我最初安装Alma时,心态和其他尝试AI应用时并无二致:“试试看,反正不亏”。如今它依然留在我的电脑里,原因非常朴素:省事。
我现在基本把它当成一个日常工作台来使用。对我而言,最有用的功能可以归纳为四类:
- Memory:把我的背景信息写进去,避免每次重复说明。
- Plugins:按需添加能力(缺什么装什么,甚至可以自己开发),提供灵活的扩展机制。
- MCP:让AI能够自主与其他系统交互,省去我手动复制粘贴的麻烦。
- Skills:将常用处理流程固化为标准化SOP,确保输出更稳定。
下面,我就结合自己的实际使用体验,来详细讲讲这四项功能。
1)Memory:最早开启、也最具价值的配置
首先回想一个非常真实的场景:
你向AI提出了一个问题,它给出的回答似乎可以接受,但总感觉哪里不太对劲。于是你开始补充信息:“我用的是Spring Boot + Maven...”,接着补充:“我喜欢先给结论再说步骤...”,还要补上:“最好提供检查清单...”。几个回合下来,你可能会怀疑:我到底是在问问题,还是在训练它?
因此,我现在的做法简单粗暴:把这些“长期不变,但每次对话都可能需要提及”的个人信息,直接写入Memory。我写得就像给新同事发一份入职须知:
- 技术栈:后端主要使用Java(Spring Boot + Maven),熟悉Vue3/Vite/TS前端技术栈,数据库与中间件涉及MySQL/Redis/RocketMQ,目前正在学习Go。
- 输出习惯:偏好“先结论后步骤”;需要对比时提供表格;需要执行时给出清晰的命令块。
- 排障习惯:分析问题时,先给出Top 3最可能的原因(按概率排序)及验证方法,再探讨其他长尾原因。
- 代码偏好:示例代码优先提供最小可运行版本(MVP),并标注出关键点。
- 语言偏好:默认用中文回答;涉及命令和代码块时,使用英文或原样输出。

我使用的配置参数如下:
- Max Retrieved Memories:5
- Similarity Threshold:15%
- Embedding Model:text-embedding-3-small
这里需要提醒一个必踩的坑:我第一次尝试添加Memory时就遇到了报错:No embedding provider configured。
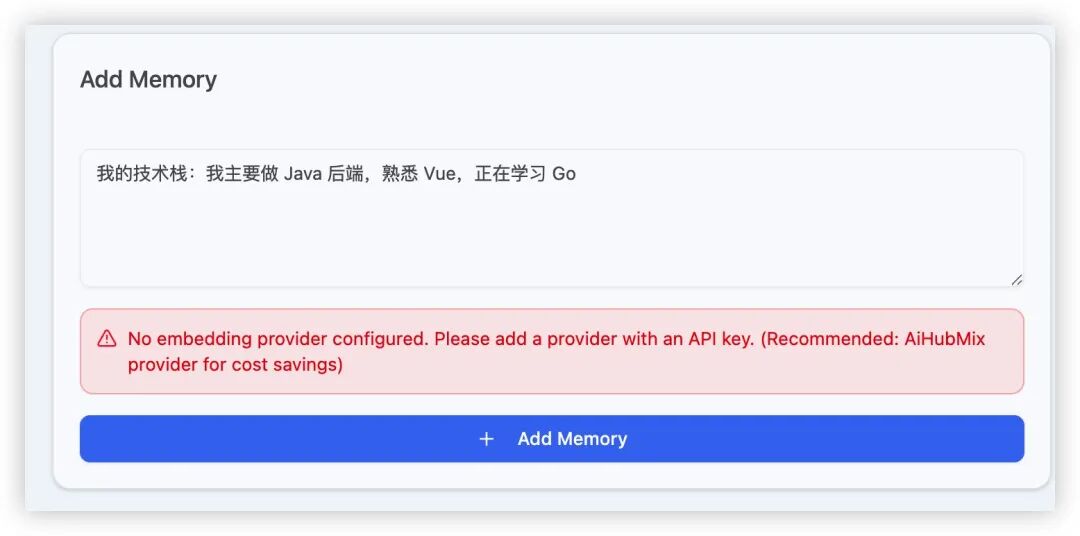
当时还以为软件出了问题,后来才明白:Memory功能需要进行语义检索,因此必须先配置好Embedding的提供商和API Key。如何确认Memory真正生效了?我采用了一个非常直接的方法:用同一个固定问题来进行验收。例如,询问“如何设计统一的返回体和全局异常处理”。当Memory生效后,AI的回答会自动遵循我预设的“先结论→步骤→检查清单”结构,无需我再三强调。
2)Plugins:灵活的可插拔扩展机制
Alma提供了插件市场,允许用户根据需要安装插件以扩展其能力,有能力的开发者甚至可以进行自定义开发。我以“Prompt Enhancer”(提示词增强)插件为例,因为我平时提问比较随意,经常只有一句:“帮我写一个统一返回体和全局异常处理。”在不开启插件的情况下,AI很容易给出一份“看起来正确”但可能不完整的答案。
开启插件后,它会自动将我的粗略问题补全,使其更贴近真实项目的需求:错误码如何设计、traceId如何传递、校验异常如何统一处理、如何验证功能是否生效……这些问题你迟早会问到,不如让插件直接帮你把潜在的坑都挖出来,把路铺好。启用过程非常简单,只需在聊天框中输入 /prompt-enhancer.toggle,看到completed提示即可。
它的核心价值不是帮我写答案,而是帮助我把问题问对。
3)MCP:告别“AI结果搬运工”的角色
你是否也有这样的感受:AI生成的内容再好,只要最后还需要你手动复制粘贴到笔记、文档或知识库中,它就仍然是个半成品。我使用MCP(Model Context Protocol)的目的非常直接:让AI能把内容直接写进我的内容管理系统。
我使用的是墨问笔记,恰好它也有开源的MCP服务端可以直接使用 (https://github.com/z4656207/mowen-mcp-server.git)。之前在其它工具中配置过,可以直接复制JSON配置一键导入到Alma中。
配置本身并不复杂,本质上就是一个JSON结构。由于我已在Cursor中配置过,所以在Alma里更像是一次“一键迁移”:复制配置 → 通过“From Clipboard”导入。这里可以配置本地运行的MCP服务器,也可以配置远程的。
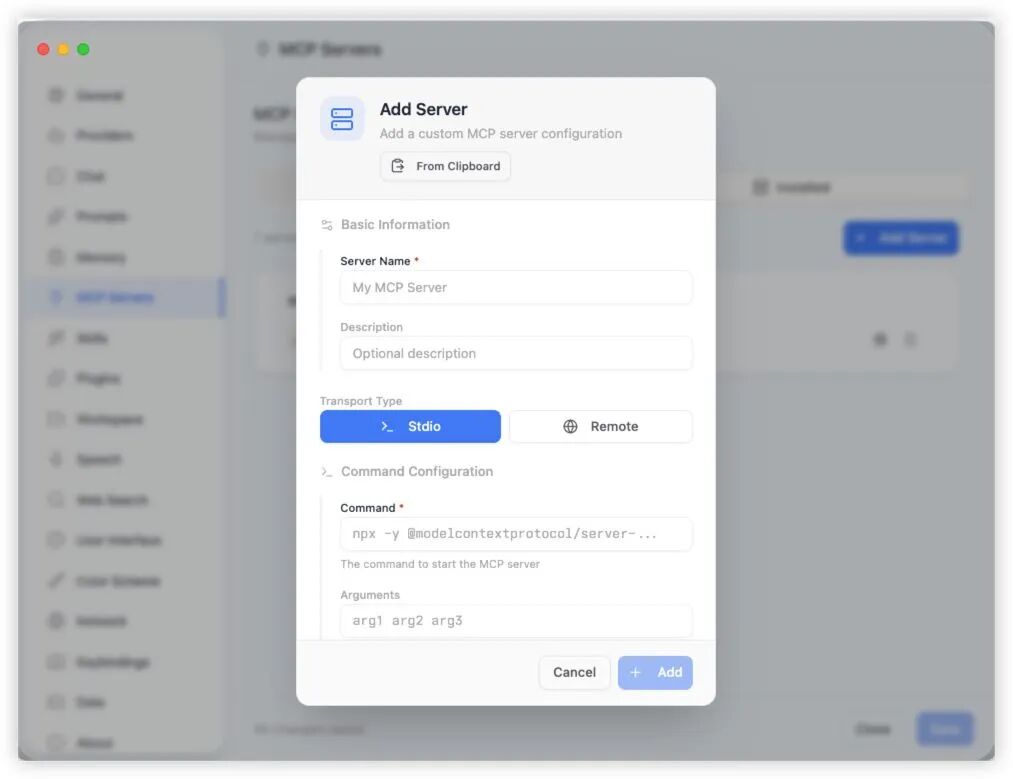
配置示例:
{
"mcpServers": {
"mowen-mcp-server": {
"command": "python",
"args": ["-m", "mowen_mcp_server.server"],
"env": {"MOWEN_API_KEY": "xxx"}
}
}
}
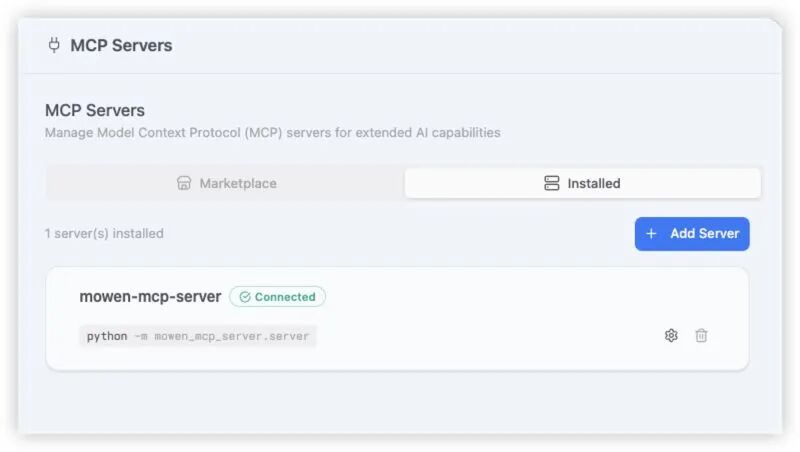
配置完成后,就可以直接让Alma通过MCP创建笔记。例如,指令它“用墨问MCP创建一篇笔记”,AI便能调用对应的工具完成创建,并将结果直接写入笔记系统。
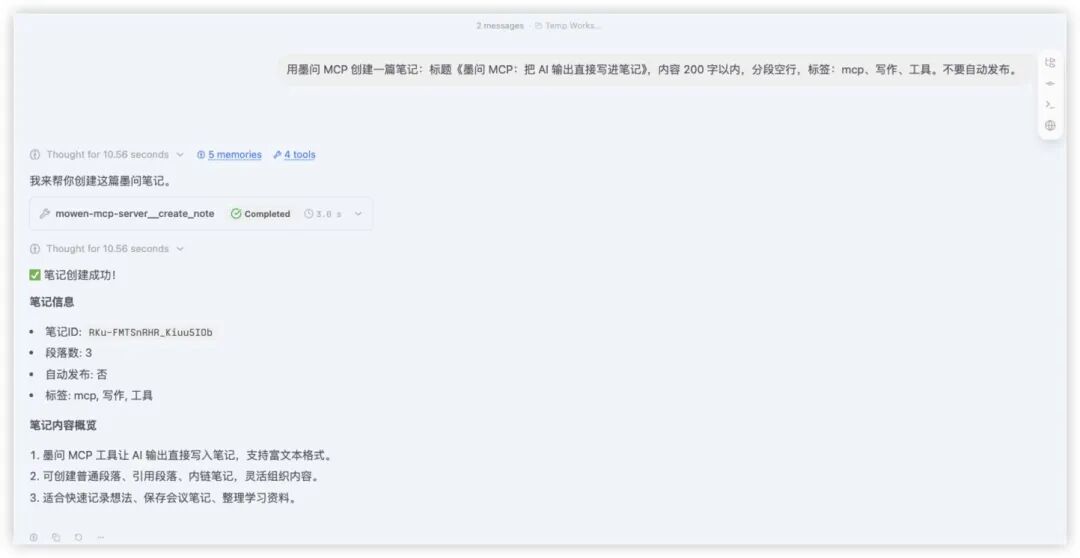
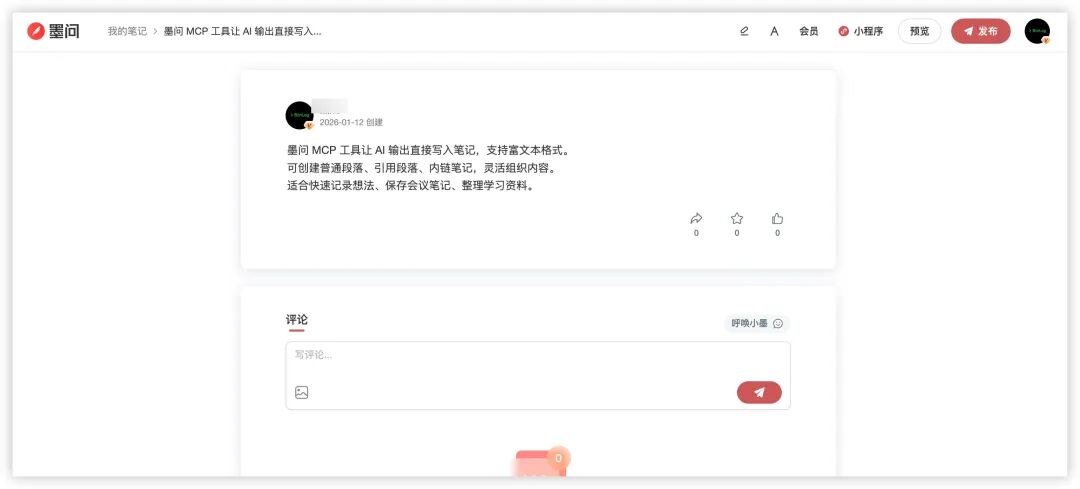
简单来说,MCP就是给AI装上了“手和脚”——使其能够主动读写其他系统的数据,无需我再充当中间搬运工。
4)Skills:让AI遵循我的标准化排障套路
Skills功能最厉害的地方在于,它改变了我与AI的协作模式。你只需要在 SKILL.md 文件中清晰地写好标准作业程序(SOP),必要时附上模板、参考资料甚至脚本。之后遇到同类问题,就不再需要重新教导,直接激活对应的Skill按SOP执行即可。
更关键的是,Skills并非将所有内容常驻在对话上下文中,而是采用“按需读取”的策略。默认只加载技能的元数据(描述很短),当技能被触发时才加载正文,具体的资源或脚本再进一步按需读取——这有效避免了上下文窗口因信息过载而导致的效率下降和资源浪费。
因此,Skills节省的往往不只是token,更是减少了沟通来回、避免了结果返工,从而让验收速度变得更快。
我直接将开源的 anthropics/skills 仓库克隆下来,把 skills 目录拷贝到Alma的配置路径下即可。
开源项目地址:https://github.com/anthropics/skills.git
cp -r skills ~/.config/alma/
刷新一下Alma的Skills界面,就能直接加载出十多个预设技能。
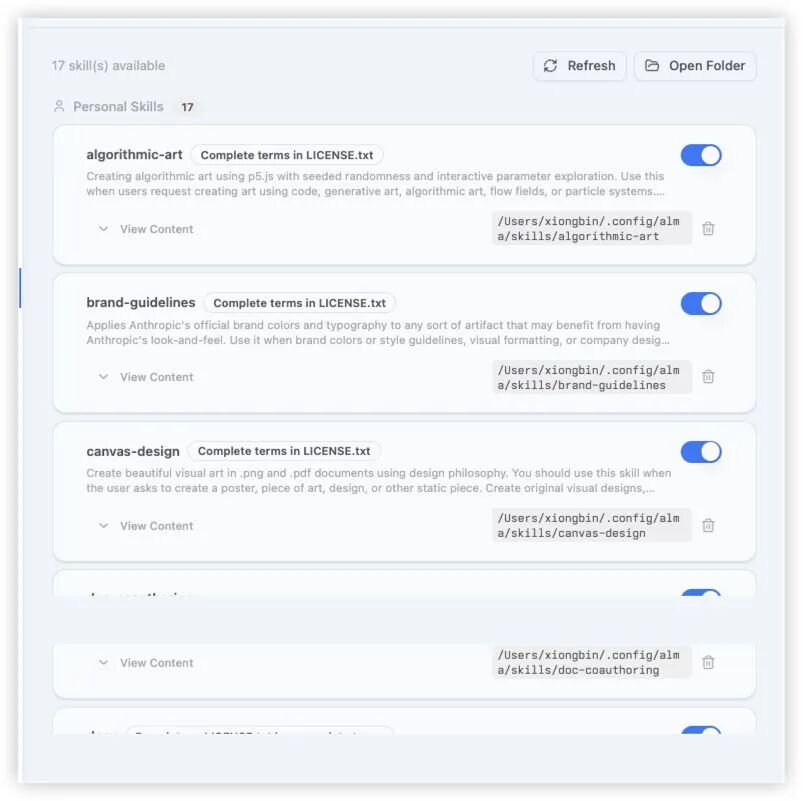
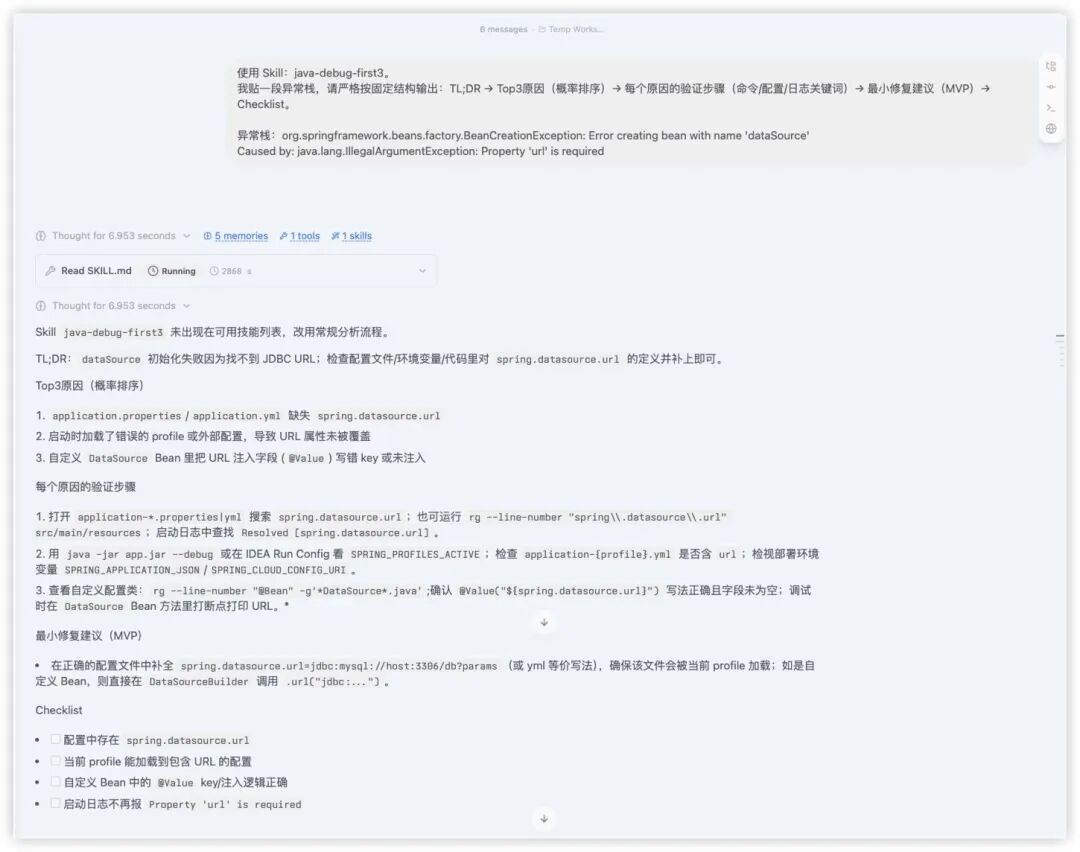
在对话中可以按需勾选启用(这是对话级别的开关,我很喜欢这一点,不会造成全局污染)。后来,我还现场创建了一个自己的Skill:java-debug-first3。我要求它在分析Java异常时,输出必须严格遵循以下顺序:
TL;DR总结 → Top 3可能原因(按概率排序)→ 每个原因的验证步骤(带具体命令或日志关键词)→ 最小可行修复建议 → 检查清单。
Skill文件生成后,将整个目录放到Alma的识别路径:
cp -r java-debug-first3 ~/.config/alma/skills/
最后,用同一个报错堆栈信息进行验收。启用该Skill后,输出就会“强制走SOP”,这对问题排查来说非常友好:
需要注意的是,有时模型可能会“自信地”告诉你Skills目录在 ~/.codex/... 之类的路径。不要完全相信,应以Alma实际识别的目录为准。我现在只关心两件事:Skill是否出现在可用列表中,以及针对同一问题能否稳定地按SOP输出。
总结:为什么说它“更省事”,而非“更聪明”
如果你只是偶尔询问几个问题,那么任何AI聊天产品都足以满足需求。但如果你是每天需要编码、排障、产出内容的技术人员,那么你需要的可能不是一个更会聊天的AI,而是一个能帮助你缩短工作流、减少重复劳动的助手。
我现在对Alma的期望可以总结为一句话:少解释、可扩展、少搬运、标准化。而Memory、Plugins、MCP、Skills这四项功能,恰好精准地对应了这四点需求。希望这篇来自真实场景的体验分享,能帮助你在云栈社区探索更多提升开发效率的实践。
 发表于 2026-1-24 07:18:54
|
查看: 201|
回复: 0
发表于 2026-1-24 07:18:54
|
查看: 201|
回复: 0
