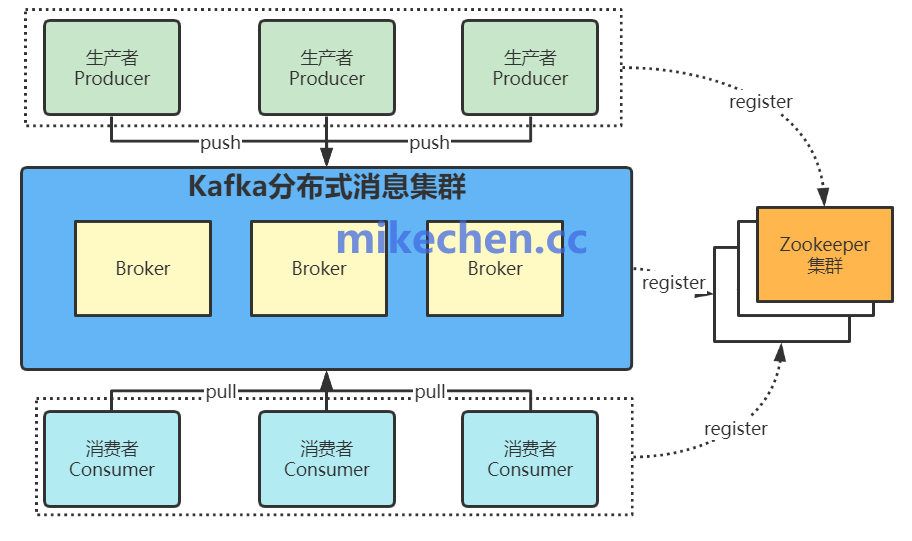
Kafka作为主流消息中间件,在各大互联网公司的技术栈中扮演着关键角色。然而,在分布式环境下,消息被重复消费是一个常见且棘手的问题。本文将深入剖析重复消费的根源,并系统性地介绍五种核心的解决策略,帮助你构建更健壮的消息处理系统。
为什么会产生重复消费?
在探讨解决方案之前,我们有必要先理解问题是如何产生的。重复消费通常并非Kafka本身的缺陷,而是由其“至少一次(at-least-once)”的默认投递语义与复杂的分布式环境共同作用的结果。常见的诱因包括:
- 消费者异常重启:消费者处理完消息但尚未提交偏移量(offset)时发生崩溃,重启后会从上次提交的偏移量开始重新消费。
- Rebalance(再平衡):当消费者组内的消费者数量发生变化(如扩容、缩容或故障),会触发分区重分配。在此过程中,消费者可能短暂失去分区所有权,导致已处理但未提交偏移量的消息被新分配到此分区的消费者再次处理。
- 生产者重试:生产者发送消息后未收到Broker确认(如网络抖动),会触发重试机制,可能导致同一条消息被发送多次。
理解了根源,我们就可以有针对性地设计防御方案。以下是五种从不同层面应对重复消费的主流方案。
方案一:业务端实现幂等性(最推荐)
这是最根本、最稳定且最可控的方案。其核心思想是:无论同一条消息被消费多少次,其对业务系统产生的最终影响都应与消费一次相同。
实现的关键在于为每条消息赋予一个全局唯一的业务标识符,例如订单ID、支付流水号等。
常见的实现思路有以下几种:
1. 基于数据库的唯一约束
设计一张“消息去重表”,表结构包含消息的唯一ID(作为主键或唯一索引)、消费状态、消费时间等字段。
处理流程如下:
- 消费者接收到消息。
- 开启数据库事务。
- 尝试向“消息去重表”中插入该消息的唯一ID。
- 插入成功:说明是第一次处理,继续执行后续业务逻辑,并在同一事务中完成业务数据更新。
- 插入失败(违反唯一约束):说明该消息已被处理过,直接丢弃或记录日志,不执行业务操作。
- 提交事务。
这种方式利用数据库的ACID特性保证了强一致性,适用于对数据准确性要求极高,且QPS(每秒查询率)不是特别极端的场景。
2. 基于Redis等缓存的原子操作
对于吞吐量要求更高的场景,可以利用Redis的原子操作(如SETNX)实现轻量级去重。
处理流程如下:
def process_message(message_id, biz_data):
# 尝试将message_id设置为键,值任意(如1),并设置合理的过期时间
lock_acquired = redis_client.setnx(message_id, 1)
if lock_acquired:
redis_client.expire(message_id, 3600) # 设置1小时过期,防止内存泄漏
# 执行核心业务逻辑
do_business(biz_data)
else:
# key已存在,说明消息已被处理,直接跳过
log.warning(f"Message {message_id} is duplicate, skipped.")
SETNX(SET if Not eXists)命令只有在键不存在时才会设置成功,这天然地实现了“检查-设置”的原子性。此方案性能优异,但需要注意缓存故障(如Redis宕机)可能导致去重逻辑失效,因此适用于可以容忍极低概率下短暂不一致的高吞吐场景。
方案二:启用生产者幂等性与消费者事务
1. 生产者幂等性(Producer Idempotence)
在生产者端,可以通过配置 enable.idempotence=true 来启用幂等性。其原理是,Kafka会为每个生产者实例分配一个唯一的PID(Producer ID),并为发送到同一分区的每条消息分配一个序列号(Sequence Number)。Broker端会缓存每个PID在每个分区上最近接收到的序列号,对于序列号不连续或重复的消息,Broker会直接拒绝。
这能有效防止因生产者重试导致的Broker端消息重复。但请注意,它无法解决因消费者端故障或Rebalance导致的重复消费问题。
2. 消费者事务(Consumer Transactions)
这是Kafka提供的一种更强的一致性保障机制,旨在实现“精确一次(Exactly-Once)”处理语义。
核心原理是将消费者的偏移量提交(Offset Commit)与它对外部系统(通常是数据库)的写入操作绑定在同一个事务中。这需要借助支持事务的消费者客户端或流处理框架(如Kafka Streams)。
一个典型的事务型消费者处理流程如下:
- 初始化一个事务。
- 拉取消息。
- 开始数据库事务。
- 执行业务逻辑并更新数据库。
- 将处理完的消息偏移量作为“事务消息”发送到一个特殊的Kafka事务日志中。
- 提交事务(此操作会原子性地提交数据库变更和Kafka的偏移量)。
如果中间任何步骤失败,整个事务回滚,偏移量不会被提交,数据库状态也会恢复,从而保证了端到端的一致性。此方案功能强大,但实现复杂度高,且会带来额外的性能开销。
方案三:利用Kafka自身的事务与流处理语义
对于完全在Kafka生态内的流处理作业,可以利用其高级API来实现“精确一次”。
- Kafka Streams:该库内置了“精确一次”处理语义的支持。它通过将中间状态存储在Kafka的变更日志(Changelog)主题中,并将状态更新与输入记录的偏移量提交协调在同一事务内来实现。
- Kafka Connect(带有Exactly-Once语义的Sink Connector):某些官方的Sink连接器(如写入JDBC数据库的连接器)支持“精确一次”交付模式。它们内部实现了与“方案二”中消费者事务类似的机制。
这类方案将复杂性封装在了框架内部,对于使用这些框架的用户而言,是避免重复消费非常优雅的方式。
方案四:手动管理偏移量(谨慎使用)
Kafka消费者默认是自动周期性提交偏移量的。你可以通过设置 enable.auto.commit=false 改为手动提交。
手动提交给了你更精准的控制权:确保在业务逻辑成功执行完成后再提交偏移量。这样可以避免消费者在业务处理中和提交偏移量之间崩溃导致的重复消费。
然而,这种方案要求开发者必须妥善处理提交失败、重复提交等各种边界情况,否则极易导致消息丢失(如果提交了偏移量但业务实际失败)或更严重的重复消费。通常不建议在复杂的生产环境中单独使用此方案,而是作为其他方案(如幂等性)的辅助手段。
方案五:消息日志与对账补偿(最终一致性)
在一些金融或对账场景,即使实现了幂等,也可能需要事后百分之百的核对。这时可以引入“消息审计日志”和“离线对账”机制。
- 记录详细日志:在消费端,无论是否重复,都记录下每一条消息的ID、消费尝试时间、处理状态、业务结果等。
- 离线对账:定期(如每天)运行对账任务,将消息日志与业务系统的最终状态(如订单表)进行比对,找出可能存在的不一致(例如,有消费成功日志但无对应订单)。
- 补偿修复:对于对账发现的问题,进行人工或自动化的补偿操作。
这是兜底的最终一致性方案,能最大程度保证数据的最终正确性,但实时性最差,运维成本也较高。
总结与选型建议
没有一种方案是放之四海而皆准的“银弹”。在实践中,我们通常需要根据业务场景进行组合选择:
- 通用场景(强推荐):“业务幂等性 + 生产者幂等性”。这是绝大多数应用的首选组合,能以合理的复杂度获得极高的可靠性。
- 金融交易、计费等高敏感场景:在方案1的基础上,可以叠加 “消费者事务” 或使用支持EOS(Exactly-Once Semantics)的 “Kafka Streams” 框架,并辅以 “离线对账” 作为终极保障。
- 简单数据处理、日志收集场景:若可以接受极低概率的重复,可以只使用 “生产者幂等性” 并设置合理的消费者参数来降低重复概率。
最后,架构设计本质上是一种权衡。理解每种方案的原理、优势与代价,才能在你的系统复杂度、开发成本、性能要求与数据一致性需求之间找到最佳平衡点。
如果你在设计与实现分布式消息系统时遇到了其他挑战,欢迎到 云栈社区 的 后端 & 架构 或 数据库/中间件/技术栈 等板块与更多开发者交流探讨。
 发表于 2026-3-4 17:32:08
|
查看: 151|
回复: 0
发表于 2026-3-4 17:32:08
|
查看: 151|
回复: 0
