
刘壮团队在无需归一化(Normalization-Free)Transformer的研究上取得了新的突破。
长久以来,LayerNorm几乎是Transformer架构中的标配组件,但它也带来了显著的性能开销,特别是在大模型推理阶段,其计算和访存成本不容忽视。因此,探索一种高效且无需依赖归一化层的Transformer架构,一直是研究者追求的长远目标。然而,这条探索之路长期面临两大障碍:一是训练过程不稳定,二是模型的最终性能往往难以匹敌使用归一化层的标准模型。
近日,一篇题为《Stronger Normalization-Free Transformers》的新论文提出了一种名为Derf(Dynamic erf) 的简单激活层,它成功让无归一化的Transformer不仅能稳定训练,更是在多个任务设定下超越了使用LayerNorm的标准模型的性能。

论文作者之一刘壮在社交媒体上分享了这一成果。他表示,这项研究提出的Derf是一种极其简单的逐点层,它使得完全抛弃归一化层的Transformer不仅能够工作,甚至能在实际性能上超越传统的、依赖LayerNorm等机制的模型。

这一发现有力地表明,曾被长期视为“黄金标准”的归一化层,或许并非构建高性能Transformer的唯一必要选项。
实际上,今年早些时候,刘壮、何恺明、Yann LeCun等人在《Normalization-Free Transformer》一文中已经证明,Dynamic Tanh(DyT)函数可以替代Transformer中的归一化层。而Derf正是在DyT基础上的进一步发展和强化。
与DyT类似,Derf也是一种不依赖于激活值统计量的逐点层。它的核心是一个经过平移和缩放的高斯误差函数,仅包含少量可学习参数。在模型架构中,它可以像“即插即用”的组件一样,直接替换掉原本的LayerNorm或RMSNorm层。
凭借其极简的结构、稳定的训练特性和更强的性能表现,Derf为构建真正高效的无归一化Transformer提供了一条极具实践价值的路径,相关代码已经开源。
超越归一化层的逐点函数
这项研究的核心目标,就是寻找一种性能能够超越传统归一化层的逐点函数,从而推动更强Transformer架构的发展。
研究团队首先系统性地探索了逐点函数的内在性质如何影响训练动态和最终性能。他们重点关注了四个基础且具有代表性的数学属性:零中心性、有界性、中心敏感性以及单调性。

实验表明,一个同时满足上述四个条件的函数,往往能带来更稳定的训练过程和更优异的性能表现。这一分析筛选出了一类有效的归一化替代函数,并为无归一化Transformer的设计总结出了明确的原则。最终,Dynamic erf(Derf) 以其极简的设计和最优的性能脱颖而出。
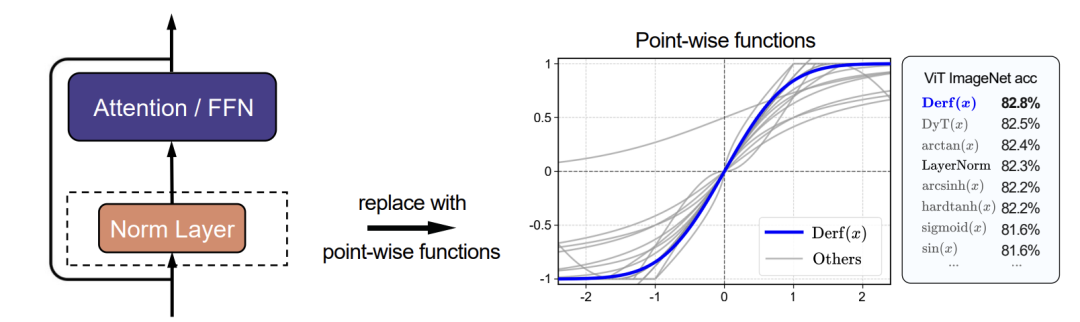
这项研究传递出一个明确信息:只要设计得当,简单的逐点函数不仅能替代复杂的归一化层,甚至可以实现性能上的反超。
最优函数设计:Derf
在广泛的函数搜索中,研究者发现误差函数 erf(x) 表现最佳。误差函数与标准高斯分布的累积分布函数密切相关,其定义如下:
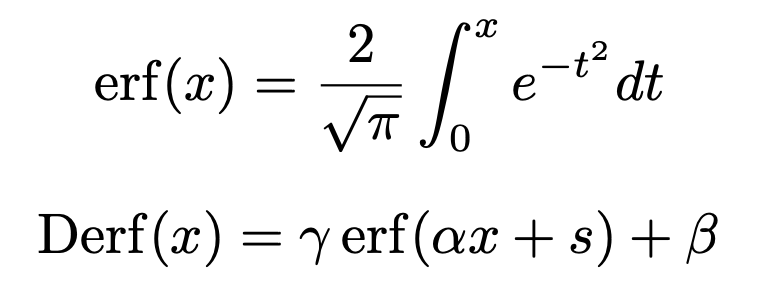
在本文的设计中,对erf(x)引入了可学习参数,从而构成了Derf(Dynamic erf)。对于一个输入张量 x,Derf层的计算如以下公式所示:
Derf(x) = γ erf(αx + s) + β
其中,位移参数 s 和缩放参数 α 是可学习的标量,而 γ 和 β 是可学习的逐通道向量。在将Derf集成到Transformer架构中时,研究人员采用了直接的“一对一”替换策略:将模型中所有的归一化层(包括注意力层前、前馈网络前以及最终的输出归一化层)都替换为Derf层,确保其在整个模型中的一致应用。
实验结果
研究团队在多种基于Transformer的模型以及少量其他现代架构上,系统地评估了Derf的有效性。在保持训练配置完全一致的条件下,Derf的表现不仅能够与传统的LayerNorm持平,在多数情况下更是实现了超越,并且其性能在各个领域都稳定地优于先前提出的DyT。
简而言之,在以下任务中Derf均展现出优势:
- ImageNet图像分类(ViT):Top-1准确率更高。
- 图像生成(扩散Transformer, DiT):FID分数更低(图像质量更高)。
- 基因组任务(HyenaDNA, Caduceus):DNA序列分类准确率更高。
- 语音表示学习(wav2vec 2.0):验证集损失更低。
- 语言建模(GPT-2):整体表现与LayerNorm相当,但显著优于DyT。
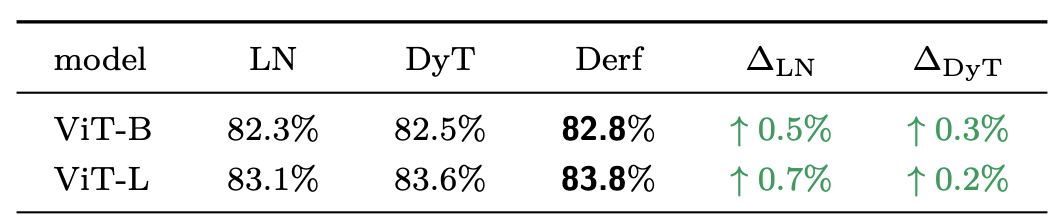
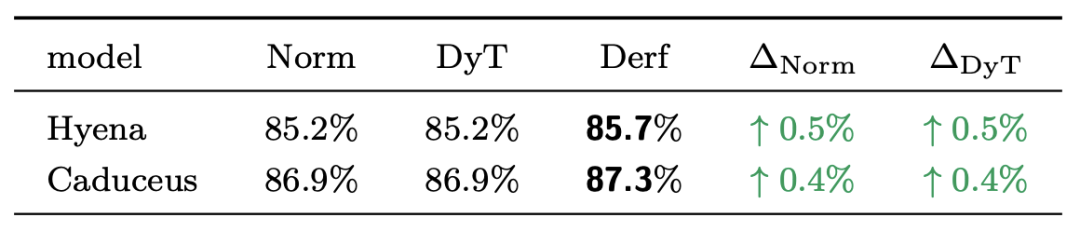
在ImageNet-1K数据集上训练ViT-Base和ViT-Large模型的结果表明,在不同模型规模下,Derf的Top-1准确率均高于LayerNorm和DyT。
在图像生成任务中,研究人员在ImageNet-1K上训练了不同规模的DiT模型,并使用FID分数评估生成质量。结果显示,Derf在所有模型规模下的FID都低于LayerNorm和DyT。
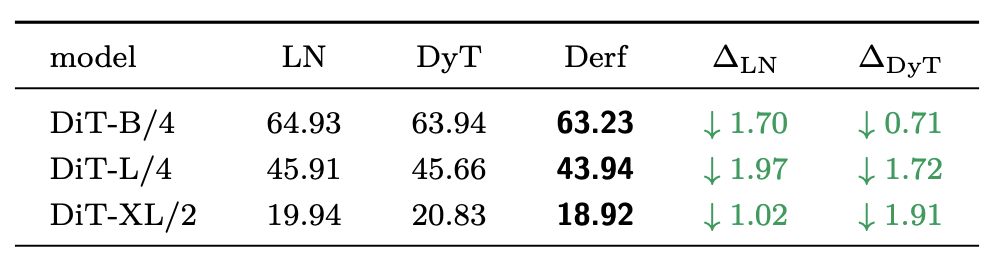
语音模型(wav2vec 2.0)
在LibriSpeech数据集上进行语音表示学习的预训练后,Derf在两个不同规模的wav2vec 2.0模型上,均取得了比LayerNorm和DyT更低的验证集损失。
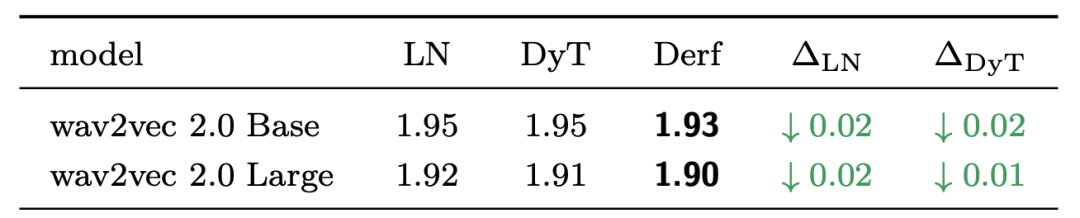
DNA序列模型(HyenaDNA, Caduceus)
在长序列DNA建模任务中,对模型进行预训练并在GenomicBenchmarks数据集上评估。结果表明,Derf的性能超过了模型默认使用的LayerNorm、RMSNorm以及DyT。
语言模型(GPT-2)
在OpenWebText数据集上预训练GPT-2模型,Derf在验证集损失上的表现与LayerNorm基本持平,同时明显优于DyT。

结论与洞见
这些实验结果清晰地表明:一个设计精良的简单逐点层,不仅可以完美“替代”归一化层,更能让Transformer变得“更强”,而不仅仅是“不差”。
一个有趣的发现是,Derf的优势并非源于其更强的拟合能力。当研究者在评估模式下对训练集本身测量损失时,基于归一化的模型训练损失最低,而Derf的损失反而更高。然而,在测试集上,Derf的表现却更好。这揭示了一个关键事实:Derf的优势主要来源于其更出色的泛化能力,而非对训练数据的过拟合。
总而言之,Derf是一个简单、实用的“即插即用”层,它为构建性能更强、无需归一化的Transformer提供了新的可靠选择。这项研究也促使我们重新思考深度学习模型中一些被视为“理所当然”的组件设计。
 发表于 2026-1-24 13:58:05
|
查看: 259|
回复: 0
发表于 2026-1-24 13:58:05
|
查看: 259|
回复: 0
