随着AI模型的复杂度不断增加,AI系统对存储器的要求也水涨船高:需要更大容量、更低延迟、更高带宽以及更高能效。不同形式的存储器各有优劣。SRAM速度极快但密度低,成本高昂。DDR DRAM密度高且价格低廉,但带宽有限。当今最流行的选择是片上HBM(高带宽内存),它在容量、带宽和能耗之间取得了最佳平衡。
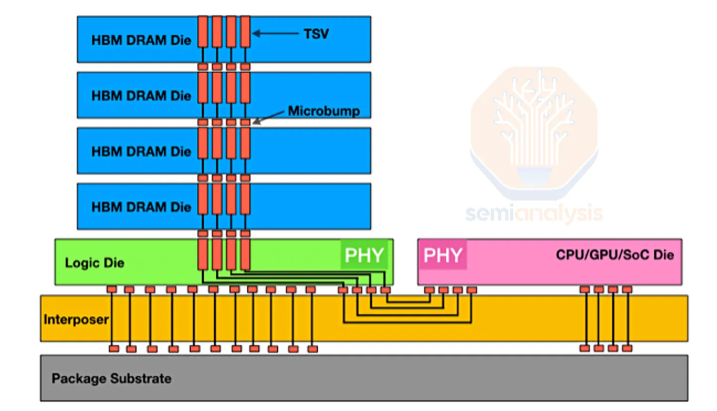
HBM通过垂直堆叠DRAM芯片并结合超宽数据路径,为AI工作负载提供了卓越的带宽、密度和能耗表现。尽管生产成本更高,但对HBM的需求依然强劲。所有用于GenAI训练和推理的领先AI加速器都依赖于HBM。行业路线图的普遍趋势是通过增加堆叠层数、采用更高层级以及转向更快的HBM代际,来持续提升每个芯片的内存容量和带宽。依赖其他存储形式的架构在性能上已显乏力。
HBM简介
HBM的独特之处及其制造挑战是什么?虽然HBM以多个DRAM芯片在3DIC组件中堆叠而闻名,但其另一个关键特性是更宽的数据总线。即使信号传输速度一般,更宽的总线也能带来极高的带宽,使HBM在单位封装带宽上远超其他任何内存形式。
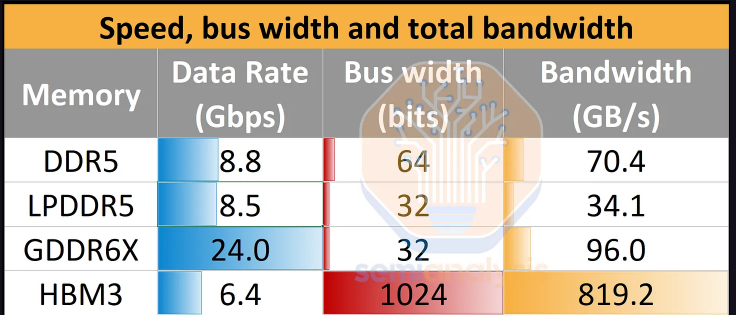
大量增加的I/O接口意味着更高的布线密度和复杂性。每个I/O都需要独立的连线,还需额外的线路用于供电和控制。对于HBM3E堆栈,相邻的XPU(如GPU)与HBM之间有过千条导线。这种布线密度无法在PCB或封装基板上实现,因此需要像CoWoS这样的2.5D封装技术,并依赖中介层(硅基或有机基板)进行互连。
为降低数据传输延迟和能耗,HBM需要紧邻计算引擎放置。这使得芯片边缘区域变得极为重要,因为HBM通常只能放置在芯片的两个边缘,另外两个边缘则需留给封装外部的I/O。这限制了HBM的放置区域,从而需要通过垂直堆叠内存芯片来提供足够容量。
实现3DIC结构,堆叠中的每一层(顶层除外)都需要TSV(硅通孔)来向上层传输电力和信号。这些TSV所需的额外面积,是HBM芯片尺寸大于同等规格DDR芯片的主要原因。TSV工艺是标准DRAM与HBM之间的核心区别之一,相关工具设备也是将常规DDR DRAM晶圆产能转化为HBM产能的主要瓶颈。
另一区别在于后端工艺,HBM需要在底层逻辑芯片之上堆叠8层或12层DRAM芯片(共9或13层)。与CoWoS技术一样,HBM已将先进封装技术推向主流。像MR-MUF(批量回流塑封)这样的特殊封装技术如今已成为业内的通用知识。
比特需求的激增
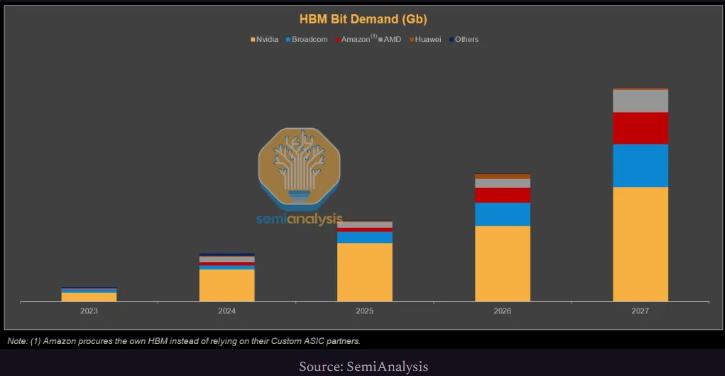
随着AI加速器需求增长,HBM比特需求也大幅上升。尽管各类ASIC迅速崛起,但到2027年,英伟达凭借其雄心勃勃的路线图(如Rubin Ultra将单GPU容量提升至1TB),仍将占据HBM需求的绝大部分份额。
工艺流程:前端
将常规DDR DRAM产能“转换”为HBM产能,主要变化在于增加了用于形成TSV的设备,并且由于HBM晶圆需要双面凸点加工,其凸点加工能力也需提升。这两个步骤都是为了实现3D堆叠,但对于用于堆叠顶层的芯片晶圆,由于只需单面凸点且无需TSV,这些步骤可以省略。
通过光刻制造三维TSV需要刻蚀机来创建通孔,以及沉积和电镀设备来填充这些通孔。要暴露这些TSV,还需要研磨机、另一道刻蚀工序以及临时粘合材料。因此,当前HBM的产能常以TSV产能来表述,因为这是将DDR晶圆转化为HBM晶圆的主要增量工艺步骤。
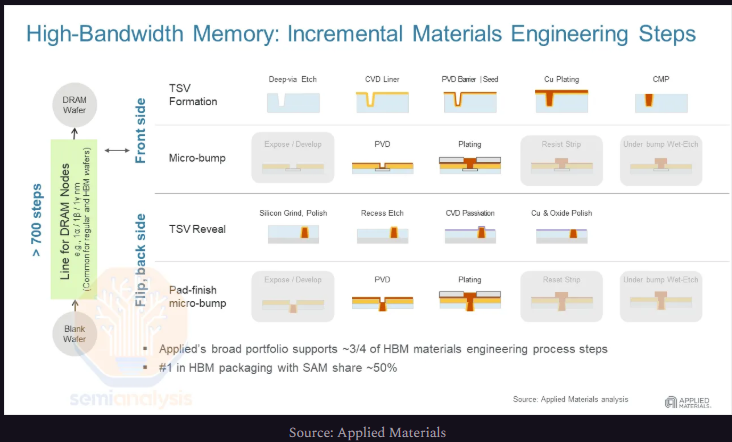
工艺流程:封装
另一部分是后端封装,即SK海力士主导的MR-MUF技术。简而言之,MR-MUF具有更高的生产效率和更好的散热性能。海力士专有的(与NAMICS共同开发)注塑填充材料,在散热方面比美光和三星使用的非导电薄膜更具优势。海力士能够避免使用热压键合(TCB),是因为他们找到了其他方法来控制芯片翘曲。
该工艺效率更高,采用批量整体回流和单次模塑步骤形成连接。相比之下,使用TC-NCF(热压非导电薄膜)则需要对每一层都进行完整的TCB步骤。

工艺流程:良率
HBM在技术上比其他类型DRAM更为复杂,尤其是其高层的3DIC堆叠结构。因此,其封装良率与制造商习惯的传统产品水平不同。然而,前端的良率挑战也很大。
其中一个挑战在于电源分配网络(PDN),因为微凸点技术涉及的线路需要将电力沿堆叠向上输送。微凸点的布局和设计是专有技术,也是不同制造商之间的主要差异所在。
HBM的一个关键挑战是如何通过电源TSV将电力有效传输至顶层。刷新操作尤其耗电,因此PDN设计至关重要。所有制造商的HBM良率都远低于传统存储芯片晶圆的水平,这涉及到相对产量和最终经济效益。对于SK海力士和美光,较高的售价弥补了良率损失,使HBM具有盈利性。
更高的堆叠层数意味着更大的挑战。简单来说,如果单层堆叠良率是x%,那么n层堆叠的总良率是x%的(n-1)次幂。例如,8层堆叠,若每层堆叠良率99%,总良率约92%;12层堆叠则降至约87%。随着层数增加,非关键的堆叠缺陷会累积,导致良率下降。
工艺流程:键合工具与供应链
键合或芯片贴装步骤是影响良率的关键,需要先进的工具。由于TSV间距约为40微米,键合器必须具备亚微米级的对准精度。压力分布也至关重要,以避免在多层结构中加剧翘曲。生产效率直接影响成本。
韩国设备商Hanmi多年前就专注于热压键合(TC)领域,以开拓HBM市场,这一策略使其在当前的HBM生产流程中占据了近乎垄断的地位。近期,SK海力士引入了竞争对手的设备,引发了供应链紧张,甚至一度影响了生产支持服务,凸显了关键设备供应商的重要性。

中国:CXMT和华为HBM
出口限制规定禁止将所有HBM堆叠材料转移到中国境内。但由于HBM是加速器的关键组件,中国自然将资源投入国内开发。中国计划在未来五年为本土半导体产业提供巨额补贴,预计其中很大一部分将用于HBM研发。DRAM行业领军企业长鑫存储(CXMT)正在大力扩充HBM产能以应对出口管制。
HBM堆叠层数:是否选择混合键合?
HBM堆叠层数越多,存储容量越大。此前,堆叠高度被限制在720微米内。为了增加层数,每个芯片(顶层除外)都变得更薄,凸点间距也更细。越来越薄的芯片更容易发生翘曲和断裂,从而降低良率。
混合键合的主要优势在于无需凸点,通过消除凸点间隙为容纳更多DRAM核心层提供空间。但它带来了新的生产良率和成本挑战。HBM并不需要混合键合所提供的那种极高密度互连。
HBM3和HBM3E采用12层高的堆叠结构,并仍使用基于凸点的互连。由于在720微米厚度内12层堆叠已接近极限,实现更高层数要么采用无凸点技术,要么增加堆叠总高度。目前,JEDEC已确认将堆叠高度放宽至775微米。
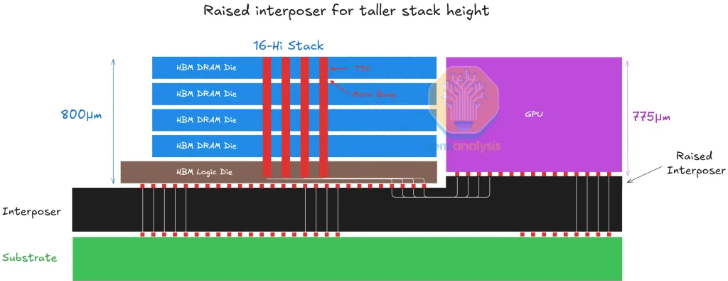
虽然16层结构通过增加堆叠高度得以实现,但要达到20层及以上,可能需要进一步缩小凸点间距并对晶圆进行更大幅度的减薄,或者将层数限制在16层以内。
通过优化吞吐量:I/O是AI加速器的生命线
AI加速器的关键特征在于高度并行化,并针对吞吐量进行了优化。它们的设计旨在最大化每秒操作总数,以满足AI训练和推理的需求。相比之下,CPU核心更“智能”,能执行更复杂任务,但吞吐量低得多。
AI加速器需要巨大的片外带宽来处理数据以及与外部互联。如果带宽不足,计算单元将无法得到充分利用,强大的并行计算能力便形同虚设。
内存容量增加
提高性能的关键一直在于增加内存容量、带宽和算力。容量和带宽的扩展有三个维度:
- 新一代HBM通过更快的信号传输速度和更密集的核心芯片实现更高带宽。
- 增加每堆叠的层数以提高容量,12层高HBM即将成为主流。
- 每个封装内增加更多的HBM堆叠,以增加总带宽和容量。
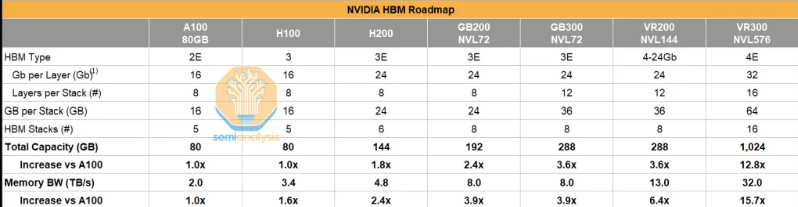
英伟达的路线图清晰体现了这一点。HBM容量从A100的80GB HBM2E增加到了未来Rubin Ultra的1024GB HBM4E,每个芯片的内存带宽也大幅提升。
这也与对非内存I/O(如芯片间互联)的需求增长有关。增加单个一致性域中的GPU数量可以提供更大的总内存容量和带宽,从而支持更大参数规模的模型和更长的上下文长度。
现代AI似乎遵循一种“内存帕金森定律”:神经网络架构会不断扩张,直至占满任何可用的HBM空间。每一代HBM容量和吞吐量的提升,都会迅速促使设计者增加参数数量、上下文长度和KVCache大小,从而抵消之前预留的空间。
HBM在推理中的应用
在LLM推理过程中,模型所有权重永久存储在封装的HBM中,以便GPU无延迟获取。此外,HBM还保存着KV(键值)缓存。每次生成下一个词时,GPU首先从HBM读取权重,同时获取整个KV缓存,以便在自注意力阶段将新词与历史对话比较。计算完成后,GPU将新词的KV添加回HBM,扩大缓存。
这对带宽要求极高,因为每个词解码步骤都会反复读取静态权重和不断增长的KV缓存。如果内存带宽不足,GPU将花费更多时间等待数据而非计算。实际上,带宽需求明显超过了词解码的计算强度,使得大多数LLM推理工作负载受限于内存带宽,而非算力。
随着模型能力的演进,其处理的上下文长度也在急剧增加,这给内存容量带来了巨大压力。尽管近期有一些技术进步降低了每个token的KV缓存量,但内存限制仍在快速增长。
KV缓存卸载
有多种算法或系统级的改进旨在减轻对稀缺HBM容量的压力。其中一种技术是将KV缓存卸载到成本更低、更易获取的内存层级,例如传统的DDR内存甚至NVMe存储设备。
如今,KV缓存卸载技术已得到应用。从概念上讲,这与通用处理器中的多层内存缓存类似:极快但容量小的L1/L2/L3缓存,以及较慢但容量大的DRAM。在AI系统中,KV的存储位置和管理根据其使用频率决定。优化良好的系统会将当前活跃的KV存储在HBM中,不常使用的存储在DDR中,极少使用的则存储在NVMe中。
至于使用DDR还是NVMe,取决于工作负载的需求、规模以及循环频率。频繁循环的KV不适合写入耐久度有限的NAND闪存。这些是架构和用户体验方面的权衡。
预训练中的HBM应用
在传统预训练中,GPU执行一次前向和反向传播所需的所有数据都通过HBM传输。首先,模型权重存储在HBM中。每层计算完一批数据的前向传播后,会将中间激活值写入HBM暂存。
前向传播完成并计算出损失后,开始反向传播:GPU重新访问存储的激活值和权重,从HBM中读取它们来计算梯度。产生的权重梯度和优化器状态也会写入HBM。最后,优化器从HBM读取这些信息来更新权重。
然而,训练操作相对于数据传输所需的计算量更大,这意味着训练往往更多地受到计算能力的限制。但强化学习现在是提升模型能力的关键,而强化学习很大程度上类似于一种特殊形式的推理。
本文基于SemiAnalysis的报告编译,原文链接:https://newsletter.semianalysis.com/p/scaling-the-memory-wall-the-rise-and-roadmap-of-hbm。了解更多前沿技术解析,欢迎访问云栈社区。
 发表于 2026-1-22 05:58:33
|
查看: 394|
回复: 0
发表于 2026-1-22 05:58:33
|
查看: 394|
回复: 0
