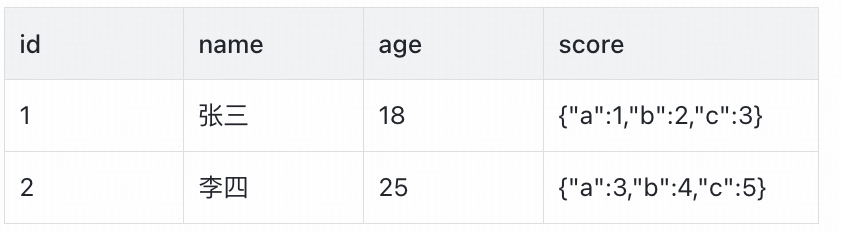
表a数据示例如下:
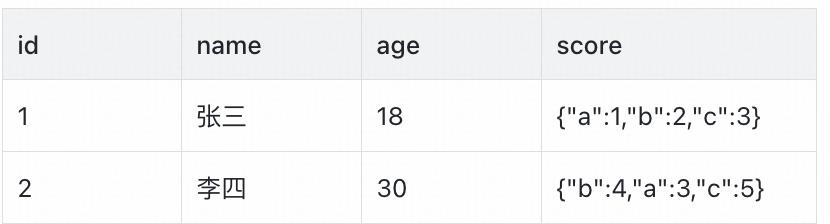
表b数据示例如下(注意age和score字段顺序与表a存在差异):
表行数比较:
这是比对的第一个检查点。如果表数据量不一致,则无需进行更耗时的字段比对。
select count(1) from a ;
select count(1) from b ;
如果查询结果数量不一致,则直接终止比对流程,提示修复后重试。如果数量一致,则继续进行字段值的比对。
字段值比较:
第一步:将表a和表b进行UNION ALL操作。
select 1 as _t1_count, 0 as _t2_count, `id`, `name`, `age`, `score`
from a
union all
select 0 as _t1_count, 1 as _t2_count, `id`, `name`, `age`, `score`
from b
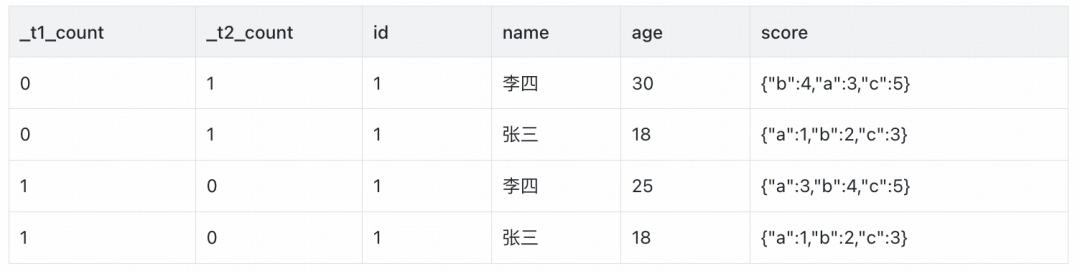
合并后的中间结果如下,_t1_count和_t2_count用于标记记录来源:
第二步:按所有字段分组,并分别汇总_t1_count和_t2_count。
select sum(_t1_count) as sum_t1_count, sum(_t2_count) as sum_t2_count, `id`, `name`, `age`, `score`
from (
select 1 as _t1_count, 0 as _t2_count, `id`, `name`, `age`, `score`
from a
union all
select 0 as _t1_count, 1 as _t2_count, `id`, `name`, `age`, `score`
from b
) as union_table
group by `id`, `name`, `age`, `score`
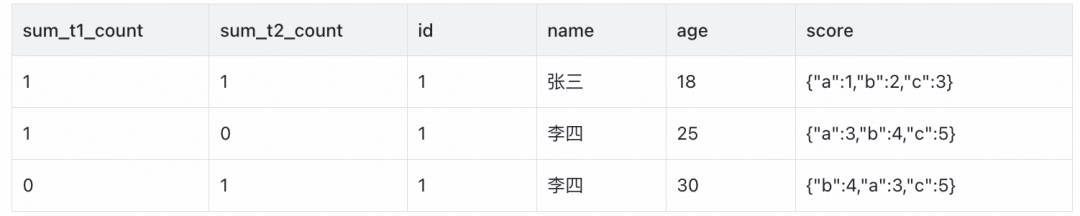
分组聚合后,如果一行数据在两张表中都存在且完全一致,那么sum_t1_count和sum_t2_count应都等于1。
第三步:筛选出不一致的数据(sum_t1_count不等于sum_t2_count)并写入结果表。
drop table if exists a_b_diff_20240908;
create table a_b_diff_20240908 as select * from (
select sum(_t1_count) as sum_t1_count, sum(_t2_count) as sum_t2_count, `id`, `name`, `age`, `score`
from (
select 1 as _t1_count, 0 as _t2_count, `id`, `name`, `age`, `score`
from a
union all
select 0 as _t1_count, 1 as _t2_count, `id`, `name`, `age`, `score`
from b
) as union_table
group by `id`, `name`, `age`, `score`
having sum(_t1_count) <> sum(_t2_count)
) as tmp
如果a_b_diff_20240908表为空,则说明两张表完全一致,比对通过。如果存在差异,结果可能如下所示:

第四步:读取不一致记录表,基于主键(如id)定位具体是哪些字段不一致,并将结果写入详情表。
第五步:针对不一致的字段数据进行根因分析,例如判断是否为JSON格式差异、数组顺序问题或浮点数精度问题等,并给出具体的不一致原因。
哈希值聚合实现高效一致性校验
尽管“UNION后分组”的方法可以精确找出差异,但在数据量极大时,其资源消耗和时间成本依然很高。考虑到实际生产环境中,大部分(约70%)比对任务的数据是一致的,我们引入了一种更高效的预筛选机制:哈希值聚合比较。
SELECT count(*),SUM(xxhash64(cloum1)^xxhash64(cloum2)^...) FROM tableA
EXCEPT
SELECT count(*),SUM(xxhash64(cloum1)^xxhash64(cloum2)^...) FROM tableB
这条SQL的核心思想是,将表内所有字段的哈希值进行异或(XOR)累加,得到一个代表整行数据的“指纹”,再对所有行的“指纹”求和,并与另一张表的结果对比。如果查询结果为空,则说明两张表数据在哈希层面一致,可快速判定为一致,无需进行更详细的逐行比对。否则,再启用上述“UNION分组”方法进行精确定位。
效果:通过哈希值聚合预筛,单个任务的比对时间从约500秒降低到160秒左右,效率提升约70%。
2.精准定位异常数据实现方法
找到不一致的数据后,下一步是精准定位差异点。这通常需要基于表的主键进行逐字段比对。因此,系统首先要能自动探查主键,并对无主键场景进行兜底处理。
自动探查主键:实现原理如下
最初的方案是简单地尝试前N个字段的组合,但成功率较低(仅50.4%)。为此,我们进行了多轮优化,形成了当前的主键探查流程。
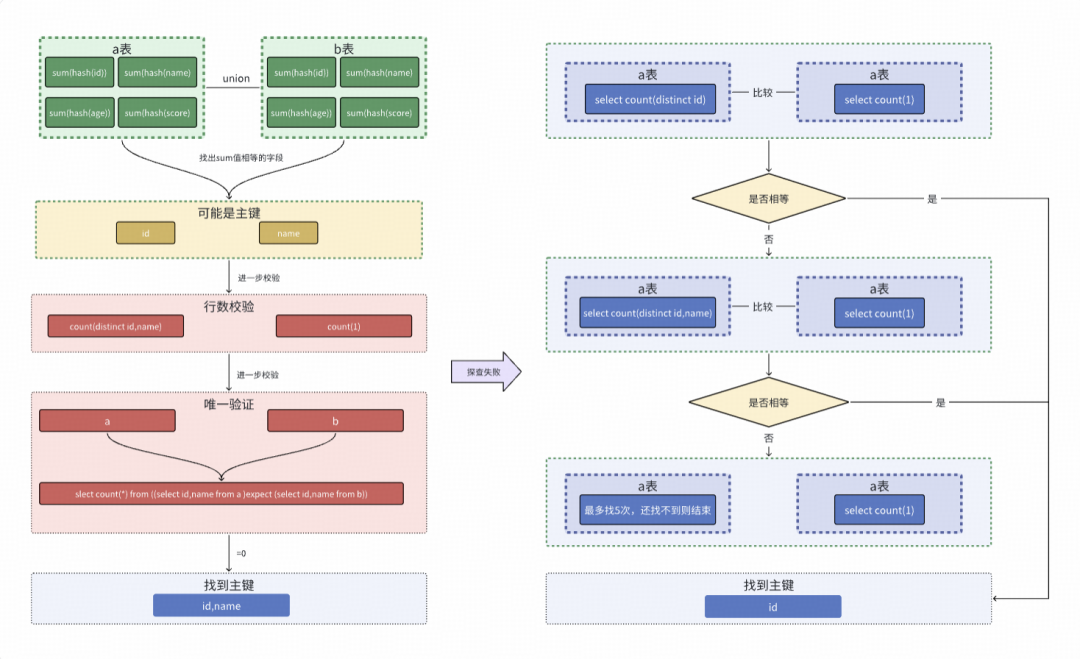
一、采用SUM(HASH())高效探查方式
- 计算两张表每个字段的哈希和。
select sum(hash(id)),sum(hash(name)),sum(hash(age)),sum(hash(score)) from a
union all
select sum(hash(id)),sum(hash(name)),sum(hash(age)),sum(hash(score)) from b;
- 找出哈希和相等的字段组合(本例中为
id, name),它们可能是主键。
- 进行行数校验:如果
select count(distinct id,name) from a 等于 select count(1) from a,则进入下一步唯一性验证,否则转入第二种探查方式。
- 唯一性验证:如果以下查询结果为0,则探查成功。
select count(*) from ((select id,name from a ) except (select id,name from b))
二、传统的DISTINCT计数方式探查
如果高效方式失败,则回退到此方法,尝试字段的前N种组合(如前5个字段、后5个字段等)。
- 比较
select count(distinct id) from a 与 select count(1) from a,若相等,则主键为id。
- 若不相等,则尝试
select count(distinct id,name) from a 与 select count(1) from a 比较,以此类推。
三、全字段排序模拟分析
如果以上两种方式均未找到主键,系统会将不一致记录表按所有字段排序,取前两条记录进行逐字段对比分析。
select * from a_b_diff_20240908 order by id,name,age,score asc limit 10;

通过上图结果可以直观看出,两张表中id=1, name=李四的记录,age字段(25 vs 30)和score字段(虽然键值对顺序不同,但按Key排序后内容一致)存在差异。
如果自动化分析仍然无法确定差异,用户可以在平台上手动指定主键字段,系统将依据用户指定的主键进行后续的差异字段定位分析。
通过优化,主键自动探查的成功率从最初的50.4%提升到了75%,结合“全字段排序”的兜底分析策略,综合成功率可达90%以上。
根因分析:实现原理如下
当定位到具体的不一致字段后,平台会启动根因分析引擎,对差异原因进行智能推断。
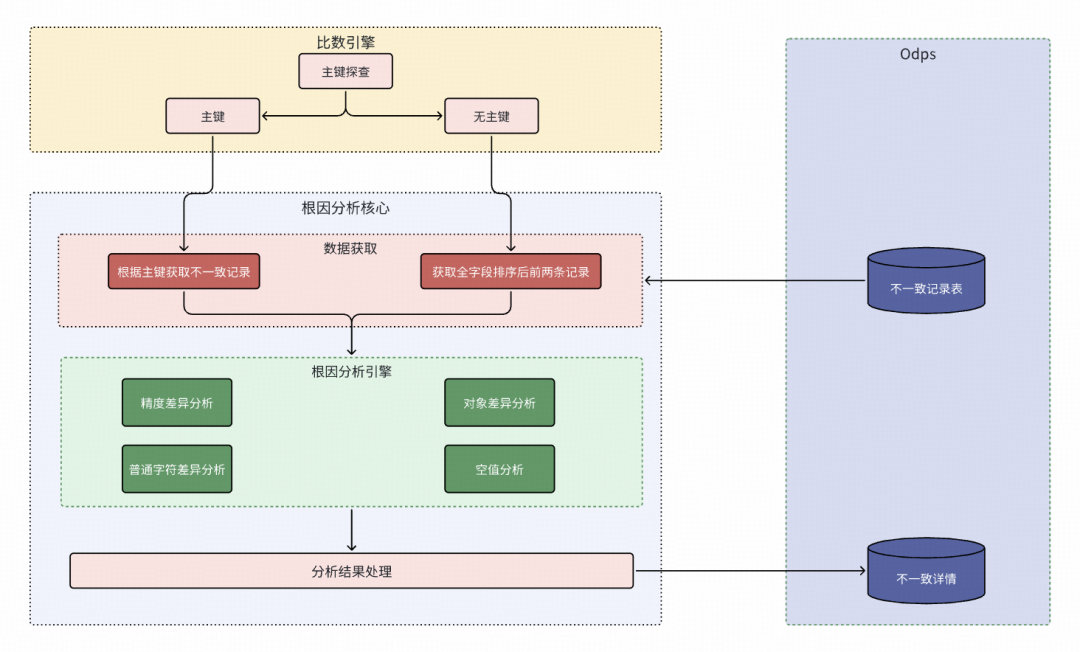
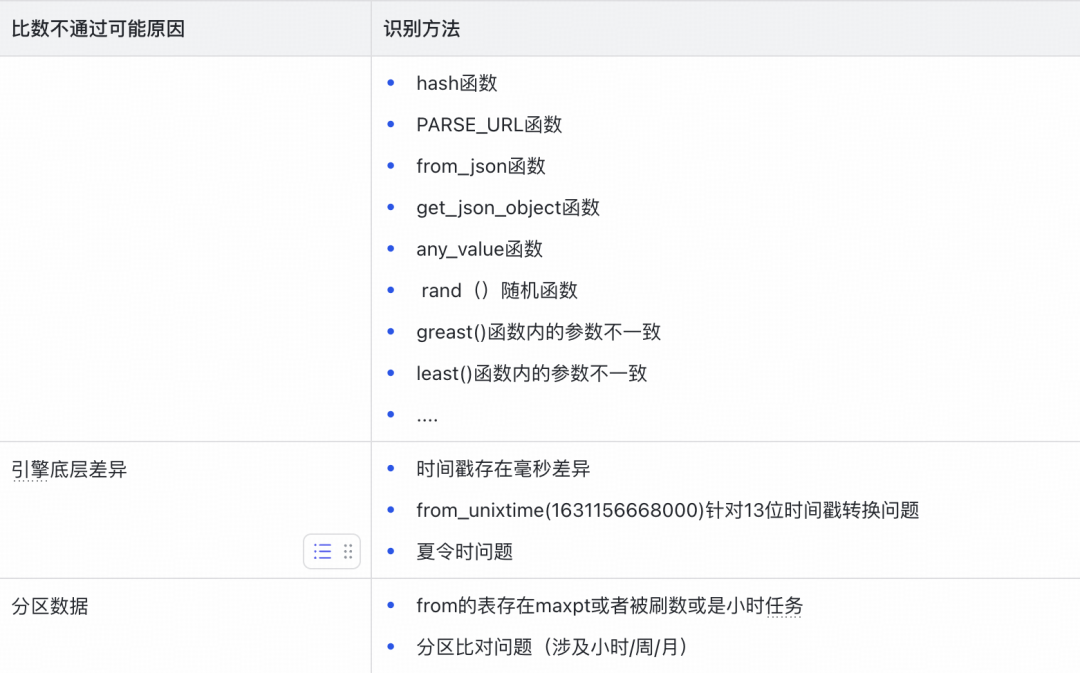
平台内置了多种差异模式识别规则,能够自动分析并提示不一致的可能原因,例如:
- 精度问题:如浮点数计算中
1.0000000001 与 1.0 的微小差异。
- 顺序问题:如数组
[1,2,3] 与 [3,1,2],或JSON对象 {"a":1, "b":2} 与 {"b":2, "a":1} 因顺序不同导致的差异。
- 引擎底层差异:不同计算引擎对同一函数或时间戳的处理方式可能不同。
- 空值处理差异:
NULL值与空字符串""的判定差异。

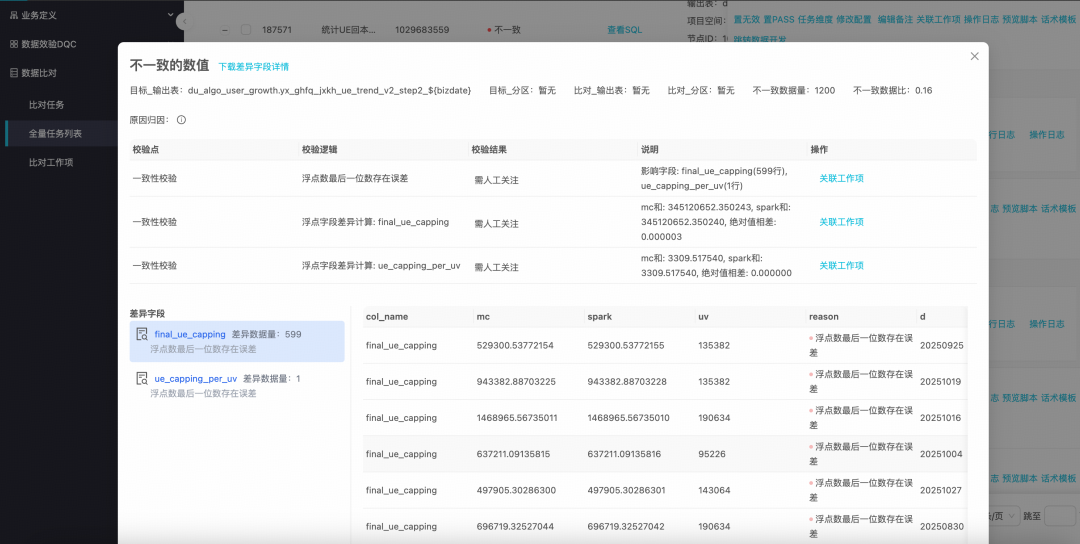
分析完成后,平台会提供清晰的比对结果统计(总数据量、一致/不一致数据量及不一致率),并可视化展示差异详情。用户可根据平台分析的差异原因,决定是手动标记通过还是对任务进行修复。
四、比数平台功能介绍
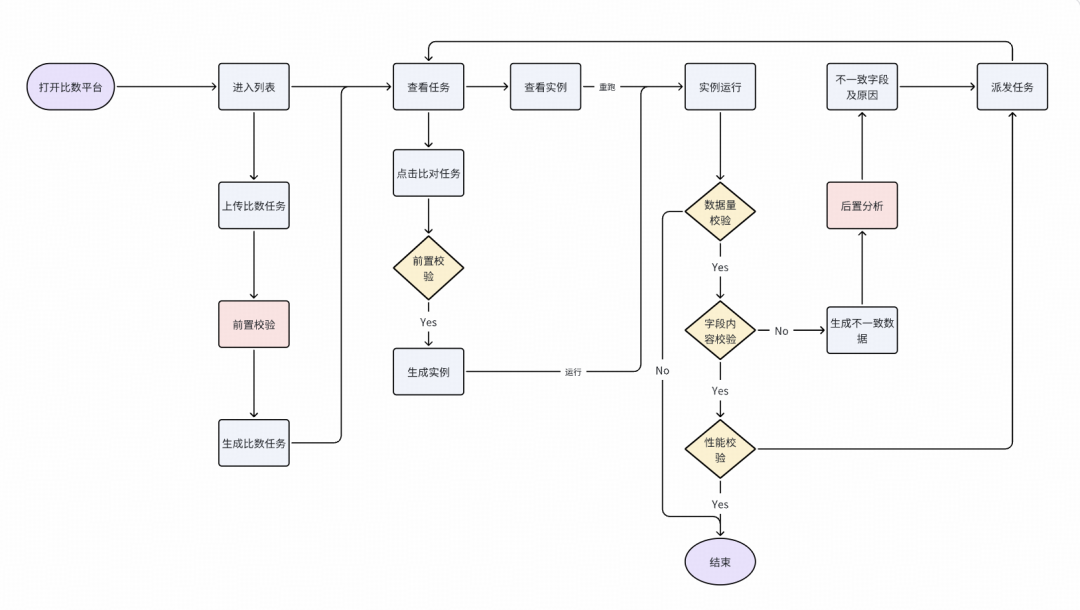
1.数据比对基本流程
Galaxy平台为用户提供了标准化的数据比对操作流程。
2.任务生成:三种比对模式
为了适应不同场景,平台支持三种任务生成模式。
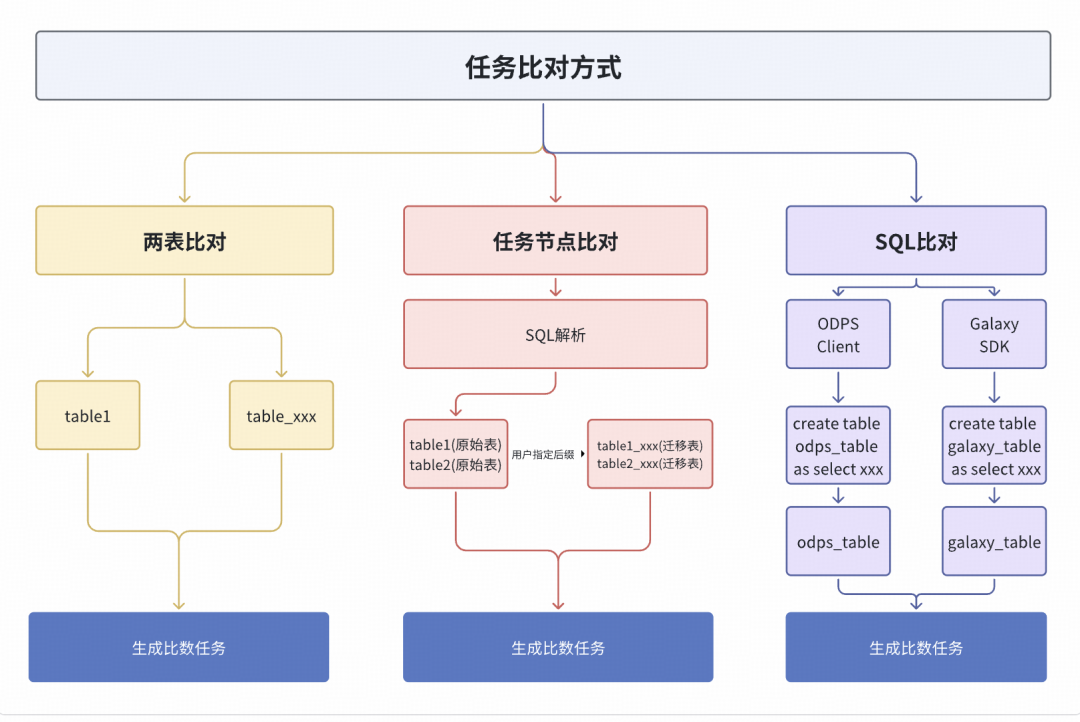
- 两表比对:最基础的比对方式。用户直接指定源表和目标表,平台启动全量数据比对。适用于临时的、单表比对场景。
- 任务节点比对:一个数据处理任务节点通常会产生多个输出表。此模式允许用户直接输入任务节点ID,平台自动解析其SQL代码,提取所有输出表,并批量生成比对任务,极大提升了迁移比对的效率。
- SQL查询比对:在进行SDK迁移时,业务方更关心特定查询语句在迁移前后的结果是否一致。此模式下,用户提交查询SQL,平台分别在ODPS和Spark引擎上执行,将结果集导出为临时表,再生成比对任务。
3.前置校验:提前发现问题
在全量比对这一资源消耗型操作开始前,进行前置校验至关重要。它能提前拦截因表结构不一致、环境问题等导致的必然失败,节省大量集群资源和时间。平台的校验主要涵盖以下几个方面:
- 元数据一致性校验:检查比对双方的字段名、类型、顺序、数量是否完全一致。
- 函数缺失校验:针对Spark引擎,校验SQL中使用的UDF(用户自定义函数)是否存在,避免因函数不支持而导致任务失败。
- 语法问题校验:分析SQL语句,识别在目标引擎中可能无法解析或会导致结果不一致的特定写法,并给出改写建议。


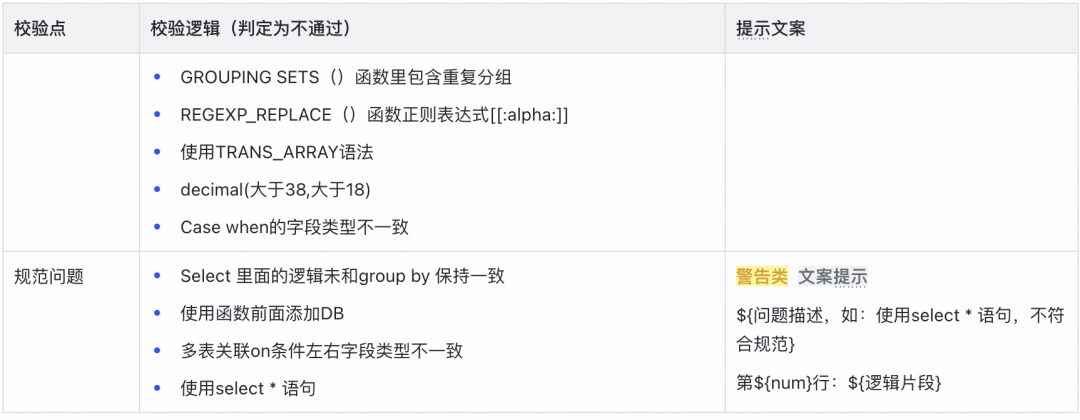
效果:通过强化前置校验,平台每日发起的无效比数任务从3000+下降至1500+,减少了约50%的资源浪费。其中,仅“UDF缺失”一项就拦截了1238个任务,一次性发现了87个缺失函数,避免了开发人员反复沟通和零散添加函数的时间成本。
4.破解比数瓶颈:资源分配与任务调度优化
随着接入团队增多,平台遇到了性能瓶颈:
- 资源不足与竞争:不同业务线(计算迁移、存储迁移、SDK迁移)的任务混跑,基础比数任务与耗时的根因分析任务相互抢占资源。
- 任务编排不合理:缺乏优先级机制,大任务可能长时间阻塞队列,影响小任务及时完成。
- 引擎参数未调优:Spark任务的并行度、数据分块大小等参数使用默认值,未能发挥最佳性能。
针对这些问题,平台进行了系统性优化:
- 业务队列隔离:为不同业务线划分独立的运行队列,避免相互影响。
- 读写队列分离:将数据比对(读密集型)和根因分析/结果写入(写密集型)任务分配到不同队列,防止“死锁”。
- 优先级调度:在业务队列内部,支持按批次、分时段和优先级运行,确保高优任务优先执行。
- 引擎参数调优:为Spark引擎设置了优化的公共参数,并允许用户根据任务特性自定义高级参数。
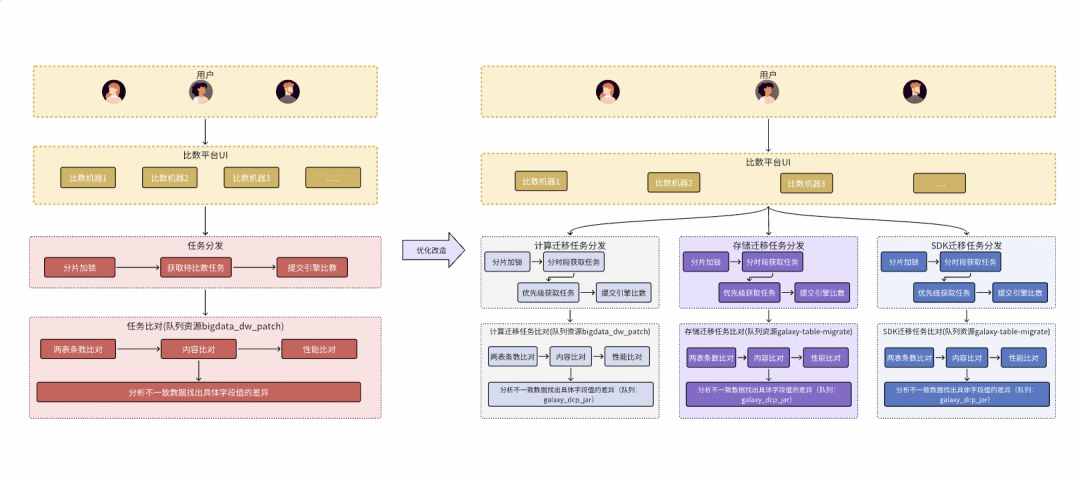
优化效果:
- 每日比数任务的整体完成时间从晚上22点提前至18点前。
- 用户自主找主键等交互接口的平均响应时间从58.5秒降低到26.2秒。
五、比数平台收益分享
截至目前,Galaxy比数平台已持续稳定运行500+天,每日可完成2000+个任务的自动化比对,累计完成有效比对128万+次,且保持0误判记录。
- 助力计算迁移团队:每月节省45+人日,高效完成了数据分析、离线数仓等核心任务的迁移与交割验证。
- 助力存储迁移团队:完成了超过20%存储数据的迁移一致性保障。
- 助力引擎团队:完成了800+批次引擎版本升级的回归验证,确保了每次发布的安全与稳定。
- 助力SDK迁移团队:保障了超过80%应用的平滑迁移。
六、未来演进方向
平台计划在以下方向持续演进:
- 智能分析引擎:针对JSON等复杂嵌套类型字段,探索引入大模型技术进行深度语义理解和根因分析。
- 比对策略优化:针对超大数据表,研发自动数据分片比对策略,进一步提升大表比对的成功率和效率。
- 通用方案沉淀:将平台在数据迁移场景中沉淀的典型解决方案产品化、通用化,赋能给更多有数据一致性校验需求的团队和场景。
七、结语
Galaxy比数平台是得物在面对海量数据迁移、确保数据一致性这一严峻挑战时,所构建的专项解决方案。从实践中来,到实践中去,它已从一个服务于特定迁移项目的工具,逐步演进为公司 数据平台 中一项不可或缺的基础设施。未来,它将继续作为数据质量的可靠守护者,在更广阔的场景中发挥作用。
 发表于 2026-1-21 01:52:11
|
查看: 146|
回复: 0
发表于 2026-1-21 01:52:11
|
查看: 146|
回复: 0
