就在最近,技术圈发生了一件颇有意思的事:有人通过逆向工程,揭开了 Apple M4 芯片中 Apple Neural Engine(简称 ANE)的秘密。Ronald Mannak 甚至在社交平台上调侃道:“赶紧读,万一被 Apple 下架了呢。”
这不仅仅是一项技术破解,更像是对 Apple 封闭生态策略的一次直接挑战。为什么这么说?因为 Apple 官方从未公开过 ANE 的工作细节。它没有文档,没有公开的指令集架构(ISA),开发者甚至没有一个直接的编程接口——所有操作都必须经过 CoreML 这一层抽象的“中介”。
其结果就是,硬件本应提供的强劲加速性能,在软件层面被无情地稀释了。
Apple 不愿示人的技术“黑盒”
整个探索源于一个朴素的问题:“我们能在 Apple Neural Engine 上直接训练模型吗?”
按照 Apple 官方的定义,这个问题本身可能就不成立。ANE 是专为模型推理(Inference)而设计的硬件,而非训练。更关键的是,Apple 把这部分技术封锁得严严实实:你想直接编程?没门。你想了解底层架构?更是痴心妄想。
但一位名为 maderix 的研究者(以及他的得力助手 Claude Opus 4.6)并不服气。他们花了数天时间,从 CoreML 的公共 API 一路深挖,穿透 Espresso/E5RT 等私有层,最终触及底层的 IOKit 内核驱动,几乎将整个软件栈翻了个底朝天。
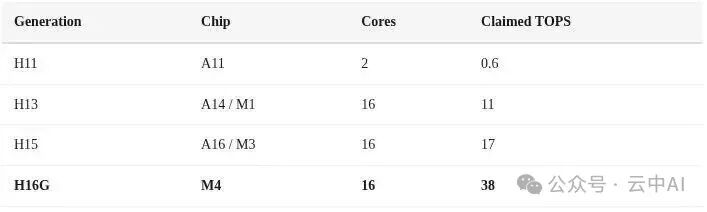
M4 芯片中的 ANE(代号 H16G)拥有 16 个核心和高达 127 的队列深度,并具备独立的电源管理域。
平心而论,ANE 的硬件设计相当激进。它并非传统的 CPU 或 GPU,而是一个图执行引擎。开发者无需一条条发送指令,只需将整个计算图(例如一个神经网络)提交给它,硬件便会像执行一条原子指令一样,高效地完成整个图的计算。
当然,这一切的前提是:你得有办法直接跟它“对话”。
性能缩水高达4倍:CoreML 的“隐性开销”
这是整个逆向工程中最令人意外的发现之一。
我们通常认为 CoreML 是高效利用 ANE 的“高速公路”。但这次挖掘揭示了一个残酷的现实:对于细粒度的操作而言,CoreML 引入的开销巨大,性能损失可达 2 到 4 倍。
这是什么概念?假设你的模型推理在底层硬件上原本只需 1 毫秒,但经过 CoreML 的一系列抽象层、优化通道和中间处理,最终耗时可能被拉长到 3 至 4 毫秒。
这也解释了为什么业界如此期待传闻中 WWDC 上可能发布的 CoreAI 更新。 现有的软件栈,很大程度上限制了下层硬件的真实潜能。
maderix 团队没有使用 CoreML,而是直接找到了 _ANEClient 这个私有框架作为入口。
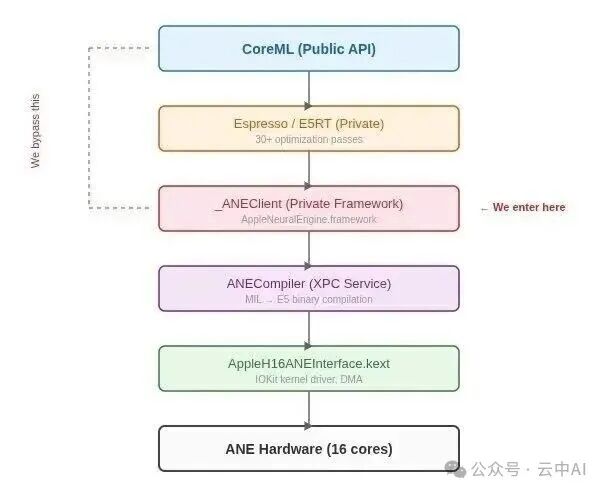
CoreML 只是冰山一角,真正的直通路径在更底层的 AppleNeuralEngine.framework。图中标明了绕过 CoreML 直接进入的入口点。
他们甚至破解了 ANE 的编译流程。CoreML 传递给 ANE 的并非常见的 ONNX 格式,而是一种称为 MIL 的中间语言,最终会被编译成 E5 二进制文件。
一个有趣的细节是:一个 1024×1024 的矩阵乘法,编译出的 E5 文件大小仅为 2688 字节;而一个 128×128 的矩阵乘法,文件大小也仅为 2680 字节。
这说明了什么? ANE 并非在传统意义上“执行代码”,它更像是在根据一份“硬件配置图”来工作。E5 文件本质上是一份“接线图”,告诉硬件内部的固定计算单元如何连接以实现特定的计算图。
38 TOPS 算力的“水分”与工程师的“手滑”
Apple 官方宣称 M4 芯片的 ANE 算力高达 38 TOPS。
但这个数字需要理性看待。maderix 的测试表明,想要逼近这个峰值性能,必须绕过 CoreML 直接操作。此外,测试还发现 卷积运算的速度比矩阵乘法快约 3 倍。如果采用了错误的调用方式,性能会大打折扣。
逆向过程中还有一个让人会心一笑的发现。在 Apple 的内部代码中,他们看到了一个包含拼写错误的类名:Desctiptor(正确应为 Descriptor)。
看来,即便是 Apple 的工程师,在编写私有 API 时也难免会手滑。
通过 IOKit 探测,他们还确认 ANE 拥有独立的 DVFS(动态电压与频率调节)系统。这意味着它能根据实时负载自行调节频率和电压,与 CPU、GPU 的电源管理完全隔离。在空闲状态下,其功耗可以真正降至 0 毫瓦。
不得不说,这块硬件的设计非常精妙。但软件层的过度封闭,无疑锁死了它大半的潜力。
在推理芯片上强行实现“模型训练”
这是整件事最富挑战性的部分。
ANE 从设计初衷上就是一个推理引擎,用于“运行”已训练好的模型,而非“训练”新模型。但当 maderix 团队绕过了 CoreML,获得了底层控制权后,他们决定挑战一下 Apple 划定的禁区。
他们尝试让 ANE 执行神经网络训练中的关键步骤:反向传播。
为了实现这一点,他们必须解决一个棘手的问题:编译速度。传统的编译流程需要将文件写入磁盘,而训练过程的每一步都可能涉及权重更新,频繁的磁盘 I/O 是无法接受的。
他们找到了内存编译的接口 _ANEInMemoryModelDescriptor,试图直接在内存中完成模型的编译与更新。过程当然充满了坎坷(例如发现参数必须是 NSData 类型而非 NSString,又或者发现所谓的“内存编译”依然需要在临时目录写入文件),但最终,他们成功了。
在一个专为推理设计的芯片上,他们强行跑通了神经网络训练流程。 这无疑是对硬件设计边界的一次大胆探索。
“围墙花园”被凿开了一个洞

文章最后,maderix 选择了将相关代码开源。此举的意义远超技术极客的炫技。它尖锐地揭示了一个普遍存在的矛盾:硬件能力飞速进步,但软件抽象层却可能越来越厚重,成为性能瓶颈。
ANE 的硬件能效本应非常出色,但 CoreML 的存在,使得广大开发者难以触及这份本属于硬件的性能。2-4 倍的开销,对于移动端和边缘计算等对延迟极其敏感的场景而言,影响可能是决定性的。
现在,这堵封闭的墙被凿开了一个洞。当然,这可能会引起 Apple 的注意。像 _ANEClient 这类私有 API,随时可能在未来的 macOS 版本中被修改或封禁。
但有一点是确定的:如果你想知道硬件能力的真实上限,永远不能完全依赖官方提供的、带有“中间商”的抽象层。 有时,深入的逆向工程和底层探索是揭示真相的唯一途径。

至于被逆向解析出的 E5 二进制格式细节,以及那个神秘的 127 队列深度究竟能带来多高的并发性能?那将是第二部分和第三部分的故事了。
这件事,远未结束。对于致力于人工智能硬件加速和边缘计算的开发者而言,此类探索提供了宝贵的洞见,也引发了关于硬件开放性与软件效率的更深层思考。你可以在技术社区如云栈社区的智能 & 数据 & 云板块找到更多相关的深度讨论。
参考链接:
https://x.com/ronaldmannak/status/2028560995875168292
 发表于 2026-3-5 15:12:32
|
查看: 117|
回复: 0
发表于 2026-3-5 15:12:32
|
查看: 117|
回复: 0
