随着AI智能体工作流将上下文窗口推向百万token级别、模型规模逼近万亿参数,AI原生组织正面临日益严峻的规模化挑战。当前系统依赖智能体长期记忆来维护跨轮次、跨工具、跨会话的上下文,让智能体能够基于先前推理持续推进任务,而非每次请求都从零开始。
随着上下文窗口扩大,键值(KV)缓存的容量需求呈线性增长,而重新计算历史信息的算力需求增速则快得多,这使得KV缓存复用与高效存储成为保障性能与能效的核心。
这一趋势给现有内存层级带来巨大压力,AI厂商被迫在稀缺的GPU高带宽内存(HBM)与通用存储层级之间做出选择——后者专为数据持久性、管理与保护设计,而非服务于瞬时性、AI原生的KV缓存。这不仅推高了功耗、抬升了单token成本,还让昂贵的GPU资源处于低利用率状态。
NVIDIA Rubin平台助力AI原生组织实现推理基础设施规模化,满足智能体时代的需求。Rubin平台将AI基础设施组织为计算Pod——由多机架GPU、NVIDIA Spectrum‑X以太网网络与存储构成的单元,是AI工厂的核心横向扩展积木。
在每个Pod内部,NVIDIA推理上下文内存存储(ICMS)平台提供了一类全新的AI原生存储基础设施,专为千兆级推理场景设计。NVIDIA Spectrum‑X以太网提供可预测、低延迟、高带宽的 RDMA 连接,确保大规模共享 KV 缓存的访问具备一致性与低抖动特性。
依托NVIDIA BlueField‑4数据处理器,Rubin平台构建优化的上下文内存层级,通过存储延迟敏感、可复用的推理上下文并进行预加载,弥补现有网络对象存储与文件存储的不足,提升GPU利用率。Rubin平台可提供额外的上下文存储能力,实现每秒token生成量(TPS)提升5倍,且能效比传统存储方案高5倍。
本文将阐述不断增长的AI智能体工作负载与长上下文推理如何给现有内存与存储层级带来持续压力,并介绍NVIDIA推理上下文内存存储(ICMS)平台 —— 作为Rubin AI工厂中的全新上下文层级,它能实现更高吞吐量、更优能效与可扩展的 KV 缓存复用。
一、全新推理范式与上下文存储挑战
随着基础模型从简单聊天机器人进化为复杂的多轮次智能体工作流,组织面临全新的规模化挑战。当基础模型参数达万亿级、上下文窗口覆盖百万token,三大AI规模化定律(预训练、后训练与测试时规模化)正推动算力密集型推理需求激增。智能体不再是无状态的聊天机器人,而是依赖对话、工具调用与中间结果的长期记忆,这些记忆需在服务间共享并被反复调用。
在基于Transformer的模型中,这种长期记忆以推理上下文(即KV缓存)的形式实现。它会保存推理阶段的上下文信息,避免模型为每个新token重新计算全部历史数据。随着序列长度增加,KV缓存呈线性增长,需在更长会话中持久化,并在多个推理服务间高效共享。
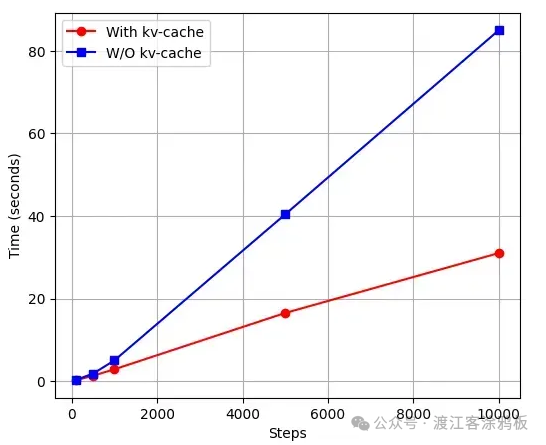
标准模型与KV缓存模型在不同生成步数下的推理时间对比
这一演进让KV缓存成为一类独特的AI原生数据,具备性能关键且瞬时性的双重特性:在智能体系统中,KV缓存实际成为模型的长期记忆,在多步骤中被复用与扩展,而非单次提示响应后就被丢弃。
推理上下文(KV缓存)不是要永久保存的 “账本”,而是模型推理用的 “草稿纸”——丢了重写就行,没必要花大价钱、耗大量电去做多重备份和强一致性。现代AI基础设施拼的是 “每度电能出多少有效token”,所以存储必须优先快、省电、便宜,而不是数据不丢。
满足这些需求,正将现有内存与存储层级推向极限,这也是需要重新思考上下文在GPU内存、主机内存与共享存储间布局的核心原因。
要理解这一差距,需先看推理上下文在 G1–G4 层级间的流转逻辑(图 1)。AI基础设施团队借助NVIDIA Dynamo等编排框架,实现上下文在这些存储层级间的管理:
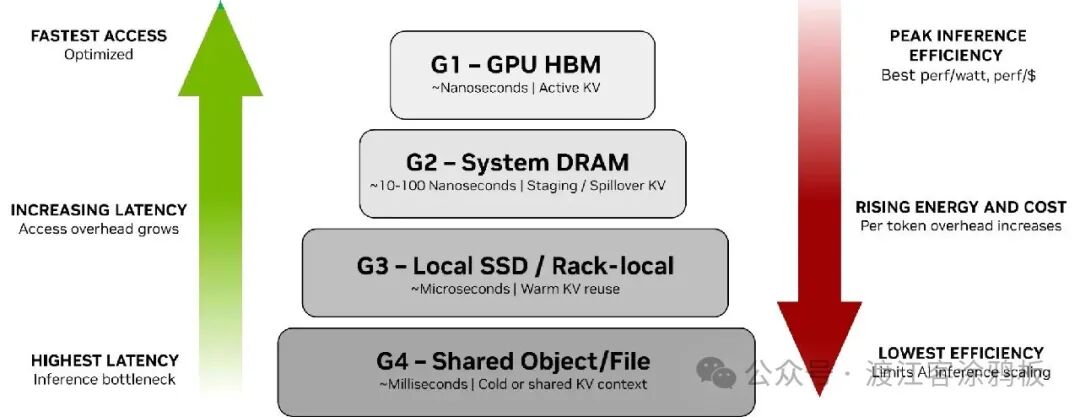
G1至G4存储层级与性能、效率的关系
- G1(GPU HBM):纳秒级访问,用于活跃生成中、对延迟敏感的热KV缓存
- G2(系统RAM):10–100 纳秒级访问,用于从HBM溢出的KV缓存暂存与缓冲
- G3(本地SSD):微秒级访问,用于短时间内可复用的温KV缓存
- G4(共享存储):毫秒级访问,用于需持久化但非即时关键路径的冷数据、历史记录与结果
G1专为访问速度优化,G3与G4则专为持久性优化。随着上下文规模增长,KV缓存会快速耗尽G1–G3的本地存储容量,被迫下沉至企业级存储(G4),这会引入不可接受的开销,同时推高成本与功耗。
图1说明:KV缓存离GPU越远,使用成本就越高。左侧向上箭头表示越靠近顶部访问速度越快、延迟越低;右侧向下箭头表示效率持续下降,从 GPU HBM 的峰值效率,到共享存储的最低效率,同时能耗、成本与单 token 开销持续上升。
在层级顶端,GPU HBM(G1)提供纳秒级访问与最高能效,是直接参与token生成的活跃KV缓存的理想载体。当上下文超出 HBM 物理容量时,KV缓存会溢出至系统 DRAM(G2)与本地/机架挂载存储(G3),此时访问延迟上升,单 token 能耗与成本开始增加。尽管这些层级扩展了有效容量,但每多一次跳转都会引入开销,降低整体效率。
在层级底端,共享对象与文件存储(G4)提供持久性与大容量,但延迟达毫秒级,是推理场景中能效最低的层级。虽然适用于冷数据或共享数据,但将活跃或频繁复用的 KV 缓存推入该层级,会大幅推高功耗,直接限制 AI 的低成本规模化。
核心结论是:延迟与效率紧密耦合—— 推理上下文离GPU越远,访问延迟越高,能耗与单token成本越高,整体效率越低。这种性能优化型内存与容量优化型存储之间的差距不断扩大,迫使AI基础设施团队重新思考如何在系统中布局、管理与扩展不断增长的KV缓存上下文。
AI工厂需要一个互补的、专用的上下文层,将KV缓存视为独立的AI原生数据类型,而非强行塞入稀缺的 HBM 或通用企业存储中。
二、NVIDIA推理上下文内存存储(ICMS)
NVIDIA推理上下文内存存储(ICMS)平台是一套完整集成的存储基础设施。借助NVIDIA BlueField‑4数据处理器,在Pod级别构建专用的上下文内存层级,弥合高速GPU内存与可扩展共享存储之间的鸿沟。这一设计加速KV缓存数据的访问与跨节点高速共享,提升性能并优化功耗,以应对大上下文推理的增长需求。
ICMS平台新增G3.5 层级——专为KV缓存优化的以太网挂载闪存层级。这一层级作为AI基础设施Pod的智能体长期记忆,容量足以同时承载多个智能体的共享、动态上下文,同时又足够靠近计算节点,可频繁将上下文预加载回GPU与主机内存,避免解码阶段卡顿。
ICMS为每个GPU Pod提供PB级共享容量,让长上下文工作负载在被HBM与DRAM逐出后仍能保留历史数据。这些历史数据存储在低功耗的闪存层级中,扩展GPU与主机内存的层级体系。G3.5层级可提供海量聚合带宽,且能效优于传统共享存储,将KV缓存转化为可共享的高带宽资源,让编排器能在智能体与服务间协调复用,无需在每个节点上独立重新生成。
当大部分延迟敏感、瞬时性的KV缓存由G3.5层级提供服务后,持久化的G4对象与文件存储可仅用于真正需要长期保存的数据,包括非活跃的多轮次 KV 状态、查询历史、日志及其他多轮次推理产物,这些数据可能在后续会话中被调用。
这既减轻了G4的容量与带宽压力,又能在关键场景保留应用级历史数据。随着推理规模扩大,G1–G3的KV容量会随GPU数量增长,但仍无法覆盖所有KV需求,而ICMS恰好填补了G1–G3与G4之间的KV容量缺口。
NVIDIA Dynamo等推理框架,会结合其KV块管理器与NVIDIA推理传输库(NIXL),编排推理上下文在内存与存储层级间的流转,将ICMS作为KV缓存的上下文内存层。这些框架中的 KV 管理器会预加载KV块,在解码阶段前将其从ICMS调入G2或G1内存。
这种可靠的预加载机制,依托ICMS相比传统存储更高的带宽与更优的能效,旨在最小化卡顿与空闲时间,为长上下文与智能体工作负载实现最高5倍的持续TPS提升。当与运行KV I/O平面的NVIDIA BlueField‑4处理器结合时,系统可高效处理NVMe‑oF与对象/RDMA协议的终结。
图 2 展示ICMS在 NVIDIA Rubin 平台与 AI 工厂技术栈中的位置。这是一张分层示意图,展示ICMS在NVIDIA Rubin平台中的位置:上层为推理池,包含Dynamo、NIXL与KV缓存管理;中间为Grove编排与Rubin计算节点,实现KV在各内存层级的分层调度;底层为Spectrum‑X连接的、基于SSD的BlueField‑4 ICMS节点。
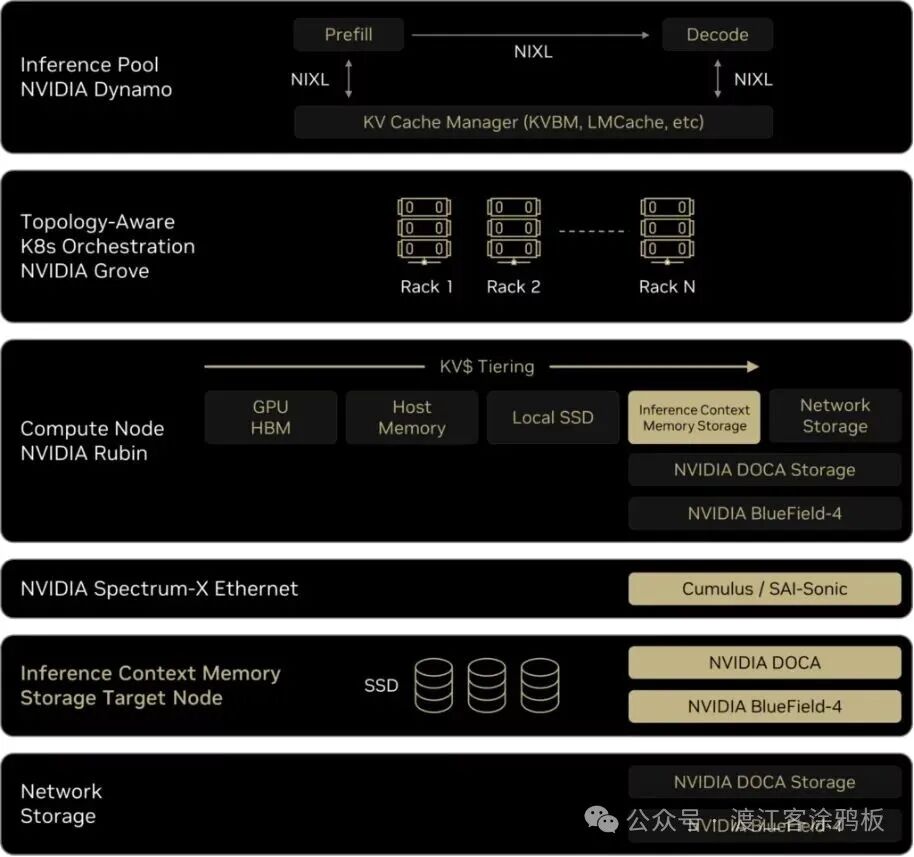
图 2:NVIDIA推理上下文内存存储架构,从推理池到BlueField‑4 ICMS目标节点
在推理层,NVIDIA Dynamo与NIXL管理预填充、解码与KV缓存,同时协调共享上下文的访问。其下是拓扑感知的编排层,借助NVIDIA Grove实现工作负载在机架间的部署,同时感知KV局部性,确保工作负载在节点间迁移时仍能复用上下文。
在计算节点层面,KV分层覆盖GPU HBM、主机内存、本地SSD、ICMS与网络存储,为编排器提供覆盖不同容量与延迟目标的上下文布局连续体。将所有组件串联的是Spectrum‑X以太网,它连接Rubin计算节点与BlueField‑4 ICMS目标节点,提供低延迟、高能效的网络,将闪存支撑的上下文内存融入服务于训练与推理的AI优化网络fabric中。
三、ICMS 平台的核心支撑技术
NVIDIA BlueField‑4为ICMS提供800 Gb/s连接、64核NVIDIA Grace CPU与高带宽LPDDR内存。专用硬件加速引擎可实现最高800 Gb/s线速加密与CRC数据保护。
BlueField‑4可集成到KV pipeline中,在不增加主机CPU开销的前提下,保障KV数据流的安全与校验。通过兼容标准NVMe与NVMe‑oF传输协议(包括NVMe KV扩展),ICMS在保持与标准存储基础设施互操作性的同时,满足KV缓存所需的专用性能。
该架构借助BlueField‑4加速KV I/O与控制平面操作,覆盖Rubin计算节点上的DPU与ICMS闪存机箱中的控制器,减少对主机CPU的依赖,最小化序列化与主机内存拷贝操作。此外,Spectrum‑X以太网提供AI优化的 RDMA fabric,以可预测、低延迟、高带宽的连接,链接ICMS闪存机箱与GPU节点。
此外,NVIDIA DOCA框架引入了 KV 通信与存储层,将上下文缓存视为 KV 管理、共享与布局的一级资源,充分利用 KV 块的独特属性与推理模式。DOCA 对接推理框架,通过 BlueField‑4 高效实现 KV 缓存与底层闪存介质间的传输。
这种无状态、可扩展的设计,与AI原生KV缓存策略高度契合,同时借助NIXL与Dynamo实现AI节点间的高级共享,提升推理性能。DOCA框架支持开放接口,便于更广泛的编排场景,为存储合作伙伴提供灵活性,将其推理解决方案扩展至G3.5上下文层级。
Spectrum‑X以太网作为面向AI原生KV缓存的RDMA访问高性能网络 fabric,为NVIDIA推理上下文内存存储平台提供高效的数据共享与检索能力。Spectrum‑X以太网专为 AI 设计,可在大规模场景下提供可预测、低延迟、高带宽的连接,通过先进的拥塞控制、自适应路由与优化的无损 RoCE 技术,在高负载下最小化抖动、尾部延迟与丢包。
NVIDIA DOCA 软件框架
NVIDIA DOCA充分释放NVIDIA BlueField网络平台的潜力。通过利用BlueField DPU和SuperNIC的强大功能,DOCA能够快速创建可卸载、加速和隔离数据中心工作负载的应用程序和服务。使开发人员能够创建软件定义、云原生、DPU和 SuperNIC加速且具有零信任保护的服务,从而满足现代数据中心对性能和安全的需求。
source https://developer.nvidia.com/networking/doca
四、高能效、高吞吐的KV缓存存储实现
电力供应是AI工厂规模化的首要瓶颈,能效因此成为超大规模推理的核心指标。传统通用存储栈能效低下:x86控制器将大量能耗浪费在元数据管理、副本复制、一致性校验等功能上,而这些对瞬时、可重建的KV数据毫无必要。
KV缓存与企业数据有着本质区别:具有瞬时性、衍生性,丢失后可重新计算生成。作为推理上下文,无需为长期留存数据设计的持久性、冗余备份或复杂数据保护机制。将重型存储服务应用于KV缓存,会引入不必要的开销,既增加延迟与功耗,又降低推理效率。而ICMS将KV缓存视为独立的AI原生数据类型,消除这类冗余开销,能效相比通用存储方案最高可提升5倍。
这种能效提升不仅局限于存储层,还延伸至整个计算架构。通过可靠预加载上下文、减少甚至避免解码器卡顿,ICMS避免了GPU在空闲周期或重复计算历史数据上浪费能耗,进而实现每秒token生成量(TPS)最高提升5倍。该方案确保电力被用于主动推理而非基础设施开销,最大化整个AI Pod的有效token/瓦特产出。
五、以更优性能与 TCO 实现超大规模智能体AI
基于BlueField‑4的ICMS平台,为AI原生组织提供规模化智能体AI的全新路径:在Pod级别构建上下文层级,扩展有效GPU内存,并将KV缓存转化为跨NVIDIA Rubin Pod的共享高带宽、长时记忆资源。通过卸载KV数据流转操作,并将上下文视为可复用、非持久化的数据类型,ICMS减少了重复计算与解码器卡顿,将更高的每秒 token 生成量(TPS)直接转化为更多服务查询、更高智能体并发数,以及规模化场景下更短的尾部延迟。
这些收益共同优化了总拥有成本(TCO):团队可在相同机架、行级或数据中心内容纳更多有效 AI 算力,延长现有设施的使用寿命,并围绕 GPU 容量规划未来扩展,而非受制于存储开销。
参考资料:
Ref:https://developer.nvidia.com/
如果你对 AI 基础设施、高性能存储与网络技术有更多兴趣,欢迎在 云栈社区 与其他开发者交流探讨,这是一个聚焦前沿技术的开发者社区。
 发表于 2026-1-24 14:18:09
|
查看: 136|
回复: 0
发表于 2026-1-24 14:18:09
|
查看: 136|
回复: 0
