我们都知道 HTTP 协议是互联网世界的通用“语言”,不管是浏览器和服务器的交互,还是不同服务间的通信,它都能搞定。
既然 HTTP 已经能满足服务的通信需求,那为什么还要专门设计 RPC 呢?今天,我们就带着这个疑问好好聊聊。
HTTP:能用,但不够”好用“
有个冷知识你可能不知道:RPC 的诞生时间其实比 HTTP 还要早。但历史的进程很有意思 — 随着互联网爆发式增长,HTTP 凭借简单灵活的特性,率先成为了互联网世界的“通用语言”。它的优势太明显了:

- 文本协议友好:用 JSON、XML 序列化数据,调试时抓个包就能直接看懂内容;
- 无状态设计:服务器不需要记录上一次请求的信息,每个请求都能独立响应。哪怕流量暴增,也能通过增加服务器轻松扛住压力。
- 标准化方法:GET 查数据、POST 提交数据、PUT 更新、DELETE 删除,一套规则走天下。
所以在微服务早期,比如 Spring Cloud 刚兴起时,大部分团队都用 HTTP/RESTful 做内部服务通信。那时候服务数量不多,调用关系简单,HTTP 确实够用 — 毕竟不用额外学新东西,框架也成熟。
但随着业务的快速膨胀,微服务的调用链路早已从简单串联变成了网状交织:一个看似简单的电商下单请求,实则要串联订单、商品、库存、支付、用户等多个核心服务,每个服务又要调用 1-2 个下游服务。
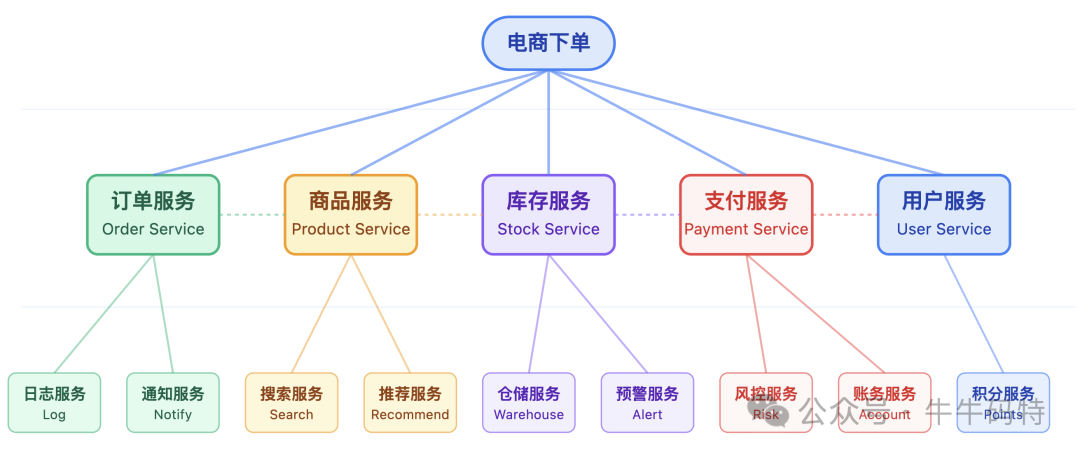
当调用链路复杂到这个地步,HTTP 的短板就再也藏不住了。
首当其冲的就是调用成本太高 — 胶水代码的体量甚至超过了业务代码。就算用了封装好的 HTTP 工具框架,也避不开繁琐的请求参数映射、响应结果解析,以及处理跨服务调用的各类异常。这些工作本质上都是为了调用而做的额外铺垫,却要占据开发者大量的精力。
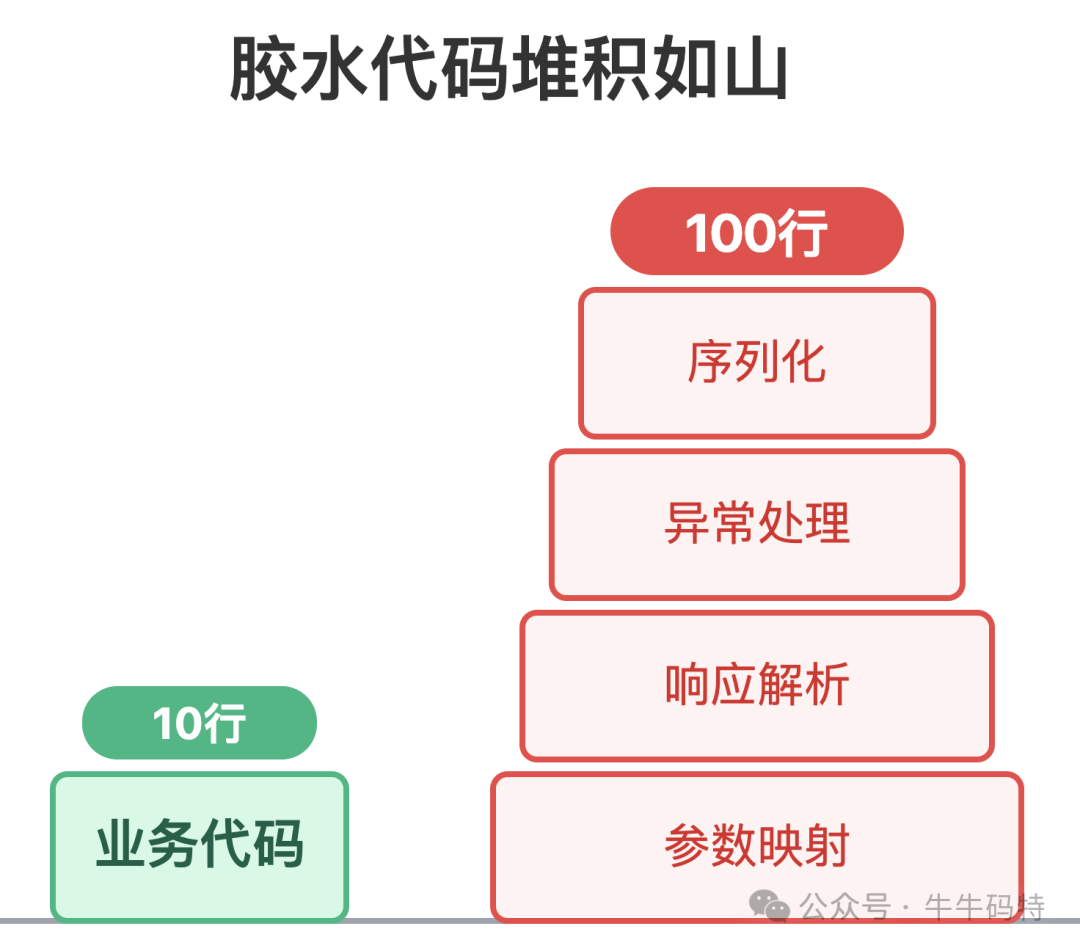
其次是传输效率太低,这点在高频服务调用场景下会被无限放大。
一方面是请求头和文本协议太过臃肿。举个简单例子:假设传输一条「用户 ID=123」的 10 字节数据,单是请求头的体积就能轻松突破 500 字节。更别提 JSON、XML 这类文本格式本身,还会带着一堆引号、大括号之类的冗余语法,进一步加重传输负担。

另一方面是连接模型太“笨重”:HTTP 1.1 之前,默认每次发请求都需新建 TCP 连接,三次握手、四次挥手的开销在高频调用下被无限放大;就算后续的 Keep-Alive 长连接实现了连接复用,同一连接上的请求仍需串行处理,无法并行传输。
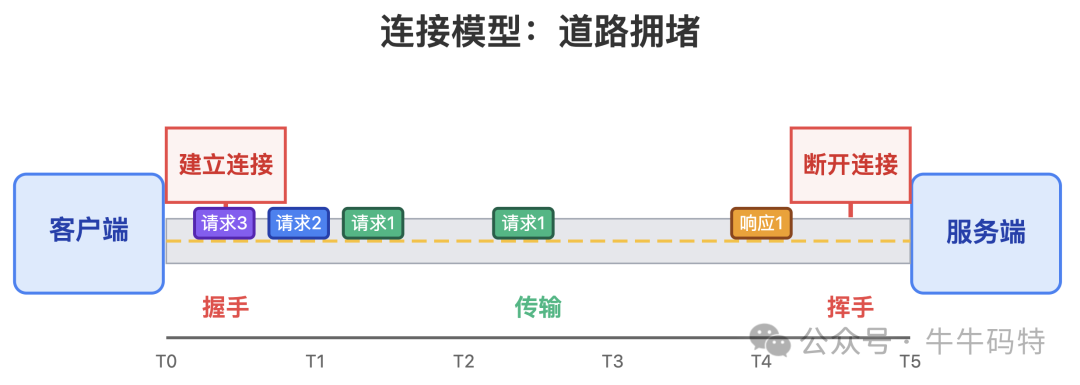
不过,这些传输层面的问题,在 HTTP/2 兴起后几乎都得到了解决,但 HTTP 还是难逃通信协议的根本性局限:作为一条标准化的传输管道,它们只负责把数据从 A 端送到 B 端,至于管道另一端的服务状态如何、能不能正常响应请求,它完全不过问。
可在复杂的微服务架构里,服务之间的远程调用往往绕不开一堆实际的问题:
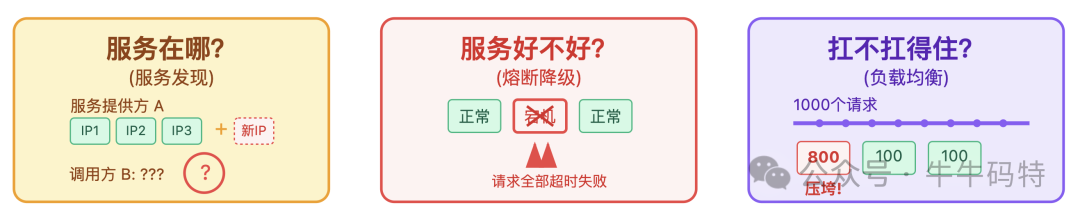
- 服务在哪?:服务 A 今天扩容了 3 台机器,IP 地址全变了,服务调用方 B 怎么自动感知到新地址?
- 服务好不好?:如果服务 A 的其中一台机器宕机了,服务 B 怎么自动跳过这台故障机器,避免请求全部打进去超时失败?
- 服务扛不扛得住?:1000 个请求同时涌进来,怎么均匀分配到服务 A 的 3 台机器上,防止某一台被请求压垮?
这些服务治理的问题,HTTP 完全帮不上忙,只能靠开发者自己引入相应组件解决。到最后,原本简单的服务调用,硬生生变成了 “组件缝合怪”,维护成本居高不下。
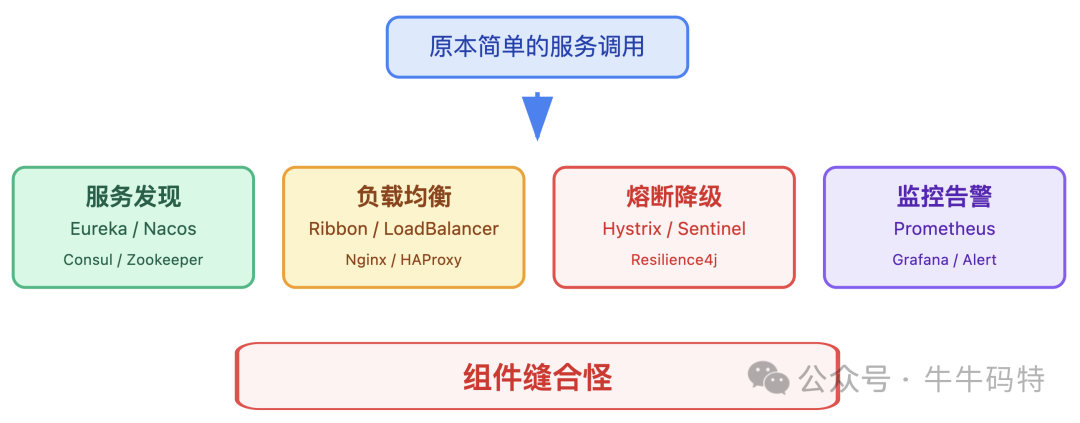
所以对于服务间通信来说,HTTP 能用吗?能用;但好用吗?不好用。当调用一个远程服务需要同时操心 “怎么连、怎么传、怎么管” 时,开发者自然会想:有没有一种方案,能让我像调用本地函数一样简单,还能自动搞定效率和治理的问题?
于是,为高效内部通信而生的 RPC 重新回到了大众视野。
RPC:为微服务内部通信而生
RPC 又叫远程过程调用,本质上它不是一款通信协议,而是一种能抹平「本地」与「远程」调用边界的设计思想:让开发者像调用本地函数一样,轻松完成跨机器、跨进程的服务“交流”。
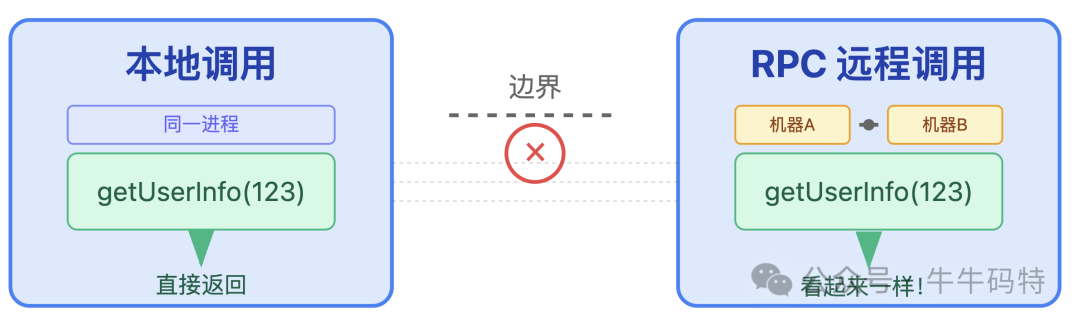
那这种“交流”,到底能有多简单?举个直观的例子:如果订单服务 A 要调用用户服务 B 的 getUserInfo(123) 方法,只需要一行代码:

- 对调用方 A 来说:你只需要写一行代码,写起来就像调用本地工具类一样自然。
- 对提供方 B 来说:你只需要专注写
getUserInfo 的核心业务逻辑。
至于“怎么找到服务 B 的地址、发起网络请求、打包响应结果、怎么处理网络异常”这些脏活累活,统统交给 RPC 框架处理。
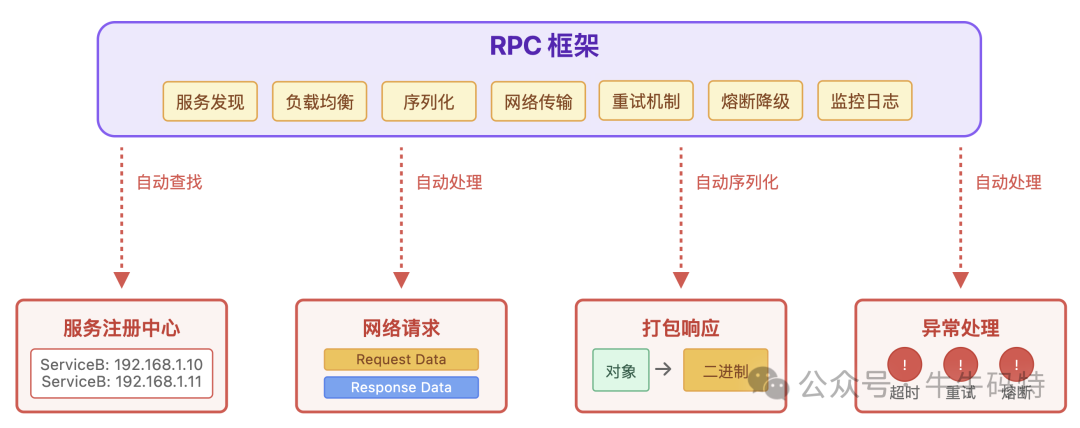
当然,理论上我们也可以照着 RPC 的思想,自己动手封装一套 RPC 调用逻辑。但现实里几乎没人会这么干 — 毕竟现成的 RPC 框架早就把这些底层工作打磨得炉火纯青。

那 RPC 框架到底是怎么把这么多复杂工作藏在“本地调用”表象下的?其实不管是 Dubbo、gRPC 还是Thrift,它们背后都遵循着一套高度相似的 RPC 调用逻辑。接下来,我们就拆开它的 “黑盒子”,看看 RPC 从调用到响应的完整工作流。
RPC 的幕后工作流
当写下 userService.getUserInfo(123) 这行代码时,RPC 的「幕后工作流」就已经悄悄启动了 — 这个流程其实我们就像去银行办理业务,从找对网点到拿到回执单,整个过程分为五步:
1. 查找服务网点:服务注册与发现
去银行办业务得先找对网点,服务 A 要调用服务 B 也一样,第一步得明确:服务 B 在哪台机器上?这个问题,由「注册中心」来解决 — 它相当于银行的全国网点查询系统,专门负责记录所有服务的位置和业务信息。
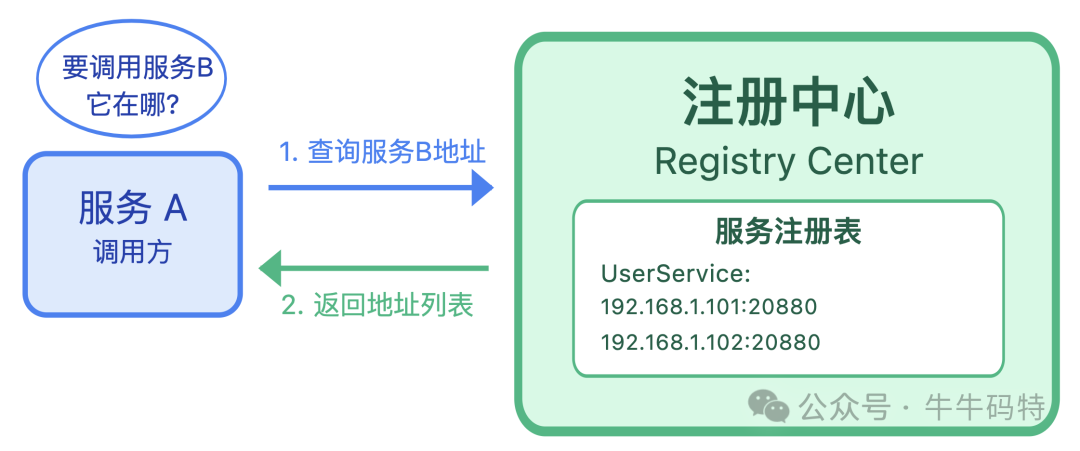
它的工作简单来说就是存地址、推地址、更地址:
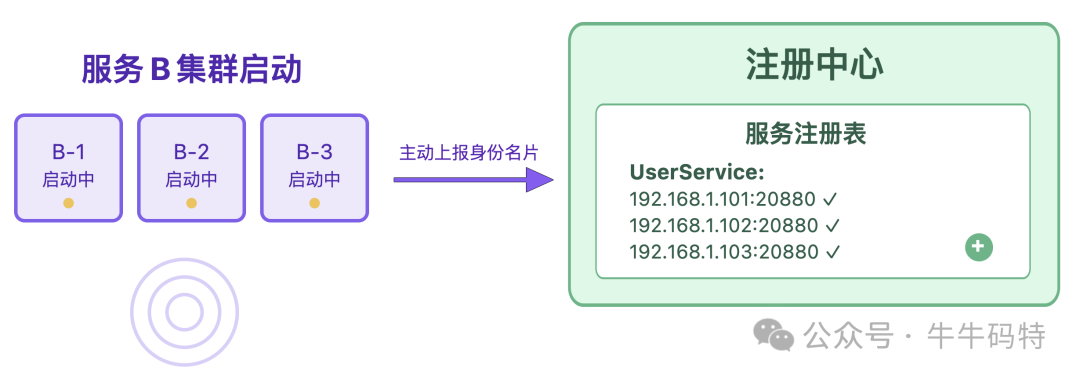
- 存地址:银行开业后,会把地址和可办业务录入网点查询系统;服务 B 启动时,也会主动把自己的“身份名片” 上报给注册中心,把「IP + 端口」、接口名这些关键信息登记在册。
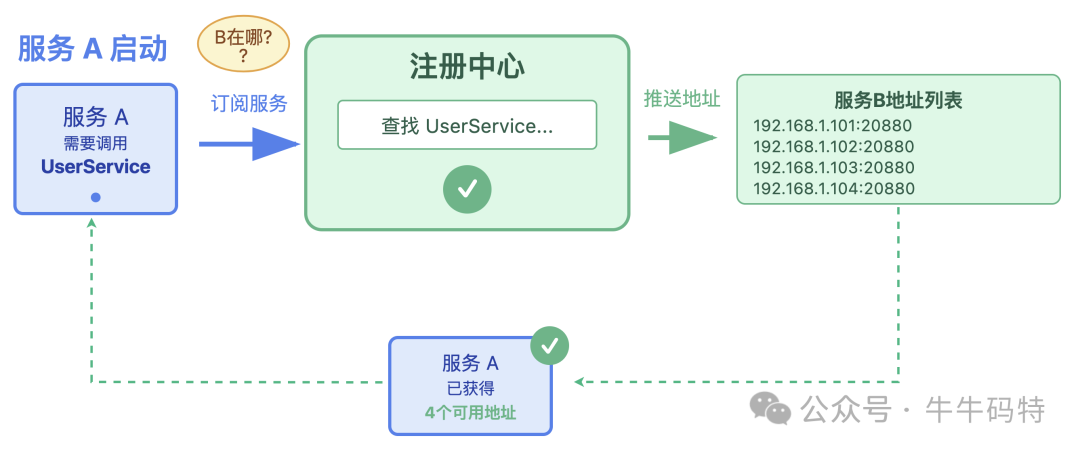
- 推地址:服务 A 如果想找服务 B “办理业务”,启动后就会向注册中心订阅需求:“我要调用服务 B,帮我找找它在哪?” 注册中心收到请求后,会把服务 B 的所有可用地址列表推给 A;
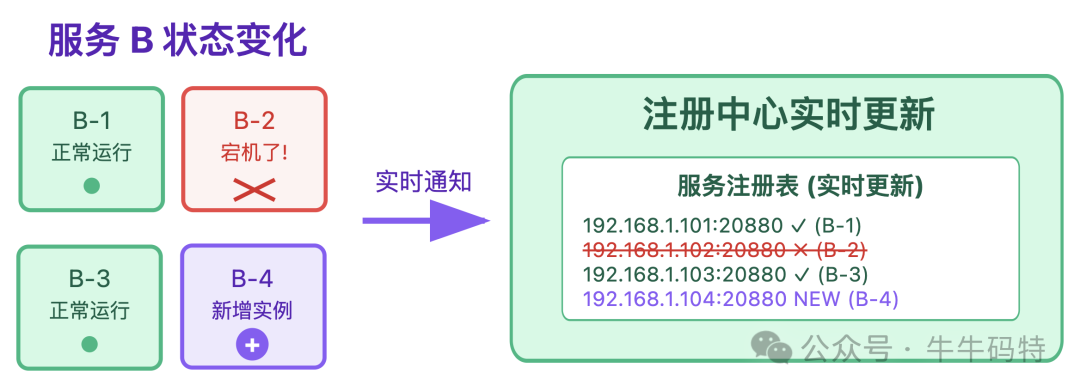
- 更地址:后续无论是服务 B 搬迁、扩容、或者某台机器宕机,注册中心都会实时把地址变化同步给服务 A。这意味着服务 A 永远能拿到服务 B 的「最新可用地址」。
不过,找对了网点只是第一步,要办理业务还得填写银行的标准化单据。服务 A 也一样,得把 “调用 getUserInfo (123) 的指令” 转换成标准化的格式,才能准确传给服务 B — 这就是第二步要讲的序列化与反序列化。
2. 填写“标准化单据”:序列化与反序列化
要知道,服务 A 和服务 B 是两台独立的机器,机器之间的通信内容,本质上是二进制数据,要让这条指令顺利“办成事”,需要经历一套标准化的流程。
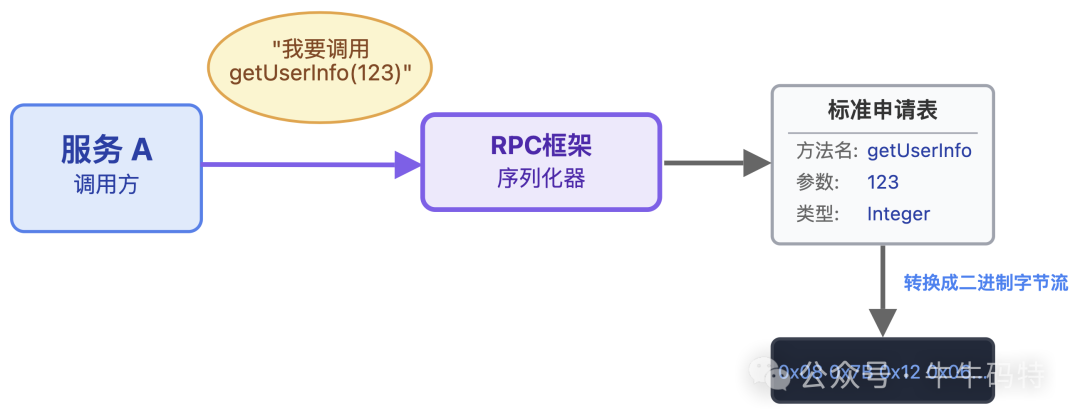
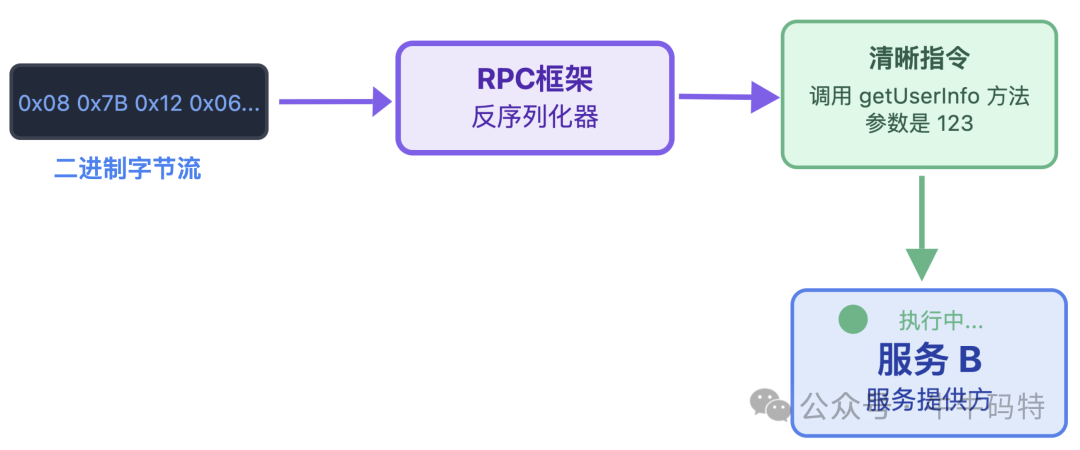
第一步就是服务 A 的序列化,这步就像我们把口头需求,填进统一格式的银行申请表。当服务 A 调用 getUserInfo (123) 时,RPC 框架会把「方法名(getUserInfo)+ 参数(123)」这种好懂的语义,转换成机器可识别的二进制字节流。
等服务 B 收到这份 “二进制申请表” 后,就轮到反序列化出场了。RPC 框架会把字节流还原成「调用 getUserInfo 方法,参数是 123」的清晰指令,这样服务 B 就能一眼看懂需求,立刻执行查询用户信息的业务逻辑。
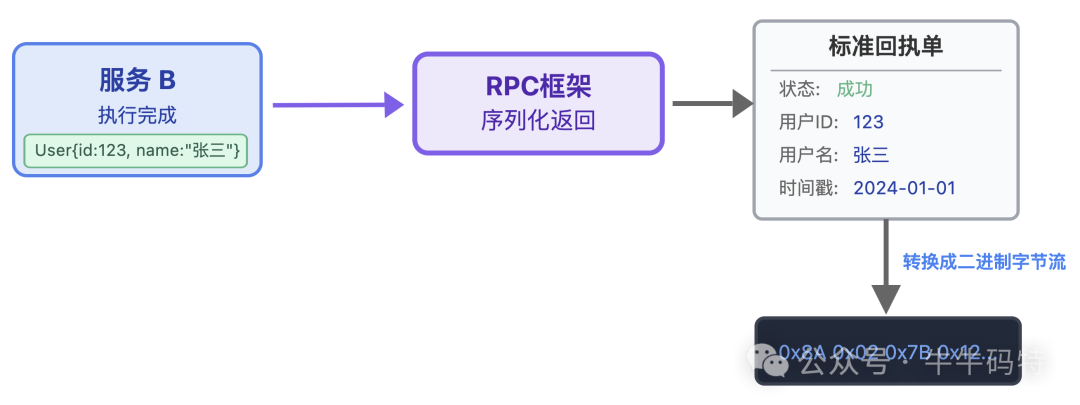
服务 B 执行逻辑、生成完 User 对象后,也需要把对象序列化成二进制字节流;这就像银行柜员办完业务,会先把结果整理好,再打印成标准的回执单交给我们。
而整个过程中,最关键的就是藏在“标准化单据”背后的约定格式 — 序列化协议。RPC 的序列化协议通常首选二进制协议,这类协议的优势很突出:
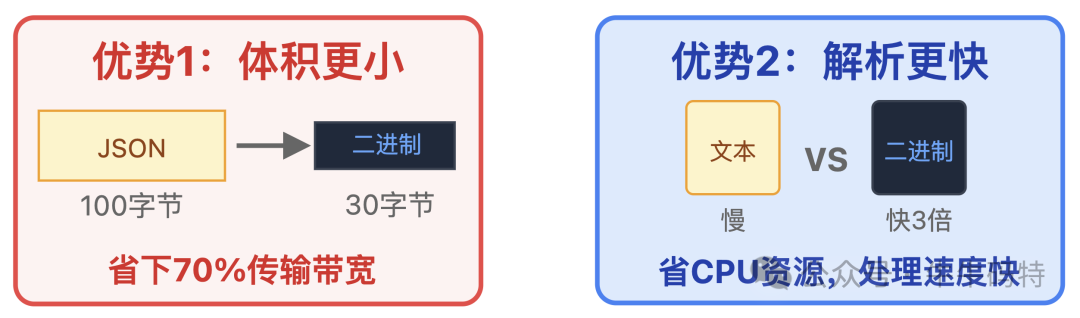
- 体积更小:同样的数据,比起 JSON、XML 这些 HTTP 常用的文本格式,二进制打包后能缩小到文本的 1/3 以内,省不少传输带宽。
- 解析更快:机器能直接看懂二进制数据,不用像解析文本那样反复校验格式、转换字符,既省 CPU 资源,处理速度也快得多。
比如 Dubbo 框架支持的 Hessian,还有 gRPC 默认使用的 Protobuf,都属于这类高效的二进制协议。当然,RPC 框架也会支持 JSON、XML 这类文本协议,用来兼容开发调试、轻量级服务通信等对性能要求不高的场景。
完成序列化的二进制数据,接下来就需要通过网络从服务 A 传到服务 B,这一步的核心诉求是高效与低开销。
3. 传递“单据”:网络传输
如果每次去银行办业务都得排队取号,效率会非常低。RPC 通信可不会这么麻烦,它走的是专属 VIP 通道 — TCP 长连接。长连接能在服务 A 和服务 B 之间建立起一条持久的通信通道,不用每次调用都重新 “握手” “挥手”,省去了反复建立和断开连接的开销。
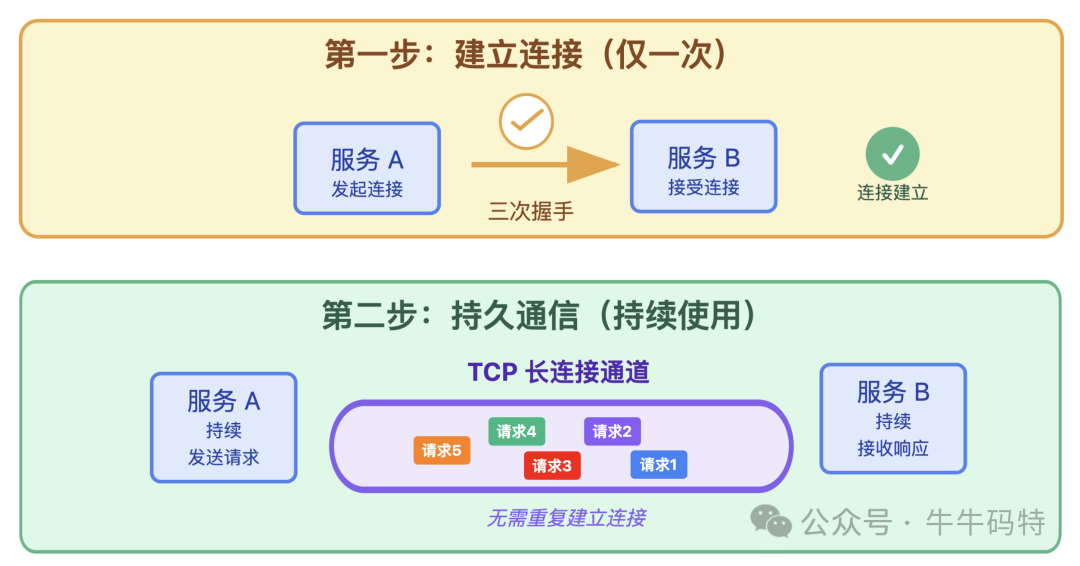
同时,为了进一步提升传输效率,框架会在 TCP 长连接这个通道里实现多路复用 — 简单来说,就是把每个 RPC 请求和响应都封装成独立的 “数据帧”,这样一条 TCP 连接上就能同时传输多个数据帧,请求之间互不阻塞,能够并行处理。
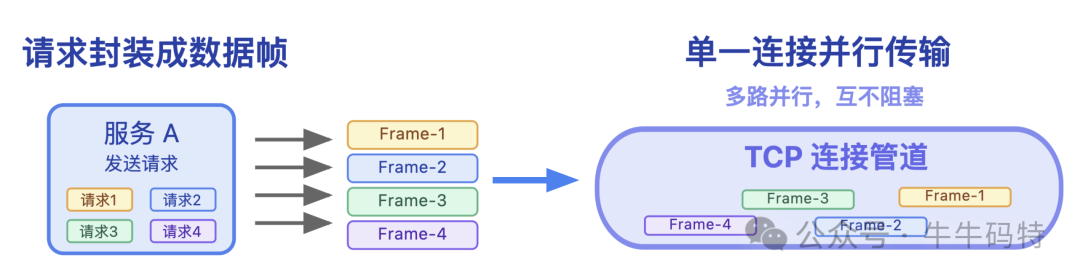
当然除了 TCP 长连接,RPC 也可以基于其他协议实现通信。比如主流的 gRPC 框架,就默认采用 HTTP/2 作为底层传输协议。HTTP/2 本身就自带多路复用、二进制帧和头部压缩的特性,无需额外开发就能实现高效数据传输。
到这里,我们已经解决了 RPC 调用的 “寻址、编码、传输” 三大问题,但还有一个最核心的疑问:为什么开发者只需要写一行 userService.getUserInfo(123),就能触发这么复杂的远程通信流程?这就要归功于 RPC 最巧妙的设计 — 动态代理。
4. 专人“跑腿”:动态代理
这是 RPC 最神奇的环节 — 它能让服务 A 产生一种错觉:“我调用的明明就是本地方法!”。但实际上,服务 A 调用的并不是服务 B 的真实方法,而是 RPC 框架自动生成的动态代理对象。这个代理就像你去银行办业务时的专属 “跑腿员”,帮你揽下填单据、递单据、拿回执单等所有繁琐的跑腿活。

当服务 A 调用 代理对象.getUserInfo(123) 时,代理会先拦截这个调用请求;接着悄悄完成一系列 RPC 底层操作:把调用指令序列化、从注册中心找到服务 B 的地址、通过网络把请求传过去,还会自动带上 traceId、userId 等上下文信息;等拿到服务 B 的响应结果后,又会把二进制数据解析成服务 A 能识别的格式,最终返回给调用方。
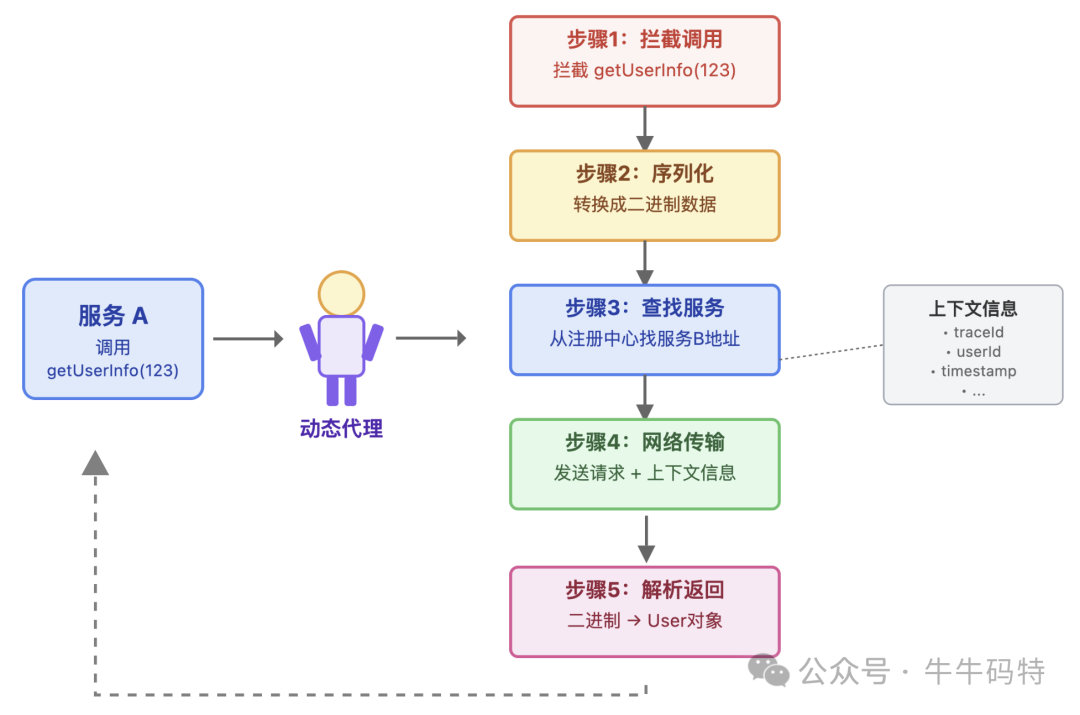
对服务 A 的开发者来说,整个过程完全是透明的。你只需要专注于写出这一行调用代码,剩下的脏活累活,全由代理对象一手包办,丝毫感觉不到 “远程调用” 的存在。
到这里,远程调用的基础问题就已经全部解决了,但整个流程还没结束。最后一步,我们要解决 “服务能不能稳定、可靠地调用” 的问题,也就是服务治理。
5. 业务全链路保障:服务治理
在实际生产环境中,服务可能面临机器宕机、网络抖动、请求量突增等各种问题,RPC 框架的服务治理能力就是为应对这些问题而生,常见的能力包括:
- 负载均衡:如果服务 B 部署了 3 台机器,RPC 框架会按预设策略,比如轮询、加权、最少活跃数等,帮服务 A 选一台 “最合适” 的机器调用,避免某台机器被请求压垮。
- 熔断降级:如果服务 B 连续报错,框架会自动 “熔断” — 暂时停止调用这台机器,直接返回默认值,防止服务 A 被拖垮,引发全链路雪崩。

- 超时重试:如果服务 B 响应太慢,框架会自动重试几次,或者达到超时时间后直接返回,避免请求一直挂着占用资源。
- 监控告警:框架会记录每一次调用的耗时、成功率、错误类型,一旦出现异常,比如成功率低于 90%,就会触发告警,方便开发者及时排查问题。

这些能力就像给 RPC 调用加了“保险” — 即使服务出问题,也能保证整个系统的稳定。通过这五步流程,RPC 把原本复杂的远程服务调用,封装成了像调用本地函数一样简单、高效且可靠的体验。
HTTP 与 RPC:不是对手,是搭档
最后,我们再回到开头的问题:HTTP 够用了,为什么还要 RPC?
答案很简单:场景不同,需求不同。
HTTP 是互联网的 “通用语言”,优势在于通用性 — 不管是浏览器、APP 还是第三方服务,都能通过 HTTP 通信。
RPC 是微服务内部的 “专属方言”,优势在于高性能和低侵入性 — 它从一开始就为 “服务间高频调用” 优化,用二进制协议、长连接、原生服务治理解决 HTTP 的痛点。
一个成熟的微服务架构里,两者从来不是谁替代谁,而是互补:
- 对外:用 HTTP/RESTful 承接用户流量,因为它简单、通用,不需要客户端额外依赖;
- 对内:用 RPC 做服务间通信,因为它高性能、低侵入,能支撑复杂的调用链路。
希望这篇对比分析能帮助你更清晰地理解 HTTP 与 RPC 的定位与差异。在实际的技术选型中,理解不同协议和框架背后的设计哲学与适用场景,远比记住几个技术名词更重要。如果你想了解更多关于网络协议或系统架构的深度内容,欢迎在云栈社区交流探讨。
 发表于 2026-1-24 20:03:23
|
查看: 147|
回复: 0
发表于 2026-1-24 20:03:23
|
查看: 147|
回复: 0
