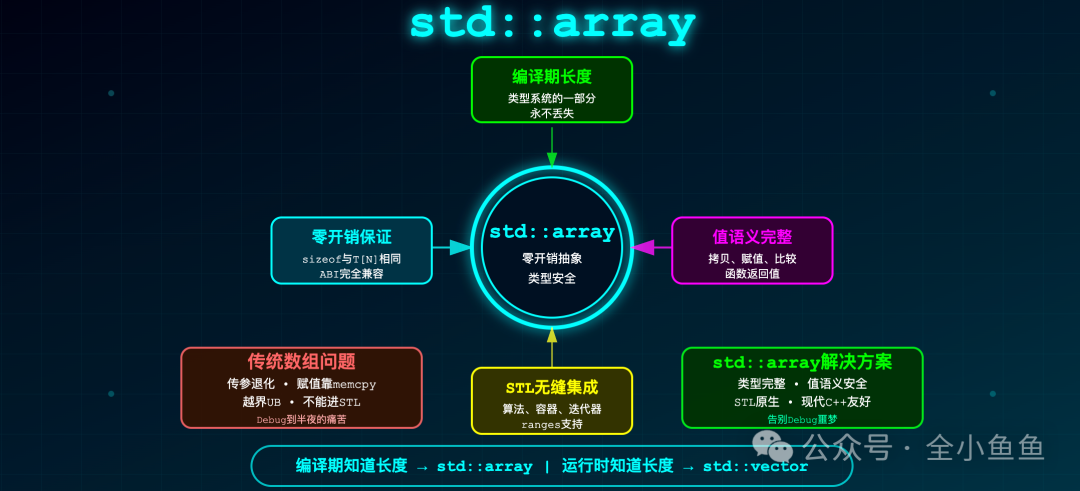
std::array 的存在,就是为了让固定大小的数组真正成为一个完整的对象:它能正常传参、能赋值、能比较、能无缝融入 STL 生态。
使用传统的内置数组(C-style array)时,你是否遇到过这些麻烦?传参时它会退化成指针,长度信息直接丢失;赋值需要依赖 memcpy,不仅容易出错,在包含非平凡(non-POD)类型成员时更会导致未定义行为(UB);越界访问在 Release 构建下往往静默崩溃,让调试过程异常痛苦。
关于如何选择容器,一个核心经验是:在编译期就知道数组长度时,就使用 std::array;如果长度在运行时才能确定或会变化,则使用 std::vector。
一、三者本质不同
很多人将 std::vector、std::array 和内置数组 T[N] 放在一起比较,但实际上它们解决的是不同维度的问题。

1. std::vector 是动态容器
它在堆上分配内存,支持动态扩容,代价是可能发生重分配(realloc)、导致迭代器失效,以及缓存局部性可能存在波动。它非常适合长度未知或会变化的场景。
2. T[N] 是语言原生类型
元素直接内嵌在栈或对象的内存布局中,非常紧凑,是“零开销抽象”的基石。但它不能像普通对象那样使用:传参会退化成指针,不能直接赋值,不能作为函数返回值,也不能用作 std::map 的键。
3. std::array 是标准库对 T[N] 的现代化封装
它的内存布局与 T[N] 完全一致(sizeof(std::array<T, N>) == sizeof(T[N]),对齐方式相同),没有任何额外开销。关键在于,它在类型系统层面是一个完整的对象。
std::array 在所有主流编译器(GCC、Clang、MSVC)中都被实现为聚合类型,内部仅包含一个 T[N] 成员,因此其 ABI(应用程序二进制接口)与内置数组完全兼容。你可以安全地将其用于二进制协议解析、硬件寄存器映射或跨模块/库的边界传递。
二、std::array vs 内置数组

1. 类型安全:长度信息永不丢失
内置数组的问题:
void process(float data[4]); // 实际签名为 void process(float*)
调用时:
float buf[4] = {1,2,3,4};
process(buf); // N=4 这个信息在进入函数时就丢失了
std::array 的解决方案:
void process(const std::array<float, 4>& data) {
static_assert(data.size() == 4); // 编译期即可获知并校验长度
}
std::array<float, 4> buf = {1,2,3,4};
process(buf); // 类型完整传递,无退化
2. 值语义完整:可拷贝、可赋值、可返回
内置数组不能直接赋值:
struct Point { double coords[3]; };
Point p1{{1,2,3}}, p2;
p2 = p1; // 表面成功,实则是 memcpy,若含非 POD 成员则导致未定义行为
std::array 可以:
struct Point { std::array<double, 3> coords; };
Point p1{{{1,2,3}}}, p2 = p1; // 调用 array 的拷贝构造函数,安全可靠
3. 容器接口统一:无缝接入 STL
std::array<int, 5> a = {5,3,1,4,2};
std::sort(a.begin(), a.end()); // 直接使用,无需手动计算边界
std::ranges::transform(a, a.begin(), [](int x) { return x * 2; }); // C++20 Ranges
auto view = a | std::views::take(3); // 管道操作符组合
而使用内置数组则必须手动传递 a, a+5 这样的迭代器范围,既容易出错又难以维护。
4. 安全与可维护性
std::array<int, 10> buf;
buf.at(15) = 42; // 抛出 std::out_of_range 异常,调试友好
buf.fill(0); // 类型安全的初始化,优于 memset
if (buf1 == buf2) // 提供逐元素比较运算符,语义明确
相比之下,内置数组的越界访问是未定义行为,错误难以追踪。
三、该用 std::array 而不是 std::vector 的场景
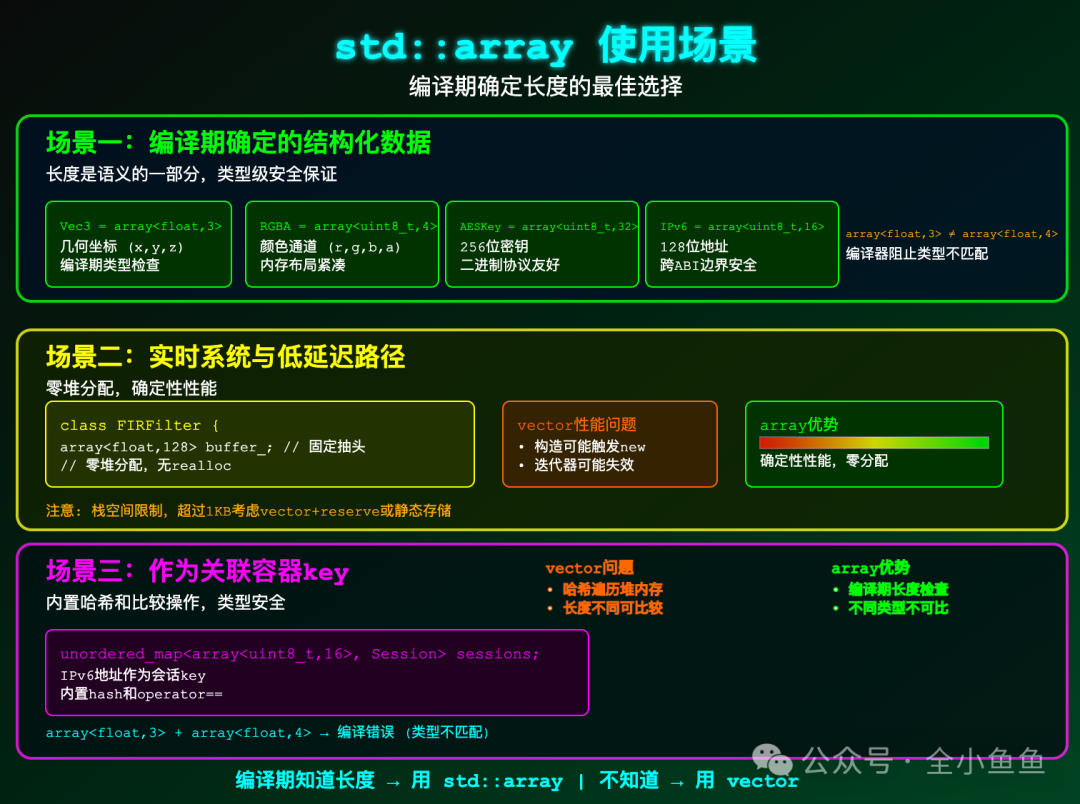
场景一、编译期确定的结构化数据
- 几何:
Vec3 = std::array<float, 3>
- 颜色:
RGBA = std::array<uint8_t, 4>
- 密码学:
AESKey = std::array<uint8_t, 32>
- 网络:
IPv6 = std::array<uint8_t, 16>
在这些类型中,长度本身就是语义的一部分。std::array<float, 3> 和 std::array<float, 4> 是完全不同的类型,编译器会阻止你将一个三维点与四维向量相加,这提供了 std::vector 无法实现的类型级安全。
场景二、实时系统与低延迟路径
高频交易、音频数字信号处理(DSP)、嵌入式控制等场景要求不能有堆分配,且性能必须可预测。
std::vector 即使提前 reserve,在构造时也可能触发一次 new;而 std::array 的数据完全内嵌在对象自身中,实现零动态分配,访问速度具有确定性。
class FIRFilter {
std::array<float, 128> buffer_; // 固定大小的抽头缓冲区,无堆分配
size_t pos_ = 0;
public:
float process(float x) {
buffer_[pos_] = x;
// 进行卷积计算...
pos_ = (pos_ + 1) % 128;
return y;
}
};
注意:std::array 占用栈空间,如果 N 过大(例如超过 1-4KB),放在栈上可能导致栈溢出。此时,即使长度固定,也应考虑使用 std::vector 并提前 reserve,或者使用静态存储。
场景三、作为关联容器的键(Key)
std::unordered_map<std::array<uint8_t, 16>, Session*> sessions; // IPv6地址作为会话Key
std::array 自带了 operator== 和 std::hash 特化,可以直接用作关联容器的键,开箱即用。
std::vector 虽然也能作为键,但其比较和哈希需要遍历堆内存,性能较差。更棘手的是,两个长度不同的 std::vector 进行比较是合法的(结果为 false),逻辑错误可能被隐藏。而 std::array<float, 3> 和 std::array<float, 4> 根本就是不同的类型,编译时就会报错,从根本上杜绝了此类错误。
四、为什么不直接用内置数组?

在 -O2/-O3 优化级别下,std::array<T, N> 和 T[N] 的访问性能没有区别,编译器生成的汇编代码通常一模一样。
问题的关键不在速度,而在于与现代 C++ 生态的融合度与使用的便利性:
- 模板友好性:写模板函数想自动推导数组长度,
T[N] 的语法复杂易错,而 std::array<T, N> 简洁安全。
- 结构化绑定:
auto [r, g, b, a] = color;,float[4] 不支持,std::array<float, 4> 完美支持。
constexpr 支持:在常量表达式中操作数组,C++20 之前 T[N] 的许多操作受限,std::array 则拥有完整的 constexpr 支持。- 与
std::span 集成:将数组传递给 std::span 视图,T[N] 需要手动传入长度参数容易出错,而 std::array 可以自动推导长度,类型安全。
std::array 让上述所有操作都能直接、自然地完成。
许多人最初认为 std::array 是多此一举,但在经历过几次因内置数组的陷阱而调试至深夜的痛苦后,就会明白:std::array 不是为了炫技,而是为了让固定大小的数组能够在现代 C++ 的生态中,像一个普通的、行为良好的对象一样工作。
你是否也曾为了省事而使用内置数组,最终却陷入调试的泥潭?是时候做出更明智的选择了。
 发表于 2026-1-21 12:42:24
|
查看: 158|
回复: 0
发表于 2026-1-21 12:42:24
|
查看: 158|
回复: 0
