在对抗 OLLVM(Obfuscator-LLVM)混淆的征途中,理解其混淆原理是制定还原策略的第一步。本文将深入探讨 OLLVM 的三大核心混淆手段:指令替换、虚假控制流、控制流平坦化,并分享实用的还原技巧。
所用附件:测试样本 (ollvm_bcf-fla-sub.zip)
https://oacia.github.io/ollvm-study/ollvm_bcf-fla-sub.zip
二、指令替换 SUB(Substitution)
1. 核心原理
指令替换(Instruction Substitution) 是一种通过数学等价变换来增加代码复杂度的混淆技术。它的核心思想是将程序中原本简单的指令(如加法、异或),替换为一段功能等效但逻辑极其晦涩的指令序列。
本质:MBA 混淆
OLLVM 的指令替换大量采用了 MBA(Mixed Boolean-Arithmetic,混合布尔算术) 表达式。
- 定义:简单来说,MBA 混淆将基础的算术运算(如
x + y)替换为复杂的位运算(And、Or、Xor、Not)与算术运算的组合。
-
示例:
原本一条简单的异或指令:
r = x ^ y;
在经过 OLLVM 混淆后,可能会变成如下形式(基于数学公式 (x + y) - 2 * (x & y) == x ^ y):
r = (x + y) - 2 * (x & y);
甚至更复杂的嵌套多项式:
r = (x | y) - (x & y); // 也是异或的一种表现形式
混淆后果
这种变换在保持数学结果绝对不变的前提下,带来了两个显著的恶果:
- 代码膨胀:一条指令变成数十条甚至上百条指令,导致二进制体积剧增。
- 对抗分析:极大地干扰了 IDA Pro、Ghidra 等反编译器的分析引擎,生成的伪代码(Pseudocode)充斥着大量冗余的位运算逻辑,让人眼花缭乱,难以识别其真实的业务含义。
2. 对抗方法
面对“指令替换”带来的垃圾代码,手动分析显然是不现实的。我们主要依赖自动化工具来进行代数简化。
方法 A:使用 IDA 插件 D-810(推荐首选)
D-810 是一款基于 IDA 的强大反混淆插件,它能在反编译阶段动态地优化指令流。
- 工作原理:D-810 挂载在 IDA 的 Hex-Rays 流程中,利用预定义的模式匹配(Pattern Matching)和启发式规则,自动识别常见的 OLLVM 混淆模式(如上述的
(x|y)-(x&y)),并将其折叠回原始指令(如 x^y)。
- 优势:集成度高,安装配置后,F5 刷新即可看到简化后的代码,无需离开 IDA 环境。
- 局限性:对于某些极其复杂或非标准的 MBA 表达式,D-810 可能无法完全识别。
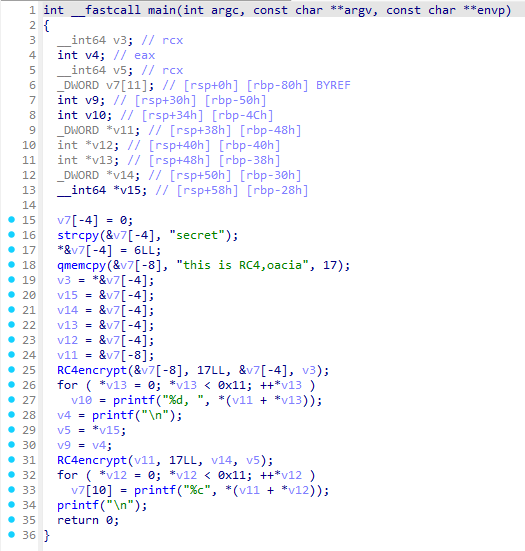
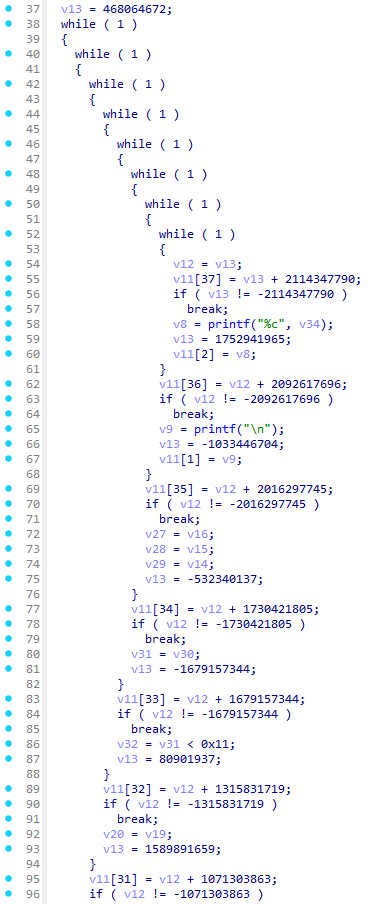
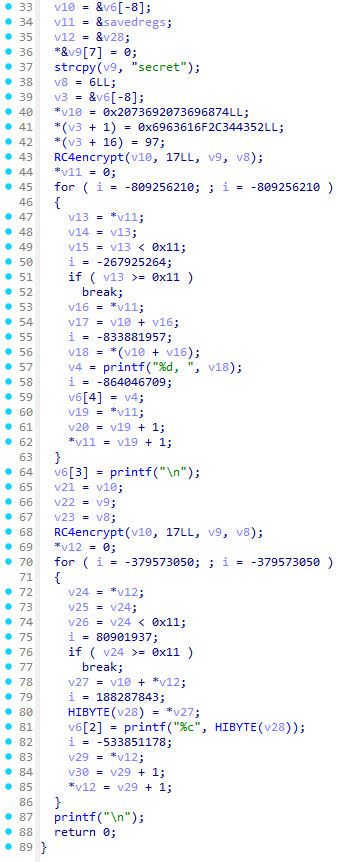
案例:test-sub
以下是一段经过 OLLVM 指令替换混淆后的 RC4 算法代码,可以看到逻辑极其复杂,充斥着大量冗余的位运算:

开启 D-810 后(F5 刷新):

可以看到,虽然 D-810 成功去除了一部分混淆,但核心逻辑(RC4 的异或操作)依然被更深层次的 MBA 表达式掩盖,未能完全还原。
方法 B:使用 GAMBA(深度清理)
当 D-810 无法完全还原,或者你需要处理极高强度的 MBA 表达式时,GAMBA 是你的终极武器。
- 工具定位:GAMBA 是一款基于代数重写和 SMT 求解技术的自动化简化工具。它不依赖于模式匹配,而是通过数学证明的方式进行化简。
- 核心优势:它像剥洋葱一样,能将那些冗长晦涩的位运算公式还原为最原始、最直观的算术形式。特别是在处理 D-810 遗留的“顽固”表达式时,GAMBA 往往能给出令人惊喜的简洁结果。
- 处理技巧:由于 GAMBA 是 Python 脚本,无法直接识别 IDA 中的指针符号
*() 或数组索引 []。在使用前,建议将这些复杂的内存访问表达式重命名为简单的变量名(例如将 v12[v9] 替换为 V12_v9,*(v16 + i) 替换为 V16_i),以避免解析错误。
该工具的详细使用方法请移步:[分享]Ollvm 指令替换混淆还原神器:GAMBA 使用指南
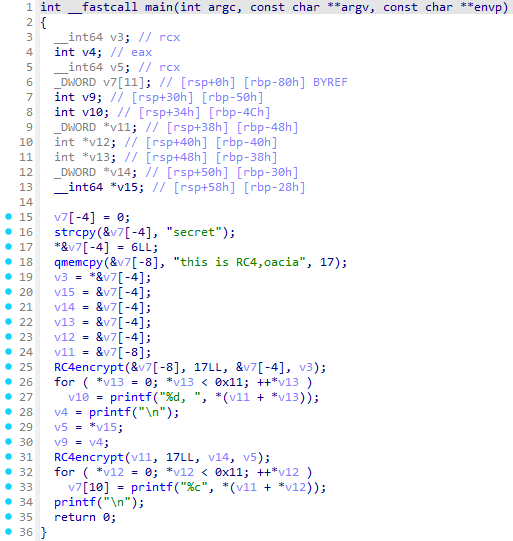
还原 RC4 核心:
我们继续处理 D-810 遗留的那三行“残渣”代码:
原始残渣:
v5 = ~(~v12[v9] | (*(v16 + i) & 0x9A | ~*(v16 + i) & 5) ^ (~*(v16 + i) & 0x60 | 5) ^ 0x60);
v6 = *(v16 + i) & ((v12[v9] & 0x21 | ~v12[v9] & 2 | 0xC8) ^ (~v12[v9] & 0x14 | (v12[v9] & 0xC0 | ~v12[v9] & 8) ^ 8 | 2) ^ 0x23);
*(v16 + i) = v6 & v5 | v5 & 0x23 ^ (v5 & 0x14 | ~v5 & 0xC8) ^ v6 ^ 0xC8;
第一步:变量代换
为了方便 GAMBA 处理,我们进行如下重命名:
v12[v9] → V12_v9*(v16 + i) → V16_i
替换后的表达式:
v5 = ~(~V12_v9 | (V16_i & 0x9A | ~V16_i & 5) ^ (~V16_i & 0x60 | 5) ^ 0x60);
v6 = V16_i & ((V12_v9 & 0x21 | ~V12_v9 & 2 | 0xC8) ^ (~V12_v9 & 0x14 | (V12_v9 & 0xC0 | ~V12_v9 & 8) ^ 8 | 2) ^ 0x23);
V16_i = v6 & v5 | v5 & 0x23 ^ (v5 & 0x14 | ~v5 & 0xC8) ^ v6 ^ 0xC8;
第二步:逐个击破
使用 GAMBA 依次简化这三个表达式:
简化 V16_i 的赋值逻辑:
python simplify.py "v6 & v5 | v5 & 0x23 ^ (v5 & 0x14 | ~v5 & 0xC8) ^ v6 ^ 0xC8" -v 3

输出结果:v5 | v6
简化 v5 的逻辑:
python simplify.py "~(~V12_v9 | (V16_i & 0x9A | ~V16_i & 5) ^ (~V16_i & 0x60 | 5) ^ 0x60)" -v 3

输出结果:~V16_i & V12_v9
简化 v6 的逻辑:
python simplify.py "V16_i & ((V12_v9 & 0x21 | ~V12_v9 & 2 | 0xC8) ^ (~V12_v9 & 0x14 | (V12_v9 & 0xC0 | ~V12_v9 & 8) ^ 8 | 2) ^ 0x23)" -v 3

输出结果:V16_i & ~V12_v9
第三步:终极合并
现在我们将简化后的结果代回原逻辑:
V16_i = v5 | v6v5 = ~V16_i & V12_v9v6 = V16_i & ~V12_v9
合并后的表达式为:
V16_i = (~V16_i & V12_v9) | (V16_i & ~V12_v9)
再次交给 GAMBA 进行最终简化:
python simplify.py "(~V16_i&V12_v9) | (V16_i&~V12_v9)" -v 3

输出结果:V16_i ^ V12_v9
结论:
经过 GAMBA 的层层抽丝剥茧,这段复杂的代码最终还原为:
*(v16 + i) = *(v16 + i) ^ v12[v9];
这正是 RC4 加密算法 中最经典的异或操作!通过 D-810 初步清洗 + GAMBA 深度还原 的组合拳,我们成功击穿了 OLLVM 的指令替换混淆。
三、虚假控制流 BCF(Bogus Control Flow)
1. 核心原理
虚假控制流(Bogus Control Flow) 是 OLLVM 通过向代码中注入永远不会执行的“死代码”块和难以预测的条件跳转,来干扰控制流图(CFG)分析的一种混淆技术。
两个关键概念:
不透明谓词(Opaque Predicate):
这是一个在编译时或运行时其值已知,但对于静态分析工具(如 IDA)而言看似未知的条件表达式。
示例:
if (x * (x + 1) % 2 != 0) { ... }。数学上任意整数 x,其 x(x+1) 必然是偶数,因此条件永远为假。但 IDA 在不进行深度代数分析的情况下,会认为这是一条合法的分支。
不可达块(Unreachable Block):
由永假的不透明谓词保护的代码块。由于条件永远不满足,这些代码在实际运行时永远不会执行,但在静态反编译时会生成大量干扰逻辑,极大地增加了分析工作量。
2. 对抗方法
方法 A:使用 IDA 插件 D-810(推荐)
D-810 内置了强大的不透明谓词匹配器,能够自动识别常见的 OLLVM 谓词模式并将其优化掉,这里不再做演示。
方法 B:修改数据段属性与初值(利用编译器优化)
OLLVM 常使用全局变量(通常未初始化,位于 .bss 段)作为不透明谓词的判断条件。
核心思路:既然 IDA 不知道这些变量的值,我们就人为地给它赋予一个定值,并告诉 IDA 这个值是“只读”的。这样 IDA 的反编译器就会触发常量传播(Constant Propagation) 优化,自动剪除死代码分支。
案例:test-bcf

实战步骤:
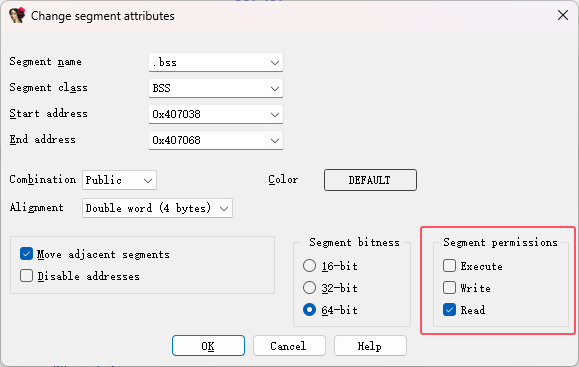
定位变量:在伪代码中找到干扰判断的全局变量(如 x_9, y_10),双击进入 .bss 段。

修改段属性:
按 Alt + S 打开段编辑窗口。
勾选 "Read-only" 或去掉 "Write" 权限,确保 IDA 认为该段不可写。
赋予初值:将这些变量批量赋值(例如全改为 2)。

辅助脚本(IDA Python):
import ida_segment
import ida_bytes
# 获取 .bss 段
seg = ida_segment.get_segm_by_name('.bss')
# 1. 批量赋值:将该段所有变量初始化为 2 (或其他固定值)
# 步长为 4 (int类型)
for ea in range(seg.start_ea, seg.end_ea, 4):
ida_bytes.patch_bytes(ea, int(2).to_bytes(4, 'little'))
# 2. 修改段权限为只读 (Read Only)
# seg.perm 格式: 4=Read, 2=Write, 1=Execute
seg.perm = 0b100 # 只保留读权限 (R--)
ida_segment.update_segm(seg)
print("[+] BSS segment patched: Read-only & Initialized.")
最后一步:
在 .bss 段对相关变量执行 "Convert to data"(快捷键 D),然后回到反编译界面按 F5 刷新。你会发现大量分支因条件确定而被 IDA 自动优化消失了。

简化效果:
方法 C:汇编指令修补(Patch Instruction)
如果你不想修改段属性,或者变量分布比较零散,可以直接修改汇编指令,将对全局变量的读取替换为立即数(常量)。
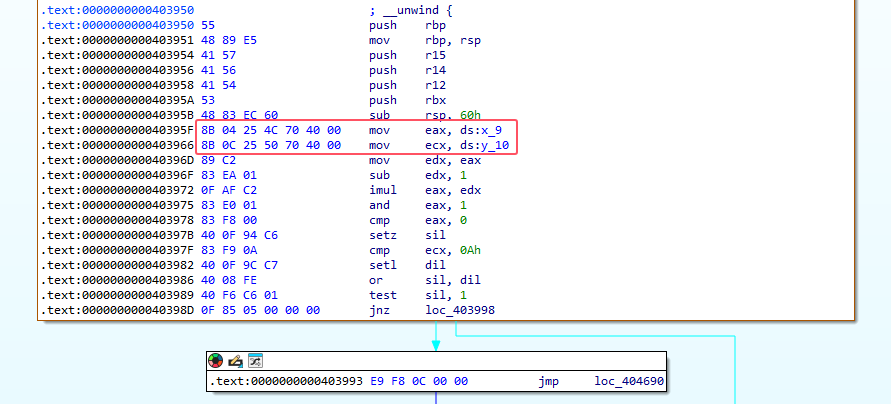
原理:
原指令:mov eax, ds:x_9(从内存读值,值不确定)
修改后:mov eax, 0(直接赋常量)
IDA Python 自动化脚本:
import ida_xref
import ida_idaapi
from ida_bytes import get_bytes, patch_bytes
import ida_segment
def do_patch(ea):
# 检查指令特征:mov reg, [mem] (通常是 8B 开头)
# 注意:这里仅适配了特定的 mov 指令格式,实战需根据具体指令调整
if get_bytes(ea, 1) == b"\x8B":
# 解析目标寄存器
reg = (ord(get_bytes(ea + 1, 1)) & 0b00111000) >> 3
# 构造新指令:mov reg, 0
# 操作码:0xB8 + reg
# 填充 nop 保持指令长度一致
new_code = (0xB8 + reg).to_bytes(1, 'little') + b'\x00\x00\x00\x00\x90\x90'
patch_bytes(ea, new_code)
print(f"[+] Patched at {hex(ea)}: mov reg, 0")
else:
print(f"[-] Skip unknown instruction at {hex(ea)}")
# 遍历 .bss 段中的不透明谓词变量
seg = ida_segment.get_segm_by_name('.bss')
for addr in range(seg.start_ea, seg.end_ea, 4):
# 获取所有引用了该变量的代码位置
ref = ida_xref.get_first_dref_to(addr)
while ref != ida_idaapi.BADADDR:
do_patch(ref)
ref = ida_xref.get_next_dref_to(addr, ref)
print("[+] All opaque predicates patched.")
此方法直接从汇编层面切断了不透明谓词的来源,IDA 在重新分析时会发现这些寄存器都是定值,从而优化掉虚假分支。简化效果和方法 B 一样。
四、控制流平坦化 FLA(Control Flow Flattening)
1. 核心原理
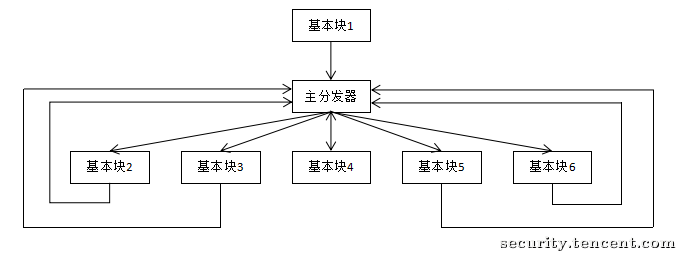
控制流平坦化(Control Flow Flattening,简称 FLA 或 CFF) 是一种旨在摧毁程序结构信息的重度混淆技术。它通过引入一个中央分发器,将原函数中原本层级分明、先后有序的基本块(Basic Blocks)全部“拍扁”,使得它们在控制流图(CFG)上看起来像是在同一个层级上。
图解:CFG 的崩塌
-
原始 CFG:
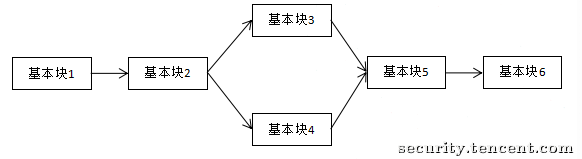
-
混淆后 CFG:
六大核心组件
要理解并还原 FLA,必须识别出以下组件:
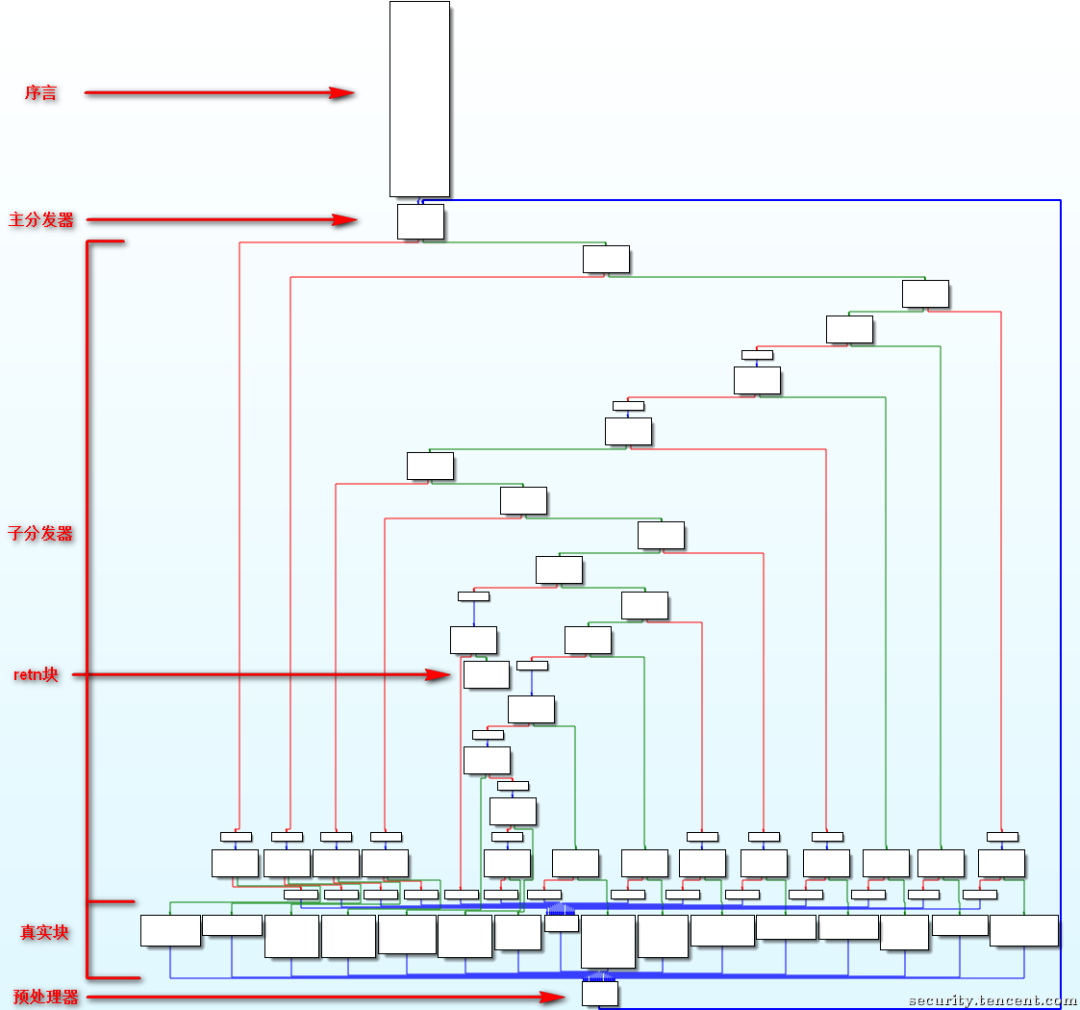
- 序言(Prologue):函数的入口。它的核心任务是初始化状态变量(State Variable),例如
state = START_KEY。
- 主分发器(Main Dispatcher):混淆的心脏。通常是一个巨大的
while(true) 循环,内部包裹着 switch(state)。它不断读取当前状态值,决定下一个要执行哪个块。
- 子分发器(Sub-Dispatcher)(变种):更复杂的 FLA 会嵌套多层 switch,或者使用数学公式计算跳转目标,进一步隐藏状态转移关系。
- 真实块(Relevant Blocks):包含原始业务逻辑的代码块。它们不再直接跳转到下一个真实块,而是被“隔离”成了 switch 的一个个 case。
- 预处理块(Predispatcher) / 状态更新:每个真实块执行完后,不会直接跳转。而是通过更新
state 变量(例如 state = NEXT_KEY),然后无条件跳转回主分发器,由分发器在下一轮循环中根据新状态进行调度。
- 返回块(Return):函数的出口,当状态变量达到特定值时,跳出循环并返回。
执行流程演示
- 初始化:序言设置
state = 1。
- 分发:主分发器检查
state,跳转到 case 1(真实块 A)。
- 执行与更新:真实块 A 执行业务逻辑,并在末尾将
state 更新为 2。
- 回环:跳转回主分发器。
- 再分发:主分发器检查
state(此时为 2),跳转到 case 2(真实块 B)。
- 循环往复... 直到
state 变为结束标志。
2. 对抗方法
面对 FLA 混淆,我们的目标是重建真实块之间的直接跳转关系,即:如果块 A 执行完后 state 变成了 2,而 state=2 对应的是块 B,那么我们就把块 A 的结尾直接修改为 JMP Block_B,从而绕过分发器。
方法 A:使用 IDA 插件 D-810(静态分析首选)
D-810 的强大之处在于它不仅能处理 MBA 混淆和不透明谓词,还内置了针对 FLA 的启发式去混淆规则。
去混淆前:
去混淆后:
可以看到去混淆程度是很大的,十分接近原逻辑。
方法 B:使用 Deflat 脚本(基于 Angr)
Deflat 是经典的基于符号执行的去混淆工具。它利用 Angr 框架模拟执行,能够精准地计算出每个基本块的“下一跳”目标。
项目地址:https://github.com/cq674350529/deflat
使用命令:
# -f: 目标二进制文件
# --addr: 混淆函数的起始地址 (十六进制)
python deflat.py -f test-fla --addr 0x400660
原理:
- 识别组件:自动寻找序言、分发器、真实块和返回块。
- 符号执行:从每个真实块开始,符号执行到分发器,求解出
state 的值以及对应的目标块。
- 二进制修补(Patch):直接修改 ELF/PE 文件,将真实块末尾的跳转指令修改为直连目标块,并 NOP 掉分发器相关指令。
示例:test-fla
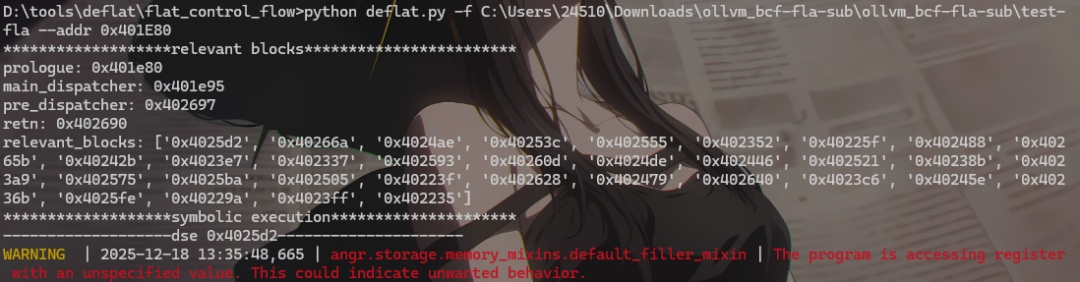

查看去混淆后的文件 test-fla_recovered:
可以看到还原程度还是不错的,部分残留可以手动 NOP 清除一下:
方法 C:使用 Unicorn 框架(动态模拟还原)
通过模拟执行,我们可以记录程序在运行时的真实轨迹(Trace),从而无视复杂的静态混淆逻辑。
核心技术路径:
- 静态提取:利用 IDA 识别并提取所有基本块信息(真实块、虚假块、分发器)。
- 动态模拟:使用 Unicorn 运行程序,记录块与块之间的跳转关系及上下文(ZF 标志位)。
- 静态修复:根据记录的关系,Patch 二进制代码,短路分发器,重建 CFG。
案例:test-fla
我们先查看 IDA 的流程图,可以很明显的看出该程序的序言、分发器、return 块、真实块、预处理器。
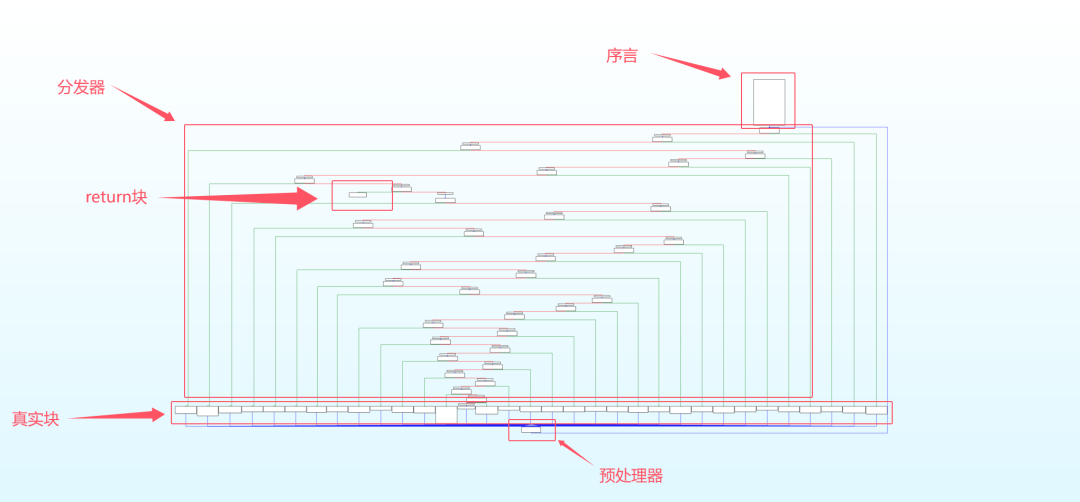
第一步:静态提取(IDA Python)
我们需要先让 IDA 告诉我们哪些是“真实块”,哪些是“分发器/虚假块”。
分析逻辑:
- 序言块:函数的入口。
- 真实块(True Block):预处理器前的块。
- Return 块:无后续块。
- 虚假块(Fake Block):除了上述块以外的其他块。
提取脚本(Extract Blocks):
import idaapi
import idc
# ================= 配置 =================
TARGET_FUNC_EA = 0x401E80 # 目标函数入口
PREPROCESSOR_EA = 0x402697 # 分发器/预处理器地址
# ================= 数据结构 =================
true_blocks = set() # 真实块集合
fake_blocks = set() # 虚假块集合
func = idaapi.get_func(TARGET_FUNC_EA)
flowchart = idaapi.FlowChart(func, flags=idaapi.FC_PREDS)
print(f" Analyzing function at 0x{TARGET_FUNC_EA:x}...")
# ================= CFG 分析 =================
for block in flowchart:
start_ea = block.start_ea
# 获取块的实际结束地址(排除对齐填充)
end_ea = idc.prev_head(block.end_ea)
# 1. 识别分发器 (Dispatcher)
# 分发器本身归类为虚假块
if start_ea == PREPROCESSOR_EA:
fake_blocks.add((start_ea, end_ea))
# 分发器的前驱通常是真实块(因为真实块执行完要跳回来)
for pred in block.preds():
true_blocks.add((pred.start_ea, idc.prev_head(pred.end_ea)))
continue
# 2. 识别返回块 (Return Block)
# 没有后继的块通常是函数出口
succs = list(block.succs())
if not succs:
print(f"[+] Found Return Block: 0x{start_ea:x}")
# 返回块算作真实逻辑的一部分,但不参与循环
continue
# 3. 识别真实块 (True Block)
# 如果当前块的后继是分发器,说明它是参与调度的真实块
if any(succ.start_ea == PREPROCESSOR_EA for succ in succs):
true_blocks.add((start_ea, end_ea))
continue
# 4. 识别序言 (Prologue)
if start_ea == TARGET_FUNC_EA:
print(f"[+] Found Prologue: 0x{start_ea:x}")
print(f"[+] Prologue_end: 0x{end_ea:x}")
continue
# 5. 其他块归类为虚假块 (Fake Block)
# 排除掉已经被标记为真实的块
if (start_ea, end_ea) not in true_blocks:
fake_blocks.add((start_ea, end_ea))
# ================= 输出 =================
print(f"\n[+] True Blocks Count: {len(true_blocks)}")
print("TBS =", sorted(true_blocks))
print(f"\n[+] Fake Blocks Count: {len(fake_blocks)}")
print("FBS =", sorted(fake_blocks))
第二步:动态模拟(Unicorn Trace)
有了块列表,我们使用 Unicorn 模拟执行,记录真实的跳转路径。
具体的 Unicorn 框架学习文章:[原创]深入浅出 Unicorn 框架学习
关键点:不仅要记录跳到了哪里,还要记录跳转时的ZF(Zero Flag) 标志位。因为条件跳转(JZ/JNZ)完全依赖它。
模拟脚本(Unicorn Tracer):
from unicorn import *
from unicorn.x86_const import *
from capstone import *
# ============================================================
# 1. 全局配置(地址布局 & 目标函数)
# ============================================================
BASE_ADDR = 0x400000
CODE_ADDR = BASE_ADDR
CODE_SIZE = 1024 * 1024
STACK_ADDR = 0x0
STACK_SIZE = 1024 * 1024
MAIN_ADDR = 0x401E80
MAIN_END = 0x40269C
# ============================================================
# 2. 基本块信息(IDA 静态分析得到)
# ============================================================
# 从第一步脚本中获取的真实块列表
TBS = [
(4203066, 4203066), (4203071, 4203098), (4203103, 4203157),
(4203162, 4203314), (4203319, 4203341), (4203346, 4203366),
(4203371, 4203398), (4203403, 4203428), (4203433, 4203457),
(4203462, 4203490), (4203495, 4203514), (4203519, 4203558),
(4203563, 4203585), (4203590, 4203609), (4203614, 4203636),
(4203641, 4203651), (4203656, 4203689), (4203694, 4203737),
(4203742, 4203776), (4203781, 4203804), (4203809, 4203831),
(4203836, 4203856), (4203861, 4203888), (4203893, 4203918),
(4203923, 4203957), (4203962, 4203981), (4203986, 4204025),
(4204030, 4204040), (4204045, 4204067), (4204072, 4204091),
(4204096, 4204118), (4204123, 4204133), (4204138, 4204171)]
# 结果记录: [(tb_start, tb_end), zf_value]
tb_trace = []
# ============================================================
# 3. 反汇编 & 模拟器初始化
# ============================================================
cs = Cs(CS_ARCH_X86, CS_MODE_64)
uc = Uc(UC_ARCH_X86, UC_MODE_64)
# ============================================================
# 4. Hook:指令级 Hook(核心)
# ============================================================
def hook_code(uc, address, size, user_data):
# 1. 模拟环境修补
# 读取指令,处理 call 和 ret
try:
code = uc.mem_read(address, size)
except:
return
for insn in cs.disasm(code, address):
# 跳过 Call:FLA 通常只在当前函数内,无需跟进子函数
if insn.mnemonic == "call":
uc.reg_write(UC_X86_REG_RIP, address + size)
return
# 遇到 Ret:函数结束,停止模拟
if insn.mnemonic == "ret":
print(" Function Return hit. Stopping...")
uc.emu_stop()
# 输出最终 Trace 供下一步使用
print("\n" + "="*30)
print("real_flow = [")
for item in tb_trace:
print(f" {item},")
print("]")
print("="*30 + "\n")
return
# 2. 记录执行轨迹
# 检查当前地址是否是某个真实块的“结束地址”
for tb_start, tb_end in TBS:
if address == tb_end:
# 记录此时的 ZF 标志位 (EFLAGS 第 6 位)
eflags = uc.reg_read(UC_X86_REG_EFLAGS)
zf = (eflags >> 6) & 1
tb_trace.append(((tb_start, tb_end), zf))
break
# ============================================================
# 5. Hook:非法内存访问 / 中断(调试用)
# ============================================================
def hook_mem_invalid(uc, access, address, size, value, user_data):
access_type = {
UC_MEM_READ_UNMAPPED: "READ",
UC_MEM_WRITE_UNMAPPED: "WRITE",
UC_MEM_FETCH_UNMAPPED: "FETCH",
}.get(access, "UNKNOWN")
# 打印内存错误信息
print(f"[MEM {access_type}] 0x{address:x}, size={size}")
return False
def hook_intr(uc, intno, user_data):
print(f"[INT] interrupt {intno}")
return False
# ============================================================
# 6. Unicorn 初始化
# ============================================================
def init_unicorn(uc, code_data):
# 映射内存
uc.mem_map(CODE_ADDR, CODE_SIZE, UC_PROT_ALL)
uc.mem_map(STACK_ADDR, STACK_SIZE, UC_PROT_ALL)
# 写入代码
uc.mem_write(CODE_ADDR, code_data)
# 初始化栈
uc.reg_write(UC_X86_REG_RSP, STACK_ADDR + STACK_SIZE // 2)
# 添加 hook 逻辑
uc.hook_add(UC_HOOK_CODE, hook_code)
# 未映射内存访问
uc.hook_add(UC_HOOK_MEM_UNMAPPED, hook_mem_invalid)
# 中断(int 0x80 / syscall / ud2 等)
uc.hook_add(UC_HOOK_INTR, hook_intr)
# ============================================================
# 7. 主流程
# ============================================================
if __name__ == "__main__":
# 读取二进制文件
with open(r"C:\Users\24510\Downloads\ollvm_bcf-fla-sub\ollvm_bcf-fla-sub\test-fla", "rb") as f:
CODE_DATA = f.read()
init_unicorn(uc, CODE_DATA)
print(" Starting Emulation...")
try:
uc.emu_start(MAIN_ADDR, MAIN_END)
except UcError as e:
print(f"[Error] {e}")
第三步:静态修复(IDA Python Patch)
拿到 real_flow(真实执行流)后,我们就可以在 IDA 中重建 CFG 了。
修复策略:
- 单后继块:如果块 A 后面永远只跟块 B,直接修改块 A 结尾为
JMP Block_B。
- 双后继块(条件跳转):如果块 A 后面有时跟 B(ZF=1),有时跟 C(ZF=0),说明它是条件跳转。
- 难题:原始块 A 结尾空间可能不够写
JZ + JMP 指令。
- 巧解:利用无用的虚假块(Fake Blocks) 作为“跳板”。
- 操作:
Block_A -> JMP Fake_Block -> [JZ Target_True; JMP Target_False]。
修复脚本(Patch CFG):
import idaapi
import ida_bytes
import ida_ua
import ida_kernwin
from collections import defaultdict, deque
# ============================================================
# 输入数据区
# ============================================================
# fake_blocks:
# 第一步分析 CFG / dispatcher 后得到的「虚假块列表」
# 每一项格式为 (start_ea, end_ea)
# 这些块在最终逻辑中只作为“跳板”或被 NOP 掉
fake_blocks = [(4202133, 4202159), (4202165, 4202165), (4202170, 4202187), (4202193, 4202193), (4202198, 4202215),
(4202221, 4202221), (4202226, 4202243), (4202249, 4202249), (4202254, 4202271), (4202277, 4202277),
(4202282, 4202299), (4202305, 4202305), (4202310, 4202327), (4202333, 4202333), (4202338, 4202355),
(4202361, 4202361), (4202366, 4202383), (4202389, 4202389), (4202394, 4202411), (4202417, 4202417),
(4202422, 4202439), (4202445, 4202445), (4202450, 4202467), (4202473, 4202473), (4202478, 4202495),
(4202501, 4202501), (4202506, 4202523), (4202529, 4202529), (4202534, 4202551), (4202557, 4202557),
(4202562, 4202579), (4202585, 4202585), (4202590, 4202607), (4202613, 4202613), (4202618, 4202635),
(4202641, 4202641), (4202646, 4202663), (4202669, 4202669), (4202674, 4202691), (4202697, 4202697),
(4202702, 4202719), (4202725, 4202725), (4202730, 4202747), (4202753, 4202753), (4202758, 4202775),
(4202781, 4202781), (4202786, 4202803), (4202809, 4202809), (4202814, 4202831), (4202837, 4202837),
(4202842, 4202859), (4202865, 4202865), (4202870, 4202887), (4202893, 4202893), (4202898, 4202915),
(4202921, 4202921), (4202926, 4202943), (4202949, 4202949), (4202954, 4202971), (4202977, 4202977),
(4202982, 4202999), (4203005, 4203005), (4203010, 4203027), (4203033, 4203033), (4203038, 4203055),
(4203061, 4203061), (4204183, 4204183)]
# real_flow:
# 第二步通过动态 / 符号执行 / 手工跟踪得到的真实执行路径
# 每一项格式为:
# ((block_start, block_end), zf)
# 含义是:
# 执行到该真实块时,ZF 的取值为 zf
real_flow = [
((4203071, 4203098), 0), ((4203103, 4203157), 0), ((4203162, 4203314), 1), ((4203319, 4203341), 1),
((4203346, 4203366), 1), ((4203371, 4203398), 0), ((4203403, 4203428), 0), ((4203433, 4203457), 1),
((4203462, 4203490), 0), ((4203495, 4203514), 1), ((4203519, 4203558), 1), ((4203563, 4203585), 1),
((4203590, 4203609), 0), ((4203614, 4203636), 1), ((4203641, 4203651), 1), ((4203319, 4203341), 1),
((4203346, 4203366), 1), ((4203371, 4203398), 0), ((4203403, 4203428), 0), ((4203433, 4203457), 1),
((4203462, 4203490), 0), ((4203495, 4203514), 1), ((4203519, 4203558), 1), ((4203563, 4203585), 1),
((4203590, 4203609), 0), ((4203614, 4203636), 1), ((4203641, 4203651), 1), ((4203319, 4203341), 1),
((4203346, 4203366), 1), ((4203371, 4203398), 0), ((4203403, 4203428), 0), ((4203433, 4203457), 1),
((4203462, 4203490), 0), ((4203495, 4203514), 1), ((4203519, 4203558), 1), ((4203563, 4203585), 1),
((4203590, 4203609), 0), ((4203614, 4203636), 1), ((4203641, 4203651), 1), ((4203319, 4203341), 1),
((4203346, 4203366), 1), ((4203371, 4203398), 0), ((4203403, 4203428), 0), ((4203433, 4203457), 1),
((4203462, 4203490), 0), ((4203495, 4203514), 1), ((4203519, 4203558), 1), ((4203563, 4203585), 1),
((4203590, 4203609), 0), ((4203614, 4203636), 1), ((4203641, 4203651), 1), ((4203319, 4203341), 1),
((4203346, 4203366), 1), ((4203371, 4203398), 0), ((4203403, 4203428), 0), ((4203433, 4203457), 1),
((4203462, 4203490), 0), ((4203495, 4203514), 1), ((4203519, 4203558), 1), ((4203563, 4203585), 1),
((4203590, 4203609), 0), ((4203614, 4203636), 1), ((4203641, 4203651), 1), ((4203319, 4203341), 1),
((4203346, 4203366), 1), ((4203371, 4203398), 0), ((4203403, 4203428), 0), ((4203433, 4203457), 1),
((4203462, 4203490), 0), ((4203495, 4203514), 1), ((4203519, 4203558), 1), ((4203563, 4203585), 1),
((4203590, 4203609), 0), ((4203614, 4203636), 1), ((4203641, 4203651), 1), ((4203319, 4203341), 1),
((4203346, 4203366), 1), ((4203371, 4203398), 0), ((4203403, 4203428), 0), ((4203433, 4203457), 1),
((4203462, 4203490), 0), ((4203495, 4203514),......)] # (为控制长度,此处省略重复项)
# 函数序言块的起止地址
# 用于修复 main 入口,直接跳转到第一个真实块
PROLOGUE_STAR = 0x401E80
PROLOGUE_END = 0x401E8B
# 最终 return 块(例如 epilogue / leave; ret 所在块)
RETURN_BLOCK = 0x402690
# ============================================================
# 逻辑处理区
# ============================================================
# ------------------------------------------------------------
# 1. 构建真实控制流映射
# ------------------------------------------------------------
# block_next_map:
# 结构为:
# block_next_map[block][zf] = {next_block1, next_block2, ...}
#
# 表示:
# 当执行到 block 且 ZF == zf 时
# 下一跳可能进入哪些真实块
block_next_map = defaultdict(lambda: defaultdict(set))
# block_zf_map:
# block_zf_map[block] = {0, 1}
#
# 表示:
# 该真实块在执行过程中,ZF 出现过哪些取值
block_zf_map = defaultdict(set)
# 根据 real_flow 构建上述两个映射
for i in range(len(real_flow) - 1):
cur_block, zf = real_flow[i] # 当前真实块及其 ZF
next_block, _ = real_flow[i + 1] # 下一个真实块(ZF 无关)
block_zf_map[cur_block].add(zf)
block_next_map[cur_block][zf].add(next_block)
# ------------------------------------------------------------
# 2. 准备虚假块资源池
# ------------------------------------------------------------
# 使用 deque:
# - 顺序分配 fake block
# - 避免重复使用
fake_queue = deque(fake_blocks)
# 记录哪些 fake block 被用作跳板
used_fake = set()
def alloc_fake_block(min_size=10):
"""
从 fake_blocks 中分配一个可用的虚假块
要求:
- 尚未使用
- 空间足够大(至少能容纳 jz + jmp,约 11 字节)
返回:
(start_ea, end_ea)
"""
while fake_queue:
fb = fake_queue.popleft()
if (fb[1] - fb[0]) >= min_size:
used_fake.add(fb)
return fb
raise Exception("No more fake blocks available!")
# ------------------------------------------------------------
# 通用工具函数
# ------------------------------------------------------------
def nop_range(start, end):
"""将 [start, end] 区间全部填充为 NOP"""
ea = start
while ea <= end:
ida_bytes.patch_byte(ea, 0x90)
ea += 1
def get_last_insn_ea(block_start, block_end):
"""在一个 block 内,反向查找最后一条“有效指令”"""
ea = ida_bytes.prev_head(block_end + 1, block_start)
while ea != idaapi.BADADDR and ea >= block_start:
if ida_bytes.is_code(ida_bytes.get_full_flags(ea)):
return ea
ea = ida_bytes.prev_head(ea, block_start)
return idaapi.BADADDR
def patch_jmp(frm, to):
"""在 frm 地址处,强制 patch 成:jmp to"""
ida_bytes.del_items(frm, ida_bytes.DELIT_SIMPLE)
ida_ua.create_insn(frm)
ida_bytes.patch_byte(frm, 0xE9)
rel = to - (frm + 5)
ida_bytes.patch_dword(frm + 1, rel)
def emit_jz_jmp(ea, true_target, false_target):
"""在 fake block 中构造如下逻辑:
jz true_target
jmp false_target
"""
# jz true_target
ida_bytes.del_items(ea, ida_bytes.DELIT_SIMPLE)
ida_ua.create_insn(ea)
ida_bytes.patch_byte(ea, 0x0F)
ida_bytes.patch_byte(ea + 1, 0x84)
rel = true_target - (ea + 6)
ida_bytes.patch_dword(ea + 2, rel)
ea += 6
# jmp false_target
ida_bytes.del_items(ea, ida_bytes.DELIT_SIMPLE)
ida_ua.create_insn(ea)
ida_bytes.patch_byte(ea, 0xE9)
rel = false_target - (ea + 5)
ida_bytes.patch_dword(ea + 1, rel)
ea += 5
return ea
print(" Starting Patching...")
# ------------------------------------------------------------
# 3. 修复函数序言块
# ------------------------------------------------------------
# main 的序言块不应再进入 dispatcher
# 直接跳转到第一个真实块
first_real_block = real_flow[0][0][0]
patch_jmp(
get_last_insn_ea(PROLOGUE_STAR, PROLOGUE_END),
first_real_block
)
# ------------------------------------------------------------
# 4. 修复所有真实块
# ------------------------------------------------------------
for block, zf_set in block_zf_map.items():
start, end = block
last_insn = get_last_insn_ea(start, end)
branches = block_next_map[block]
# --------------------------------------------------------
# 情况 A:该真实块只出现过一种 ZF
# → 实际是“退化条件”或“直跳块”
# --------------------------------------------------------
if len(zf_set) == 1:
zf = list(zf_set)[0]
target = list(branches[zf])[0][0]
patch_jmp(last_insn, target)
# --------------------------------------------------------
# 情况 B:该真实块同时出现 ZF=0 / ZF=1
# → 真正的条件分支
# --------------------------------------------------------
else:
# 分配一个 fake block 作为条件跳板
fb_start, fb_end = alloc_fake_block()
# 原真实块无条件跳到 fake block
patch_jmp(last_insn, fb_start)
# 确定 ZF=1 / ZF=0 的真实目标
true_target = list(branches[1])[0][0]
false_target = list(branches[0])[0][0]
# 清空 fake block
nop_range(fb_start, fb_end)
# 写入:
# if (ZF) goto true_target
# else goto false_target
emit_jz_jmp(fb_start, true_target, false_target)
# ------------------------------------------------------------
# 5. 修复最后一个真实块 → return block
# ------------------------------------------------------------
last_true_block_start = real_flow[-1][0][0]
last_true_block_end = real_flow[-1][0][1]
patch_jmp(
get_last_insn_ea(last_true_block_start, last_true_block_end),
RETURN_BLOCK
)
# ------------------------------------------------------------
# 6. 清理所有未使用的 fake blocks
# ------------------------------------------------------------
# 防止残留 FLA 垃圾逻辑
for fb in fake_blocks:
if fb not in used_fake:
nop_range(fb[0], fb[1])
print("[+] Patching Done! Press F5 to decompile.")
效果验证:
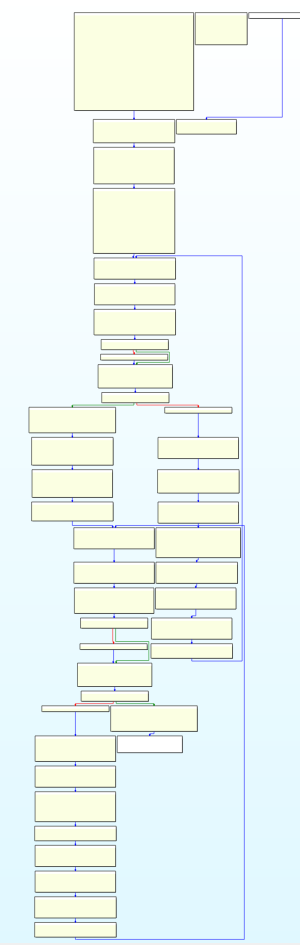
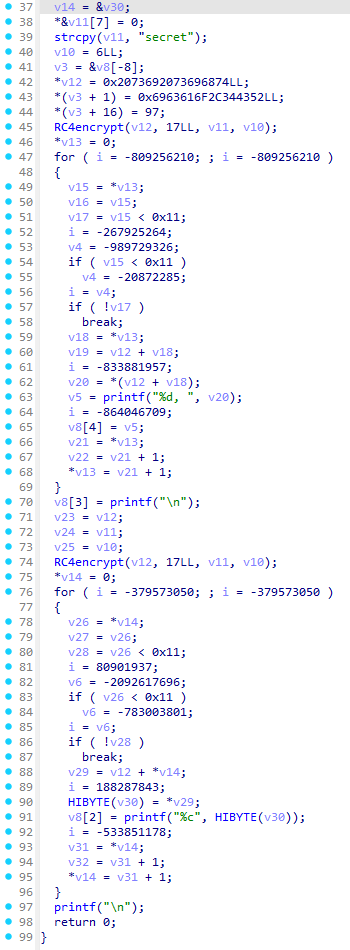
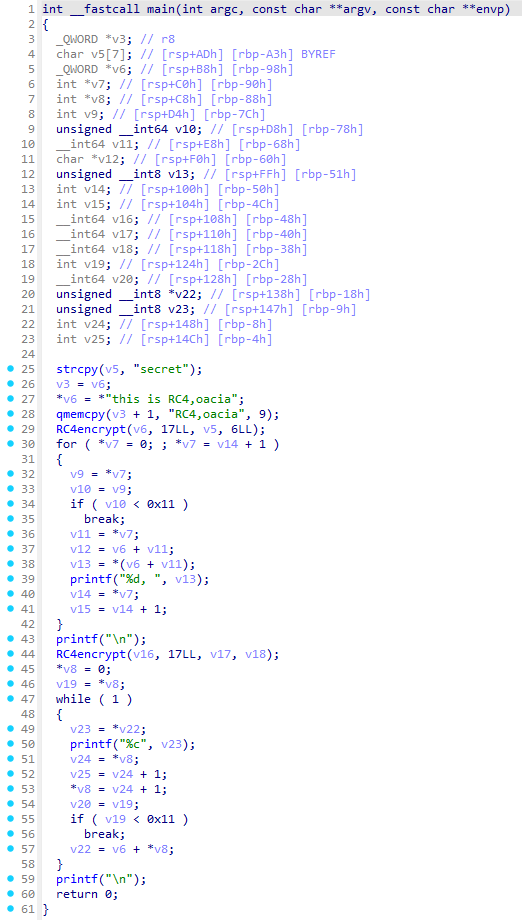
可以看到到了这一步已经很接近原程序的逻辑了,接下来我们可以手动进行一些修复,例如:去掉残留的控制代码流程变量 i 等。
以下修复后的代码:
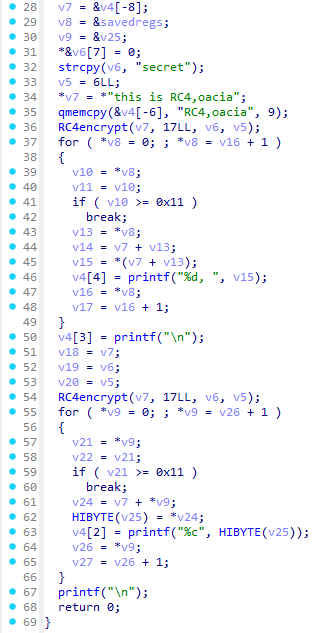
 发表于 2026-1-22 22:31:31
|
查看: 202|
回复: 0
发表于 2026-1-22 22:31:31
|
查看: 202|
回复: 0
