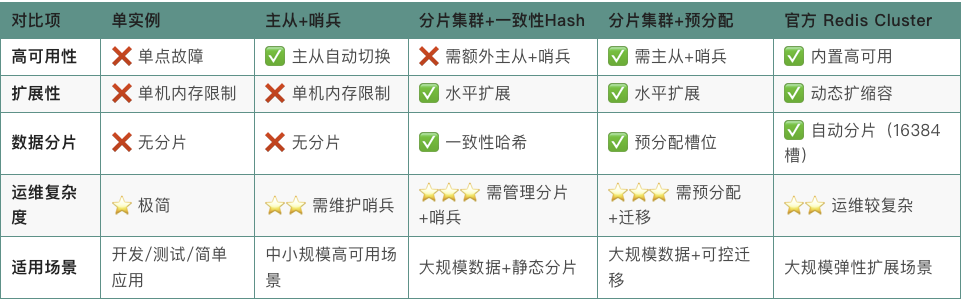
这篇文章,分享自己职业生涯经历的五种 Redis 部署模式,希望对大家有所启发。
单实例
这是 Redis 最简单、最基础的部署方式,即:整个 Redis 服务运行在单个服务器和单个进程中。
笔者第一次在生产环境使用 Redis ,是在艺龙红包系统中,使用 Redis 实现分布式锁。
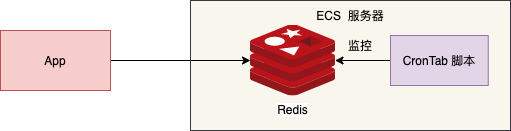
因为上线时间要求比较着急,运维说有一个实例可以不用申请,可以直接用,于是就采用了单实例的模式。笔者还特意和运维说假如 Redis 挂了,就通过 Linux 定时任务重新启动 。
单实例模式的优点显而易见:简单(部署、配置、维护),但缺点同样突出:服务器宕机,服务将完全不可用,同时内存大小受限于服务器。这种模式通常在开发、测试或对可用性要求不高的简单应用中使用。
主从 + 哨兵
在艺龙红包系统初版上线后,团队架构师向我介绍了Redis的高可用方案——主从复制+哨兵集群模式。这种部署模式通过主从数据同步实现数据备份,配合哨兵集群的自动故障检测与主从切换能力,能够有效保障服务的高可用性。
如图所示的架构中:
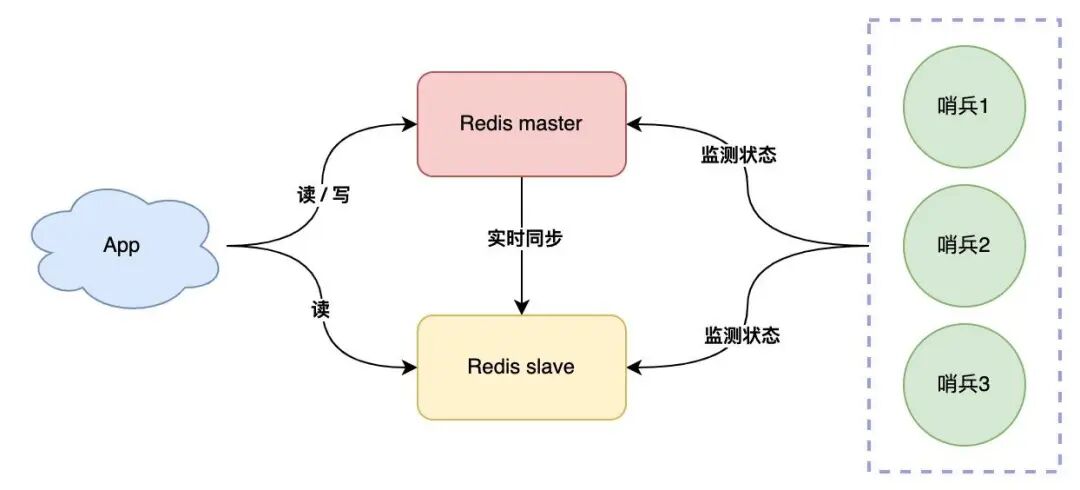
- 主节点负责处理所有写请求
- 从节点实时同步主节点数据,可分担读请求
- 哨兵集群持续监控节点健康状态
- 当主节点故障时,哨兵会自动选举新的主节点
通过这种改造,红包系统的缓存架构获得了质的提升:不仅避免了单点故障风险,还实现了读写分离,整体系统的稳定性和可用性都得到了显著增强。即便在突发故障情况下,也能保证红包业务持续稳定运行。
分片集群 + 一致性 Hash
「主从 + 哨兵」模式非常健壮,但当缓存数据量超出单机内存容量时,这种模式就有瓶颈了。这时就需要引入多组独立的 Redis 实例来分摊数据,即分片集群。
艺龙的流式计算服务的计算过程大量依赖这种多 Redis 实例模式 ,如下图:
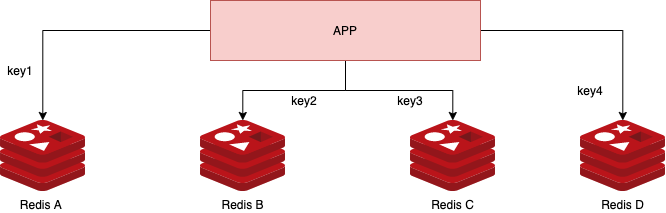
为了实现数据在各个分片间的均匀分布与高效路由,我们可以采用一致性哈希算法:
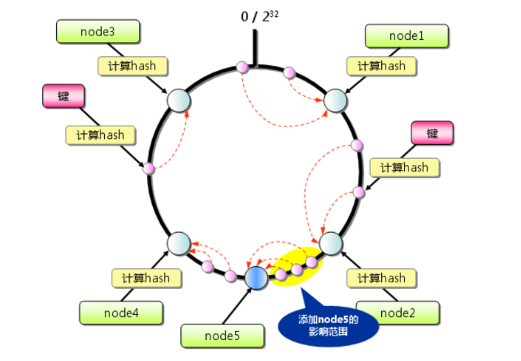
- 哈希环构建:将整个哈希空间(0~2^32-1)组织成环形结构 。
- 节点映射:对每个Redis节点计算多个虚拟节点(通常200-300个)的哈希值,均匀分布在环上 。
- 数据路由:对每个key计算哈希值,在环上顺时针找到最近的节点 。
然而,上述流式计算中使用的 Redis 集群仅为单主模式,存在高可用风险。某个分片挂掉,整个系统就会出现问题。解决方案其实很简单:为每个分片配置主从模式,并引入哨兵集群进行监控和自动切换。
改造后的缓存部署架构(参考神州专车订单缓存部署架构)如下图所示:
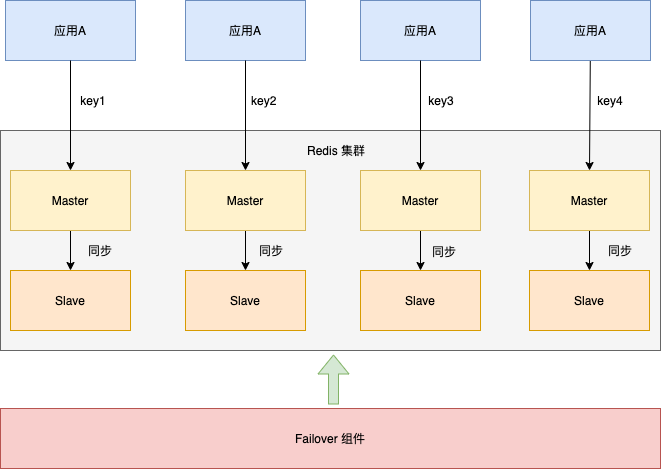
分片集群 + 预分配
当我们再来看「分片集群 + 一致性 Hash」这种模式时,虽然看起来很完美,但是它有一个隐形的缺点:当需要新增分片节点时,数据迁移会涉及大量key的重新分布,难以做到平滑迁移。
解决这种问题最有效的方案是:预分配槽位。
笔者曾经介绍过专车的分库分表算法。假设现在需要将订单表平均拆分到 4 个分库 shard0 ,shard1 ,shard2 ,shard3 。
首先将 [0-1023] 平均分为4个区段:[0-255],[256-511],[512-767],[768-1023],然后对字符串(或子串,由用户自定义)做 hash, hash 结果对 1024 取模,最终得出的结果 slot 落入哪个区段,便路由到哪个分库。
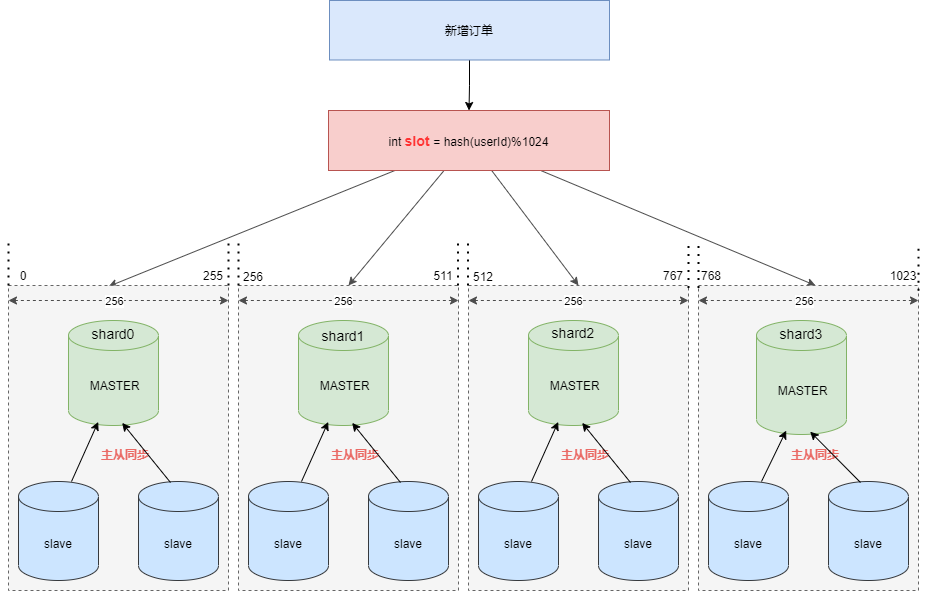
我们可以将分库分表的预分配理论应用到 Redis 分片集群中,见下图:
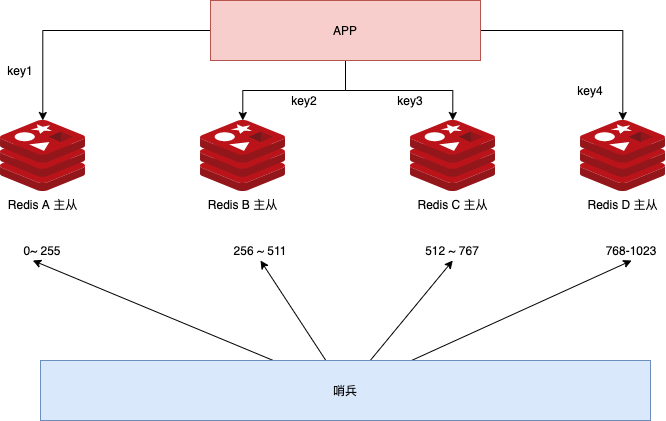
大名鼎鼎的开源项目 Codis 也是使用预分配的技巧。「分片集群 + 预分配」既可以保留分片集群的可扩展的优势,也可以通过预分配槽位的技巧实现较为平滑的数据迁移,但数据迁移的具体操作仍然非常考验架构师的功底。
那么,有没有一种方案可以原生支持高可用、数据分片和弹性扩缩容呢?有的,它来了,它就是:官方 Redis Cluster。
官方 Redis Cluster
笔者在花生好车和科大讯飞都使用过 Redis Cluster 这种模式。
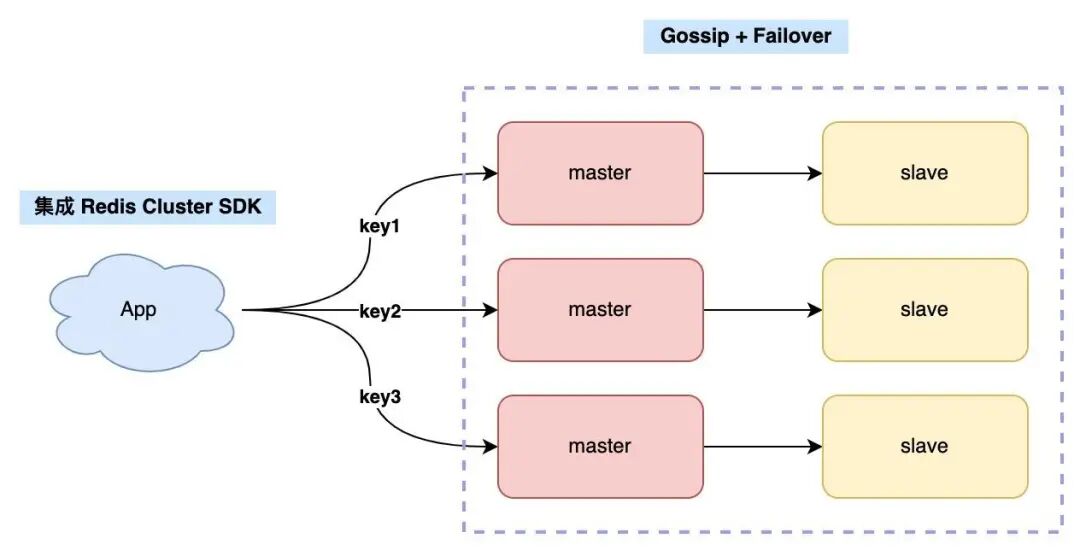
Redis Cluster 集群具有如下几个特点:
- 集群完全去中心化,采用多主多从架构。
- 每一个分区(shard)都是由一个Redis主机和多个从机组成,分片和分片之间是相互平行的。
- Redis Cluster 无需额外部署哨兵集群,集群内 Redis 节点通过 Gossip 协议互相探测健康状态,在故障时可发起自动切换。
- Redis Cluster将数据分为16384个槽位,每个节点负责管理一部分槽位。
- 当客户端向 Redis Cluster 发送请求时,Cluster 会根据键的哈希值将请求路由到相应的节点。具体来说,Redis Cluster 使用 CRC16 算法计算键的哈希值,然后对16384 取模,得到槽位编号。
- Redis Cluster 提供了配套的 SDK,只要客户端升级 SDK,就可以与 Redis Cluster 集成。SDK 会帮你找到 key 对应的 Redis 节点进行读写,还能自动适配节点的增加和删除,业务侧无感知。
Redis Cluster 从功能来讲,已经非常强大,在提供高可用性的同时,实现了数据分片和负载均衡,适用于大规模数据存储和高性能要求的场景。但是,其配置和运维相对复杂,并且一些涉及多个key的复杂操作(除非这些key在同一个槽位)可能受到限制。
真的有银弹吗
在 Redis 的部署模式演进过程中,从单实例到 Redis Cluster,我们看到了不同架构的优缺点。但没有一种方案是完美的银弹,每种模式都有其适用场景和局限性。
所以,我们需要深入理解业务需求,在性能、扩展性、高可用和运维成本之间做出权衡,才能选择最合适的部署模式。如果你对更多数据库与中间件的技术选型和架构设计感兴趣,欢迎到 云栈社区 的 数据库/中间件技术板块 与其他开发者交流探讨。
 发表于 2026-1-21 10:17:14
|
查看: 140|
回复: 0
发表于 2026-1-21 10:17:14
|
查看: 140|
回复: 0
